









“字即图”是一种语义排版技术,其中的单词插图展示了单词意义的可视化,同时保持了其可读性。我们提出了一种自动创建“字即图”插图的方法。这项任务极具挑战性,因为它需要对单词的语义理解以及如何在视觉上令人愉悦且清晰地描绘这些语义的创造性想法。我们依赖于最近大型预训练语言-视觉模型的卓越能力,将文本概念视觉化。我们专注于简单、简洁、黑白的设计,以清晰地传达语义。我们故意不改变字母的颜色或纹理,也不使用装饰。我们的方法通过预训练的Stable Diffusion模型指导,优化每个字母的轮廓以传达所需的概念。我们还加入了额外的损失项,以确保文本的可读性和字体风格的保留。我们在众多示例中展示了高质量且引人入胜的结果,并与其他技术进行了比较。

图1. 我们的“字即图”插图在不同字体和不同文本概念中的几个示例。这些语义调整的字母完全通过我们的方法自动创建,然后可以像我们在这里展示的那样用于进一步的创意设计。
引言
语义排版是使用排版来视觉上强化文本意义的做法。这可以通过选择字体、字体大小、字体样式和其他排版元素来实现。更复杂和引人入胜的语义排版技术是通过“字即图”插图来呈现的,其中仅使用字母的图形元素来展示给定单词的语义。这种插图提供了单词意义的视觉表示,同时保持了整个单词的可读性。
创建“字即图”的任务极具挑战性,因为它需要理解并描绘给定概念的视觉特性,并以简洁、美观和可理解的方式传达这些特性,同时不损害可读性。将选定的视觉概念融入字母形状中需要大量的创造力和设计技巧(Lee, 2011)。在图2中,我们展示了一些手动创建的“字即图”示例。例如,要创建“jazz”(爵士乐)的插图,设计师首先需要选择最符合文本语义的视觉概念(如萨克斯管),考虑所需的字体特性,然后选择最合适的字母进行替换。找到正确的视觉元素来说明一个概念是不明确的,因为有无数种方式来说明任何给定的概念。此外,不能简单地将选定的视觉元素复制到单词上——需要找到字母形状的微妙修改。
由于这些复杂性,直到最近,自动创建“字即图”插图的任务在计算机上几乎是不可能实现的。在本文中,我们定义了一个基于深度学习最新进展和结合语言和视觉理解的巨大基础模型的可用性来自动创建“字即图”插图的算法。我们的结果插图(见图1)可以用于标志设计、标志、贺卡和邀请函,以及仅仅为了娱乐。它们可以按原样使用,或者作为进一步设计细化的灵感。
文本风格化领域的现有方法通常依赖于光栅纹理(Yang et al., 2018),在笔画分割上放置手动创建的风格(Berio et al., 2022),或者将文本变形为预定义的目标形状(Zou et al., 2016)(见图3)。只有少数作品(Tendulkar et al., 2019;Zhang et al., 2017)处理语义排版,并且它们通常在光栅域中操作,并使用现有的图标进行替换(见图3E)。
我们的“字即图”插图专注于仅改变字母的几何形状来传达意义。我们故意不改变颜色或纹理,也不使用装饰。这允许简单、简洁、黑白的设计,清晰地传达语义。此外,由于我们保留了字母的矢量表示,这允许在任何大小下平滑地光栅化,以及如果需要,使用颜色和纹理对插图应用额外的风格操作。

图2. 手动创建的“字即图”插图
给定一个输入词,我们的方法分别对每个字母进行处理,允许用户稍后选择最喜爱的组合进行替换。我们把每个字母表示为封闭的向量形状,并优化其参数以反映单词的含义,同时仍然保留其原始风格和设计。
我们依赖于预训练的Stable Diffusion模型(Rombach等人,2021年)来连接文本和图像,并利用Score Distillation Sampling方法(Poole等人,2022年)(见第3节)来鼓励字母的外观反映提供的文本概念。由于Stable Diffusion模型是在光栅图像上训练的,我们使用了一个可微分的光栅器(Li等人,2020年),它允许从光栅基础的损失向形状的参数反向传播梯度。
为了保留原始字母的形状并确保单词的可读性,我们使用了两个额外的损失函数。第一个损失通过约束变形尽可能地与字母形状的三角剖分保持一致来调节形状修改。第二个损失通过比较结果的光栅化字母与原始字母的低通滤波器来保留字母的局部色调和结构。
我们与几个基线进行了比较,并使用了多种字体和大量概念展示了大量结果。我们的单词作为图像插图传达了预期的概念,同时保持了可读性并保留了字体的外观,展示了视觉创意。
相关工作
文本风格化
文本风格化的一种方法是艺术文本风格迁移,其中将给定源图像的风格迁移到所需文本中(如图3A所示)。为了解决这一任务,现有作品结合了基于补丁的纹理合成(Yang等人,2017年;Fish等人,2020年)以及GAN的变体(Azadi等人,2018年;Wang等人,2019年;Jiang等人,2019年;Yang等人,2022年;Mao等人,2022年)。这些作品在光栅域内操作,这是一种对于排版师来说不理想的数据格式,因为字体必须是可缩放的。相比之下,我们在字母的参数轮廓上操作,我们的字形操作是由单词的语义含义引导的,而不是由预定义的风格图像引导的。

图3.以前文本风格化作品的示例 - (A)Yang等人(2018年),(B)Berio等人(2022年),(C)Zhang等人(2017年),(D)Zou等人(2016年),以及(E)Tendulkar等人(2019年)。大多数使用颜色和纹理或将图标复制到字母上。我们的工作集中在字母的微妙几何形状变形上,以传达语义含义,而不使用颜色或纹理(这可以稍后添加)。
一些作品(Ha和Eck,2018年;Lopes等人,2019年;Wang和Lian,2021年)处理字体生成和风格化的任务,在矢量领域进行。通常,构建字体轮廓的潜在特征空间,表示为轮廓样本(Campbell和Kautz,2014年;Balashova等人,2019年)或参数曲线段(Ha和Eck,2018年;Lopes等人,2019年;Wang和Lian,2021年)。这些方法通常仅限于轻微偏离输入数据。其他方法依赖于模板(Suveeranont和Igarashi,2010年;Lian等人,2018年)或用户指导(Phan等人,2015年)和自动(Berio等人,2022年)笔划分割来生成字母风格化(如图3B所示)。然而,它们依赖于手动定义的风格,而我们依赖于稳定扩散的表现力来指导字母形状的修改,以传达所提供单词的含义。
在生成拼字画的任务中(Zou等人,2016年;Xu和Kaplan,2007年),整个单词被变形为给定的目标形状。这项任务优先考虑形状而非单词的可读性(见图3D),与我们的工作本质不同,因为我们使用单词的语义来推导单个字母的变形。
与我们的目标最相关的,是执行文本的语义风格化的作品。Tendulkar等人(2019年)将给定单词中的字母替换为描述给定主题的剪贴画图标(见图3E)。为了选择最合适的图标进行替换,使用自动编码器来测量字母与所需类别图标之间的距离。同样,Zhang等人(2017年)将一个或多个字母的类似笔划部分替换为剪贴画实例,以生成装饰性风格化。图3C展示了一个例子。这些方法在光栅领域操作,并用现有图标替换字母,这限制了它们到数据集中存在的预定义类别集。
然而,我们的方法在矢量领域操作,并结合了大型预训练的图像-语言模型的表现力,创建传达所需概念的新插图。
大型语言-视觉模型 随着语言-视觉模型(Radford等人,2021年)和扩散模型(Ramesh等人,2022年;Nichol等人,2021年;Rombach等人,2021年)的最近进展,图像生成和编辑领域经历了前所未有的发展。这些模型经过数百万图像和文本对的训练,已被证明有效地执行挑战性的视觉相关任务,如图像分割(Amit等人,2021年)、领域适应(Song等人,2022年)、图像编辑(Avrahami等人,2022年;Hertz等人,2022年;Tumanyan等人,2022a年)、个性化(Ruiz等人,2022年;Gal等人,2023年,2022年)和可解释性(Chefer等人,2021年)。尽管它们在光栅图像上进行训练,它们强大的视觉和语义先验也已成功应用于其他领域,如运动(Tevet等人,2022年)、网格(Michel等人,2021年)、点云(Zhang等人,2021年)和矢量图形。
CLIPDraw(Frans等人,2021年)使用可微分光栅化器(Li等人,2020年)优化一组彩色曲线,由CLIP的图像-文本相似性度量指导,针对给定的文本提示。Tian和Ha(2021年)结合CLIP指导使用进化算法创建基于文本的抽象视觉概念。其他作品(Vinker等人,2022b, a)利用CLIP的图像编码器从图像生成抽象矢量草图。
扩散模型已用于文本引导的图像到图像翻译任务(Choi等人,2021年;Tumanyan等人,2022b年)。在SDEdit(Meng等人,2022年)中,向参考图像添加适量的噪声,以保持其整体结构,然后在引导文本的反向过程中对图像进行去噪。预训练的扩散模型还用于生成3D对象(Poole等人,2022年;Metzer等人,2022年)或基于文本的矢量艺术(Jain等人,2022年)。
在我们的工作中,我们也利用预训练的稳定扩散模型(Rombach等人,2021年)强大的视觉和语义先验,但用于语义排版的任务。为此,我们在优化过程中添加了新的组件,以保持字体的风格和文本的可读性。

图4.我们方法产生的更多文字作为图像。注意,通过语义修改,不同字体的风格是如何被保留的。
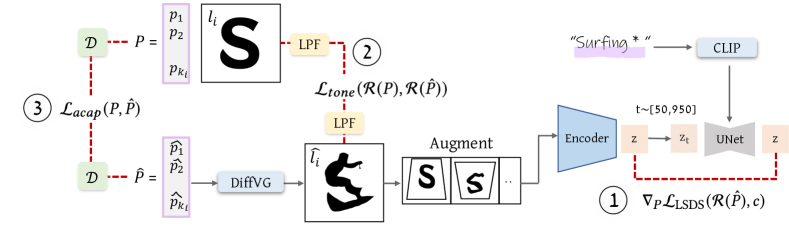
图5.我们方法的概述。给定一个由控制点集合P表示的输入字母li,以及一个概念(以紫色显示),我们迭代地优化变形字母li的新位置P。在每次迭代中,集合P被输入到一个可微分的光栅器(DiffVG标记为蓝色),该光栅器输出光栅化的变形字母li。然后,li被增强并通过一个预训练的冻结的稳定扩散模型传递,该模型使用∇PLSDS损失(1)驱动字母形状传达语义概念。li和li也被通过一个低通滤波器(LPF标记为黄色)传递,以计算Ltone(2),这鼓励保留字体风格的整体色调和局部字母形状。此外,集合P和P通过一个Delaunay三角剖分算子(D标记为绿色)传递,定义Lacap(3),这鼓励保留初始形状。
背景
3.1.字体与向量表示
现代字体格式,如TrueType(Penney,1996)和PostScript(Inc.,1990),使用向量化的轮廓表示来表示字形。具体来说,轮廓通常由一系列线条和贝塞尔或B样条曲线表示。这种表示方法允许以任何所需尺寸缩放字母并进行光栅化,类似于其他向量表示。我们的方法保留了这一属性,因为我们的输出保留了字母的向量化表示。
3.2.潜在扩散模型
扩散模型是一种生成模型,通过从高斯分布中采样的变量的逐渐去噪过程来学习数据分布。
在我们的工作中,我们使用了公开的文本到图像的稳定扩散模型(Rombach等人,2021)。稳定扩散是一种潜在扩散模型(LDM),其中扩散过程在预训练图像自动编码器的潜在空间中进行。编码器ℰ的任务是将输入图像x映射到潜在向量z,而解码器𝒟被训练为解码z,使得𝒟(z)≈x。
作为第二阶段,训练了一个去噪扩散概率模型(DDPM)(Ho等人,2020)以在学习的潜在空间中生成代码。在训练的每一步中,都会均匀采样一个标量t∈{1,2,…,T}并用于定义一个噪声的潜在代码zt=αt z+σt ϵ,其中ϵ∼𝒩(0,I),而αt,σt是控制噪声时间表的项,是扩散过程时间t的函数。
基于UNet架构(Ronneberger等人,2015)的去噪网络ϵθ接收作为输入的噪声代码zt,时间步t和一个可选的条件向量c(y),并负责预测添加的噪声ϵ。LDM损失定义为:
(1)ℒLDMM=𝔼z∼ℰ(x),y,ϵ∼𝒩(0,1),t[‖ϵ−ϵθ(zt,t,c(y))‖22].
在稳定扩散中,对于文本到图像的生成,条件向量是预训练的CLIP文本编码器(Radford等人,2021)产生的文本嵌入。在推理时,随机采样一个潜在代码zT∼𝒩(0,I),并通过训练的ϵθ迭代去噪,直到产生一个干净的z0潜在代码,该代码通过解码器𝒟生成图像x。
3.3.分数蒸馏
利用预训练的大文本图像模型的强先验来生成除光栅化图像之外的其他模态是可取的。在稳定扩散中,文本条件是通过在UNet网络中定义的不同分辨率的交叉注意力层进行的。因此,使用条件扩散模型引导优化过程并不简单。
DreamFusion(Poole等人,2022)提出了一种使用扩散损失来优化NeRF模型参数的方法,用于文本到3D生成。在每次迭代中,从一个随机角度渲染辐射场,形成图像x,然后将其噪声化形成xt=αt x+σt ϵ。然后将噪声图像传递给Imagen的预训练UNet模型(Saharia等人,2022),该模型输出噪声预测ϵ。分数蒸馏损失由原始扩散损失的梯度定义:
(2)∇ϕℒSDS=[w(t)(ϵθ(xt,t,y)−ϵ)∂x∂ϕ]
其中y是条件文本提示,ϕ是NeRF的参数,w(t)是依赖于αt的常数乘数。在训练过程中,梯度被反向传播到NeRF参数,以逐渐改变3D对象以适应文本提示。请注意,UNet的梯度被跳过,直接从LDM损失导出的梯度用于修改Nerf的参数。
3.4.VectorFusion
最近,VectorFusion(Jain等人,2022)利用SDS损失来完成文本到SVG生成的任务。提出的生成流程包括两个阶段。给定一个文本提示,首先使用稳定扩散(在提示中添加后缀)生成图像,然后使用LIVE(Ma等人,2022)自动将其向量化。这定义了在第二阶段使用SDS损失进行优化的初始参数集。在每次迭代中,使用可微分的光栅器(Li等人,2020)生成600×600图像,然后按照CLIPDraw(Frans等人,2021)的建议进行增强,以获得512×512图像xaug。然后xaug被输入到稳定扩散的预训练编码器ℰ中,以产生相应的潜在代码z=ℰ(xaug)。然后在潜在空间中应用SDS损失,与DreamFusion中定义的方式类似:
(3)∇θℒLSDS=𝔼t,ϵ[w(t)(ϵ^ϕ(αtzt+σtϵ,y)−ϵ)∂z∂z aug ∂xaug ∂θ]
我们发现SDS方法对我们产生语义字形的任务很有用,并且我们遵循VectorFusion中提出的步骤(例如增强和添加后缀)。
方法
给定一个由n个字母{l1, …, ln}组成的单词W,我们的方法将分别应用于每个字母li,以产生字母的语义视觉描述。用户可以选择替换哪些字母,保留哪些字母的原始形式。
4.1. 字母表示
我们首先定义单词W中字母的参数化表示。我们使用FreeType字体库(FreeType, 2009)来提取每个字母的轮廓。然后将每个轮廓转换成一组三次贝塞尔曲线,以便在不同的字体和字母之间保持一致的表示,并便于使用diffvg(Li et al., 2020)进行可微光栅化。
根据字母的复杂性和字体的风格,提取的轮廓由不同数量的控制点定义。我们发现初始的控制点数量显著影响最终的外观:随着控制点数量的增加,视觉变化的自由度也随之增加。因此,我们还对包含少量控制点的字母应用了细分过程。我们为每个字母定义了一个期望的控制点数量(在不同的字体之间共享),然后迭代地细分贝塞尔段,直到达到这个目标数量。在每次迭代中,我们计算所有贝塞尔段中的最大弧长,并将每个段的这个长度分成两部分(见图6)。我们在第5.3节分析控制点数量的影响。
这个过程定义了一组ki控制点Pi={pj}j=1ki,代表字母li的形状。
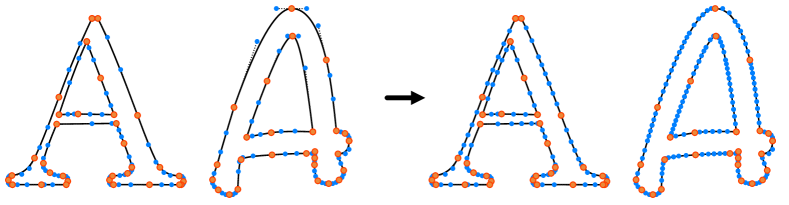
图6. 字母轮廓和控制点在细分过程前(左)和后(右)的示意图。橙色点是初始Bézier曲线段的端点。蓝色点分别是细分前后剩余的控制点。
4.2.优化
我们的方法的流程如图5所示。由于我们是单独优化每个字母𝑙𝑖,为了简洁起见,在接下来的文本中我们将省略字母索引𝑖,并将输入字母的控制点集合定义为𝑃。
给定𝑃和期望的文本概念𝑐(图5中都用紫色标记),我们的目标是产生一个新的控制点集合𝑃,定义一个调整过的字母𝑙,该字母传达给定的概念,同时保持初始字母𝑙的整体结构和特征。
我们将学习得到的控制点集合𝑃初始化为p,并将其传递给一个可微分的光栅器ℛ((Li等人,2020年)(用蓝色标记),该光栅器输出光栅化的字母ℛ(𝑃)。然后将光栅化的字母随机增强,并传递给一个预训练的Stable Diffusion模型(Rombach等人,2021年),该模型以CLIP的文本嵌入𝑐为条件。然后使用第3节中描述的SDS损失∇𝑃ℒLSDS(如第3节所述)来鼓励ℛ(𝑃)传达给定的文本提示。
为了保持每个字母的形状并确保整个单词的可读性,我们使用两个额外的损失函数来指导优化过程。第一个损失限制了整体形状变化,通过定义尽可能保形的形状变形约束。第二个损失通过限制修改后的字母的色调(即形状局部部分的明暗区域的量)不与原始字母相差太大,来保持整体形状和字体风格(见第4.3节)。
然后将所有损失得到的梯度反向传播,以更新参数𝑃^。我们重复这个过程500步,这在RTX2080 GPU上大约需要5分钟来生成单个字母的插图。
4.3.损失函数
我们的主要目标是鼓励生成的形状传达预定的语义概念,这是通过∇𝑃ℒLSDS损失实现的(如第3节所述)。我们观察到仅使用∇𝑃ℒLSDS可能会导致与初始字母外观的较大偏差,这是不希望的。会导致与初始字母外观的较大偏差,这是不希望的。因此,我们的另一个目标是保持字母ℛ(𝑃^)的形状和可读性,以及保持原始字体的特性。为此,我们使用了两个额外的损失。
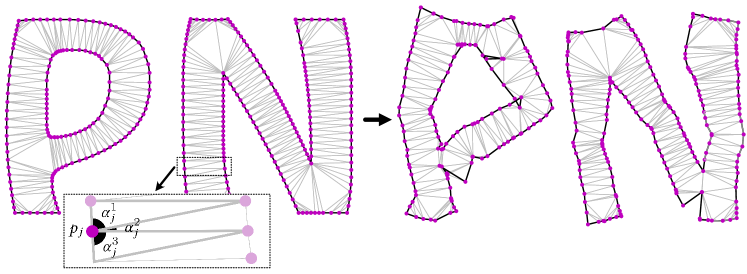
图7.约束Delaunay三角剖分的可视化示例,应用于初始形状(左)和结果形状(右),用于单词“pants”。ACAP损失保持了变形后字母的结构。放大矩形显示了给定控制点pj的角度。
尽可能接近的变形损失(As-Conformal-As-Possible Deformation Loss)
为了防止最终的字母形状与初始形状偏离太多,我们对字母的内部部分进行三角剖分,并尽可能地约束字母的变形为共形(ACAP)(Hormann和Greiner,2000)。我们使用约束Delaunay三角剖分(Delaunay等人,1934;Barber和Huhdanpaa,1995)对定义字形的控制点集进行操作。众所周知,Delaunay三角剖分可以用来产生轮廓的骨架(Prasad,1997;Zou等人,2001),因此ACAP损失也隐式地捕捉了字母形状的骨架表示。
Delaunay三角剖分𝒟§将由𝑃表示的字形分割成一组三角形。这定义了每个控制点pj的相应角度集合mj(见图7)。我们用{𝛼𝑗𝑖}𝑖=1𝑚𝑗表示这组角度。ACAP损失鼓励优化形状𝑃^的诱导角度不要与原始形状𝑃的角度相差太大,并定义为相应角度之间的L2距离:
(4) ℒ𝑎𝑐𝑎𝑝(𝑃,𝑃)=1𝑘∑𝑗=1𝑘(∑𝑖=1𝑚𝑗(𝛼𝑗𝑖−𝛼𝑗𝑖)2)
其中𝑘=|𝑃|,𝛼是由𝒟(𝑃)诱导的角度。
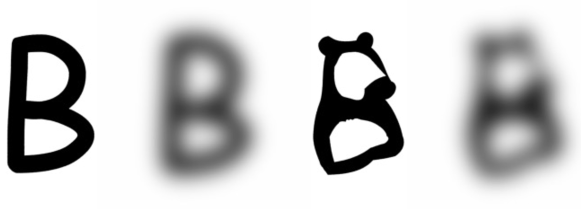
图8.我们的色调保持损失通过比较字母图像在变形前后(左图和右图)的低通滤波器来保持字体的局部色调。它限制了调整后的字母与原始字母的色调偏差不会太大。这个例子是字母B和单词“Bear”。
色调保持损失
为了保持字体的风格以及字母的结构,我们添加了一个局部色调保持损失项。这个项限制了调整后的字母的色调(形状中黑色与白色的比例)与原始字体字母的色调不会偏差太大。为此,我们对光栅化的字母(变形前后)应用低通滤波器(LPF),并计算得到的模糊字母之间的L2距离:
(5) ℒ𝑡𝑜𝑛𝑒=‖𝐿𝑃𝐹(ℛ(𝑃))−𝐿𝑃𝐹(ℛ(𝑃^))‖2
图8展示了模糊字母的例子,可以看出,我们在模糊核中使用了较高的标准差σ来模糊掉如熊耳朵等小细节。
我们的最终目标是通过以下加权平均三个项来定义:
(6) min𝑃∇𝑃ℒLSDS(ℛ(𝑃),𝑐)+𝛼⋅ℒ𝑎𝑐𝑎𝑝(𝑃,𝑃)+𝛽𝑡⋅ℒ𝑡𝑜𝑛𝑒(ℛ(𝑃),ℛ(𝑃^))
其中𝛼=0.5,𝛽𝑡取决于步骤𝑡,如下所述。
4.4.权重
选择上述三个损失项的相对权重对于最终字母的外观至关重要。虽然∇𝑃^ℒLSDS损失鼓励形状偏离其原始外观以更好地适应语义概念,但两个项ℒ𝑡𝑜𝑛𝑒和ℒ𝑎𝑐𝑎𝑝负责保持原始形状。因此,我们在公式中有两个相互竞争的部分,并希望找到它们之间的平衡,以保持字母的可读性,同时允许所需的语义形状发生变化。
我们发现ℒ𝑡𝑜𝑛𝑒可能非常占主导地位。在某些情况下,如果从一开始就使用它,就不会进行语义变形。因此,我们调整了ℒ𝑡𝑜𝑛𝑒的权重,使其仅在发生了一些语义变形之后才开始起作用。我们定义𝛽𝑡:
(7) 𝛽𝑡=𝑎⋅exp(−(𝑡−𝑏)2/2𝑐2) 其中𝑎=100,𝑏=300,𝑐=30。
我们在第5.3节分析了不同权重的影响。请注意,相同的超参数选择适用于各种单词、字母和字体。
 图9. 使用我们的方法为“YOGA”这个词生成的字形图像,使用了八种不同的字体。
图9. 使用我们的方法为“YOGA”这个词生成的字形图像,使用了八种不同的字体。
结果
我们的方法的鲁棒性意味着它应该能够处理各种输入概念以及支持不同的字体设计。图1、4、33、17以及补充文件中的更多结果表明,我们的方法可以处理来自许多不同类别的输入和各种字体,并且生成的结果是可读的和有创意的。图9展示了我们的方法为同一单词创建的插图遵循不同字体的特性。虽然字形图像的审美感知可能是主观的,但我们为一个有效的结果定义了三个目标:(1)它应该视觉上捕捉给定的语义概念,(2)它应该保持可读性,(3)它应该保留原始字体的特性。
我们评估了我们的方法在一组随机选择的输入上的表现。我们选择了五个常见的概念类别——动物、水果、植物、运动和职业。使用ChatGPT,我们为每个类别随机抽取了十个实例,总共产生了50个单词。接下来,我们选择了四种具有明显视觉特征的字体,即Quicksand、Bell MT、Noteworthy-Bold和HobeauxRococeaux-Sherman。对于每个单词,我们随机抽取了这四种字体中的一种,并将我们的方法应用于每个字母。对于每个有n个字母的单词,我们可以生成2^n个可能的字形图像,这些都是所有字母替换插图的可能组合。图33中展示了这些结果的一个选定子集。所有字母和单词的结果都展示在补充材料中。
如图所示,大多数情况下,生成的字形图像成功地传达了给定的语义概念,同时仍然保持可读性。此外,我们的方法成功地捕捉了字体特性。例如,在图33中,“DRESS”和“LION”的替换是细长的,并且与单词的其余部分很好地融合。此外,观察到在“SHARK”示例中用于鲨鱼鳍的字母A的衬线。我们进一步使用人类评估来验证这一点,如下所述。
5.1. 定量
我们进行了一项感知研究,以定量评估我们生成的字形图像的三个目标。我们从上述五个类别中随机选择每个类别两个实例的结果,并从每个单词中视觉上选择一个字母,总共产生了10个字母。在每个问题中,我们展示了一个孤立的字母插图,没有单词的上下文。为了评估我们的方法在视觉上描绘所需概念的能力,我们展示了来自同一类别的四个标签选项,并要求参与者选择最能描述字母插图的一个。为了评估结果的可读性,我们要求参与者从一个随机的四个字母列表中选择最合适的字母。为了评估字体风格的保留,我们展示了四种字体,并要求参与者为插图选择最合适的字体。我们从40名参与者那里收集了答案,结果如表1所示。如图所示,概念识别和字母可读性的水平非常高,字体风格匹配的51%远高于随机的25%。我们还测试了在相同的单词和字母上不使用两个额外的结构和风格保留损失(ℒ𝑎𝑐𝑎𝑝和ℒ𝑡𝑜𝑛𝑒)的算法(表中的“Only SDS”)。正如预期的那样,没有额外的约束,字母会显著变形,导致更高的概念识别率,但可读性和字体风格保留较低。更多细节和示例在补充材料中提供。
表1. 感知研究结果。概念识别和字母可读性的水平非常高,字体风格匹配远高于随机。通过移除我们的结构和风格保留损失得到的“Only SDS”结果。
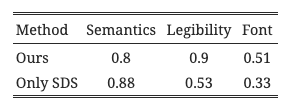

图10.基于大型文本到图像模型的替代方法比较。左侧是作为输入的字母(仅用于SDEdit、CLIPDraw和我们的方法),以及所关注的对象。从左到右的结果分别使用了Stable Diffusion(Rombach等人,2021年)、SDEdit(Meng等人,2022年)、DallE2(Ramesh等人,2022年)、特定字母提示的DallE2、CLIPDraw(Frans等人,2021年),以及我们的单字母结果,还有最终的单词作为图像。
5.2.比较
在没有相关基线进行比较的情况下,我们基于大型流行文本到图像模型定义了基线。具体来说,我们使用了(1)SD Stable Diffusion(Rombach等人,2021年)、(2)SDEdit(Meng等人,2022年)、(3)DallE2(Ramesh等人,2022年)展示单词、(4)DallE2+字母仅展示字母、(5)CLIPDraw(Frans等人,2021年)。我们应用了上述方法(详细信息可以在补充材料中找到)来处理三个代表性的单词——“bird”(鸟)、“dress”(裙子)和“tulip”(郁金香),分别使用了Bell MT、Quicksand和Noteworthy-Bold字体。结果如图10所示。
在某些情况下,Stable Diffusion(SD)无法生成文本(例如对于鸟),即使生成了文本,通常也不易辨认。SDEdit的结果保留了字体的特性以及字母的可读性,但往往无法反映期望的概念,例如鸟和裙子的情况。此外,它在光栅域中操作,并倾向于在字母上添加细节,而我们的方法直接在字母的矢量表示上操作,目的是修改它们的形状。DallE2能够反映视觉概念,但往往无法生成易读的文本。当应用特定提示仅生成一个字母的单词作为图像时(第五列),它能够生成易读的字母,但对输出的控制较少——无法指定期望的字体,也无法控制生成字母的大小、位置和形状。因此,不清楚如何将这些输出插图组合成整个单词,以创建单词作为图像。
CLIPDraw产生合理的结果,传达输入单词的语义。然而,结果不平滑,字体的特性没有保留(例如观察字母“E”与输入字母的不同)。我们在下一节进一步检查了带有我们形状保留损失的CLIPDraw。
5.3.消融研究
图11展示了字母初始控制点数量的影响。当使用较少的控制点(Po是原始控制点数量)时,我们可能会得到不足的变化,例如对于大猩猩。但这也可以导致更抽象的描述,例如芭蕾舞者。当我们添加控制点时,我们得到了更多的图形结果,但代价是它通常偏离原始字母。在图15中,我们展示了仅使用∇P^ℒLSDS损失的结果。如图所示,在这种情况下,插图强烈传达了语义概念,但代价是可读性。在图16中,我们分析了应用于ℒacap的权重α的影响。范围从1到0。当ℒacap过于主导时,结果可能不足以反映语义概念,而相反的情况则损害了可读性。图13展示了低通滤波器参数σ的变化。当σ=1几乎不应用模糊,导致形状约束过于严格。
在图14中,我们展示了用CLIP基于的损失替换∇P^ℒLSDS损失的结果,同时使用了我们提出的形状保留项。尽管使用CLIP得到的结果通常描绘了期望的视觉概念,但我们发现使用Stable Diffusion可以得到更平滑的插图,捕捉更广泛的语义概念。
通过使用论文中描述的超参数,我们能够在语义和可读性之间实现合理的平衡。这些参数是基于视觉评估手动确定的,但可以根据用户的个人喜好和目标进行调整。

图11. 初始控制点数量对输出的影响。左侧是用于生成右侧结果的输入字母和目标概念。
𝑃𝑜表示从字体中提取的原始控制点数量,𝑃是我们选择的超参数下的输入字母,对于2×𝑃我们将𝑃中的控制点数量增加两倍。
6. 结论
我们提出了一种自动创建矢量格式的单词作为图像插图的方法。我们的方法可以处理各种语义概念,并使用任何字体,同时保持文本的可读性和字体风格。
我们的方法存在一些局限性。首先,我们的方法逐字母工作,因此无法变形整个单词的形状。未来我们可以尝试优化几个字母的形状。其次,该方法最适合具体视觉概念,对于更抽象的概念可能会失败。这可以通过使用与单词本身不同的概念来优化字母形状来缓解。第三,字母的布局也可以自动化,例如,使用(Wang et al., 2022)等方法。
我们的单词作为图像插图展示了视觉创意,并为使用大型视觉语言模型进行语义排版的可能性打开了大门,可能还会添加人类在循环中,以达到机器学习模型与人类更协同的设计方法。

图12. 我们方法生成的单词图像。这个子集是从随机单词集合中选取的。

图13. 调整低通滤波器中使用的参数σ,用于计算损失函数ℒ𝑡𝑜𝑛𝑒。最左边一列是原始字母和概念,然后从左到右是使用σ∈{1,5,30,200}时得到的结果,以及没有使用ℒ𝑡𝑜𝑛𝑒的情况。
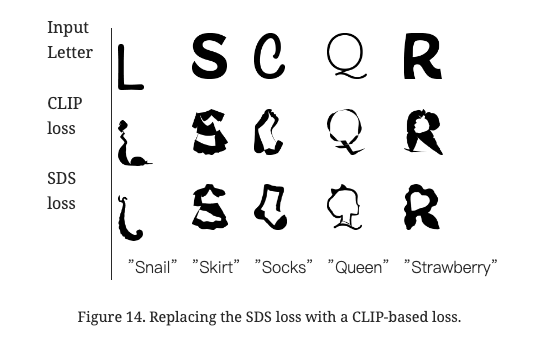
图14.用基于CLIP的损失替换SDS损失。

图15.仅使用SDS损失的效果:注意第三行看起来仅像图标插图,而第二行仍然类似于可读的字母。

图16.调整ℒ𝑎𝑐𝑎𝑝损失的权重𝛼。最左侧列为使用的原始字母和概念,然后从左到右分别是使用𝛼∈{1, 0.75, 0.5, 0.25, 0}时获得的结果。

图17.我们方法产生的额外结果。
- 致谢
我们感谢Richard Hao Zhang就文本作为图像问题的早期讨论。感谢Ali Mahdavi-Amiri和Oren Katzir审阅了文稿的早期版本,并感谢Anran Qi协助评估中文词汇。本研究得到了以色列科学基金会的部分支持(资助编号2492/20和3441/21),Len Blavatnik和Blavatnik家族基金会,以及特拉维夫大学创新实验室(TILabs)的支持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









