









关于配置使用sparklyr和Pyspark的相关记录
- 基本准备:windows 10系统。已经安装好Anaconda 并配置了基于python3的jupyter notebook(这个是在Anaconda里面直接可以用)。
已经安装好Rgui和Rstudio - 为了实现并行计算,搭建可以用于R语言与Python的spark环境
第一,参考以下博客安装JDK,Scala,Spark,Hadoop
链接: Spark学习笔记–Spark在Windows下的环境搭建
在该博客中一直到hadoop安装完成都可以按照步骤来,应该没有什么大问题。其中JDK下载jdk8u版本
,spark下载spark3.的版本。
注意,博客中提到的winutil.exe文件一定要按照那里面去配置,之后都要用到的
第二,使用sparklyr在R语言环境中操作spark
配置完winutil.exe和相关的权限修改之后就可以用sparklyr在R语言环境中(这里用的Rstudio编辑器)中操作spark了。
按照以下截图中的代码命令,连接spark,就可以进行相关的并行计算工作了
# 导入需要的程序包
library(dplyr)
library(pryr)
# 加载sparklyr包
library(sparklyr)
# 设置Spark的安装路径
Sys.setenv(SPARK_HOME = "D:\\2020sparkxilie\\spark1226\\spark-3.0.1-bin-hadoop2.7")
# 连接本地Spark
spark_conn <- spark_connect(master="local",spark_home = Sys.getenv("SPARK_HOME"))
# 打印Spark的版本
spark_version(sc = spark_conn)
# 断开与Spark的连接
spark_disconnect(sc = spark_conn)

结束并行计算后,断开spark的连接,按照以下截图代码。注意,spark连接速度较慢,一般情况下不随便断开,只有在完成工作后才断开

第三,配置Pyspark环境
还是继续上面的那个博客,完成将spark目录下的pyspark文件复制到python的安装目录下的C:\Python\Python35\Lib\site-packages;如果这里没有手动安装python,而是直接安装了Anaconda,那就把pyspark文件夹复制到Anaconda下的site-packages文件下,D:\2020Anaconda\anaconda3\Lib\site-packages
然后在本机的cmd中用pip install py4j安装py4j库。因为我用的是jupyter notebook就没有按照上述博客中配置那个路径。cmd打开方式如下

第四,在jupyter notebook中使用pyspark
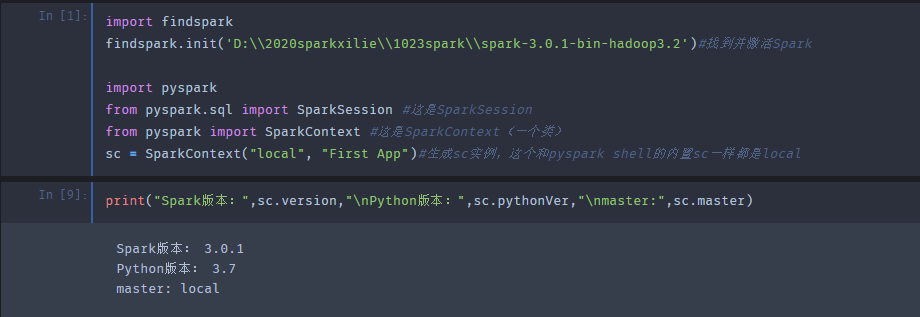
import findspark
findspark.init('D:\\2020sparkxilie\\1023spark\\spark-3.0.1-bin-hadoop3.2')#找到并激活Spark
import pyspark
from pyspark.sql import SparkSession #这是SparkSession
from pyspark import SparkContext #这是SparkContext(一个类)
sc = SparkContext("local", "First App")#生成sc实例,这个和pyspark shell的内置sc一样都是local
#打印版本信息
print("Spark版本:",sc.version,"\nPython版本:",sc.pythonVer,"\nmaster:",sc.master)
执行第一个代码块的时候遇到了三个问题,在此记录以下解决方案:
- ①运行时显示找不到findspark模块,这个好像不是Anaconda里面自带的包吧,所以得自己手动安装一下。我是从github上面下载的: findspark模块在github上的下载地址.参照我之前写的一个博客进行下载配置即可: 在jupyter notebook中安装使用github上面的python包.
- ②运行findspark.init这行代码的时候,我最开始写的是findspark.init()然后就一直显示错误
Couldn’t find Spark, make sure SPARK_HOME env is set or Spark is in an expected。然后我以为是按照之前的博客去系统变量里面配置SPARK_HOME路径,就像配置HADOOP_HOME一样,结果配了也没什么毛线作用5555。那就按照下面截图的样子在findspark.init()里面添加路径,就是之前安装的那个spark-3.0.1-bin-hadoop3.2文件所在的位置。然后,就成了! - ③再次运行,发现在sc = SparkContext(“local”, “First App”)这一句的时候又会报错,=-=,大概报错内容就是
Cannot run multiple SparkContexts at once; existing SparkContext(app=First A。然后呢这个好像是因为运行了两次SparkContext才产生的错误,关于解决,我是把jupyter notebook 关了再重新打开,然后运行第一个代码框就没问题不要运行两次。或者网上还有一种方式,就是在每次运行SparkContext之前先删掉之前的记录。
参考博客 解决SparkContexts报错的问题.链接: 看这个博客回答3














 2042
2042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









