






Series是一维表格,每个元素带标签且有下标,兼具列表和字典的访问形式
import pandas as pd
s = pd.Series(data=[80,90,100],index=['语文','数学','英语'])
for x in s: #>>80 90 100
print(x,end=" ")
print("")
print(s['语文'],s[1]) #>>80 90 标签和序号都可以作为下标来访问元素
print(s[0:2]['数学']) #>>90 s[0:2]是切片
print(s['数学':'英语'][1]) #>>100
for i in range(len(s.index)): #>>语文 数学 英语
print(s.index[i],end = " ")
s['体育'] = 110 #在尾部添加元素,标签为'体育',值为110
s.pop('数学') #删除标签为'数学’的元素
s2 = s.append(pd.Series(120,index = ['政治'])) #不改变s
print(s2['语文'],s2['政治']) #>>80 120
print(list(s2)) #>>[80, 100, 110, 120]
print(s.sum(),s.min(),s.mean(),s.median())#输出和、最小值、平均值、中位数
print(s.idxmax(),s.argmax()) #>>体育 2 输出最大元素的标签和下标DataFrame是带行列标签的二维表格,的每一列都是一个Series
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
#输出对齐方面的设置
scores = [['男',108,115,97],['女',115,87,105],['女',100,60,130],
['男',112,80,50]]
names = ['张三','李四','王五','赵六']
courses = ['性别','语文','数学','英语']
df = pd.DataFrame(data=scores,index = names,columns = courses)
print(df)
print(df.values[0][1],type(df.values))#>>108 <class 'numpy.ndarray'>
print(list(df.index)) #>>['张三', '李四', '王五', '赵六']
print(list(df.columns)) #>>['性别', '语文', '数学', '英语']
print(df.index[2],df.columns[2]) #>>王五 数学
s1 = df['语文'] #s1是个Series,代表'语文'那一列
print(s1['张三'],s1[0]) #>>108 108 张三语文成绩
print(df['语文']['张三']) #>>108 列索引先写
s2 = df.loc['李四'] #s2也是个Series,代表“李四”那一行
print(s2['性别'],s2['语文'],s2[2])
#>>女 115 87 李四的性别、语文和数学分数
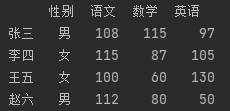
DataFrame的切片:
行切片:
#DataFrame的切片:
#iloc[行选择器, 列选择器] 用下标做切片
#loc[行选择器, 列选择器] 用标签做切片
#DataFrame的切片是视图
df2 = df.iloc[1:3] #行切片,是视图,选1,2两行
df2 = df.loc['李四':'王五'] #和上一行等价
print(df2)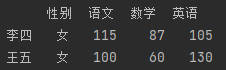
列切片:
df3 = df.iloc[:,0:3] #列切片(是视图),选0、1、2三列
df3= df.loc[:,'性别':'数学'] #和上一行等价
print(df3)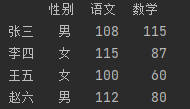
行列切片:
df4 = df.iloc[:2,[1,3]] #行列切片
df4 = df.loc[:'李四',['语文','英语']] #和上一行等价
print(df4) 
行列切片:
df5 = df.iloc[[1,3],2:4] #取第1、3行,第2、3列
df5 = df.loc[['李四','赵六'],'数学':'英语'] #和上一行等价
print(df5)















 6851
6851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









