







输入一本英文书,找出其中最长的完全重复的字符串。一本书可能有几十上百万的字符,按顺序能够组成的字符串可定比这本书包含的字符高几个数量级(考虑字符串的长度、开始取子字符串的位置变化),所以想要用暴力遍历基本上是不可能完成的,然而使用后缀数组却可以轻松解决,后缀数组是这样形成的,假设有一个字符串char * s = “abcde”,然后我们定义一个和该字符串具有同样长度的char类型的指针数组s_ptr,该指针数组的每个元素为字符串s对应位置字符的地址即:s_ptr[i] = &s[i],这样s_ptr数组就成为后缀数组,s_ptr里的每个指针现在都指向了一个字符串,并且某个字符串(第一个除外)都是前一个字符串的后缀,像下面这样:
s_ptr[0] = “abcde”;
s_ptr[1] = “bcde”;
s_ptr[2] = “cde”;
s_ptr[3] = “de”;
s_ptr[4]= “e”;
形成后缀数组后,就可以后缀数组进行排序,注意,这里排序只是对后缀数组里的指针进行,不会影响其对应的字符数组,而在排序过程中比较的依据就是每个指针指向的字符串,排序结束后,指向具有相同前缀的字符串的指针就会聚集到一起,接下来只需检查任意两个相邻的字符串前缀重复长度,即可找到原始文本中重复长度最大的字符串。
#include "stdafx.h"
#include <fstream>
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//快速排序的关键:划分函数
int partition(vector<char*> &fix_array,int start,int end)
{
char * pivot = fix_array[start];
while(start < end)
{
while(start < end && strcmp(fix_array[end],pivot) >= 0) --end;
fix_array[start] = fix_array[end];
while(start < end && strcmp(fix_array[start],pivot) <= 0) ++start;
fix_array[end] = fix_array[start];
}
fix_array[start] = pivot;
return start;
}
//快速排序算法
void sort(vector<char*> &fix_array,int start,int end)
{
if(start < end)
{
int pivot = partition(fix_array,start,end);
sort(fix_array,start,pivot - 1);
sort(fix_array,pivot + 1,end);
}
}
//快速排序算法
void sort(vector<char*> &fix_array)
{
int length = fix_array.size();
sort(fix_array,0,length - 1);
}
//读取输入文件,并构建后缀数组
void init(const char* filename,string &text,vector<char*> &fix_array)
{
text.clear();
fix_array.clear();
FILE* fp = fopen(filename,"r");
char c;
while((c = fgetc(fp)) != EOF)
{
text += c;
}
fclose(fp);
int length = text.length();
fix_array.resize(length);
for (int i = 0; i < length; ++i)
{
fix_array[i] = &text[i];
}
}
//比较两个字符串,返回最大相同前缀字符的的个数
int wordcmp(const char * word1,const char * word2)
{
char* p = (char*)word1,*q = (char*)word2;
int replicated_prefix_count = 0;
while(*p && *q && *p == *q)
{
++replicated_prefix_count;
++p;
++q;
}
return replicated_prefix_count;
}
//比较已排序的后缀数组中相邻两个字符串,以确定输入文本中重复长度
//最大的字符串
char* find_longest_replicated_prefix(vector<char*> &fix_array)
{
int count = 0,fix_count = fix_array.size();
int index = -1;
char * res = NULL;
for (int i = 1; i < fix_count; ++i)
{
int n = wordcmp(fix_array[i - 1],fix_array[i]);
if(n > count)
{
count = n;
index = i;
}
}
if(index != -1)
{
res = new char[count + 1];
memset(res,0,(count + 1)*sizeof(char));
memcpy(res,fix_array[index],count);
}
return res;
}
int _tmain(int argc, _TCHAR* argv[])
{
string s = "The Homer_1.txt";
const char* filename = s.c_str();
string text;
vector<char*> fix_array;
init(filename,text,fix_array);
sort(fix_array);
char * res = find_longest_replicated_prefix(fix_array);
cout<<res<<endl;
return 0;
}以Samuel Butler翻译的英文版《荷马史诗》(两部,共100多万个字符,包含空格,标点符号)作为输入,在我的电脑上大约花费了10秒的时间找到该字符串,耗时最多的是排序部分,输入输出以及查找都很迅速,下面是程序结果:
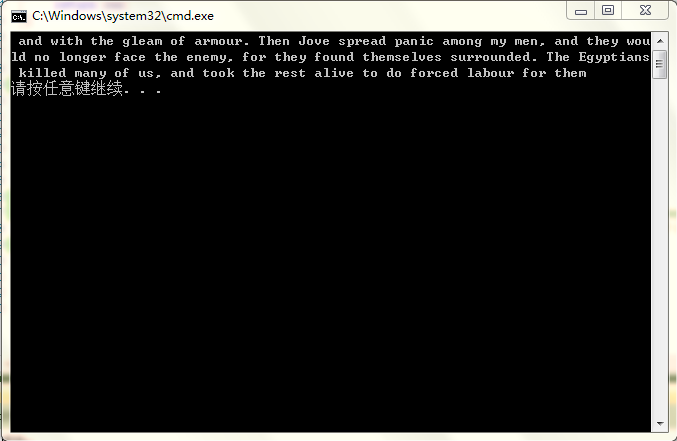
我在office 2013里查找该字符串,确实找到了两条记录,出现在奥德赛那一部里,该字符串的长度为227(开头有一个空格也算在里面),这一《编程珠玑》书里写的“whose sake so many of the Achaeans have died at Troy, far from their homes? Go about at once among the host, and speak fairly to them, man by man,that they draw not their ships into the sea.”不一致,我在文本里确实发现该字符串出现了两次,但是该字符串的长度只有190,这种不一致可能是输入不同造成的,我的输入是在网上下载的,不排除文件录入时出问题,当我查看《编程珠玑》作者的代码时,和我实现的一样。下面附上两个链接:
《编程珠玑(第二版)》网站:http://netlib.bell-labs.com/cm/cs/pearls/index.html。
我写的关于快速排序博客:http://blog.csdn.net/liao_jian/article/details/44514301。















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









