









现在,AI可以把人类脑中的信息,用高清视频展示出来了!
例如你坐在副驾所欣赏到的沿途美景信息,AI分分钟给重建了出来:

看到过的水中的鱼儿、草原上的马儿,也不在话下:


这就是由新加坡国立大学和香港中文大学共同完成的最新研究,团队将项目取名为MinD-Video。

这波操作,宛如科幻电影《超体》中Lucy读取反派大佬记忆一般:

引得网友直呼:
推动人工智能和神经科学的前沿。
值得一提的是,大火的Stable Diffusion也在这次研究中立了不小的功劳。
怎么做到的?
从大脑活动中重建人类视觉任务,尤其是功能磁共振成像技术(fMRI)这种非侵入式方法,一直是受到学界较多的关注。
因为类似这样的研究,有利于理解我们的认知过程。
但以往的研究都主要聚焦在重建静态图像,而以高清视频形式来展现的工作还是较为有限。
之所以会如此,是因为与重建一张静态图片不同,我们视觉所看到的的场景、动作和物体的变化是连续、多样化的。
而fMRI这项技术的本质是测量血氧水平依赖(BOLD)信号,并且在每隔几秒钟的时间里捕捉大脑活动的快照。
相比之下,一个典型的视频每秒大约包含30帧画面,如果要用fMRI去重建一个2秒的视频,就需要呈现起码60帧。
因此,这项任务的难点就在于解码fMRI并以远高于fMRI时间分辨率的FPS恢复视频。
为了弥合图像和视频大脑解码之间差距,研究团队便提出了MinD-Video的方法。
整体来看,这个方法主要包含两大模块,它们分别做训练,然后再在一起做微调。
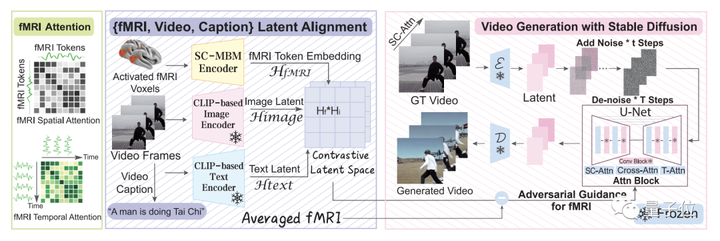
这个模型从大脑信号中逐步学习,在第一个模块多个阶段的过程,可以获得对语义空间的更深入理解。
具体而言,便是先利用大规模无监督学习与mask brain modeling(MBM)来学习一般的视觉fMRI特征。
然后,团队使用标注数据集的多模态提取语义相关特征,在对比语言-图像预训练(CLIP)空间中使用对比学习训练fMRI编码器。
在第二个模块中,团队通过与增强版Stable Diffusion模型的共同训练来微调学习到的特征,这个模型是专门为fMRI技术下的视频生成量身定制的。
如此方法之下,团队也与此前的诸多研究做了对比,可以明显地看到MinD-Video方法所生成的图片、视频质量要远优于其它方法。

而且在场景连续变化的过程中,也能够呈现高清、有意义的连续帧。

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉大厂AIGC实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉12000+AI关键词大合集👈

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









