







一、简介
Spark对RDD的操作可以整体分为两类:Transformation和Action
- Transformation可以翻译为转换,表示是针对RDD中数据的转换操作,主要会针对已有的RDD创 建一个新的RDD:常见的有map、flatMap、filter等等
- Action可以翻译为执行,表示是触发任务执行的操作,主要对RDD进行最后的操作,比如遍历、 reduce、保存到文件等,并且还可以把结果返回给Driver程序
不管是Transformation里面的操作还是Action里面的操作,我们一般会把它们称之为算子
常见的transformation算子其中Transformation算子有一个特性:lazy
lazy特性在这里指的是,如果一个spark任务中只定义了transformation算子,那么即使你执行这个任 务,任务中的算子也不会执行。 也就是说,transformation是不会触发spark任务的执行,它们只是记录了对RDD所做的操作,不会执 行。
只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。 Spark通过lazy这种特性,来进行底层的spark任务执行的优化,避免产生过多中间结果。
Action的特性:执行Action操作才会触发一个Spark 任务的运行,从而触发这个Action之前所有的 Transformation的执行
二、常见的transformation算子
- map 将RDD中的每个元素进行处理,一进一出
- filter 对RDD中每个元素进行判断,返回true则保留
- flatMap 与map类似,但是每个元素都可以返回一个或多个新元素
- groupByKey 根据key进行分组,每个key对应一个Iterable
- reduceByKey 对每个相同key对应的value进行reduce操作
- sortByKey 对每个相同key对应的value进行排序操作(全局排序)
- join 对两个包含对的RDD进行join操作
- distinct 对RDD中的元素进行全局去重
2.1、统计每个大区主播数量
val dataRDD = sc.parallelize(
Array((150001, "US", "male"), (150002, "CN", "male"),
(150001, "CH", "male"), (150002, "CH", "male")))
dataRDD.map(tup=>(tup._2,1)).reduceByKey(_+_).foreach(println(_))
2.2 打印每个主播的大区信息和音浪收入
val dataRDD3 = sc.parallelize(Array((150001, "US"), (150002, "CN" ), (150003, "CH")))
val dataRDD4 = sc.parallelize(Array((150001, 400), (150002, 500), (150003, 6000)))
val joinRDD = dataRDD3.join(dataRDD4)
joinRDD.foreach(tup=>{
val uid=tup._1
val area_gold = tup._2
//大区
val area =area_gold._1
//收入
val gold = area_gold._2
println(uid+"\t"+area+"\t"+gold)
备注:两维的即可进行join,三维的不行
2.3 对主播的收入排序
val dataRDD5 = sc.parallelize(Array((150001, 400), (150002, 500), (150003, 6000)))
dataRDD5.sortBy(_._2,false).foreach(println(_))
三、常见的action算子
- reduce:聚合计算
- collect:获取元素集合
- take(n):获取前n个元素
- count:获取元素总数
- saveAsTextFile:
- countByKey:统计相同的key出现多少次
- foreach:迭代遍历元素
应用代码:
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
val dataRDD1 = sc.parallelize(Array(("a", 1001), ("b", 1002), ("a", 1003), ("c", 1004)), 2)
//collect 应用
val collect = dataRDD.collect()
for (item <- collect) {
println("collect-:" + item)
}
//take应用
val take = dataRDD.take(2)
for (item <- take) {
println("take-:" + item)
}
//count应用
val res = dataRDD.count()
println("count-:" + res)
//reduce应用
val reduce = dataRDD.reduce(_ + _)
println("reduce-" + reduce)
//countByKey(应用)
val countByKey = dataRDD1.countByKey()
for ((k, v) <- countByKey) {
println(k + "-:" + v)
}
//通过repartition可以控制输出数据产生的文件个数
//saveAsTextFile
dataRDD.repartition(1).saveAsTextFile("D:\\bigdata/saveAsObjectFile")结果: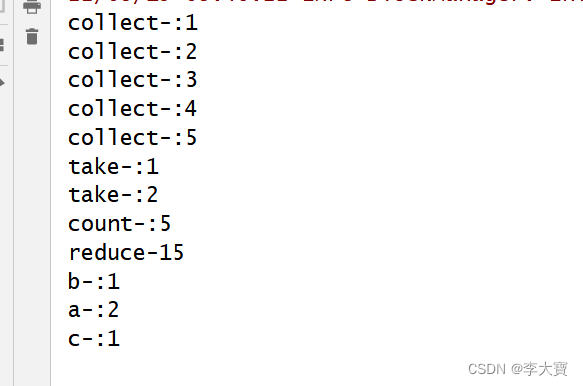
四、优化
4.1 map vs mapPartitions
- map 操作:对 RDD 中的每个元素进行操作,一次处理一条数据。 执行 1 次 map算子只处理 1 个元素,如果 partition 中的元素较多,假设当前已经处理 了 1000 个元素,在内存不足的情况下,Spark 可以通过GC等方法回收内存(比如将已处理掉的 1000 个元素从内存中回收)。因此, map 操作通常不会导致OOM异常;
- mapPartitions 操作:对 RDD 中每个 partition 进行操作,一次处理一个分区的数据。 执行 1 次map算子需要接收该 partition 中的所有元素,因此一旦元素很多而 内存不足,就容易导致OOM的异常,也不是说一定就会产生OOM异常,只是和map算子对比的话, 相对来说容易产生OOM异常
map和mapPartitions示例:
def main(args: Array[String]): Unit = {
val sc = getSparkContext
sc.setLogLevel("WARN")
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
dataRDD.map(item => {
println("map+===========")
item * 2
}).reduce(_ + _)
println("以下是mapPartitions=========")
val sum = dataRDD.mapPartitions(it => {
val result = new ArrayBuffer[Int]()
it.foreach(item => {
result.+=(item * 2)
})
result.toIterator
}).reduce(_ + _)
println("sum:" + sum)
sc.stop()
}结果:
4.2 reduceByKey和groupByKey的区别
- 当采用reduceByKey时,数据在进行shuffle之前会先进行局部聚合
- 当使用groupByKey时,数据在shuffle之间不会进行局部聚合,会原样进行shuffle 这样的话reduceByKey就减少了shuffle的数据传送,
4.3 foreach 和foreachPartiton 区别
- foreach:一次处理一条数据
- foreachPartition:一次处理一个分区的数据
def main(args: Array[String]): Unit = {
val sc = getSparkContext
sc.setLogLevel("WARN")
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5), 2)
dataRDD.foreachPartition(it=>{
println("=============")
it.foreach(item=>{
println(item)
})
})
sc.stop()
}结果:















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









