







论文在权值空间将SENet和CondConv进行了总结,提出统一的框架WeightNet,能够根据样本特征动态生成卷积核权值,并且能通过调节超参数来达到准确率和速度间的trade-off
来源:晓飞的算法工程笔记 公众号
论文: WeightNet: Revisiting the Design Space of Weight Networks

Introduction
论文提出了一种简单且高效的动态生成网络WeightNet,该结构在权值空间上集成了SENet和CondConv的特点,先通过全局平均池化以及带sigmoid激活的全连接层来获得动态的激活向量(activiation vector),然后利用激活向量进行后续的特征提取。SENet将激活向量用于加权特征层,而CondConv则将激活向量用于加权候选卷积核参数。
借鉴上面两种方法,WeightNet在激活向量后面添加一层分组全连接,直接产生卷积核的权值,在计算上十分高效,并且可通过超参数的设置来进行准确率和速度上的trade-off。。
WeightNet
Grouped fully-connected operation
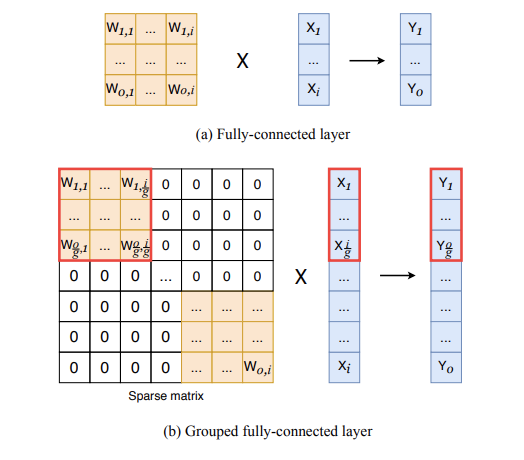
在全连接层中,原子是全部连接的,所以全连接层可认为是矩阵计算 Y = W X Y=WX Y=WX,如图a所示。分组全连接则是将原子分成 g g g组,每组(包含 i / g i/g i/g输入和 o / g o/g o/g输出)内全部连接,如图b所示。分组全连接操作的一个显著特性就是权值矩阵变成了稀疏的块对角矩阵(block diagonal matrix),而全连接操作可认为是分组数为1的分组全连接操作。
Rethinking CondConv
CondConv通过m维向量
α
\alpha
α将
m
m
m个卷积核进行加权合并得到最终的卷积核,由样本特征动态生成。向量
α
\alpha
α由全局池化、全连接层
W
f
c
1
W_{fc1}
Wfc1和sigmoid操作
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)计算:
α
=
σ
(
W
f
c
1
×
1
h
w
∑
i
∈
h
,
j
∈
w
X
c
,
i
,
j
)
\alpha=\sigma(W_{fc1}\times \frac{1}{hw}{\sum}_{i\in h, j\in w}X_{c,i,j})
α=σ(Wfc1×hw1∑i∈h,j∈wXc,i,j),
×
\times
×为矩阵乘法,
W
f
c
1
∈
R
m
×
C
W_{fc1}\in \mathbb{R}^{m\times C}
Wfc1∈Rm×C,
α
∈
R
m
×
1
\alpha \in \mathbb{R}^{m \times 1}
α∈Rm×1,最终的卷积核权值则由多个候选卷积核与向量
α
\alpha
α加权所得:
W
′
=
α
1
⋅
W
1
+
α
2
⋅
W
2
+
⋯
+
+
α
m
⋅
W
m
W^{'}=\alpha_1 \cdot W_1 + \alpha_2 \cdot W_2 + \cdots + + \alpha_m \cdot W_m
W′=α1⋅W1+α2⋅W2+⋯++αm⋅Wm,其中
W
i
∈
R
C
×
C
×
k
h
×
k
w
W_i \in \mathbb{R}^{C\times C\times k_h\times k_w}
Wi∈RC×C×kh×kw。
我们可以将上述的操作转换为:
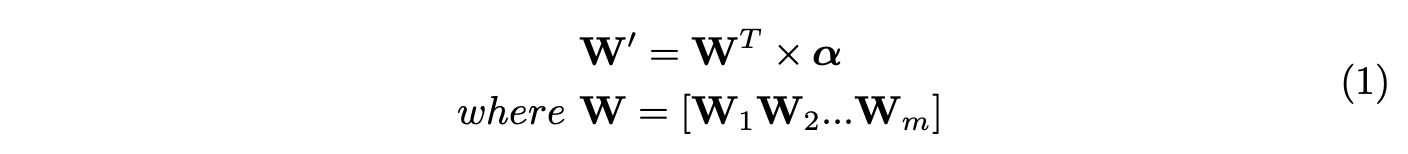
W ∈ R m × C C k h k w W\in \mathbb{R}^{m\times CCk_hk_w} W∈Rm×CCkhkw为矩阵拼接后的结果。根据公式1,我们可变相地认为,CondConv的最终卷积核计算可通过在向量 α \alpha α后面添加一层输入为 m m m、输出为 C × C × k h × k w C\times C\times k_h\times k_w C×C×kh×kw的全连接层进行输出,这比原本的CondConv实现要高效地多。
Rethinking SENet
SE模块首先根据样本特征动态生成m维向量
α
\alpha
α,再对
m
m
m个特征进行加权。向量
α
\alpha
α由全局池化、两个全连接层、ReLU操作
δ
(
⋅
)
\delta(\cdot)
δ(⋅)和sigmoid操作
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)计算:
α
=
σ
(
W
f
c
2
×
δ
(
W
f
c
1
×
1
h
w
∑
i
∈
h
,
j
∈
w
X
c
,
i
,
j
)
)
\alpha=\sigma(W_{fc2}\times \delta(W_{fc1}\times \frac{1}{hw}{\sum}_{i\in h, j\in w}X_{c,i,j}))
α=σ(Wfc2×δ(Wfc1×hw1∑i∈h,j∈wXc,i,j)),
W
f
c
1
∈
R
C
/
r
×
C
W_{fc1}\in \mathbb{R}^{C/r\times C}
Wfc1∈RC/r×C,
W
f
c
2
∈
R
C
×
C
/
r
W_{fc2}\in \mathbb{R}^{C\times C/r}
Wfc2∈RC×C/r,
×
\times
×为矩阵乘法。使用两层全连接层主要为了降低整体参数量,由于
α
\alpha
α为
C
C
C维向量,使用单层全连接层会带来过多参数。
在获得向量
α
\alpha
α后,可将其应用在卷积层之前
Y
c
=
W
c
′
∗
(
X
⋅
α
)
Y_c=W^{'}_c * (X\cdot \alpha)
Yc=Wc′∗(X⋅α),也可应用在卷积层之后
Y
c
=
(
W
c
′
∗
X
)
⋅
α
Y_c=(W^{'}_c * X)\cdot \alpha
Yc=(Wc′∗X)⋅α,
(
⋅
)
(\cdot)
(⋅)为维度坐标上的乘法。上面的两种实现实际都等价于对权值矩阵
W
c
′
W^{'}_c
Wc′进行加权:
Y
c
=
(
W
c
′
⋅
α
c
)
∗
X
Y_c=(W^{'}_c \cdot \alpha_c) * X
Yc=(Wc′⋅αc)∗X,与公式1不同的是,这里没有进行维度的减少,相当于一个输入为
C
C
C、输出为
C
×
C
×
k
h
×
k
w
C\times C\times k_h\times k_w
C×C×kh×kw、分组为
C
C
C的分组全连接操作。
WeightNet Structure
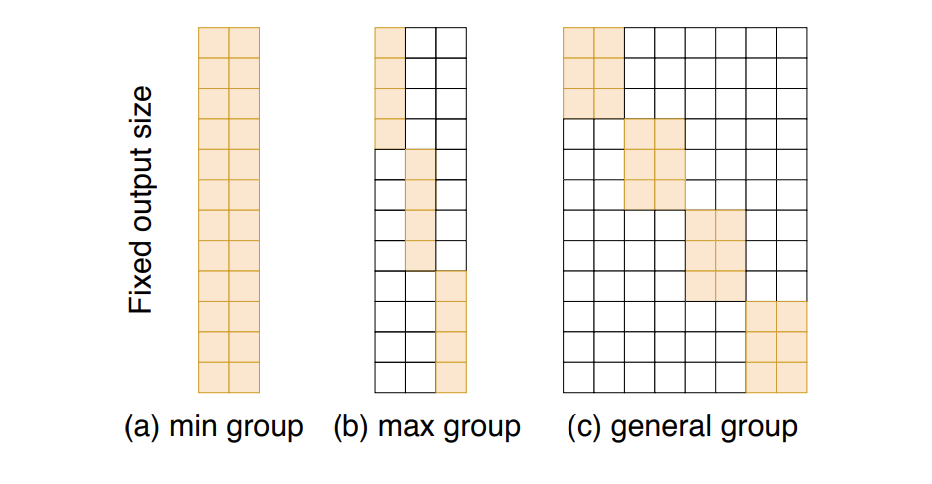
由上面的分析我们可以看到,分组全连接层的分组数最小为1(CondConv),最大为输入的维度(SeNet),所以我们得到了图c的通用分组全连接层。

如表1所示,分组全连接层包含两个超参数 M M M和 G G G, M M M用来控制输入的维度, G G G则配合 M M M一起来控制参数量和准确率之间的trade-off。
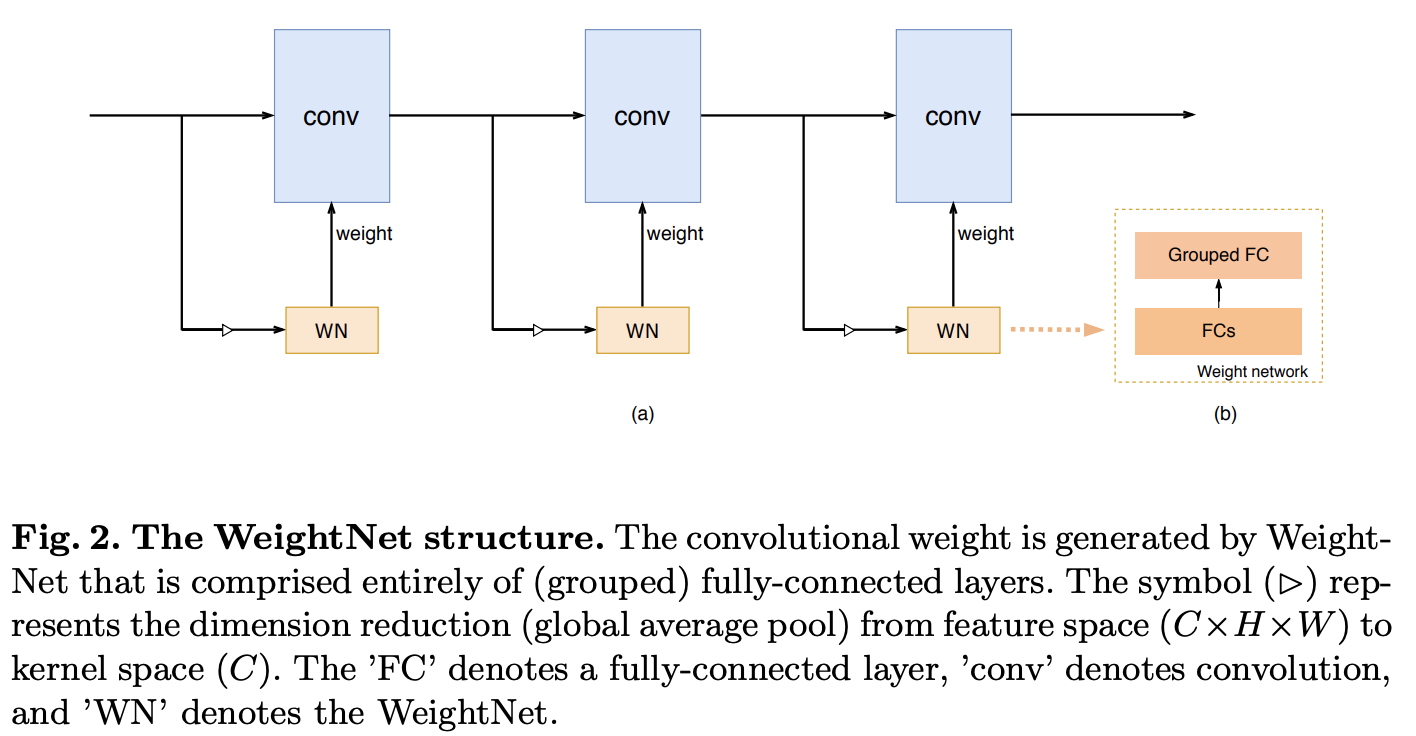
WeightNet核心模块的结构如图2所示,在生成激活向量
α
\alpha
α时,为了减少参数量,使用reduction ratio为
r
r
r的两层全连接:
α
=
σ
(
W
f
c
2
×
W
f
c
1
×
1
h
w
∑
i
∈
h
,
j
∈
w
X
c
,
i
,
j
)
\alpha=\sigma(W_{fc2}\times W_{fc1}\times \frac{1}{hw}{\sum}_{i\in h, j\in w}X_{c,i,j})
α=σ(Wfc2×Wfc1×hw1∑i∈h,j∈wXc,i,j),
W
f
c
1
∈
R
C
/
r
×
C
W_{fc1}\in \mathbb{R}^{C/r\times C}
Wfc1∈RC/r×C,
W
f
c
2
∈
R
C
×
C
/
r
W_{fc2}\in \mathbb{R}^{C\times C/r}
Wfc2∈RC×C/r,
r
r
r为16,后续的卷积核权值生成则直接使用输入为
M
×
C
M\times C
M×C、输出为
C
×
C
×
k
h
×
k
w
C\times C\times k_h\times k_w
C×C×kh×kw、分组为
G
×
C
G\times C
G×C的分组全连接层。
对于WeightNet中的卷积操作和权值分支的计算量分别为
O
(
h
w
C
C
k
h
k
w
)
O(hwCCk_h k_w)
O(hwCCkhkw)和
O
(
M
C
C
k
h
k
w
/
G
)
O(MCCk_h k_w / G)
O(MCCkhkw/G),而参数量分别为零和
O
(
M
/
G
×
C
×
C
×
k
h
×
k
w
)
O(M/G\times C\times C\times k_h\times k_w)
O(M/G×C×C×kh×kw)。
Experiment
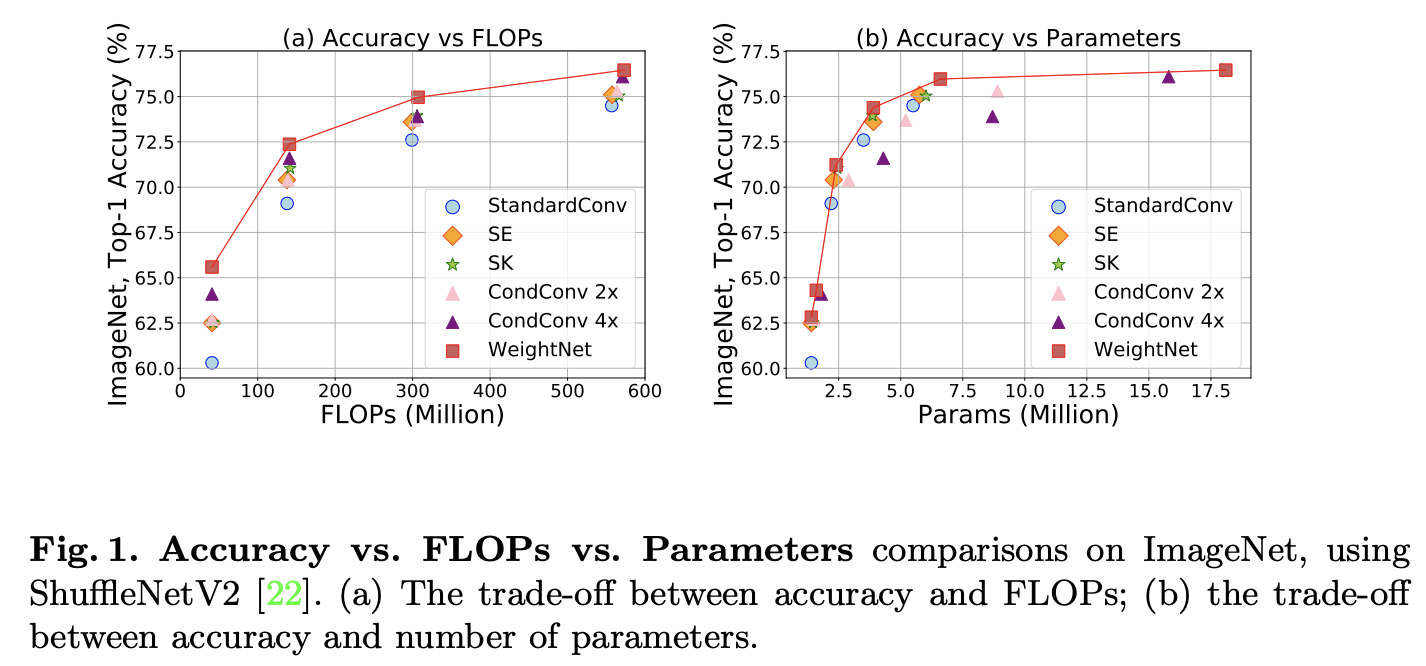
参数量/计算量与准确率的曲线对比,CondConv 2x和4x为候选卷积核数量。
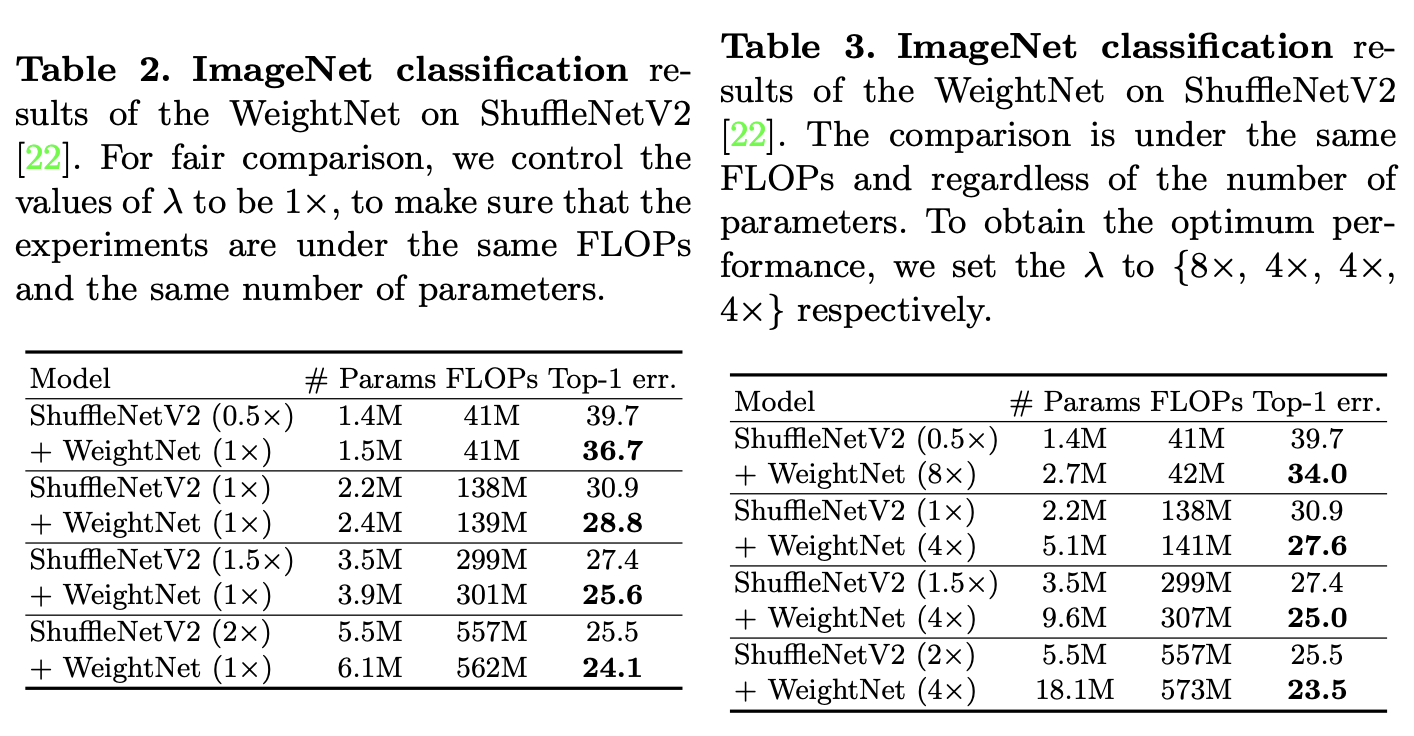
不同 λ \lambda λ配置的WeightNet的效果,这里固定 G = 2 G=2 G=2,对ShuffleNetV2进行少量的维度修改,保证其能被 G G G整除。
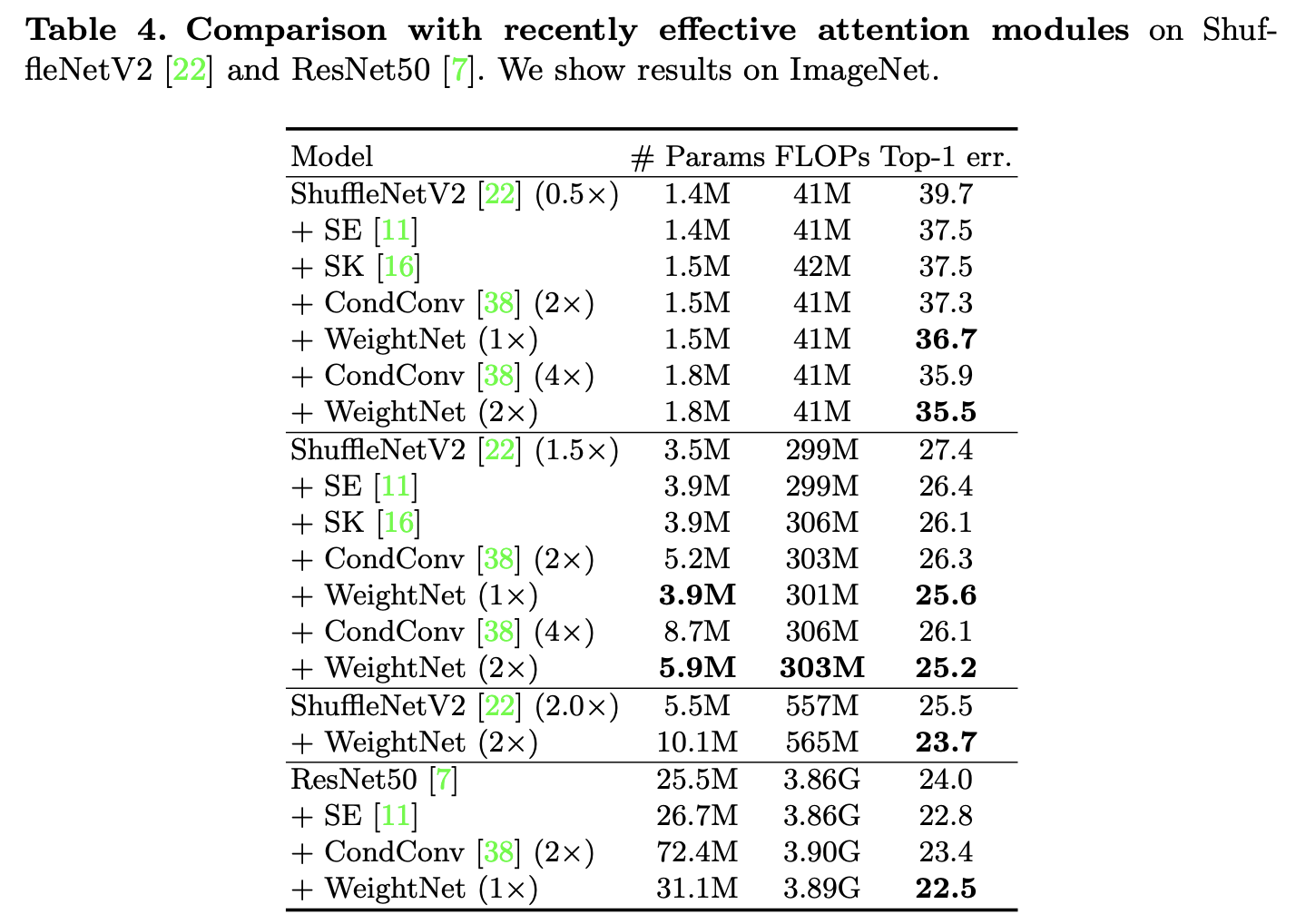
各种注意力模块的对比实验。
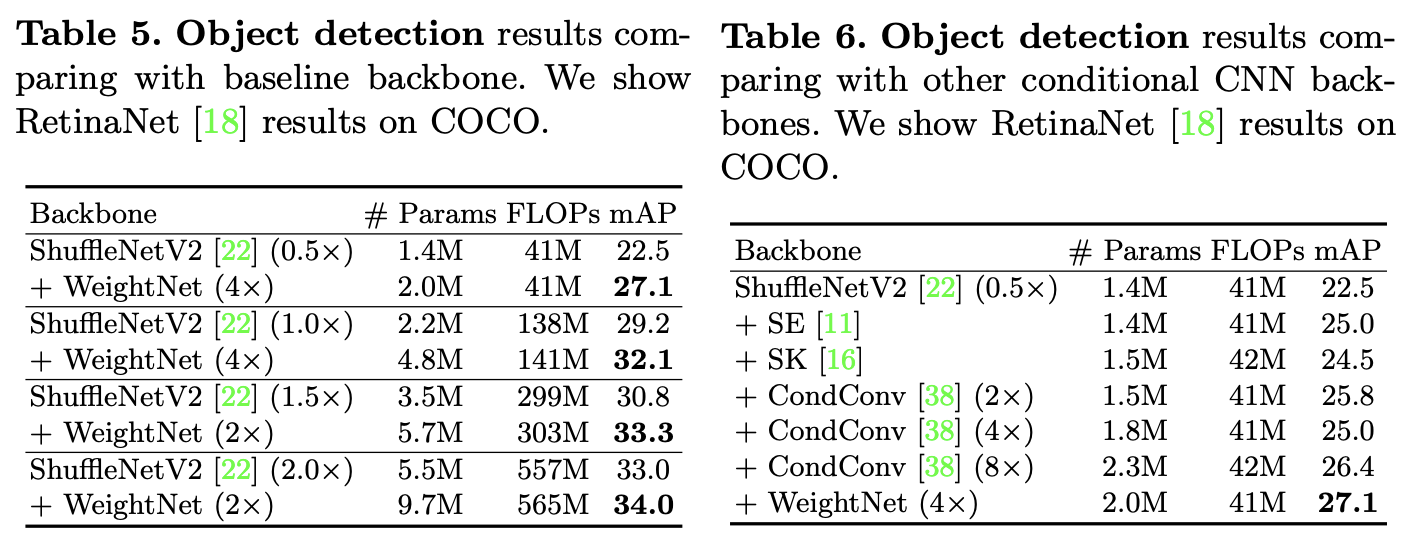
目标检测任务上的效果。
Conclusion
论文在权值空间将SENet和CondConv进行了总结,提出统一的框架WeightNet,能够根据样本特征动态生成卷积核权值,并且能通过调节超参数来达到准确率和速度间的trade-off。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









