







论文提出了用于快速图像分类推理的混合神经网络
LeVIT,在不同的硬件平台上进行不同的效率衡量标准的测试。总体而言,LeViT在速度/准确性权衡方面明显优于现有的卷积神经网络和ViT,比如在80%的ImageNet top-1精度下,LeViT在CPU上比EfficientNet快5倍来源:晓飞的算法工程笔记 公众号
论文: LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference

Introduction
虽然许多研究旨在减少分类器和特征提取器的内存占用,但推理速度同样重要,高吞吐量对应于更好的能源效率。论文的目标是开发一个基于Vision Transformer的模型系列,在GPU、CPU和ARM等高度并行的架构上具有更快的推理速度。
在相同的计算复杂度下,Transformer的速度会比卷积架构更快。这是因为大多数硬件加速器(GPU、TPU)都经过优化以执行大型矩阵乘法,而在Transformer中的注意力块和MLP块主要依赖于矩阵乘法。相反,卷积需要复杂的数据访问模式,通常跟IO绑定的。
论文引入轻量的卷积组件来代替产生类似卷积特征的Transformer组件,同时将统一的Transformer结构替换为带池化的金字塔结构。由于整体结构类似于LeNet,论文称新网络为LeViT。
除提出LeViT外,论文还提供了以下缩小ViT模型体量的方法:
- 使用注意力作为下采样机制的多阶段
Transformer架构。 - 计算高效的图像块提取器,可减少第一层中特征数量。
- 可学习且平移不变的注意力偏置,取代位置编码。
- 重新设计的
Attention-MLP块,计算量更低。
Motivation
Convolutions in the ViT architecture

ViT的图像块提取器一般为步幅16的16x16卷积,然后将输出乘以可学习的权重来得到第一个自注意力层的 q q q, k k k和 v v v特征。论文认为,这些操作也可以认为是对输入进行卷积函数处理。
如图2所示,论文可视化了DeiT第一层的注意力权值,发现权值空间都有与Gabor滤波器类似的模式。
卷积中权值空间的平滑度主要来自卷积区域的重叠,相邻的像素接收大致相同的梯度。对于没有区域重叠ViT,权值空间的平滑可能是由数据增强引起的。当图像训练多次且有平移时,相同的梯度也会平移通过下一个滤波器,因此学习到了这种平滑的权值空间。
因此,尽管Transformer架构中不存在归纳偏置,但训练确实会产生类似于传统卷积层的权值空间。
Preliminary experiment: grafting
ViT的作者尝试将Transformer层堆叠在传统的ResNet-50之上,将ResNet-50充当Transformer层的特征提取器,梯度可以在两个网络传播中。然而,在他们的实验中,Transformer层的数量是固定的。
与ViT的实验不同的是,论文主要在相近算力的情况下对比不同数量的卷积阶段和Transformer层数时之间的性能,进行Transformer与卷积网络的混合潜力的研究。
论文对具有相似的运行时间ResNet-50和DeiT-Small进行实验,由于裁剪后的ResNet产生的激活图比DeiT使用的 14 × 14 14\times14 14×14激活图更大,需要在它们之间引入了一个平均池化层。同时,在卷积层和Transformer层的转换处引入了位置编码和分类标记。对于ResNet-50,论文使用ReLU激活层和BN层。
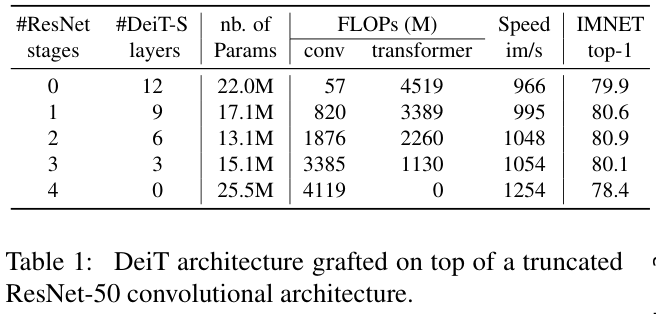
结果如表1所示,混合架构均比单独的DeiT和ResNet-50的性能要好,两个阶段的ResNet-50的参数数量最少且准确度最高。
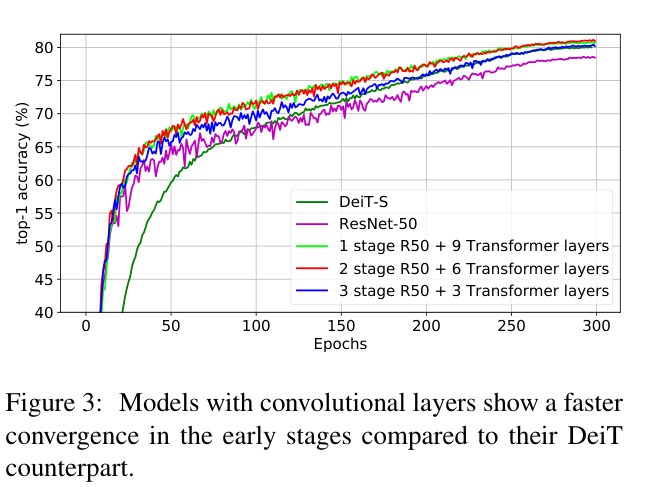
论文在图 3 中展示了一个有趣的观察结果:混合模型在训练期间的早期收敛类似于卷积网络,随后切换到类似于DeiT-S的收敛速度。由于卷积层具有很强的归纳偏差能力(尤其是平移不变性),能够更有效地学习早期层中的低级特征,而高质量的图像块编码使得训练初期能更快地收敛。
Model
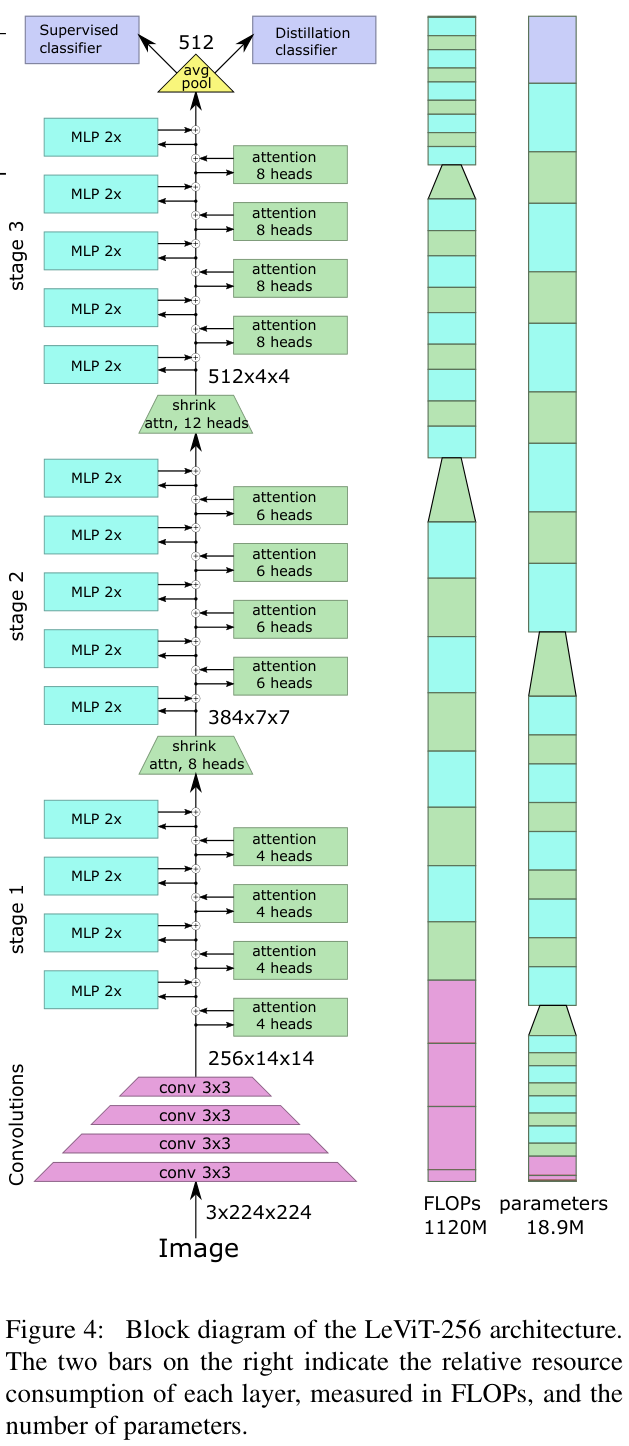
Design principles of LeViT
LeViT建立在ViT架构和DeiT训练方法之上,引入一些对卷积架构有用的组件。忽略分类标记的作用,ViT就是处理特征图的层堆叠,中间的特征编码可以看作是FCN架构中的传统 C × H × W C\times H\times W C×H×W 特征图( B C H W B C H W BCHW 格式)。因此,适用于特征图的操作(池化、卷积)也可以应用于DeiT的中间特征。
需要注意的是,优化计算架构不一定要最小化参数数量。ResNet系列比VGG网络更高效的设计之一是在两个阶段以相对较小的额外计算消耗进行有效的分辨率降低,使得第三阶段的激活图的分辨率缩小到足够小(14x14),从而降低了计算成本。
LeViT components
先前的分析表明,将小型卷积网络应用于Transformer的输入时可以提高准确性。在LeViT中,论文选择 4 层 3 × 3 3\times3 3×3 卷积(步幅为 2)来对输入进行处理,通道数分别为 C = 32 , 64 , 128 ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









