






来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Collective Critics for Creative Story Generation

创新点
- 提出了 C r i t i C S {\tt CritiCS} CritiCS 的框架,旨在通过基于创造力标准的集体评议,创造性地增强故事计划和文本表现力。
- 通过实验表明, C r i t i C S {\tt CritiCS} CritiCS 有效地创造了具有创造性和连贯性的故事,使用了多样化的标准、领导者和角色等关键组件。
- C r i t i C S {\tt CritiCS} CritiCS 支持交互式写作,使人类用户能够介入评议并主动完善故事。
内容概述
使用大型语言模型(LLMs)生成几千字的叙事连贯的长篇故事一直是一项具有挑战性的任务。之前的研究通过提出不同的框架来解决这一挑战,这些框架创建了故事计划,并基于该计划生成长篇故事。然而,这些框架主要集中在维持故事的叙事连贯性上,往往忽视了故事计划中的创造力以及从这些计划中生成的故事的表现力,而这些都是吸引读者兴趣的理想特性。
论文提出了创意故事生成框架Collective Critics for Creative Story(
C
r
i
t
i
C
S
{\tt CritiCS}
CritiCS ),该框架由计划优化阶段(
C
r
P
l
a
n
{\tt CrPlan}
CrPlan )和故事生成阶段(
C
r
T
e
x
t
{\tt CrText}
CrText )组成,旨在将协同修订机制融入长篇故事生成过程中。
在每个阶段,多位LLM评审者评估草稿,并根据评估创造力的标准(例如,叙事流的独特性和生成文本的生动性)提供改进建议。然后,一位领导者选择最有帮助于优化草稿的评审意见。这个修订过程经过多轮迭代,最终生成一个完整的计划和故事
广泛的人类评估表明, C r i t i C S {\tt CritiCS} CritiCS 显著提高了故事的创造力和读者的参与度,同时也保持了叙事的连贯性。此外,该框架的设计允许人类作者在整个评审过程中以任何角色积极参与,从而实现故事创作中的人机互动协作。
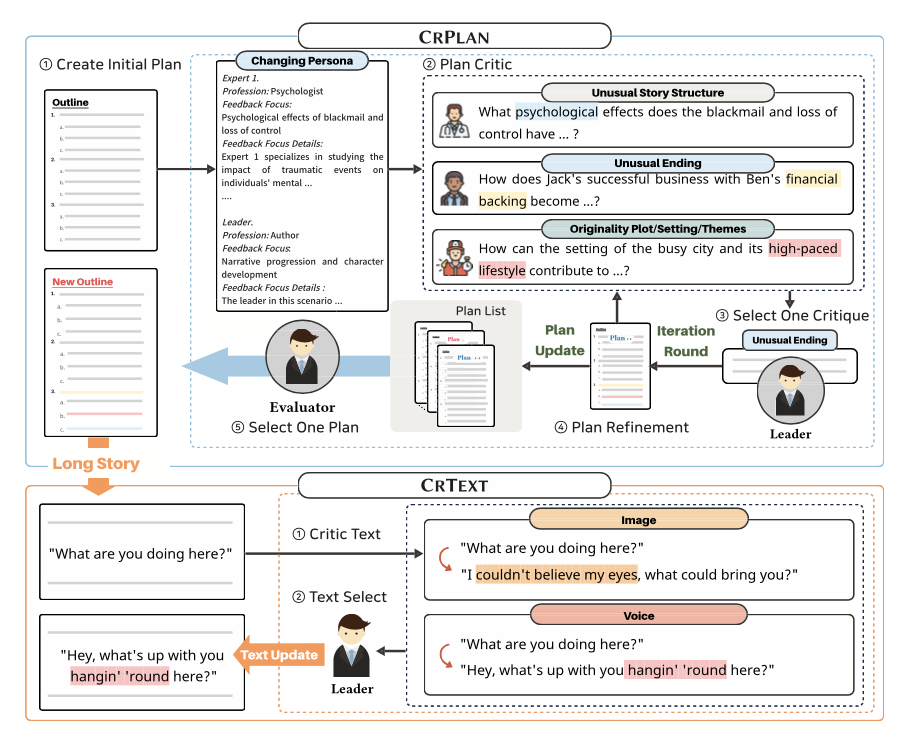
CritiCS
C
r
i
t
i
C
S
{\tt CritiCS}
CritiCS 由两个阶段组成(
C
r
P
l
a
n
{\tt CrPlan}
CrPlan 和
C
r
T
e
x
t
{\tt CrText}
CrText ),利用大语言模型(LLM)的能力来创作创意故事,并将基于创意标准的评论过程纳入其中。
CrPlan
在
C
r
P
l
a
n
{\tt CrPlan}
CrPlan 中,三个评论者根据三个标准评估故事计划的创造力:原创的主题和背景设置、不寻常的故事结构和不寻常的结局。这种评估确保为故事注入多样化的元素,同时赋予其新颖感。

上表展示了一个优化计划的例子,其中主角的孤独感被拟人化,从而增强了叙事背景的独特性。
首先,三个评论者各自提供建议,以利用他们的独特专业知识来增强草稿计划。接下来,领导者对三个建议进行评估、排名,并选择其认为最佳的一个。然后,将所选择的建议应用于完善计划。
为了进行详细的评论,三个评论者被赋予与故事计划相关的专业角色。同时,领导者被具身为文学编辑或创意写作专家,负责调和任何冲突。
整个过程重复进行若干轮,之后,计划评估者审查每轮候选计划,以选出最终一个在创造力与连贯性之间有效平衡的计划。
CrText
在 C r T e x t {\tt CrText} CrText 中,两位评论者根据来自 C r P l a n {\tt CrPlan} CrPlan 的计划审查已创作的故事,使用两个关注创意文本表现力的标准:图像和声音。

上表展示了一个经过优化的文本示例,其中动词raised被替换为arched,使得短语更具独特性。
图像表示读者被生动的心理意象所激发的程度。这包括视觉图像、声音、气味、身体感觉和情感(例如,从月球发出的柔和光辉、阴郁的阴影)。声音则指作者在创造独特且易于识别的写作风格方面的成功程度(例如,以恐怖故事风格书写、俚语、像lol这样的非正式语言)。与
C
r
P
l
a
n
{\tt CrPlan}
CrPlan 类似,领导者选择两个建议中的一个来完善表达。
与 C r P l a n {\tt CrPlan} CrPlan 不同,在此过程中评论者没有角色,因为图像和声音标准提供了明确的表达修改指示,消除了需要角色来固定故事主题的必要。同时,由于每轮中的句子都在不同程度上被修改,因此没有评估者。
人机交互写作

C r i t i C S {\tt CritiCS} CritiCS 能够促进人类写作者在修订过程中的积极参与,从而实现人类与机器在创意写作中的互动协作。人类参与者能够修改系统生成的评论或撰写自己的评论,也可以担任领导者的角色,负责评估和选择评论。
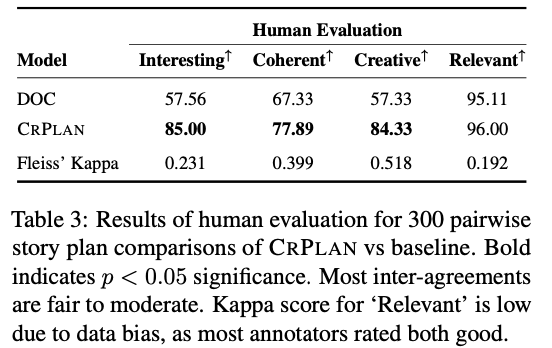
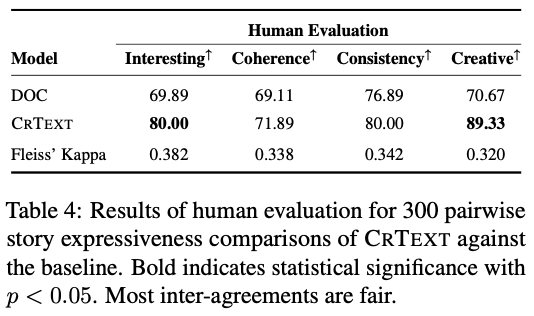
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









