







数据集
MovieSum包括2200部电影剧本及其维基百科情节摘要,用于电影剧本的抽象摘要。该数据集手动格式化电影剧本以表示它们的结构元素。与现有数据集相比,MovieSum具有几个独特的特点:(1) 它包括电影剧本,这些剧本比电视剧本更长。(2) 它是先前电影剧本数据集的两倍大小。(3) 它提供了带有IMDb ID的元数据,以便访问其他外部知识。来源:晓飞的算法工程笔记 公众号
论文: MovieSum: An Abstractive Summarization Dataset for Movie Screenplays

Introduction
近年来,大型语言模型在抽象摘要方面取得了显著进步,旨在产生输入文档的简洁连贯摘要。然而,当输入上下文较长且相关信息分布在整个文档中时,这些模型通常会遇到困难。为了更好地理解这一现象并推动研究,需要包含长格式文档并且重要信息分散于整个文档的数据集。电影剧本具有这些特点:为生成摘要,需要理解整部剧本中角色和事件的情况。
最近,叙述性摘要研究主要集中在电视剧和书籍上,对电影剧本的关注较少。值得注意的是,有研究提出电视节目剧本数据集SummScreen,引起了相当大的关注,并被纳入了长篇文档摘要基准测试中。但不同于电影剧本,电视剧集的转录往往相对较短,并且主要由口语对话构成,几乎没有场景或角色描述。此外,它们并非自包含的,因为可能会提到之前集数中发生过的事件或角色。相反,电影剧本是结构化文档,具有各种剧本元素,如场景标题、地点、角色名、对话和详细场景描述。这些是由编剧撰写,并具有特定格式以表示每个元素。
目前最大的电影剧本数据集包括917部自动格式化的剧本(ScriptBase-j),最新的电影为2013年。论文构建了一个新的电影剧本数据集MovieSum,用于抽象摘要,包括2200部电影,是ScriptBase-j的两倍多。重要的是,新数据集是使用专业剧本编写工具格式化的,并配有维基百科情节摘要。每部电影还附有其IMDB ID,以便将来收集其他外部知识。该数据集涵盖了从1930年到2023年各种类型的电影
论文提供了MovieSum的详细描述,包括收集和过滤剧本的步骤,以及与其他叙述性数据集的统计和比较。论文进行了广泛的实验,评估了最先进的摘要模型在MovieSum上的性能,展示了它作为叙述性摘要研究基准数据集的实用性。实验表明,最近的模型在长篇抽象摘要方面存在困难,论文希望能激发这一领域的进一步研究。此外,论文提供了关于如何利用剧本结构生成摘要的定性分析。
The MovieSum Dataset
论文提供了MovieSum,一个包含2200个电影剧本摘要对的电影剧本抽象摘要数据集。数据集中的所有电影剧本都是英文的。
Collection of Movie Screenplays
从各种电影剧本网站收集了电影剧本,总共收集了5639份电影剧本文档,以各种文本格式呈现,并附带电影名称、IMDB标识符和发行年份的元数据。如果缺少IMDB标识符,论文会使用IMDB数据库提取。然后,论文根据两个标准手动删除了一些电影。首先通过使用电影名称和发行年份来识别重复的电影剧本并将其删除,其次过滤掉没有文本内容或不完整的剧本。
Screenplay Formatting
电影剧本是结构化文档,具有各种脚本元素,例如场景标题(也称为标头)、角色名称、对话和场景描述(或动作),这些元素基于间距具有特定的标记。从这些电影剧本文档中提取文本时,大部分格式都不存在,这使得使用正则表达式检索元素变得具有挑战性。为确保数据集的质量,在过滤后,手动纠正电影剧本并使用专业的剧本编写工具Celtx格式化了每个电影剧本。这个过程保留了电影剧本元素的格式,论文进一步过滤掉了具有编码或光学字符识别错误的剧本。
Collection of Wikipedia Plot Summaries
为了构建一个稳健的摘要数据集,有必要收集高质量的人工撰写摘要。与以往的工作类似,论文收集了维基百科的情节摘要,发现这些摘要质量较高,这得益于维基百科对电影情节摘要采用一致的指南。
为了收集维基百科的情节摘要,首先使用电影名称和年份提取了电影的维基百科页面,然后收集了“情节”部分下的文本,筛选掉了维基百科页面或情节部分不可用的电影。
这一过程得到了2200部手动格式化的电影剧本,以及相应的维基百科摘要。
Dataset Analysis
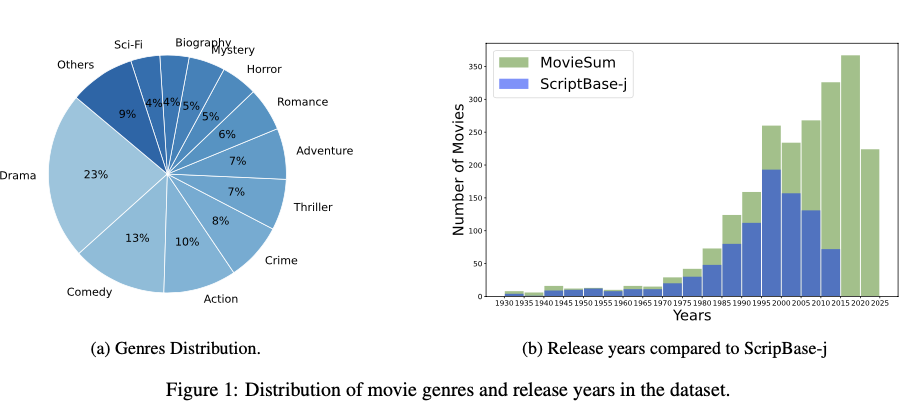
这得到了一个数据集,包括2200部手动格式化的电影剧本以及它们相应的摘要。剧本的平均长度为29,000字,摘要的平均长度为717字。重要的是,这个数据集是之前可用的电影剧本数据集的两倍大小,其中包括格式化的电影剧本。图1a展示了数据集中电影的类型分布,并展示了广泛的类型范围。在图1b中,展示了发行年份的分布,显示出这些电影跨越了多年,其中有相当数量的电影是近年来制作的
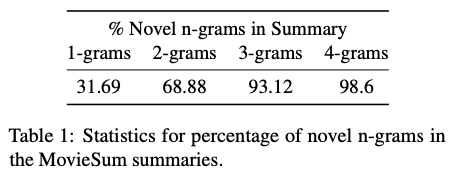
为了研究摘要的抽象性,在表1中展示了novel n-gram比例。从结果来看,大量的3-gram和4-gram是新颖的,并且在电影剧本中没有出现,表明了摘要的高度抽象性。
Comparison with Existing Datasets
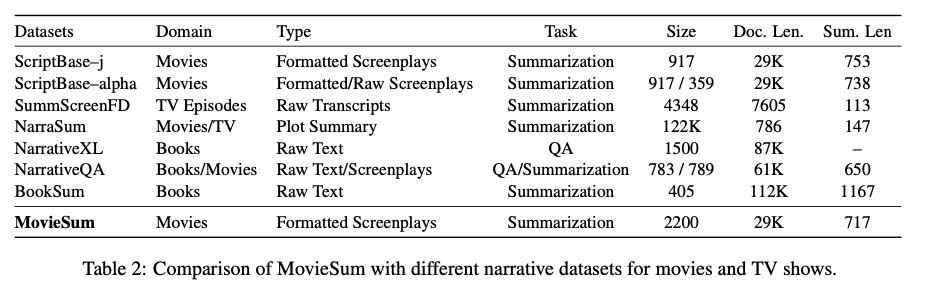
将论文的数据集与叙事领域的各种数据集进行了比较,统计数据如表2,所示这些数据集包括ScriptBase-j、ScriptBase-alpha、SummScreenFD、NarraSum、NarrativeXL、NarrativeQA和BookSum。值得注意的是,BookSum和NarrativeXL具有更长的平均文档长度,但它们包括的是书籍,而不是剧本。SummScreenFD由电视剧剧集成本文以及摘要组成,在文档和摘要长度上都要短得多。值得重视的是,SummScreen由社区贡献的成本文本构成,并且主要包括对话内容,而不像剧本那样包含详细的场景描述。此外,电视剧集并非自包含型作品,因为前期内容中可能会提到事件或角色。NarraSum包含情节摘要作为文档而不是实际剧本,并且在我们比较的各个数据集中具有最低平均文档长度。NarrativeQA既包括书籍也包括电影剧本,其中书籍明显很长,在平均文档长度方面与书籍数据集相当。然而它只由789部未格式化电影剧本组成。
ScriptBase-j和ScriptBase-alpha数据集都与论文的剧本数据集非常接近。 ScriptBase-j包含格式化的剧本,而ScriptBase-alpha包括未格式化的剧本原始文本。值得注意的是,ScriptBase-j是ScriptBase-alpha的子集,后者包括917个格式化的剧本。另一方面,ScriptBase-alpha包括另外359部电影。论文的工作可以视为ScriptBase-j的扩展,因为它也包括格式化的剧本。同时,论文克服了SciptBase-j的两个关键限制:
(1) 电影剧本的格式化是自动完成的。虽然根据规则和字符串匹配很容易检测场景标题,但要区分对话、角色名称和场景描述是具有挑战性的。该工作没有提供关于自动格式化策略的任何细节。另一方面,MovieSum包括使用专业剧本工具对ScriptBase-j中所有电影进行格式化。
(2)ScriptBase的两个子集都包含截至2013年发布的电影。相比之下,MovieSum还包括最近发布的电影。这对于确保摘要模型对新的电影叙事惯例保持稳健至关重要。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









