






峰值21WQps、亿级DAU《羊了个羊》架构
1 低吞吐、低可用的最初技术架构
DAU(Daily Active User),日活跃用户数量。
《羊了个羊》最开始的技术架构。
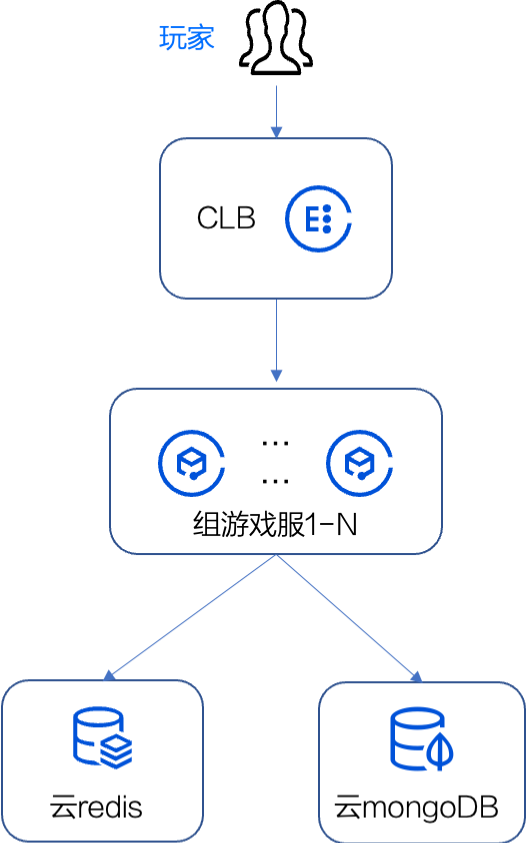
玩家流量通过一个接入层 LB进入,传输给服务层几个 POD 进行游戏逻辑处理,再将数据进行存储,其中,热数据存储在Redis中, 持久化数据存在MongoDB。
最初的服务层几个 POD ,都是单点服务。单点服务的性能瓶颈,再加上代码未进行充分优化,造成当时的系统最高只能承受5000的QPS,但实际流量增长很快, 并且持续升高并到达性能瓶颈,游戏服务开始瘫痪,全部玩家无法再进行游戏。
2 技术架构全面升级
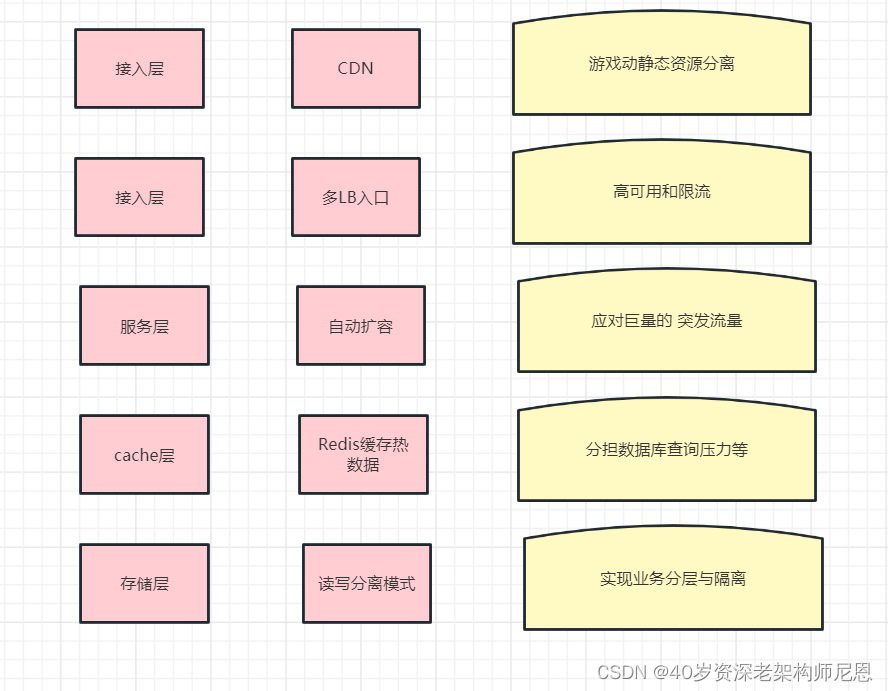
接入层的架构优化
-
启用CDN做游戏动静态资源分离,让玩家使用的游戏资源实现就近下载,减轻网络端压力;
-
设计多LB入口实现入口高可用和限流,避免系统被超额流量过载;
服务层的架构优化
-
优化服务层的自动扩容,应对巨量的 突发流量
-
具体措施上,首先通过引入腾讯云TKE Serverless 的弹性机制,实现游戏服自动纵向和横向扩展
-
实现服务解藕,增加容错和熔断机制;
Cache层的架构优化
-
Redis缓存热数据,分担数据库查询压力等。
存储层的架构优化
-
把MongoDB转换为读写分离模式,配合代码逻辑优化实现性能提升,
-
引入分库实现业务分层与隔离,
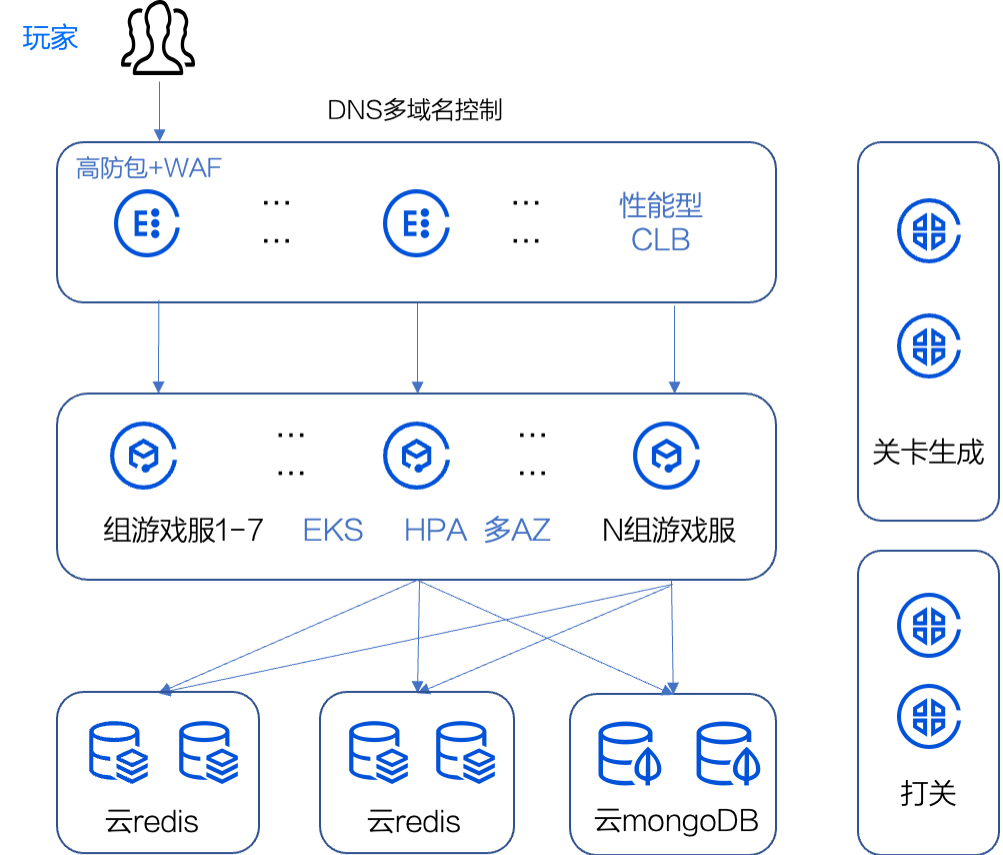
优化之后,《羊了个羊》最新技术架构
3 运维体系的升级
通过技术架构的迭代以及不断激增的用户,《羊了个羊》技术团队也认识到,因为爆火太快,更需要快速补齐运维能力,才能更好的持续调整和提升游戏体验。
在运维体系这块,包括 业务日志、性能监测等。为快速补齐运维能力,通过业务日志诊断程序性能,配合业务调优以减少服务器压力;《羊了个羊》选择了开箱即用的日志服务 云服务度 CLS,当然,有条件的团队,使用自建的 elk平台,或者基于clickhouse的高并发分布式日志监测平台,也是可以的。
CLS 对游戏接口稳定性、异常调用趋势的监控可帮助他们快速观测产品质量 ,并第一时间获取到异常panic统计分析和告警 ;在游戏运营方面,玩家登录链路耗时/对局时间等数据亦可通过 CLS 分析、校验及处理,进而调整和提升游戏体验;同时还能满足游戏用户行为及审计对账等需求。
CLS的云原生特性,辅助进行稳定性和程序性能调优。另外,CLS用作简单运维工具查日志、做接口调用告警。借助CLS的SQL分析、仪表盘、监控告警能力,可以分析出程序可优化点,解决游戏开发商在初期和爆发期对游戏稳定性和运营数据分析的难题。
除了运维数据外,CLS还提供了数据观测功能。在游戏调整玩法、分析活动数据时,运营人员可借助CLS快速观测数据变化,并作出应对策略。另外,还将游戏的通关数据、用户行为分析、审计对账等运营数据在CLS中存储分析。
4 安全防范领域的升级
哪里有流量,哪里就有黑产。许多恶意BOT流量大量涌入到游戏中,导致游戏服务器 QPS、带宽快速升高,影响服务可用性等情况。由于设计之初没有充分考虑安全问题,因此引来大量不法分子通过恶意BOT抢刷游戏排行,几乎每分每秒,都有恶意流量访问游戏接口,并且这一部分恶意群体通过互联网、QQ群和微信群中传播恶意刷排行的脚本,极大的破坏了游戏公平性,让本该属于游戏对抗的乐趣被恶意BOT抹杀。
而且更重要的是随着羊了个羊热度的不但攀升,许多恶意BOT流量的大量涌入,导致游戏服务器 QPS、带宽快速升高,一度影响服务可用性。
《羊了个羊》接入腾讯云WAF进行防护,一开始接入WAF的时候,相关 QPS 峰值已达 21W,接入WAF之前CPU一直处于临界值水位 、网络链接打满的导致服务不可用的情况。
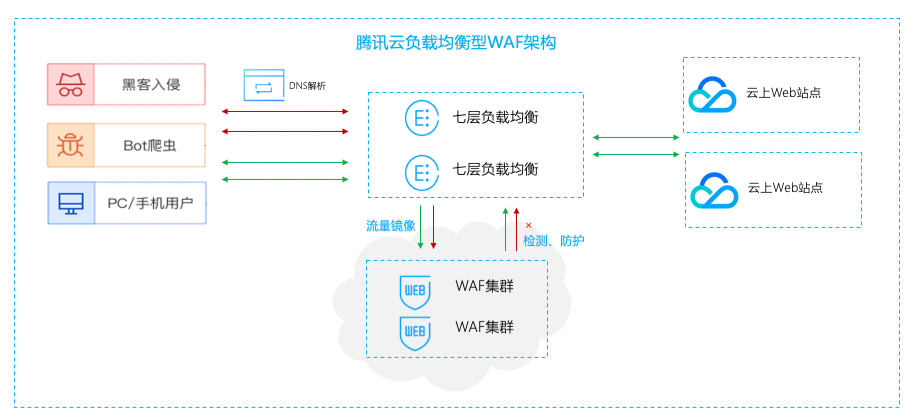
通过选择负载均衡型WAF, 即可在不改动网络架构的情况下3秒完成业务接入WAF,实现在用户无感的情况下对恶意流量进行清洗及防护。
为了有效打击攻击者的恶意流量,WAF 中 BOT 行为管理也提供了全链路、全生命周期的的恶意行为流量体系,实现快速高效的恶意流量治理。
最后在安全防范领域,通过安全方案抵抗异常流量攻击。
5 互联网应用设计的“三高”原则
通过《羊了个羊》团队在小游戏架构扩容、系统运维以及安全防范领域的实战经验,可以给大家一些参考。
面对突发流量,互联网应用在设计的过程中需要考虑以下能力:
第一是「高并发」,能够承载瞬时爆发流量,保证响应时长在可接受的范围;
其次是「高可用」,系统持续提供服务,小概率发生宕机时,过载保护将故障控制在可承受范围内,不影响核心业务;
最后是「高扩展」,服务系统应该具备水平和垂直扩展能力,在成本和可用性中实现最佳平衡点。
CPU狂飙900%处理方案
CPU飙升200%场景
场景:1:MySQL进程飙升900%
数据库执行查询或数据修改操作时,系统需要消耗大量的CPU资源维护从存储系统、内存数据中的一致性。并发量大并且大量SQL性能低的情况下,比如字段是没有建立索引,则会导致快速CPU飙升,如果还开启了慢日志记录,会导致性能更加恶化。生产上有MYSQL 飙升900% 的恶劣情况。
场景2:Java进程飙升900%
一般来说Java 进程不做大量 CPU 运算,正常情况下,CPU 应该在 100~200% 之间,但是,一旦高并发场景,要么走到了死循环,要么就是在做大量的 GC, 容易出现这种 CPU 飙升的情况,CPU飙升900%,是完全有可能的。
其他场景:其他的类似进程飙升900%的场景
比如Redis、Nginx等等。
场景一:MySQL进程CPU飙升到900%,怎么处理?
定位过程:
-
使用top 命令观察,确定是mysqld导致还是其他原因。
-
如果是mysqld导致的,show processlist,查看session情况,确定是不是有消耗资源的sql在运行。
-
找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
处理过程:
-
kill 掉这些线程(同时观察 cpu 使用率是否下降), 一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。
-
进行相应的调整(比如说加索引、改 sql、改内存参数)
index是否缺失,如果是,则建立索引。也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
-
优化的过程,往往不是一步完成的,而是一步一步,执行一项优化措辞,再观察,再优化。
场景1的真实案例:MySQL数据库优化的真实案例
之前开发同事编写的SQL语句,就导致过线上CPU过高,MySQL的CPU使用率达到900%+,通过优化最后降低到70%~80%。下面说说个人在这个过程中的排查思路。
首先,我们要对问题定位而不是盲目的开启什么 慢日志,在并发量大并且大量SQL性能低的情况下,开启慢日志无意是将MySQL推向崩溃的边缘。
当时遇到这个情况,分析了当前的数据量、索引情况、缓存使用情况。目测数据量不大,也就几百万条而已。接下来就去定位索引、缓存问题。
-
经过询问,发现很多查询都是走MySQL,没有用到缓存。
-
既然没有用到缓存,则是大量请求全部查询MySQL导致。通过下面的命令查看:
show processlist;
发现类似很多相同的SQL语句,一直处于query状态中。
select id form user where user_code = 'xxxxx';
初步分析可能是 user_code 字段没有索引导致。接着查询user表的索引情况:
show index form user;
发现这个字段是没有建立索引。增加索引之后,该条SQL查询能够正常执行。
3、没隔一会,又发生大量的请求超时问题。接着进行分析,发现是开启了 慢日志查询。大量的SQL查询语句超过慢日志设置的阀值,于是将慢日志关闭之后,速度瞬间提升。CPU的使用率基本保持在300%左右。但还不是理想状态。
4、紧接着将部分实时查询数据的SQL语句,都通过缓存(redis)读写实现。观察一段时间后,基本维持在了70%~80%。
总结:其实本次事故的解决很简单,就是添加索引与缓存结合使用。
-
不推荐在这种CPU使用过高的情况下进行慢日志的开启。因为大量的请求,如果真是慢日志问题会发生日志磁盘写入,性能贼低。
-
直接通过MySQL show processlist命令查看,基本能清晰的定位出部分查询问题严重的SQL语句,在针对该SQL语句进行分析。一般可能就是索引、锁、查询大量字段、大表等问题导致。
-
再则一定要使用缓存系统,降低对MySQL的查询频次。
-
对于内存调优,也是一种解决方案。
场景2展开:Java进程CPU飙升到900%,怎么处理?
定位过程:
CPU飙升问题定位的一般步骤是:
-
首先通过top指令查看当前占用CPU较高的进程PID;
-
查看当前进程消耗资源的线程PID:top -Hp PID
-
通过print命令将线程PID转为16进制,根据该16进制值去打印的堆栈日志内查询,查看该线程所驻留的方法位置。
-
通过jstack命令,查看栈信息,定位到线程对应的具体代码。
-
分析代码解决问题。
处理过程:
-
如果是空循环,或者空自旋。
处理方式:可以使用Thread.sleep或者加锁,让线程适当的阻塞。
-
在循环的代码逻辑中,创建大量的新对象导致频繁GC。比如,从mysql查出了大量的数据,比如100W以上等等。
处理方式:可以减少对象的创建数量,或者,可以考虑使用 对象池。
-
其他的一些造成CPU飙升的场景,比如 selector空轮训导致CPU飙升 。
处理方式:参考Netty源码,无效的事件查询到了一定的次数,进行 selector 重建。
Java的CPU 飙升700%优化的真实案例
最近负责的一个项目上线,运行一段时间后发现对应的进程竟然占用了700%的CPU,导致公司的物理服务器都不堪重负,频繁宕机。针对这类java进程CPU飙升的问题,要怎么去定位解决呢?
采用top命令定位进程
登录服务器,执行top命令,查看CPU占用情况,找到进程的pid
top
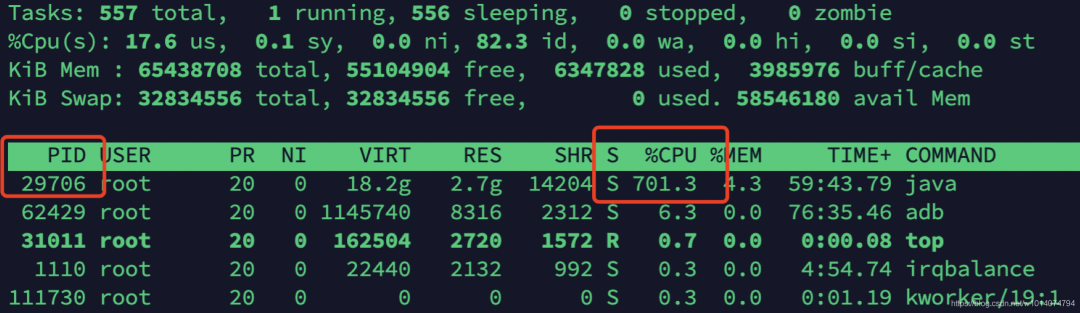
很容易发现,PID为29706的java进程的CPU飙升到700%多,且一直降不下来,很显然出现了问题。
使用top -Hp命令定位线程
使用 top -Hp命令(为Java进程的id号)查看该Java进程内所有线程的资源占用情况(按shft+p按照cpu占用进行排序,按shift+m按照内存占用进行排序)
此处按照cpu排序:
top -Hp 23602
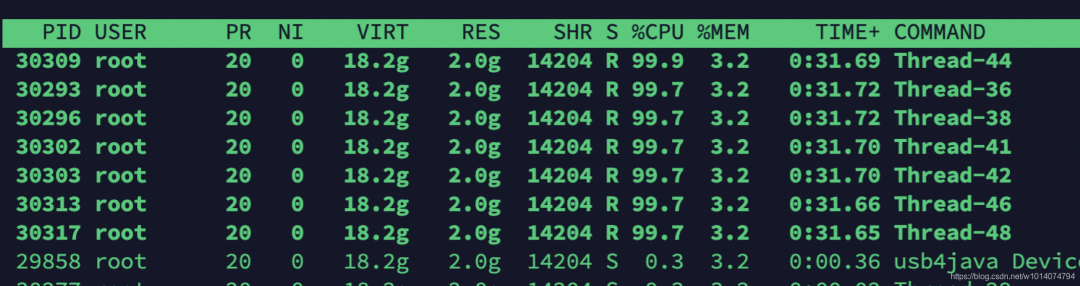
很容易发现,多个线程的CPU占用达到了90%多。我们挑选线程号为30309的线程继续分析。
使用jstack命令定位代码
1.线程号转换5为16进制
printf “%x\n” 命令(tid指线程的id号)将以上10进制的线程号转换为16进制:
printf "%x\n" 30309

转换后的结果分别为7665,由于导出的线程快照中线程的nid是16进制的,而16进制以0x开头,所以对应的16进制的线程号nid为0x7665
2.采用jstack命令导出线程快照
通过使用dk自带命令jstack获取该java进程的线程快照并输入到文件中:
jstack -l 进程ID > ./jstack_result.txt
命令(为Java进程的id号)来获取线程快照结果并输入到指定文件。
jstack -l 29706 > ./jstack_result.txt
3.根据线程号定位具体代码
在jstack_result.txt 文件中根据线程好nid搜索对应的线程描述
cat jstack_result.txt |grep -A 100 7665

根据搜索结果,判断应该是ImageConverter.run()方法中的代码出现问题。当然,这里也可以直接采用
jstack <pid> |grep -A 200 <nid>
来定位具体代码
$jstack 44529 |grep -A 200 ae24
"System Clock" #28 daemon prio=5 os_prio=0 tid=0x00007efc19e8e800 nid=0xae24 waiting on condition [0x00007efbe0d91000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrentC.TimeUnit.sleep(TimeUnit.java:386)
at com.*.order.Controller.OrderController.detail(OrderController.java:37) //业务代码阻塞点
分析代码解决问题
下面是ImageConverter.run()方法中的部分核心代码。
逻辑说明:
/存储minicap的socket连接返回的数据(改用消息队列存储读到的流数据),设置阻塞队列长度,防止出现内存溢出
//全局变量
private BlockingQueue<byte[]> dataQueue = new LinkedBlockingQueue<byte[]>(100000);
//消费线程
@Override
public void run() {
//long start = System.currentTimeMillis();
while (isRunning) {
//分析这里从LinkedBlockingQueue
if (dataQueue.isEmpty()) {
continue;
}
byte[] buffer = device.getMinicap().dataQueue.poll();
int len = buffer.length;
}
在while循环中,不断读取堵塞队列dataQueue中的数据,如果数据为空,则执行continue进行下一次循环。如果不为空,则通过poll()方法读取数据,做相关逻辑处理。
初看这段代码好像每什么问题,但是如果dataQueue对象长期为空的话,这里就会一直空循环,导致CPU飙升。那么如果解决呢?
分析LinkedBlockingQueue阻塞队列的API发现:
//取出队列中的头部元素,如果队列为空则调用此方法的线程被阻塞等待,直到有元素能被取出,如果等待过程被中断则抛出InterruptedException
E take() throws InterruptedException;
//取出队列中的头部元素,如果队列为空返回null
E poll();
这两种取值的API,显然take方法更时候这里的场景。代码修改为:
while (isRunning) {
/* if (device.getMinicap().dataQueue.isEmpty()) {
continue;
}*/
byte[] buffer = new byte[0];
try {
buffer = device.getMinicap().dataQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
……
}
重启项目后,测试发现项目运行稳定,对应项目进程的CPU消耗占比不到10%。
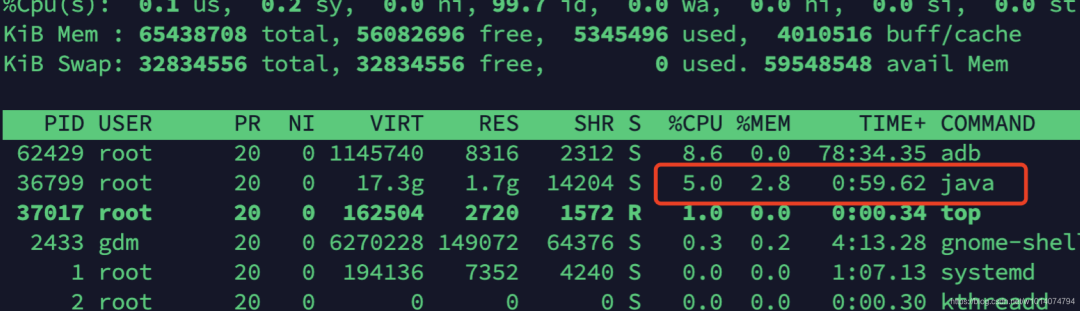
参考文献:
https://developer.aliyun.com/article/1053255
https://www.zhihu.com/question/22002813/answer/2662962349
人人可以用的代码优化案例
人人用得着的案例:后端接口返回结果的二次封装优化
场景
在移动互联网,分布式、微服务盛行的今天,现在项目绝大部分都采用的微服务框架,前后端分离方式,一般系统的大致整体架构图如下:
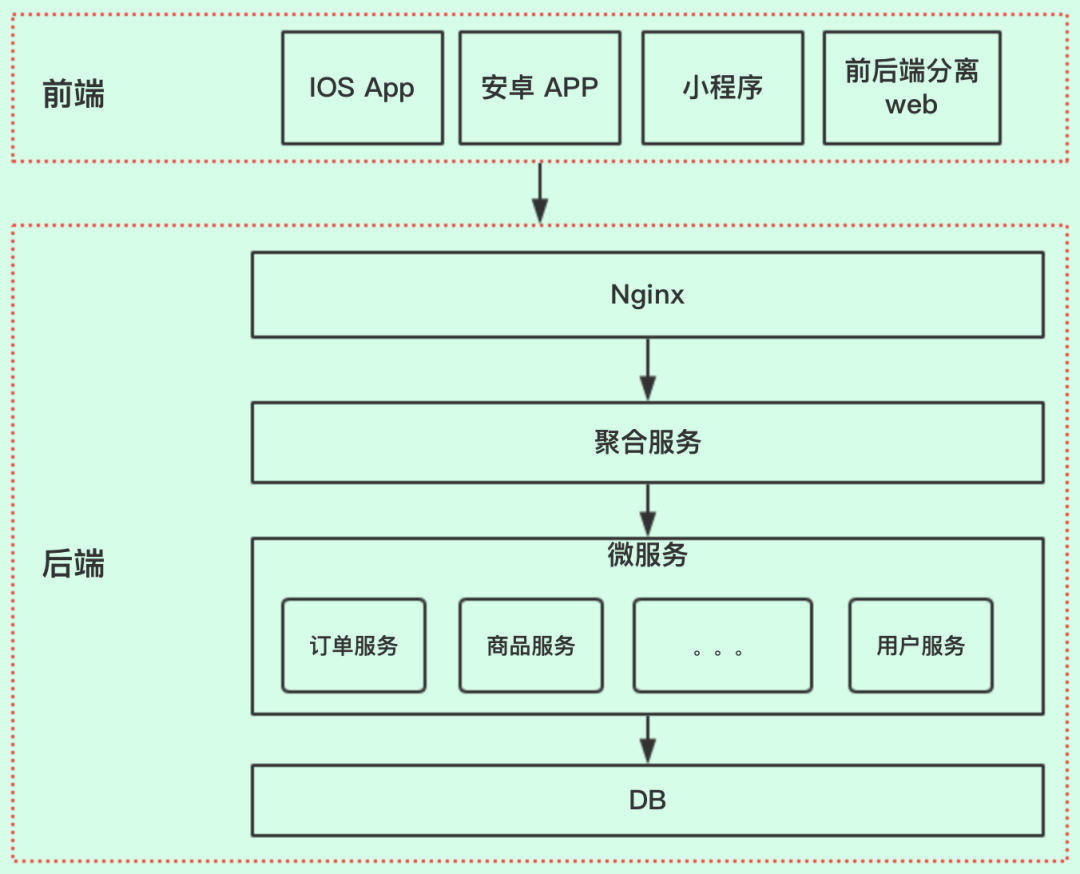
Rest API 接口交互
前端和后端进行交互,前端按照约定请求URL路径,并传入相关参数,后端服务器接收请求,进行业务处理,返回数据给前端。
返回格式
后端返回给前端我们一般用JSON体方式,定义如下:
{
#返回状态码
code:integer,
#返回信息描述
message:string,
#返回值
data:object
}
CODE状态码
code返回状态码,一般是在开发的时候需要什么,就添加什么。如接口要返回用户权限异常,加一个状态码为101吧,下一次又要加一个数据参数异常,就加一个102的状态码。这样虽然能够照常满足业务,但状态码太凌乱了。
参考HTTP请求返回的状态码:
下面是常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
| 分类 | 区间 | 分类描述 |
|---|---|---|
| 1** | 100~199 | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 200~299 | 成功,操作被成功接收并处理 |
| 3** | 300~399 | 重定向,需要进一步的操作以完成请求 |
| 4** | 400~499 | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 500~599 | 服务器错误,服务器在处理请求的过程中发生了错误 |
可以参考这样的设计,这样的好处就把错误类型归类到某个区间内,如果区间不够,可以设计成4位数。
#1000~1999 区间表示参数错误
#2000~2999 区间表示用户错误
#3000~3999 区间表示接口异常
这样前端开发人员在得到返回值后,根据状态码就可以知道,大概什么错误,再根据message相关的信息描述,可以快速定位。
Message
这个字段相对理解比较简单,就是发生错误时,如何友好的进行提示。一般的设计是和code状态码一起设计,如:
//状态码枚举
public enum ResultCode {
private Integer code;
private String message;
ResultCode(Integer code, String message) {
this.code = code;
this.message = message;
}
}
再在枚举中定义,状态码:
返回状态码
public enum ResultCode {
privateInteger code;
private String message;
ResultCode(Integer code,String message) {
this.code = code;
this.message = message;
}
public Integer code(){
return this.code;
}
public String message() {
return this.message;
}
/* 成功状态码 */
SUCCESS(1,"成功"),
/* 参数错误: 1001-1999 */
PARAM IS INVALID(1001,"参数无效"),
PARAM IS BLANK(1002,"参数为空"),
PARAM TYPE BIND ERROR(1003,"参数类型错误"),
PARAM NOT_COMPLETE(1004,"参数缺失"),
/* 用户错误: 2001-2999*/
USER NOT_LOGGED IN(2001,"用户未登录,访问的路径需要验证,请登录"),
USER LOGIN ERROR(2002,"账号不存在或密码错误"),
USER ACCOUNT FORBIDDEN(2003,"账号已被禁用"),
USER NOT_EXIST(2004,"用户不存在"),
USER HAS EXISTED(2005,"用户已存在")
}
状态码和信息就会一一对应,比较好维护。
Data
返回数据体,JSON格式,根据不同的业务又不同的JSON体。设计一个返回体类Result:
@aData
public class Result implements Serializable {
private Integer code;
private String message;
private Object data;
public Result(ResultCode resultCode, Object data) {
this.code = resultCode.code;
this.message = resultCode.message();
this.data = data;
}
}
控制层Controller
在controller层处理业务请求,并返回给前端,以order订单为例:
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("{id}")
public Result getOrder(@PathVariable("id") Integer id) {
Order order = orderService.getOrderById(id);
Result result = new Result(ResultCode.SUCCESS,order);
return result;
}
}
看到在获得order对象之后,我们是用的Result构造方法进行包装赋值,然后进行返回。
美观优化
可以在Result类中,加入静态方法:
@Data
public class Result implements Serializable {
//省。。
//返回成功
public static Result success() {
Result result = new Result();
result.setResultCode(ResultCode.SUCCESS);
return result;
}
//返回成功
public static Result success(Object data) {
Result result = new Result();
result.setResultCode(ResultCode.SUCCESS);
result.setData(data);return result;
}
//返回失败
public static Result failure(ResultCode resultCode) {
Result result = new Result();
result.setResultCode(resultCode);
return result;
}
//返回失败
public static Result failure(ResultCode resultCode, Obiect data){
Result result = new ResultO;
result.setResultCode(resultCode);
result.setData(data);
return result;
}
}
改造一下Controller:
@RestController
@RequestMapping("/orders")
public class OrderController [
@Autowired
private OrderService orderService;
GetMapping("{id}")
public Result getOrder(@PathVariable("id") Integer id) {
if(id == null){
return Result.failure(ResultCode.PARAM IS INVALID);
}
Order order = orderService.getOrderById(id);
return Result.success(order);
}
}
切面式思想优化
在Result类中增加了静态方法,使得业务处理代码简洁。但这样有几个问题:
1、每个方法的返回都是Result封装对象,没有业务含义。
2、在业务代码中,成功的时候我们调用Result.success,异常错误调用Result.failure,是不是多余?
3、上面的代码,判断id是否为null,其实我们可以使用hibernate validate做校验,没有必要在方法体中做判断。
具体解决的宏观的思路:
可以应用切面式的思想,把Rest外层包装抽取到切面中,而不是放在业务代码中,从而让业务代码回归业务本身,更为逻辑清晰、结构简单。
优化之后的效果是,业务Controller直接返回真实业务对象,最好不要改变之前的业务方式,如下图:
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("{id}")
public Order getOrder(PathVariable("id") Integer id) {
Order order = orderService.getOrderById(id);
return roder;
}
}
业务代码我们平时的代码是一样的,非常直观,直接返回order对象,这样是不是很完美。
切面式的实现方案
1、定义一个注解@ResponseResult,表示这个接口返回的值需要包装一下
2、拦截请求,判断此请求是否需要被@ResponseResult注解
3、核心步骤就是实现接口ResponseBodyAdvice和@ControllerAdvice,判断是否需要包装返回值,如果需要,就把Controller接口的返回值进行重写。
注解类
定义一个注解类,用来标记方法的返回值是否需要包装
@Retention(RUNTIME)
@Target({ TYPE,METHOD })
@Documented
public @interface ResponseResult {
}
拦截器
拦截请求,是否此请求返回的值需要包装,其实就是运行的时候,解析@ResponseResult注解
//请求拦截器
@slf4j
@Component
public class ResponseResultInterceptor implements HandlerInterceptor{
//标记名称
public static final String RESPONSE_RESULT_ANN = "RESPONSE-RESULT-ANN";
@Override
public boolean preHandle(HttpServletRequest reguest, HttpServletResponse response, Object handler)throws Exception {
//请求的方法
if(handler instanceof HandlerMethod){
final HandlerMethod handlerMethod = (HandlerMethod)handler;
final Class<?> clazz = handlerMethod.getBeanType();
final Method method = handlerMethod.getMethod();
//判断是否在类对象上面加了注解
if (clazz.isAnnotationPresent(ResponseResult.class)) {
//设置此请求返回体,需要包装,往下传递,在ResponseBodyAdvice接口进行判断
request.setAttribute(RESPONSE_RESULTANN,clazz.getAnnotation(ResponseResult.class));
}else if (method.isAnnotationPresent(ResponseResult,class)) { //方法体上是否有注解
//设置此请求返回体,需要包装,往下传递,在ResponseBodyAdvice接口进行判断
request.setAttribute(RESPONSE_RESULT_ANN,method.getAnnotation(ResponseResult.class));
}
}
return true;
}
}
此代码核心思想,就是获取此请求,根据注解判断是否需要返回值包装,并且在request上设置一个属性标记。
重写返回体
@slf4j
@ControllerAdvice
public class ResponseResultHandler implements ResponseBodyAdvice<Object>{
//标记名称
public static final String RESPONSE_RESULTANN = "RESPONSE-RESULT-ANN";
//是否请求 包含了 包装注解 标记,没有就直接返回,不需要重写返回体
@Override
public boolean supports (MethodParameter returntype, Class<? extends HttpMessagelonverter<?>> convertertype){
ServletRequestAttributes ra = ((ServletRequestAttributes) RequestContextHolder getRequestAttributes());
HttpServletRequest request = sra.getRequest();
//判断请求 是否有包装标记
ResponseResult responseResultAnn = (ResponseResult) request,getAttribute(RESPONSE RESULT_ANN);
return responseResultAnn == null ? false : true;
}
@Override
public Object beforeBodyWrite(0bject body, MethodParameter returnType, MediaType selectedContentTypeClass<? extends HttpMessageConverter<?>> selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
log.info("进入 返回体 重写格式 处理中。。。。。");
return Result.success(body);
}
}
上面supports 代码就是判断是否需要返回值包装,如果需要(support返回true)就直接进入 beforeBodyWrite包装。这里我们只处理了正常成功的包装,如果方法体报异常怎么办?
处理异常也比较简单,只要判断body是否为异常类。
@Override
public Object beforeBodywrite(0bject body, MethodParameter returnType, MediaType selectedContentType, Class<? extends HttpMessageConverter<?>> selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
log.info("进入 返回体 重写格式 处理中。。。。");
if (body instanceof ErrorResult) {
log.info("返回值 异常 作包装 处理中。。。");
ErrorResult errorResult = (ErrorResult) body;
return Result.failure(errorResult.getCode(),errorResult, getMessage ),errorResult, getErrors());
}
return Result.success(body);
}
怎么做全局的异常处理,实现方式有两种
-
第一种:使用@ControllerAdvice和@ExceptionHandler注解
-
第二种: 使用ErrorController类来实现。
参考ResponseBodyAdvice,对返回结果,进行二次包装就可以了。
重新Controller
@RestController
@RequestMapping("/orders")
@ResponseResult
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("{id}")
public Order getOrder(PathVariable("id") Integer id) {
Order order = orderService.getOrderById(id);
return roder;
}
}
在控制器类上或者方法体上加上@ResponseResult注解。
那么,这个方案还有没有别的优化空间,当然是有的。
如:每次请求都要反射一下,获取请求的方法是否需要包装,其实可以做个缓存,不需要每次都需要解析。
10亿级ES海量搜索狂飙10倍优化
措施一:调大内存,缓存越大越好
调大内存,缓存越大越好,主要指的是Filesystem Cache越大越好。
为什么要调大Filesystem Cache呢?
ES查询的时候,会有大量的mmap操作,在mmap操作的时候,OS会将磁盘文件里的segment数据,加载到 Filesystem Cache 缓存里面去。ES严重依赖于底层的 filesystem cache,你如果给 filesystem cache 更多的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,那么在搜索的时候,就基本都是走内存的,性能会非常高。
性能差距究竟可以有多大?
据压测,如果通过磁盘IO完成搜索,一般秒级返回。但如果是走 filesystem cache,那么一般来说性能比走磁盘IO要快一个数量级,基本上就是10ms、50ms、100ms、几百毫秒不等。
提升性能的策略是,提升内存命中的比例,两个思路:
-
拼命调大内存。
-
减少索引 index 索引大小。
所以:亿级索引、海量索引的调优措施之一,简单来讲,希望全部命中在内存,而不是在磁盘。
或者说:如果缓存不了全部数据,那就至少可以容纳你的总数据量的一半。目标就一个:还是把索引加载到内存,或者至少能加载一半。
措施二:缩容,缩小 index 索引
比如有一行数据,id,name,age .... 30 个字段。而搜索的时候,只需要根据 name,age 2个字段来搜索。这样搜索的时候,其余的28个字段是和搜索无关的,占了90%以上。结果这部分搜索无关数据,硬是占据了 es 机器上的 filesystem cache 的空间,单条数据的数据量越大,就会导致 filesystem cahce 能缓存的数据就越少。
所以,优化的策略就是,减少索引index 数据量。仅仅写入 es 中要用来检索的少数几个字段就可以了,比如说就写入id,name,age 三个字段。
在哪里存放全量数据呢?
一般是建议用 es + hbase 架构。es中保存hbase的key, 根据key 去habse取全量数据。
hbase 的特点是适用于海量数据的在线存储,就是对 hbase 可以写入海量数据,但是不要做复杂的搜索。当然,在hbase中做很简单的一些根据 rowkey或者范围进行查询的这么一个操作就可以了。
用 es + hbase 架构,从 es 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 rowkey,然后根据rowkey(doc id)到 hbase 里去查询每个 doc id 对应的完整的数据,给查出来,再返回给前端。
优化的结果:
然后你从 es 检索可能就花费 100ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 100ms,
-
架构整改之前,1T 数据都放 es,会每次查询都是 5~10s
-
架构整改之后,现在可能性能就会很高,每次查询就是 200ms。
结论:性能提升50倍多。
措施三:冷热分离
如果索引的数据量,还是减不下来,怎么办?
比如,索引瘦身之后,还是有300G,而 filesystem cache 只有100G,索引大小,远远大于内存大小,怎么办?
方法之1:冷热分离
方式之2:数据预热
方式之3:.....
怎么做冷热分离呢?
-
冷数据:将大量的访问很少、频率很低的数据,单独写一个索引,
-
热数据:将大量的访问很大、频率很高的数据,单独写一个索引,
目标还是一个:搜索的时候进行内存IO,而不是磁盘IO。这样可以确保热数据在被加载到filesystem os cache 之后。
怎么能保证冷索引,不把热索引从内存挤出去呢?
这个主要是 Linux 内核的 LRU内存淘汰算法导致的,当系统内存不足时,Memcached 和 Redis 都是使用 LRU算法 来淘汰内存的。
LRU(Least Recently Used)最近最少使用 的意思,其原理就是:当内存不足时,淘汰系统中最少使用的内存,这样对系统性能的损耗是最小的。
一般来说,由于热数据频繁访问,一般就会比较高的概率留在 filesystem os cache 里,不会让冷数据给冲刷掉。
假设有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 shard。
大量的时间是在访问热数据 index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都驻留 filesystem cache 里面了,就可以通过内存IO完成,而不是磁盘IO,从而实现性能优化。少量的冷数据访问,可能大量数据是在磁盘上的,此时性能差点,也无所谓了。
冷热分离之后,保障了90%的请求在1s以内。
措施四:数据预热
冷热分离之后,如何确保热数据,一直处于 filesystem cache 里?有效的措施是:数据预热。
怎么做数据预热呢?
简单的说,就是提前访问一下,让数据进入 filesystem cache 里面去。复杂点的措施,就是做一个专门的缓存预热子系统,就是对热数据每隔一段时间,访问一下,让数据进入 filesystem cache 里面去。
哪些是热点数据呢?怎识别热点数据呢?
比如电商秒杀,你可以将平时查看最多的一些商品,比如说 iphone 8,可以提前访问一次,刷到 filesystem cache 里去。搜索的时候,直接从内存里搜索了,没有走磁盘IO,速度很快。
有些热点数据是可以提前预知的,但是更多的热点数据,不实时产生的的,怎么办?
这里涉及到 热点探测系统。有了,缓存预热子系统可以和热点探测子系统结合,进行 动态的缓存预热。提前预热之后,数据已经到了缓存,这样下次别人访问的时候,性能一定会好很多。
措施五:索引模型优化
在ES的优化中,索引模型优化、或者说索引结构优化,也很重要。ES能支持的操作就那么多,很多操作性能低,不要在搜索的时候,执行各种复杂的乱七八糟的操作。
换句话说,对索引进行优化的时候,直接索引最终的结果数据,而不是过程数据、中间数据。最好是先在 Java 系统里就完成数据的处理,比如说数据的关联,将关联好的数据直接写入 ES 中。搜索的时候,就不需要利用 es 的搜索语法来完成 join 之类的关联搜索了。对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的。如果真的有那种操作,尽量在 document 模型设计的时候,写入的时候就完成。另外对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的。
关于索引结构的优化,有非常多的优化手段,根据自己的场景去定制化使用:
-
字段拉平:将复合字段拆分为多个不同字段,查询时减少查询的字段个数。
-
提前建立 mapping:预先建立 mapping,而不是让 ES 自动生成数据类型,加速检索。
-
使用 keyword 代替 int/long/numeric,
为啥使用 keyword 代替 int/long/numeric?
对于keyword类型的term query,ES使用的是倒排索引。但是numeric类型为了能有效的支持范围查询,它的存储结构并不是倒排索引。
倒排索引在内存里维护了词典 (Term Dictionary)和文档列表(Postings List)的映射关系,倒排索引本身对于精确匹配查询是非常快的,直接从字典表找到term,然后就直接找到了posting list。
措施六:查询优化
查询优化的措施太多:
-
分页性能优化
-
能用term就不用match_phrase
-
使用过滤器优化查询
查询优化1:分页性能优化
ES 的分页是较坑的,为什么?
举个例子吧,假如每页是 100 条数据,现在要查询第 10页, 分页的时候,总共需要查到 1000条,再截取一个page。如果有个 3 个 shard,实际上是会把每个 shard 上存储的前 1000 条数据,都查到一个协调节点上,那么协调节点就有3000 条数据,接着协调节点对这 3000 条数据进行一些合并、处理,再获取到最终第 10 页的 10 条数据。
ES必须得从每个 shard 都查 1000 条数据过来,然后根据你的需求进行排序、筛选等等操作,最后再次分页,拿到里面第 10 页的数据。翻页的时候,翻的越深,比如 1000,每个 shard 返回的数据就越多,而且协调节点处理的时间越长。用 ES 作分页,前几页就几十毫秒,翻到 10 页或者几十页的时候,基本上就要 5~10 秒才能查出来一页数据了。
那么怎么做分页性能优化?简单的措施:就是限制翻页的数量,不让翻到很大的page。
为什么可以这么处理?实际上,搜索引擎返回的结果,都是模糊匹配的,越到后面,结果越模糊, 对用户的价值不大。一般情况下,追求前几页,提供给用户价值大的结果。很多搜索系统,不提供大页码的翻页。
查询优化2:能用term就不用match_phrase
The Lucene nightly benchmarks show that a simple term query is about 10 times as fast as a phrase query, and about 20 times as fast as a proximity query (a phrase query with slop).
官方说:
-
term查询比match_phrase性能要快10倍,
-
term查比带slop的match_phrase(proximity——match)快20倍。
能用term就不用match_phrase,举个简单例子
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "quick fox"
}
}
}
变为
GET /my_index/my_type/_search
{
"query": {
"term": {
"title": "quick fox"
}
}
match_phrase的执行流程如下?
match_phrase查询首先解析查询字符串,产生一个词条列表。然后会搜索所有的词条,但只保留包含了所有搜索词条的文档,并且词条的位置要邻接。比如,搜索 quick fox时,如果没有文档含有邻接在一起的quick和fox词条, 一个针对短语quick fox的查询不会匹配我们的任何文档。
proximity match: slop参数告诉match_phrase查询词条能够相隔多远时仍然将文档视为匹配。
为了让查询quick fox能够匹配含有quick brown fox的文档,我们需要slop的值为1.
match和match_phrase的区别
match: 只要简单的匹配到了一个term,就会将term对应的文档作为结果返回,扫描倒排索引,扫描到了就完事。
match_phrase: 首先要扫描到所有term的文档列表,找到包含所有term的文档列表,然后对每个文档都计算每个term的position,是否符合指定的范围,需要进行复杂的运算,才能判断能否通过slop移动,匹配到这个文档。
match和match_phrase的性能比较
match 的性能比match_phrase和proximity match(有slop的match_phrase)要高得多。因为后两者都需要计算position的距离。
match query比match_phrase的性能要高10倍,比proximity match(有slop的match phrase)要高20倍。
但是Elasticsearch性能是很强大的,基本都在毫秒级。match可能是几毫秒,match phrase和proximity match也基本在几十毫秒和几百毫秒之前。
那么,如何对match和match_phrase的性能优化?
具体的措施是:先缩小范围,再打分。
具体来说,优化match_phrase和proximity match的性能,一般就是减少要进行proximity match搜索的文档的数量。
主要的思路就是用match query先过滤出需要的数据,然后在用proximity match来根据term距离提高文档的分数,同时proximity match只针对每个shard的分数排名前n个文档起作用,来重新调整它们的分数,这个过程称之为重打分rescoring。
主要是因为一般用户只会分页查询,只会看前几页的数据,所以不需要对所有的结果进行proximity match操作。也就是使用match + proximity match同时实现召回率和精准度。
默认情况下,match也许匹配了1000个文档,proximity match需要对每个doc进行一遍运算,判断能否slop移动匹配上,然后去贡献自己的分数。但是很多情况下,match出来也许是1000个文档,其实用户大部分情况下都是分页查询的,可以就看前5页,每页就10条数据,也就50个文档。
所以,proximity match只要对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数。这个时候通过window_size这个参数即可实现限制重打分rescoring的文档数量。示例:
GET /test_index/_search
{
"query": {
"match": {
"test_field": "java spark"
}
},
"rescore": {
"query": {
"rescore_query": {
"match_phrase": {
"test_field": {
"query": "java spark",
"slop": 10
}
}
}
},
"window_size": 50
}
}
查询优化3:使用过滤器优化查询
elasticsearch提供了一种特殊的缓存,即过滤器缓存(filter cache),用来储存过滤器的结果.
被缓存的过滤器不需要消耗过多的内存,因为他们只储存了哪些文档能与过滤器相匹配的相关信息,而且可供后续所有与之相关的查询重复使用,从而极大的提高了查询性能
执行下面这个查询:
{
"query":{
"bool":{
"must":[
{
"term":{"name":"joe"}
},
{
"term":{"year":1981}
}
]
}
}
}
该查询能查询出满足指定姓名和出生年代条件的足球运动员,只有同时满足两个条件的查询才可以被缓存起来。
优化这个查询:
人名有太多可能性,它不是完美的缓存候选对象,而年代是,我们使用另一种查询方法,该查询组合了查询类型与过滤器:
{
"query":{
"filtered":{
"query":{
"term":{"name":"joe"}
},
"filter":{
"term":{"year":1981}
}
}
}
}
第一次执行该查询以后,过滤器会被es缓存起来,如果后续的其他查询也要使用该过滤器,则她会被重复使用,避免es重复加载相关数据
参考
https://blog.csdn.net/whzhaochao/article/details/49126037)
https://blog.csdn.net/wuzhangweiss/article/details/101156910)
https://blog.csdn.net/Jerome_s/article/details/44992549)
10Wqps超高流量系统,如何设计?
面对超高的并发,宏观的处理思路大致如下:
-
首先硬件层面机器要能扛得住,
-
其次架构设计做好微服务的拆分,
-
代码层面各种缓存、削峰、解耦等等问题要处理好,
-
数据库层面做好读写分离、分库分表,
-
稳定性方面要保证有监控,熔断限流降级该有的必须要有,发生问题能及时发现处理。
硬件的扩展+微服务的拆分
在互联网早期的时候,单体架构就足以支撑起日常的业务需求,大家的所有业务服务都在一个项目里,部署在一台物理机器上。所有的业务包括你的交易系统、会员信息、库存、商品等等都夹杂在一起,当流量一旦起来之后,单体架构的问题就暴露出来了,机器挂了所有的业务全部无法使用了。
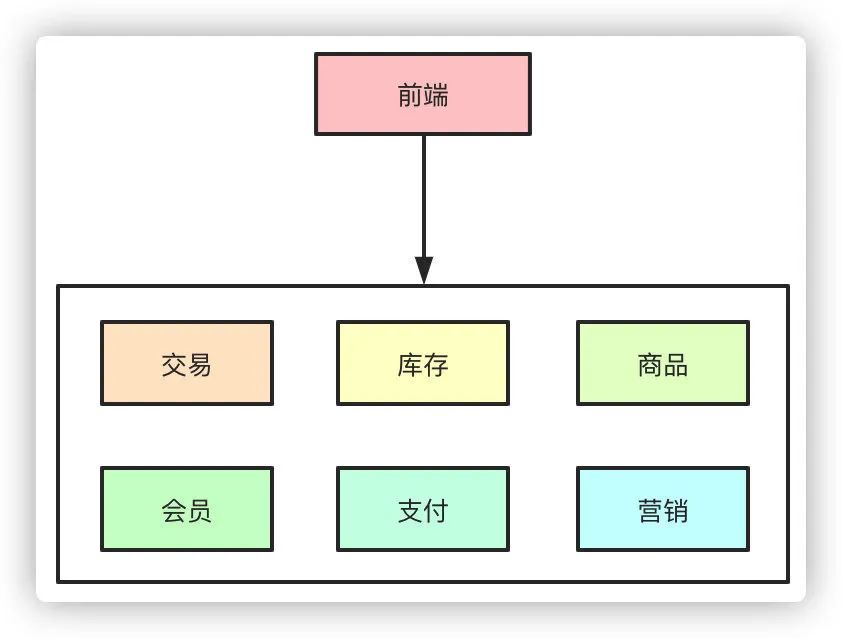
于是集群架构的架构开始出现,单机无法抗住的压力,最简单的办法就是水平拓展横向扩容了,这样,通过负载均衡把压力流量分摊到不同的机器上,暂时是解决了单点导致服务不可用的问题。
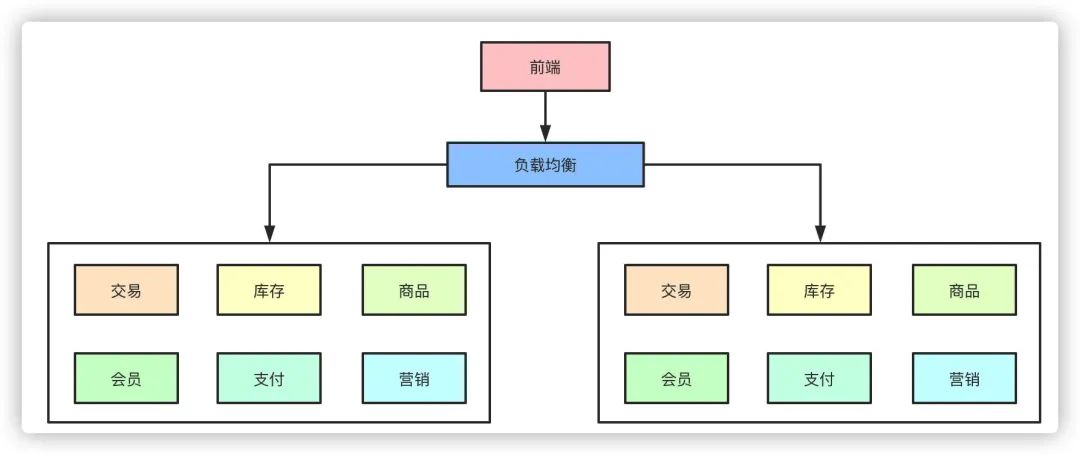
但是随着业务的发展,在一个项目里维护所有的业务场景使开发和代码维护变得越来越困难,一个简单的需求改动都需要发布整个服务,代码的合并冲突也会变得越来越频繁,同时线上故障出现的可能性越大。微服务的架构模式就诞生了。
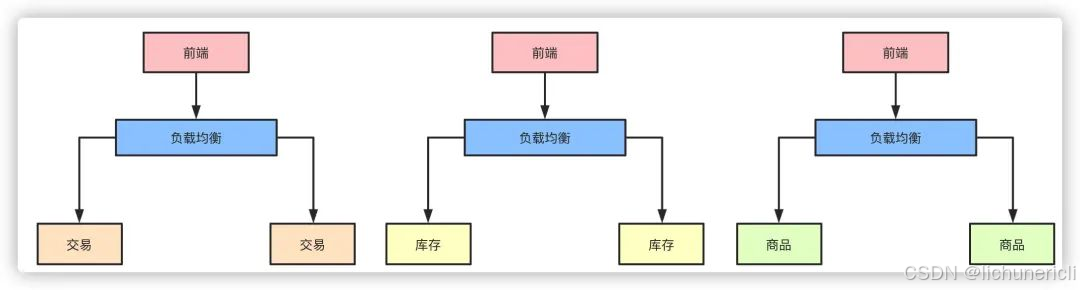
把每个独立的业务拆分开独立部署,开发和维护的成本降低,集群能承受的压力也提高了,再也不会出现一个小小的改动点需要牵一发而动全身了。
以上的点从高并发的角度而言,似乎都可以归类为通过服务拆分和集群物理机器的扩展提高了整体的系统抗压能力,那么,随之拆分而带来的问题也就是高并发系统需要解决的问题。
高性能 RPC
微服务化的拆分带来的好处和便利性是显而易见的,但是与此同时各个微服务之间的通信就需要考虑了。传统HTTP的通信方式性能首先并不太好,大量的请求头之类无效的信息是对性能的浪费,这时候就需要引入诸如Dubbo类的RPC框架。
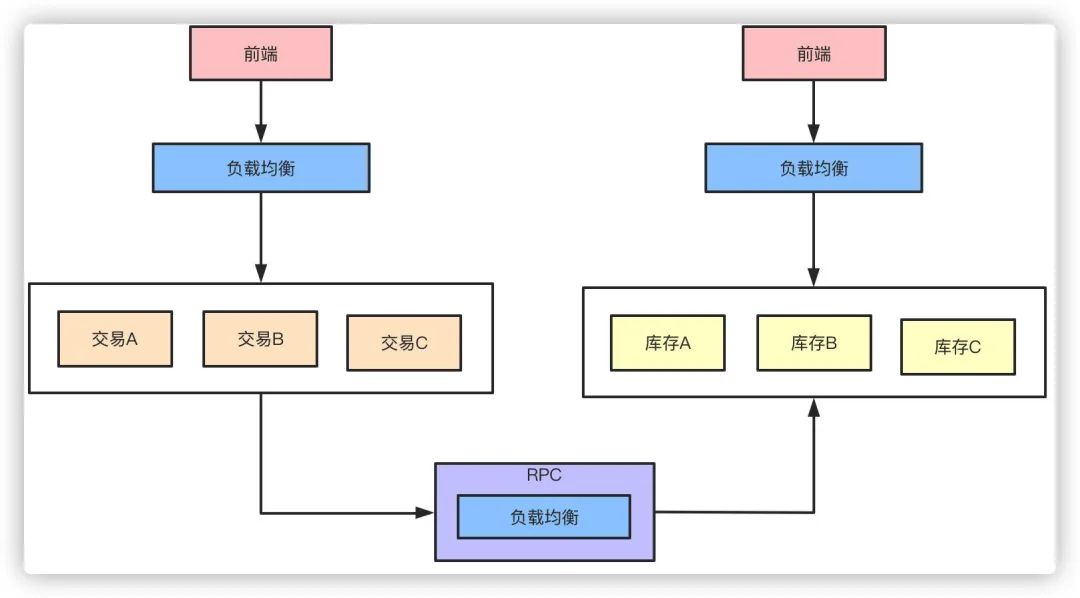
我们假设原来来自客户端的QPS是9000的话,那么通过负载均衡策略分散到每台机器就是3000,而Feign HTTP RPC 改为 Dubbo RPC 之后,接口的耗时缩短了,单体服务和整体的QPS就提升了。
而RPC框架本身一般都自带负载均衡、熔断降级的机制,可以更好的维护整个系统的高可用性。
消息队列消峰解耦
对于MQ的作用主要功能:
-
削峰填谷、解耦。
-
同步转异步的方式,可以降低微服务之间的耦合。
对于一些不需要同步执行的接口,可以通过引入消息队列的方式异步执行以提高接口响应时间。在交易完成之后需要扣库存,然后可能需要给会员发放积分,本质上,发积分的动作应该属于履约服务,对实时性的要求也不高,我们只要保证最终一致性也就是能履约成功就行了。
对于这种同类性质的请求就可以走MQ异步,也就提高了系统抗压能力了。
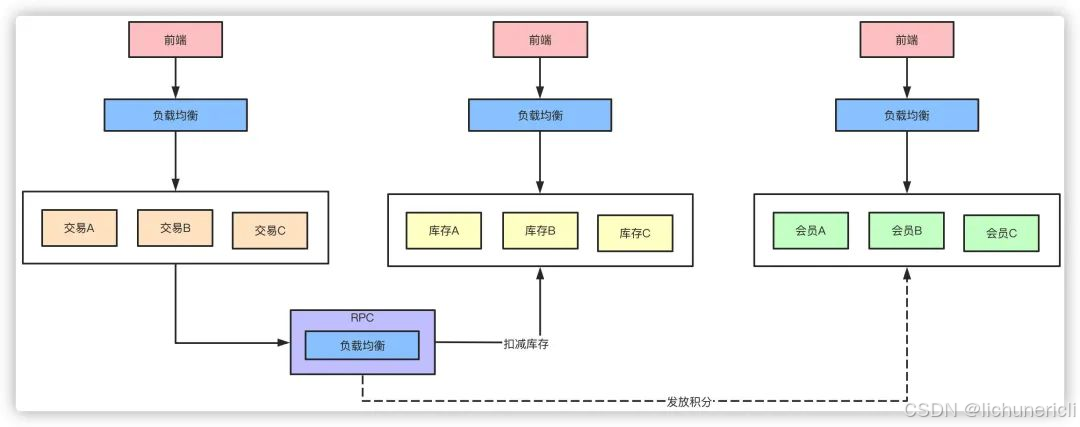
三级缓存架构
缓存作为高性能的代表,在某些特殊业务可能承担90%以上的热点流量。
对于一些活动比如秒杀这种并发QPS可能几十万的场景,引入缓存事先预热可以大幅降低对数据库的压力,10万的QPS对于单机的数据库来说可能就挂了,但是对于如redis这样的缓存来说就完全不是问题。
以秒杀系统举例,活动预热商品信息可以提前缓存提供查询服务,库存数据可以提前缓存,下单流程可以完全走缓存扣减,秒杀结束后再异步写入数据库,数据库承担的压力就小的太多了。
数据库分库分表
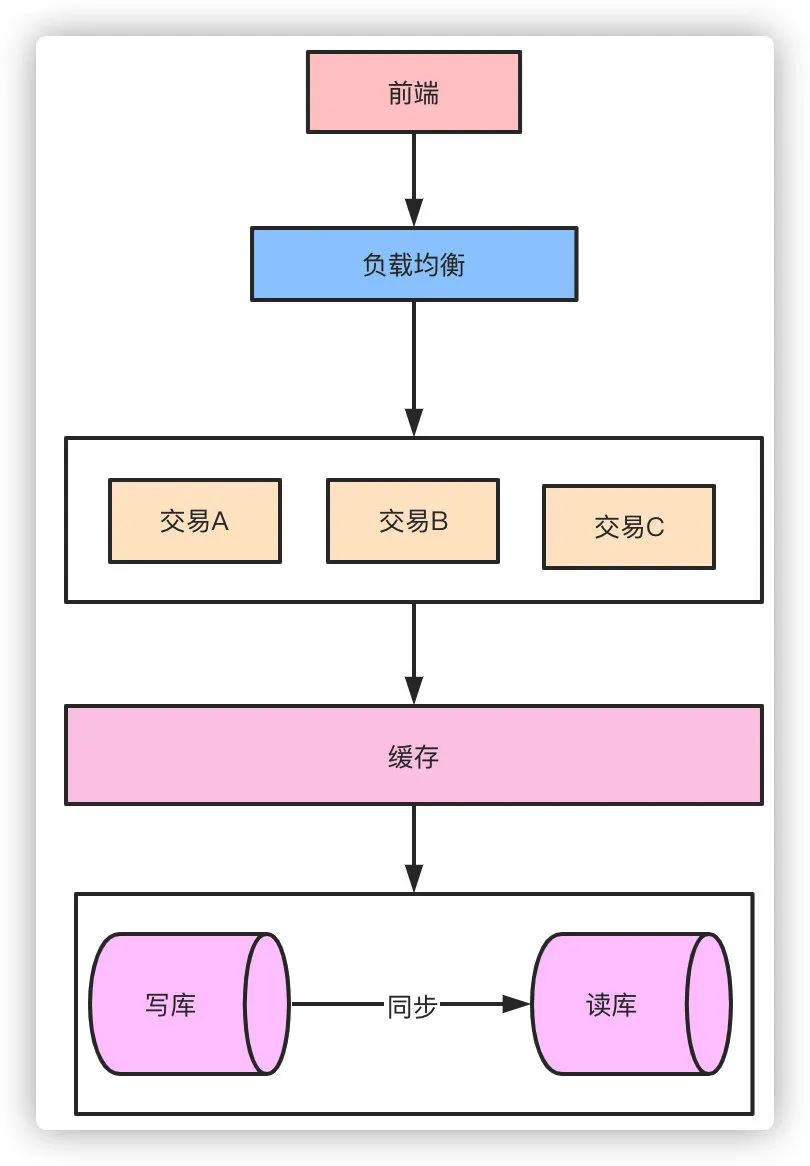
对于整个系统而言,最终所有的流量的查询和写入都落在数据库上,数据库是支撑系统高并发能力的核心。
怎么降低数据库的压力,提升数据库的性能是支撑高并发的基石。主要的方式就是通过读写分离和分库分表来解决这个问题。
对于整个系统而言,流量应该是一个漏斗的形式。比如我们的日活用户DAU有20万,实际可能每天来到提单页的用户只有3万QPS,最终转化到下单支付成功的QPS只有1万。
那么对于系统来说读是大于写的,这时候可以通过读写分离的方式来降低数据库的压力。
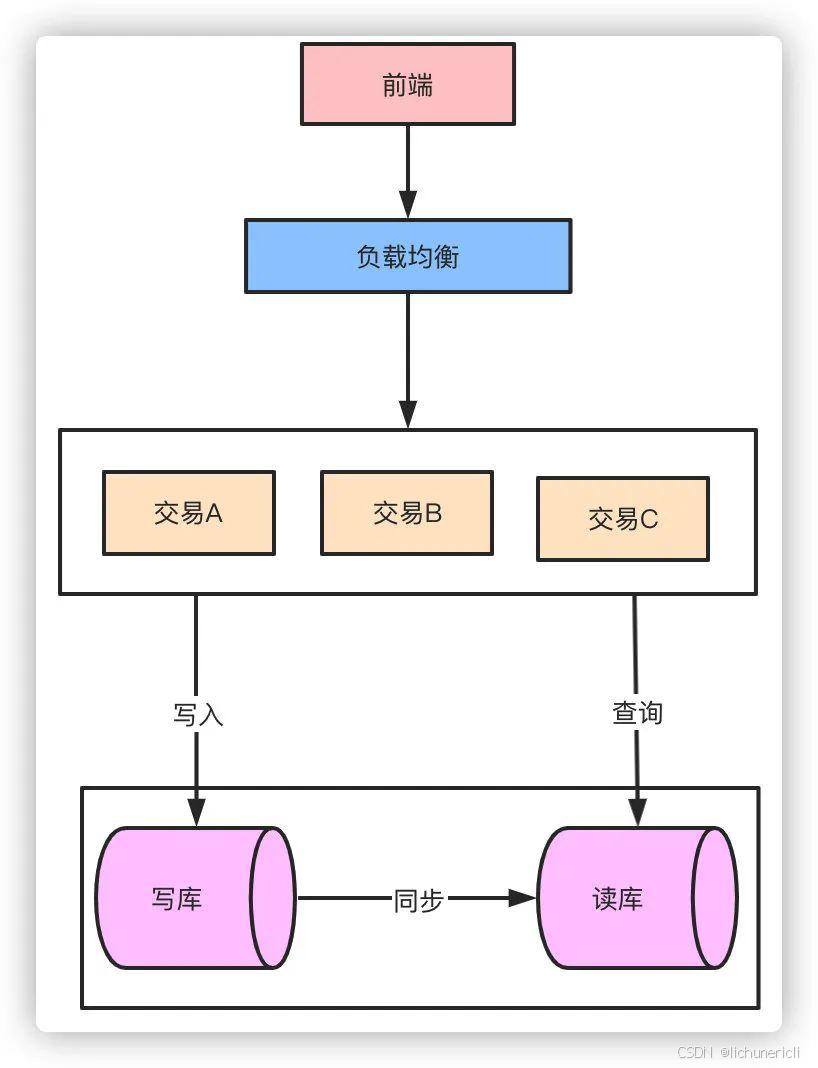
读写分离也就相当于数据库集群的方式降低了单节点的压力。而面对数据的急剧增长,原来的单库单表的存储方式已经无法支撑整个业务的发展,这时候就需要对数据库进行分库分表了。
针对微服务而言垂直的分库本身已经是做过的,剩下大部分都是分表的方案了。
高可用
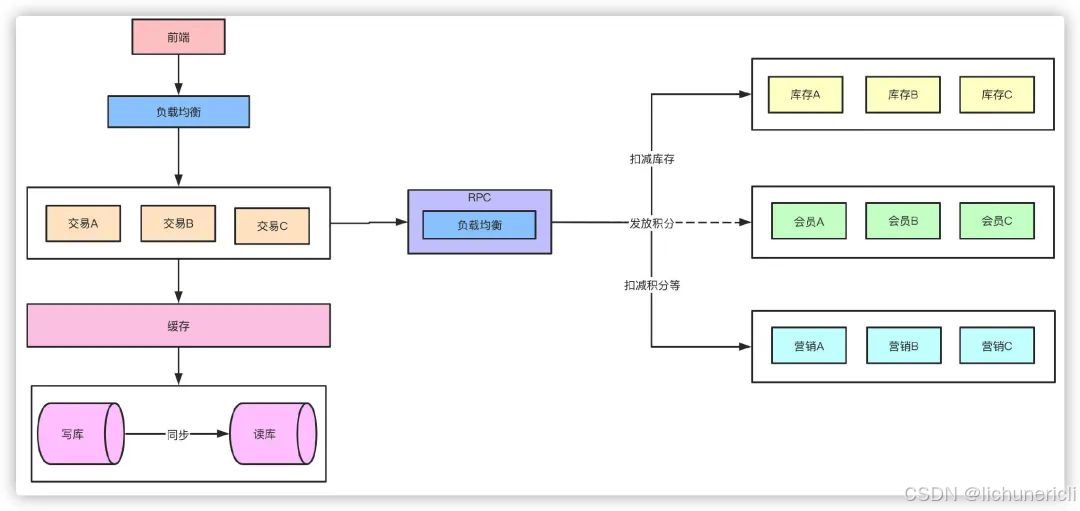
熔断
比如营销服务挂了或者接口大量超时的异常情况,不能影响下单的主链路,涉及到积分的扣减一些操作可以在事后做补救。
限流
对突发如大促秒杀类的高并发,如果一些接口不做限流处理,可能直接就把服务打挂了,针对每个接口的压测性能的评估做出合适的限流尤为重要。
降级
熔断之后实际上可以说就是降级的一种,以熔断的举例来说营销接口熔断之后降级方案就是短时间内不再调用营销的服务,等到营销恢复之后再调用。
预案
一般来说,就算是有统一配置中心,在业务的高峰期也是不允许做出任何的变更的,但是通过配置合理的预案可以在紧急的时候做一些修改。
核对
针对各种分布式系统产生的分布式事务一致性或者受到攻击导致的数据异常,非常需要核对平台来做最后的兜底的数据验证。比如下游支付系统和订单系统的金额做核对是否正确,如果收到中间人攻击落库的数据是否保证正确性。
总结
其实可以看到,怎么设计高并发系统这个问题本身他是不难的,无非是从物理硬件层面到软件的架构、代码层面的优化,使用什么中间件来不断提高系统的抗压能力。
但是这个问题本身会带来更多的问题,微服务本身的拆分带来了分布式事务的问题,http、RPC框架的使用带来了通信效率、路由、容错的问题,MQ的引入带来了消息丢失、积压、事务消息、顺序消息的问题,缓存的引入又会带来一致性、雪崩、击穿的问题,数据库的读写分离、分库分表又会带来主从同步延迟、分布式ID、事务一致性的问题,而为了解决这些问题我们又要不断的加入各种措施熔断、限流、降级、离线核对、预案处理等等来防止和追溯这些问题。

















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









