






全国14亿个姓名,统计出重名最多的前100个
1. 问题描述:
我们需要从全国14亿人的数据中,统计出重名人数最多的前100位姓名。
2. 问题分析:
我们的目标:是找到重名人数最多的前100个姓名
这意味着需要两步:
-
需要有一个高效的数据结构来统计每个名字出现的次数
-
并快速找到出现次数最多的前100个名字
所以这个问题就转化成了下一个问题: 使用一种低成本、高性能的数据结构,来统计每个名字出现的次数。
3. 如何选择一种最低成本、最高性能的数据结构?
常规的数据结构,选型如下:
-
数组
如果姓名的字符集范围很大(支持所有的Unicode字符),那么,需要极大且稀疏的数组,导致内存浪费严重,也不适合处理动态长度和多样性的字符串集合
-
链表
链表的插入和查找的操作时间复杂度为O(N),并且,在大规模数据下性能低下,也不适合快速查找的场景
-
跳表
跳表的插入、删除和查找操作的平均事件复杂度都是O(logN),跳表式空间换时间的思想,主要是它需要额外的空间来维护多级索引,每个元素在最坏的情况下需要额外的存储空间,导致总的空间复杂度为O(N log N),,在频繁的插入和查询的场景中,效率不高。
来到我们现在这个场景,统计每个名字出现的次数时,不如哈希表在时间和空间的效率高效,哈希表的O(1)时间复杂度更适合大规模的数据频繁的插入和查询。
-
哈希表
哈希表的插入和查找的时间复杂度都是O(1),但是在极端的情况下,哈希冲突会导致时间复杂度退化到O(N),在空间效率中,哈希表需要额外的空间来维护键值对,来到这个场景,空间效率和哈希冲突都有潜在风险,最重要的是哈希表不能共享前缀,在处理大量的具有共同前缀的数据时候,也不适合。
-
平衡二叉搜索树(如AVL树或红黑树)
能够维护有序数据,支持快速的插入、删除和查找操作,但在字符串的比较上,性能不如哈希表和Trie高效
-
前缀树
前缀树通过共享前缀节点,节省了大量存储空间,实现了成本的最低化。
前缀树对于字符串操作非常高效,在这个问题中,有很多名字共享相同前缀,Trie的结构能有效利用这一特点。
经过上面的分析,能够看到Trie更适合统计每个名字出现的次数。
4. 如何快速筛选出Top 100?
当知道了所有姓名出现的次数之后、怎么样快速筛选出其中出现次数最多的前100个?
首先想到的是直接排序。这个问题中,对14亿数据直接排序会有效率的问题,操作非常耗时。所以直接排序, 这种方法不可取。
我们的目标是找到次数最多的前100个,可以利用堆的性质来完成。
小顶堆总是保持堆顶为当前堆中最小的元素,这样可以确保当新的元素插入时,如果新元素大于堆顶元素,堆顶元素会被替换掉。
使用小顶堆的步骤
1.初始化一个小顶堆: 设为100
2.遍历每个姓名及其出现的次数
-
如果堆的大小小于100,将当前姓名及其出现次数插入堆中。
-
如果当前姓名的出现次数大于堆顶元素的出现次数,则移除堆顶元素,并将当前姓名及其出现次数插入堆中。
3.遍历完所有的姓名后,堆中即为重名人数最多的前100个姓名。
所以解决这个问题使用了前缀树 + 小顶堆。
5. 前缀树Trie树介绍
在计算机科学中,Trie,又称前缀树或字典树,使用一些单词来构建Trie树,如下图所示:
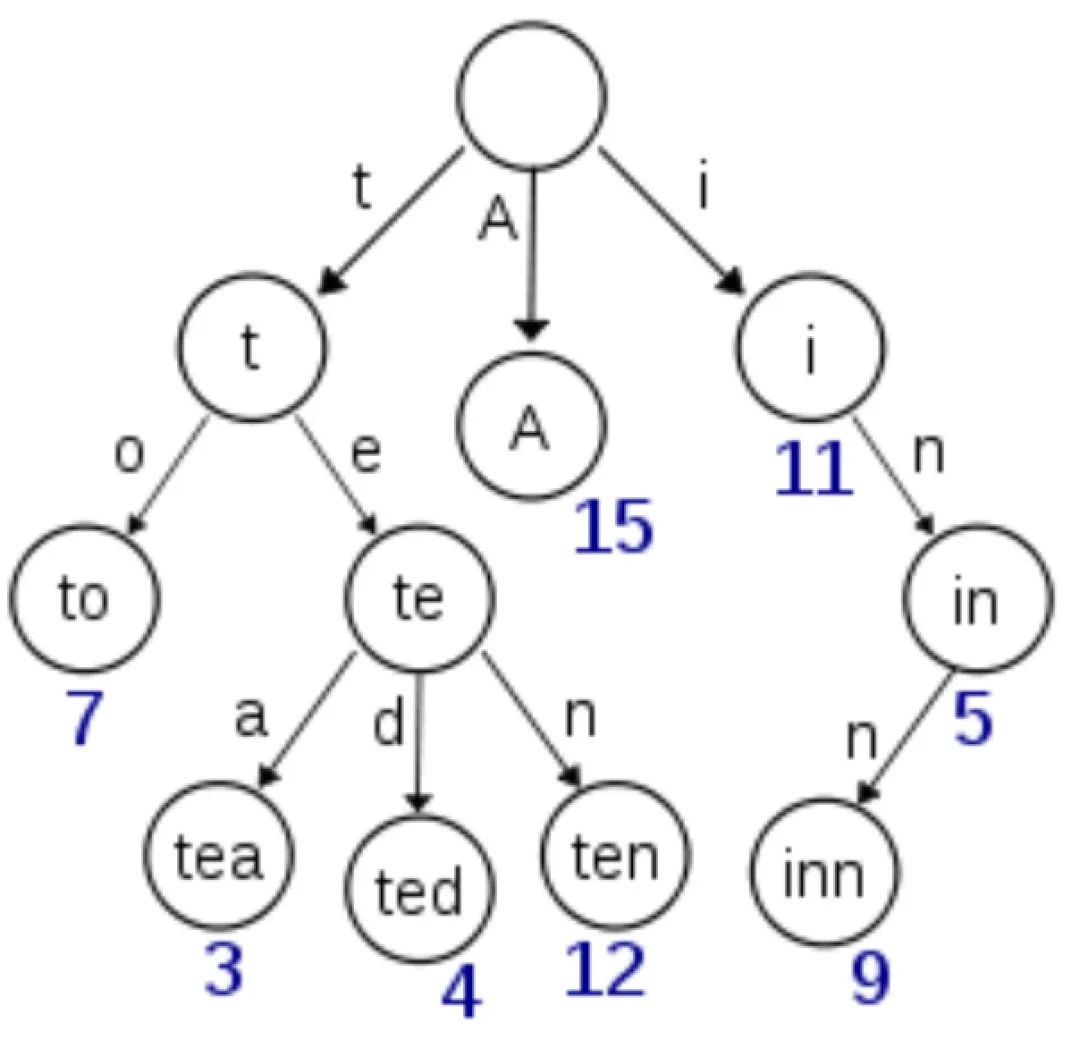
从图片中可以看到一些有意思的特性:
-
根节点没有数据
-
从根节点到某一个节点,将他们的路径进行连接就组成了对应的字符串
定义:
Trie树,又称为前缀树或字典树, 是一种用于高效存储和检索字符串集合的数据结构, 每个节点代表一个字符,边表示从一个字符到另一个字符的路径, Trie树通过共享相同前缀的节点来节省存储空间
Trie树是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,Trie树的键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。
一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。Trie中的键通常是字符串,但也可以是其它的结构。Trie的算法可以很容易地修改为处理其它结构的有序序列,比如一串数字或者形状的排列。比如,bitwise trie中的键是一串位元,可以用于表示整数或者内存地址
Trie树基本性质
1,根节点不包含字符,除根节点以外每个节点只包含一个字符。
2,从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
3,每个节点的所有子节点包含的字符串不相同。
Trie树优点:
可以最大限度地减少无谓的字符串比较,故可以用于词频统计和大量字符串排序。
跟哈希表比较:
1,最坏情况时间复杂度比hash表好
2,没有冲突,除非一个key对应多个值(除key外的其他信息)
3,自带排序功能(类似Radix Sort),中序遍历trie可以得到排序。
Trie树缺点:
当所有关键字都不具有相同或类似的前缀,空间消耗过大.
6. Trie树的基本操作:
-
插入:将一个字符串逐字符插入到Trie树中
-
查找:检查Trie树中是否存在某个字符串
-
前缀匹配:查找所有以某个前缀开头的字符串
-
删除:从Trie树中删除一个字符串
7. Trie树的应用场景:
1.字符串检索:
-
应用场景:快速检索字典中的单词
-
使用原因:Trie树通过逐字符匹配,可以在O(L)时间内完成字符串的检索,其中L是字符串的长度,比传统的线性搜索更加高效
2.自动补全:
-
应用场景:搜索引擎和输入法中的自动补全功能
-
适用原因:Trie树可以通过前缀查找快速提供所有以给定前缀开头的单词,有效提升用户输入体验
3.前缀匹配:
-
应用场景:寻找以特定前缀开头的所有字符串,如电话号码前缀匹配
-
适用原因:Trie树天生适合处理前缀匹配问题,可以在O(L)时间内找到所有以特定前缀开头的字符串
4.词频统计:
-
应用场景:文本分析中统计单词出现频率
-
适用原因:Trie树可以在插入过程中记录每个单词的出现次数,通过遍历Trie树可以快速统计所有单词的频率
5.多模式匹配:
-
应用场景:从文本中同时搜索多个模式(模式匹配算法)
-
适用原因:Trie树可以构建多个模式的结构,通过一次遍历文本同时匹配多个模式,提高匹配效率
为什么适用于这些场景:
1.空间效率:
-
共享前缀:Trie树通过共享前缀节点,减少了重复存储相同前缀的空间开销。
-
节省内存:对于大量前缀相同的字符串集合,Trie树显著节省内存使用。
2.时间效率:
-
O(L)复杂度:插入、查找和前缀匹配操作的时间复杂度为O(L),其中L是字符串的长度,显著提高了操作效率
-
快速检索:相比于其他线性结构(如数组或链表),Trie树在处理大量字符串时更快
8. Trie树的代码实现:
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
class TrieNode {
Map<Character, TrieNode> children;
int count;
public TrieNode() {
children = new HashMap<>();
count = 0;
}
}
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String name) {
TrieNode node = root;
for (char ch : name.toCharArray()) {
node = node.children.computeIfAbsent(ch, k -> new TrieNode());
}
node.count++;
}
public void getAllNames(TrieNode node, StringBuilder prefix, PriorityQueue<NameCount> minHeap, int k) {
if (node == null) return;
if (node.count > 0) {
if (minHeap.size() < k) {
minHeap.offer(new NameCount(prefix.toString(), node.count));
} else if (node.count > minHeap.peek().count) {
minHeap.poll();
minHeap.offer(new NameCount(prefix.toString(), node.count));
}
}
for (Map.Entry<Character, TrieNode> entry : node.children.entrySet()) {
prefix.append(entry.getKey());
getAllNames(entry.getValue(), prefix, minHeap, k);
prefix.deleteCharAt(prefix.length() - 1);
}
}
public PriorityQueue<NameCount> getTopKNames(int k) {
PriorityQueue<NameCount> minHeap = new PriorityQueue<>(k);
getAllNames(root, new StringBuilder(), minHeap, k);
return minHeap;
}
}
class NameCount implements Comparable<NameCount> {
String name;
int count;
public NameCount(String name, int count) {
this.name = name;
this.count = count;
}
@Override
public int compareTo(NameCount other) {
return Integer.compare(this.count, other.count);
}
@Override
public String toString() {
return name + ": " + count;
}
}
public class Main {
public static void main(String[] args) {
String[] names = {"张伟", "王伟伟", "王芳", "李伟", "李娜"}; // 示例数据
int k = 100; // 找到前100个重名人数最多的姓名
Trie trie = new Trie();
for (String name : names) {
trie.insert(name);
}
PriorityQueue<NameCount> topKNames = trie.getTopKNames(k);
while (!topKNames.isEmpty()) {
System.out.println(topKNames.poll());
}
}
}9. TopN问题发散:
上面的问题进行改进,如果对内存有个限制,比如:要求内存的使用不能超过2G,注意,这里的内存受限,尽量使用磁盘处理。
这里使用hashmap,而不适用 trie树的原因是?
trie树是按照字符为粒度组织树的节点的,进行磁盘操作性能不高,而且进行磁盘操作时算法更加复杂。hashmap 是以key为单位操作的, 磁盘操作的效率高。而且 hashmap 统计的时候,代码简洁清晰。
尽管我们hashmap,也不能直接将所有数据加载到内存中处理,所以可以采取分治的策略,使用外部排序和哈希映射的方法。
以下是详细的步骤:
1.分块读取数据:将14亿条记录分成多个较小的块,每次读取一部分数据到内存中进行处理
2.哈希映射统计词频:对每个块的数据进行哈希映射,统计每个名字出现的次数,将结果写入到磁盘文件
3.合并词频统计结果:读取所有中间文件,合并词频统计结果,得到全局的词频统计
4.使用小顶堆找出前100个重复最多的名字
import java.io.*;
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
class NameCount implements Comparable<NameCount> {
String name;
int count;
public NameCount(String name, int count) {
this.name = name;
this.count = count;
}
@Override
public int compareTo(NameCount other) {
return Integer.compare(this.count, other.count);
}
@Override
public String toString() {
return name + ": " + count;
}
}
public class ExternalMemoryTopK {
private static final int CHUNK_SIZE = 1000000; // 每个块处理100万条记录
public static void main(String[] args) throws IOException {
String inputFile = "names.txt";
String outputFile = "top100names.txt";
int k = 100;
// 第一步:分块读取数据并统计词频
int chunkIndex = 0;
BufferedReader reader = new BufferedReader(new FileReader(inputFile));
String line;
while ((line = reader.readLine()) != null) {
Map<String, Integer> frequencyMap = new HashMap<>();
int lineCount = 0;
while (line != null && lineCount < CHUNK_SIZE) {
frequencyMap.put(line, frequencyMap.getOrDefault(line, 0) + 1);
line = reader.readLine();
lineCount++;
}
writeFrequencyMapToFile(frequencyMap, "chunk_" + chunkIndex + ".txt");
chunkIndex++;
}
reader.close();
// 第二步:合并所有块的词频统计结果
Map<String, Integer> globalFrequencyMap = new HashMap<>();
for (int i = 0; i < chunkIndex; i++) {
mergeFrequencyMapFromFile(globalFrequencyMap, "chunk_" + i + ".txt");
}
// 第三步:使用小顶堆找出前100个重复最多的名字
PriorityQueue<NameCount> minHeap = new PriorityQueue<>(k);
for (Map.Entry<String, Integer> entry : globalFrequencyMap.entrySet()) {
if (minHeap.size() < k) {
minHeap.offer(new NameCount(entry.getKey(), entry.getValue()));
} else if (entry.getValue() > minHeap.peek().count) {
minHeap.poll();
minHeap.offer(new NameCount(entry.getKey(), entry.getValue()));
}
}
// 输出结果
BufferedWriter writer = new BufferedWriter(new FileWriter(outputFile));
while (!minHeap.isEmpty()) {
writer.write(minHeap.poll().toString());
writer.newLine();
}
writer.close();
}
private static void writeFrequencyMapToFile(Map<String, Integer> frequencyMap, String filename) throws IOException {
BufferedWriter writer = new BufferedWriter(new FileWriter(filename));
for (Map.Entry<String, Integer> entry : frequencyMap.entrySet()) {
writer.write(entry.getKey() + " " + entry.getValue());
writer.newLine();
}
writer.close();
}
private static void mergeFrequencyMapFromFile(Map<String, Integer> globalFrequencyMap, String filename) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(filename));
String line;
while ((line = reader.readLine()) != null) {
String[] parts = line.split(" ");
String name = parts[0];
int count = Integer.parseInt(parts[1]);
globalFrequencyMap.put(name, globalFrequencyMap.getOrDefault(name, 0) + count);
}
reader.close();
}
}10. TopK问题,典型的解题思路
这是一种典型的topK问题,一般的问法如下:从一堆数据中选出多少个最大或最小数?
解题思想:
-
先统计数量,使用前缀树,hashmap等
-
再用小顶堆 或者 大顶堆
取大用小,取小用大。简单来说就是取最大的K个数就用小顶堆,取最小的K个数,就用大顶堆
取海量数据里面最小的K个数?
要找出数组中最小的K个数,就要构造一个有K个元素的大顶堆,因为大顶堆的堆顶值是最大的,其它元素和堆顶的元素比较,大于堆顶的元素,换一个元素继续,小于堆顶的元素,将堆顶元素出堆,将更小的元素插入堆顶,如此反复,堆里面就是最小的数
取海量数据里面最大的K个数?
要找出数组中最大的K个数,就要构造一个有K个元素的小顶堆,因为小顶堆的堆顶值是最小的,其它元素和堆顶的元素比较,大于堆顶的元素,堆顶的元素出堆,将元素插入到小顶堆,将更大的元素换到堆中,如此反复,堆里面就是最大的数
百亿级分片,如何设计基因算法?
分库分表背景知识
问题1:为什么分库分表?
大家都知道,当一个表(比如订单表) 达到500万条或2GB时,需要考虑水平分表。
为什么?
读写并发高场景,单服务器单一数据库CPU、内存、网络IO压力大。所以,需要分库,一个库拆成多个库。同时,数据量大,单表存不下,需要分表,一张表拆分成多个表。
总之,分库分表的原因是:
-
数据量大,选分表;
-
并发高,选分库;
-
海量存储+高并发,分库+分表。
问题2:如何做数据库水平拆分?
分库和分表, 主要还是对数据的水平拆分,对数据的垂直拆分的重要程度弱太多,所以这个不做介绍。
水平分片又称为横向拆分。
相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。
例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。

水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
对数据的水平拆分 ,核心的设计是:
-
1: 用哪个字段拆分表
-
2: 用什么路由策略寻找目标库表。
分片键的设计目标、建议
数据库水平拆分的字段叫分片键。分片键也称为 Sharding key。
关于分片键的选择,我们需要选择具有共性的字段是最基本的要求,也是就尽量能覆盖绝大多数查询场景。同时分片键也应具有足够庞大的基数以及唯一性,从而使 Shard 可灵活规划,具备较好的扩展性。
举个反例,如果选取布尔类型的字段为分片键,那么分片最多只能存在两份,这就陷入了非常尴尬的局面,基本失去了 Sharding 的意义。
如何做 Sharding key 的设计呢?
-
最常见的情况是:用表的单个字段做分片键,
-
复杂情况是:可以用两个或多个字段组合成分片键。
Sharding key的设计目标:
合理选择 Sharding key,避免大多数的查询变成重量级操作,比如:
-
跨库查询
-
全表路由
建议:
-
合理选择 Sharding key, 尽一切可能减少 全表路由、跨库查询
-
从而使得大部分查询在 单库实现结果闭环,从而减少 多库之间大的数据合并和二次排序, 从而提升分库分表的吞吐量和性能。
分片键的设计建议:
-
选择具有共性的字段作为分片键,即查询中高频出现的条件字段;
-
分片字段应具有高度离散的特点,分片键的内容不能被更新;
-
可均匀各分片的数据存储和读写压力,避免片内出现热点数据;
-
尽量减少单次查询所涉及的分片数量,降低数据库压力;
-
最后,不要更换分片键,更换分片键需重分布数据,代价较大。
分片键的设计原则
-
选择查询频率最高的字段
分片键要能覆盖绝大多数查询场景,它决定了数据查询的效率。
正例:单号,id,时间字段
反例:姓别、商品类别
-
分片键不可以更新
分片键如果更新了,按原来的路由算法会计算出不同的库表地址,旧的数据无法正确读取
-
分片键不可以更换
分片键更换,意味着数据要重新分布,代价昂贵。
-
分片字段应有离散特性
分片键越离散,越容易把数据均匀分布在不同库表。
分片键的设计方案
按分片键的查询可以直接定位到目标库表,那么不按分片键的查询,是否只能遍历所有库表了呢?
举例:
-
电商领域有用户表和订单表。
-
订单表按订单号分库分表,
-
同时订单表有用户id字段。
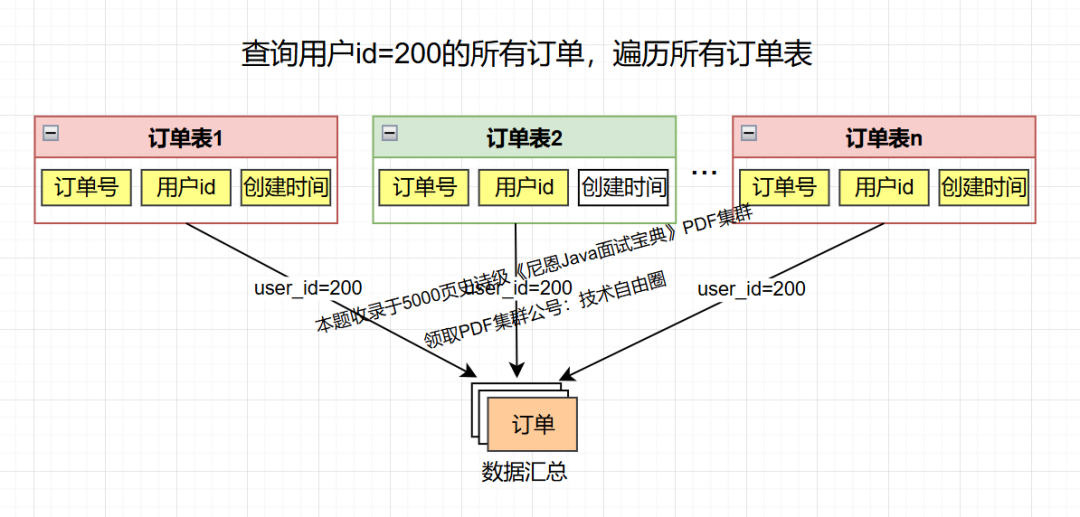
假如查询某个用户(比如user-id=200)的订单,怎么查呢?
此时,如果无法预知这个用户的数据存在订单的哪个库表,那么,其实就需要走 全表路由, 把请求路由到 这个表的所有的数据分片。
全表路由 具体如下图所示:
前面讲到,Sharding key的设计目标:
合理选择 Sharding key,避免大多数的查询变成重量级操作,比如:
-
跨库查询
-
全表路由
合理选择 Sharding key, 尽一切可能减少 全表路由、跨库查询, 从而使得大部分查询在 单库实现结果闭环,从而减少 多库之间大的数据合并和二次排序, 从而提升分库分表的吞吐量和性能。
如何去掉这里的 全表路由,提升查询效率呢?
针对这种非分片键的查询,有几种设计思路提升查询效率:
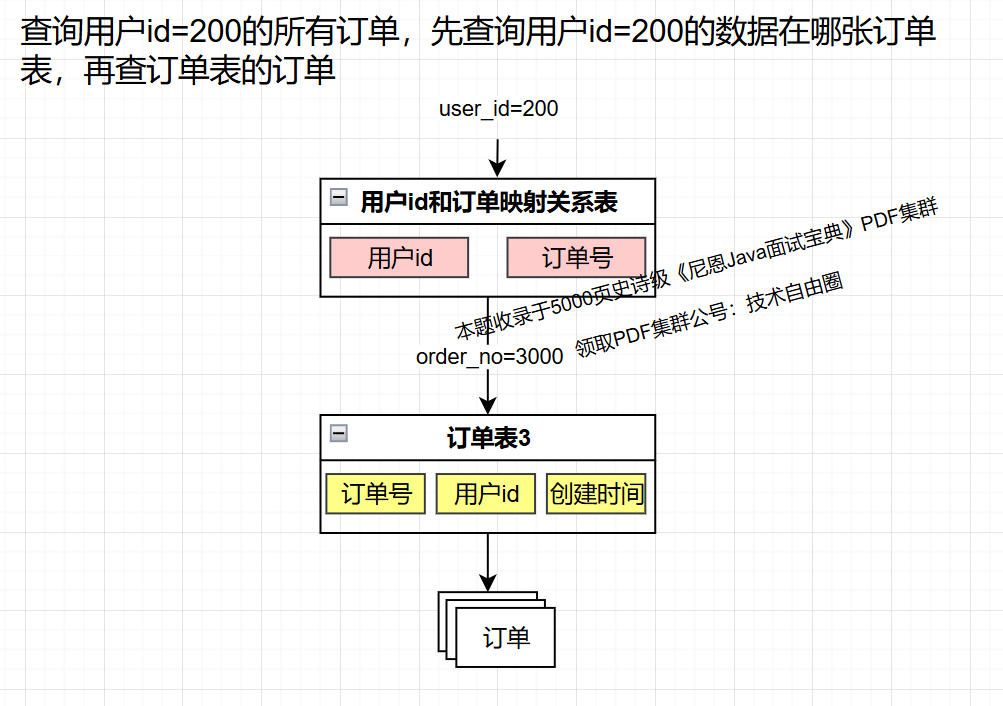
1 索引法
索引法的思路是,把非分片键和分片键的映射关系保存起来,查询数据时,先从这个映射关系查找分片键,再用分片键路由到目标库表。
-
索引表
额外建一张表保存订单号和用户id的映射关系。
优点:实现简单
缺点:
-
查询数据多查一次索引表,性能低。
-
索引表可能会很大,甚至索引表本身要分表。
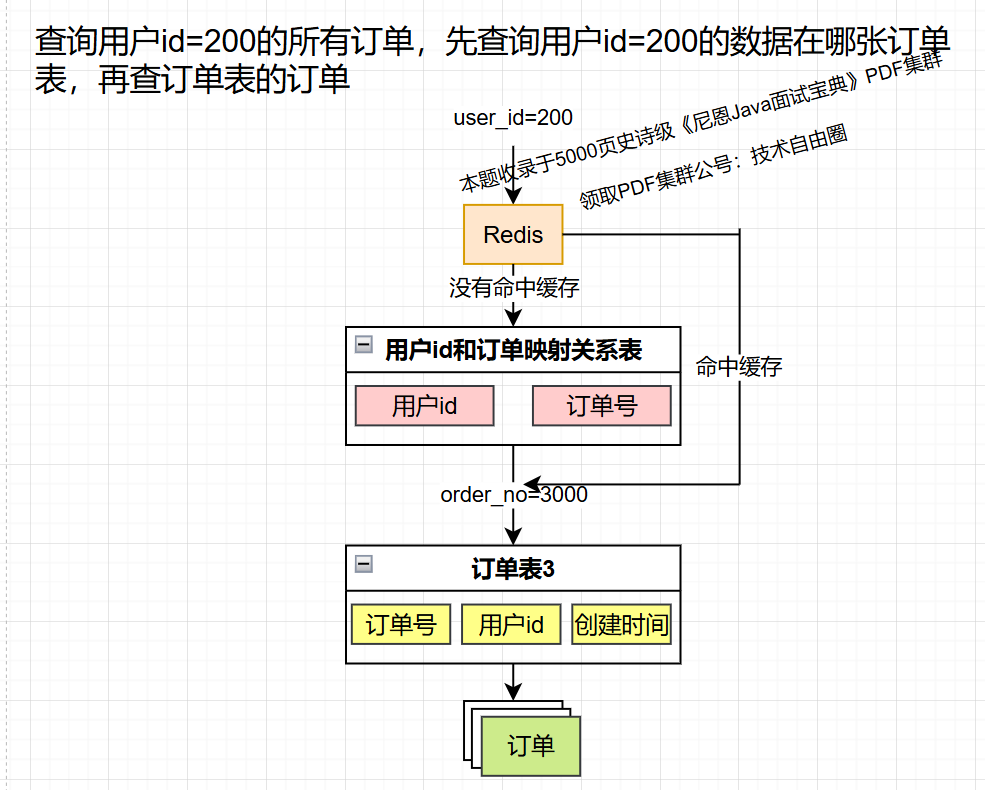
缓存映射关系
性能不够,缓存来凑。既然索引表性能低,那么 用Redis保存订单号和用户id的映射关系。
优点:查询速度比索引表快。
缺点:数据量大时,占用大量内存,缓存不断淘汰,命中率低,没有命中缓存还是得查索引表。
无论是用索引表还是用Redis,都无法在大数据量下有效查找分片键。
2 基因法
基因法的思路是,把非分片键到分片键的映射关系内嵌在非分片键字段,嵌入到非分片键的这部分内容就是基因。
基因法是大厂常常使用的方案。
比如,将买家 ID 融入到订单 ID 中,作为订单 ID 后缀。这样,指定买家的所有订单就会与其订单在同一分片内了,如下图所示。
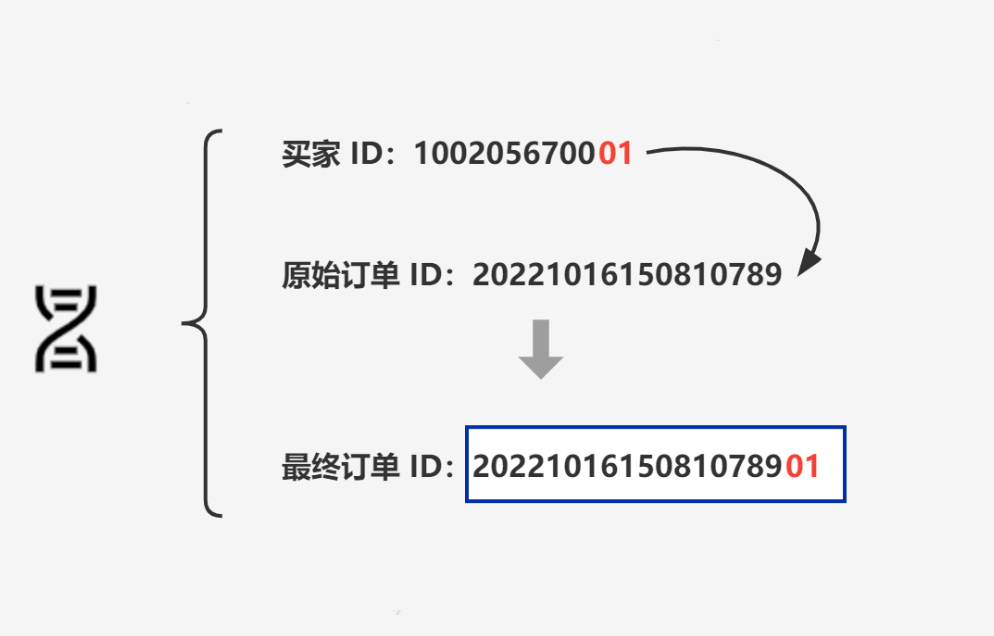
再具体一点:
-
假如订单表用订单号%16路由,分16库表。
-
用户下单生成订单号时,订单号的最后4个bit位,通过位运算,设置为用户id的最后4bit位,那么,订单号的最后4个bit位就是订单号的用户基因。
此情此景,如果在 查询某个用户的订单,就不用全表路由了。
现在是单片路由,直接根据用户id的最后4bit位,路由到订单的目标库表。

3 基因法的理论基础
如果对一个10进制的数字按10取模,取模的结果只与这个数字最后1位有关:
199%10=9
19999%10=9
1234567899%10=9
同理,按100(10^2)取模,取模的结果只与这个数字最后2位有关:
199%100=99
19999%100=99
1234567899%100=99
同理,一个二进制的数字,按2^n取模,只与这个数字最后n位有关:
例:n=3,2^3=1000
10001111%(1000)=111, 即十进制的143%8=7
10011111%(1000)=111, 即十进制的159%8=7
因此,订单表用订单号%16分库分表,对16(2^4)取模的结果只和二进制订单号的最后4位有关,这4位决定了数据落在哪个库表上。
4 数字类型的分片键设计
假如订单号是雪花算法生成的long类型数字,要在雪花算法的64个bit位中预留4位,用uid的后4位填充。

5 字符串类型分片键设计
假如订单号是一个字符串,将uid后4bit位转为字符串后拼接在订单号后面即可。
按某个业务规则生成的订单号:ORDER20240101
带有uid基因的订单号:ORDER20240101-0,ORDER20240101-15
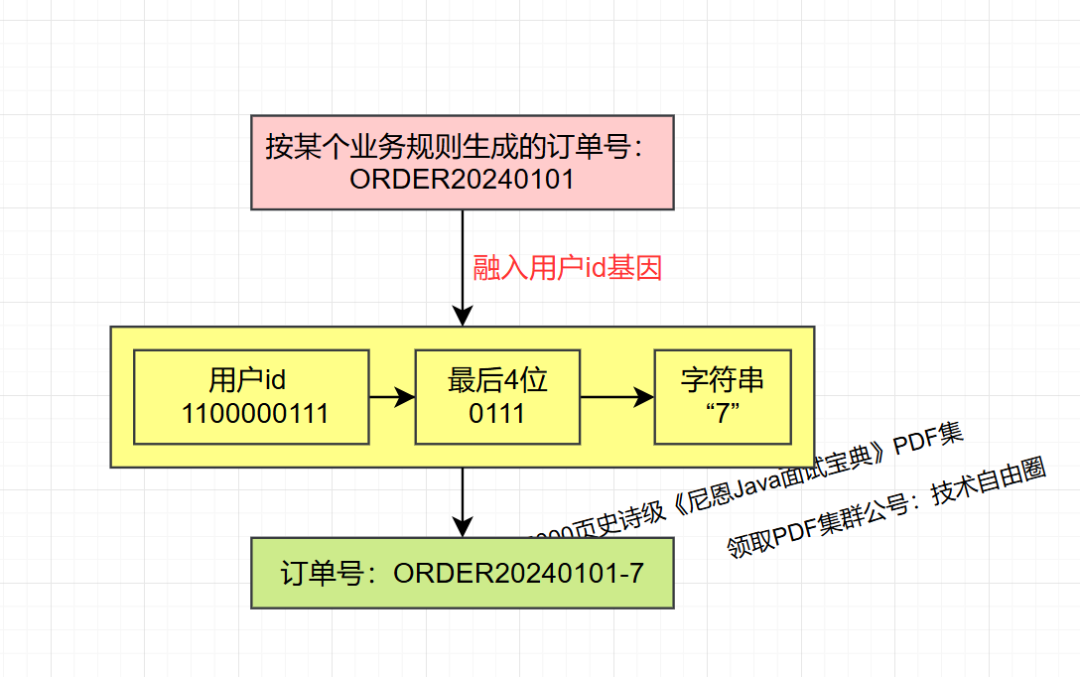
6 基因法的优缺点:
-
优点:无论按照分片键还是按某个非分片键查数据,都可以直接定位到目标库表,性能比索引法高。
-
缺点:需要提前规划好库表容量,不方便扩容。
扩展方案设计:多个非分片键的组合查询
基因法解决了单个非分片键的数据查询路由问题,减少了全表路由的出现。但是,如果有多个非分片键查询,是否要在分片键中融入多个基因呢?No。
分片键的设计不应过于复杂,况且,即使能融入多个基因,又如何支持多个非分片键组合条件查询呢?
数据库不支持任意字段任意组合的高性能查询,这不是数据库的长项,应该用ES、ClickHouse等其他中间件来解决这类问题。
CPU被打满/CPU100%,如何处理?
1.CPU 占用很高的3大类型,9大场景:
在生产环境中,会出现由代码问题导致CPU占用很高,该如何诊断出是哪行java代码导致?
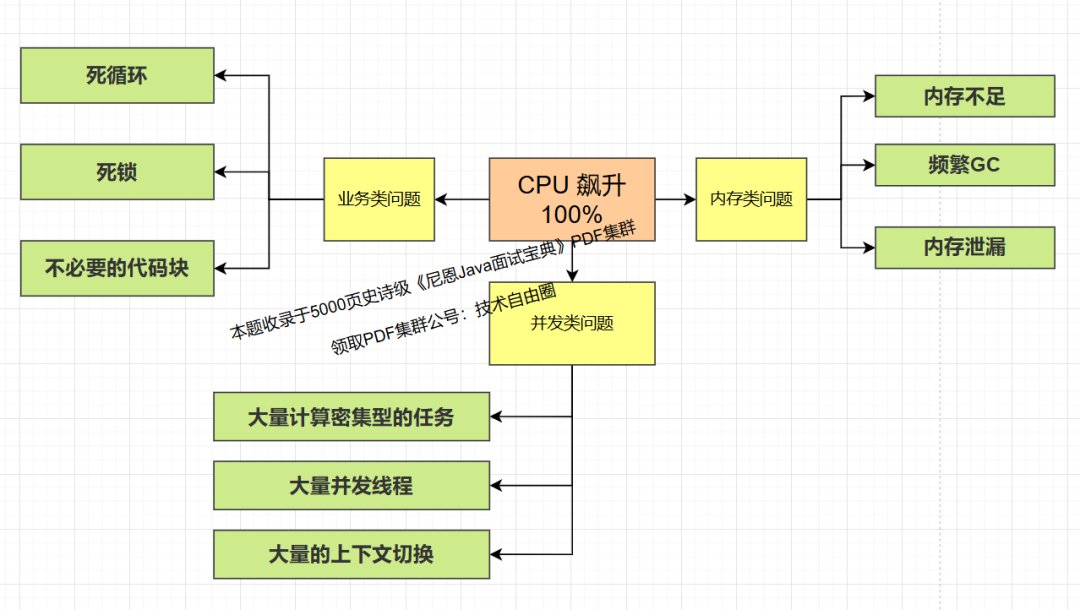
业务类问题
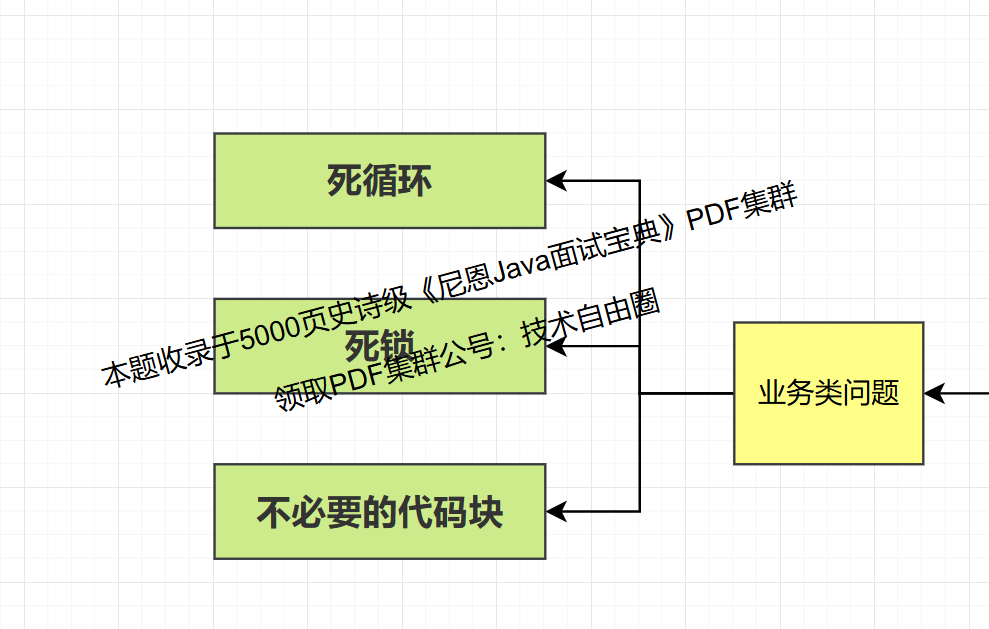
1.1 死循环
while(true)条件
导致 CPU 占用率高的最简单但最具破坏性的编程错误之一就是死循环。当程序中的循环缺乏正确的退出条件或条件从未满足时,就会出现这种情况,死循环无休止地运行,消耗过多的处理器时间,导致CPU100%
1.2 死锁
发生死锁后,就会存在忙等待或自旋锁等编程问题,从而导致 繁忙等待问题。即进程在不释放 CPU 的情况下反复检查条件是否满足,会导致 CPU 占用率居高不下。这种低效率的资源使用会妨碍 CPU 执行其他任务。
1.3 不必要的代码块
在不需要的地方使用synchronized块,会导致线程竞争和上下文切换。
解决方案:尽量减少同步块的使用范围
并发类问题
1.4 大量计算密集型的任务
比如复杂的数学计算,图像处理,视频编码。计算密集型的任务需要大量的计算能力。在没有足够系统资源的情况下运行这些应用程序,可能会导致 CPU 占用率达到 100%,因为它们试图执行高要求的任务。
解决方案:优化算法,使用更高效的库,或者利用并行计算来分摊
1.5 大量并发线程
多个线程同时运行会导致对 CPU 资源的竞争,尤其是当其中许多线程都是资源密集型进程时。这会导致所有线程获得的 CPU 时间减少,当每个线程都试图完成自己的任务时,CPU 时间可能会被耗尽。
1.6 大量的上下文切换
创建过多的线程,导致频繁的上下文切换。
解决方案:使用线程池来管理线程的数量
内存类问题
1.7 内存不足
当系统内存不足时,就会将磁盘存储作为虚拟内存使用,而虚拟内存的运行速度要慢得多。这种过度的分页和交换会导致 CPU 占用率居高不下,因为处理器需要花费更多时间来管理内存访问,而不是高效地执行进程。
1.8 频繁GC
创建大量的短生命周期的对象,频繁触发GC。
解决方案: 优化代码, 减少对象的创建 ,或者调整JVM的参数来优化
1.9 内存泄漏
程序持续分配内存但不释放,会导致频繁的GC。
解决方案:使用内存分析工具VisualVM进行检测和修复
2.CPU100%定位的两大神器:
想要定位到具体是哪一行的代码导致, 一般都会使用下面的两大神器
-
通常使用的jvm自带的工具jstack
-
还有一种就是开源神器arthas
一般而言,arthas还有其它的功能,所以选择它多一点.
3 CPU 飙升100%的解决思路与方法论
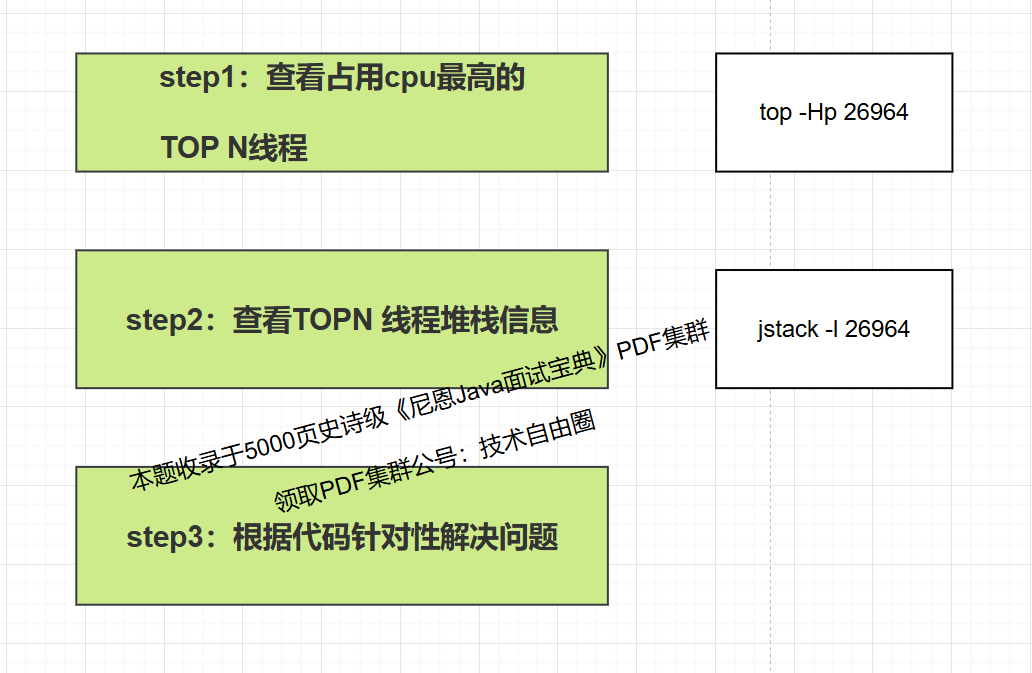
4 使用jstack 解决CPU 100%问题实操
使用jstack 解决CPU 100%问题,在方法论上要用到两个命令,
-
top 命令查看TOP N线程,
-
jstack命令查看堆栈信息
4.1.jstack命令讲解
命令jstack是java堆栈的跟踪工具,可以打印出程序中所有线程的堆栈信息,包括线程状态,调用栈信息,锁信息等。
jstack可以诊断线程死锁、内存泄漏等问题
命令格式: jstack [options] pid
常用例子: jstack -l pid,查看线程的堆栈信息
堆栈信息解读:
$ jstack -l 43953
2024-06-08 10:14:45
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.191-b12 mixed mode):
......
摘取其中的一段为说明:
"main" #1 prio=5 os_prio=31 tid=0x00007fb54280e000 nid=0xe03 waiting on condition [0x0000700001983000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at com.jvm.JVMtest.main(JVMtest.java:6)
main:线程名称
#1: 当前线程ID,从main开始,jvm会根据线程创建的顺序为其线程编号
prio: 优先级的顺序,一般默认是5
os_prio: 线程对应系统的优先级
tid: java内的线程id
nid: 操作系统级别的线程id,是一个十六进制
关于线程的信息:
NEW: 线程新建,还没开始运行
RUNNABLE: 正在java虚拟机中运行的线程
BLOCKED: 被阻塞,正在等待监视器锁的线程
WAITING: 无限期等待另一个线程执行特定操作的线程
TIMED_WAITING: 等待另一个线程执行操作达到指定等待时间的线程
TERMINATED: 已经退出的线程
这里关注的最多的就是nid
4.2.使用jstack解决CPU占用很高的问题并定位具体行数
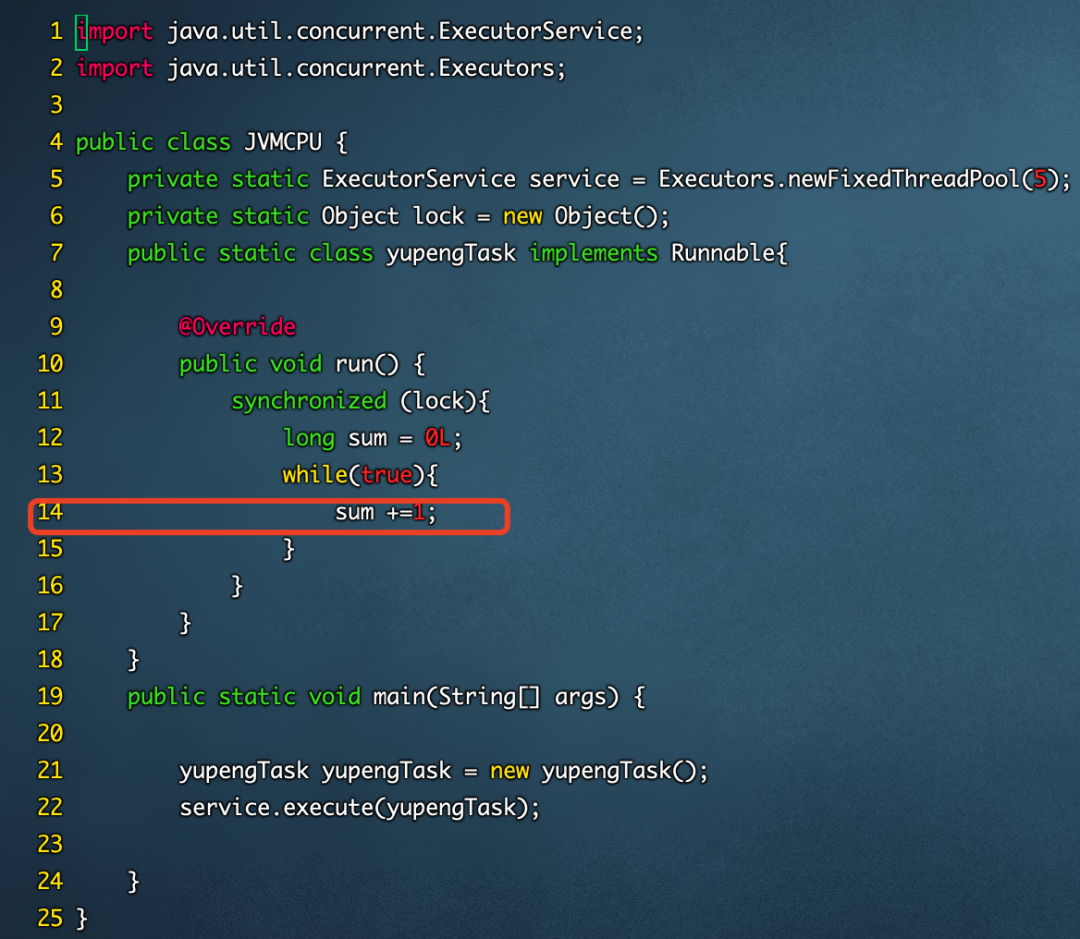
package com.jvm;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class JVMCPU {
private static ExecutorService service = Executors.newFixedThreadPool(5);
private static Object lock = new Object();
public static class yupengTask implements Runnable{
@Override
public void run() {
synchronized (lock){
long sum = 0L;
while(true){
sum +=1;
}
}
}
}
public static void main(String[] args) {
yupengTask yupengTask = new yupengTask();
service.execute(yupengTask);
}
}将这段代码上传到linux服务器,并且使用nohup java JVMCPU &运行

使用top命令可以看到cpu被打满了
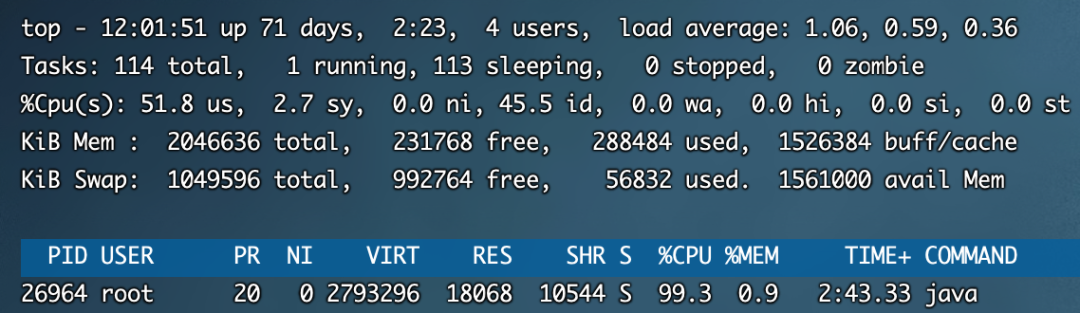
知道了进程的PID,如何找到进程下是哪个线程呢?可以使用命令top -Hp 26964,如下所示
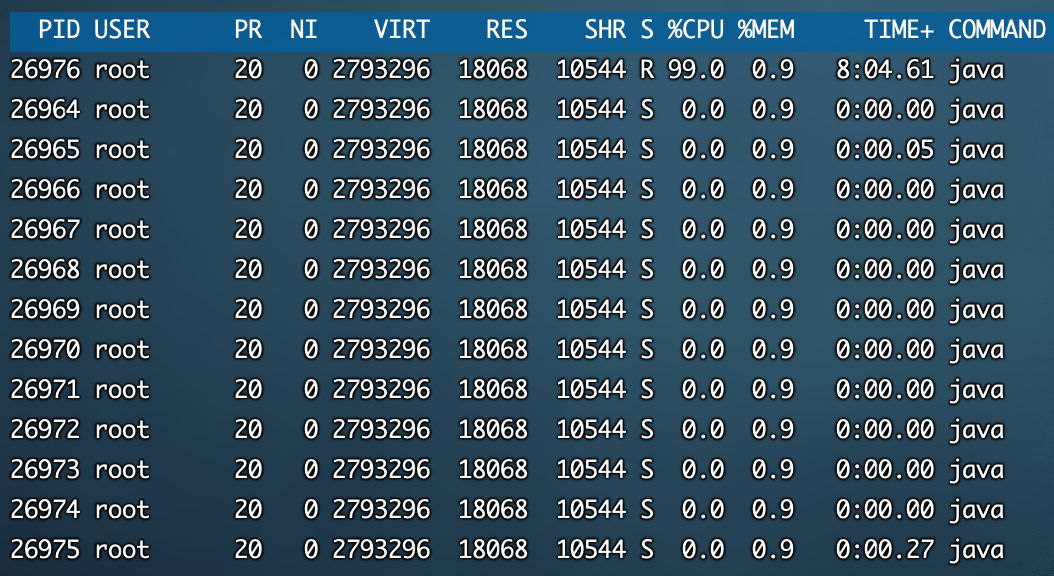
从上面的图可以看到,cpu占用最多的线程是26976这个线程id,接下来就是使用jstack命令来查看程序的所有堆栈信息,但是,这里需要有一个注意的点,26876这个是一个十进制
的,使用jstack看到的nid是十六进制,所以我们需要转换,可以使用printf "%x\n"这个命令

接下来使用jstack -l 26964打印堆栈信息
"pool-1-thread-1" #8 prio=5 os_prio=0 tid=0x00007f00a00f0000 nid=0x6960 runnable [0x00007f008b0ef000]
java.lang.Thread.State: RUNNABLE
at JVMCPU$yupengTask.run(JVMCPU.java:14)
- locked <0x00000000f59dfcf0> (a java.lang.Object)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
......
从上面的信息中,可以看到转换的结果和nid是一致的,从下面的信息中就可以看到问题其实是出现在JVMCPU.java的14行左右,这里给出的是14行,但是实际情况是14行的附近
结合代码来看一下就很容易问题
5.使用arthas解决CPU占用很高的问题,定位具体代码行
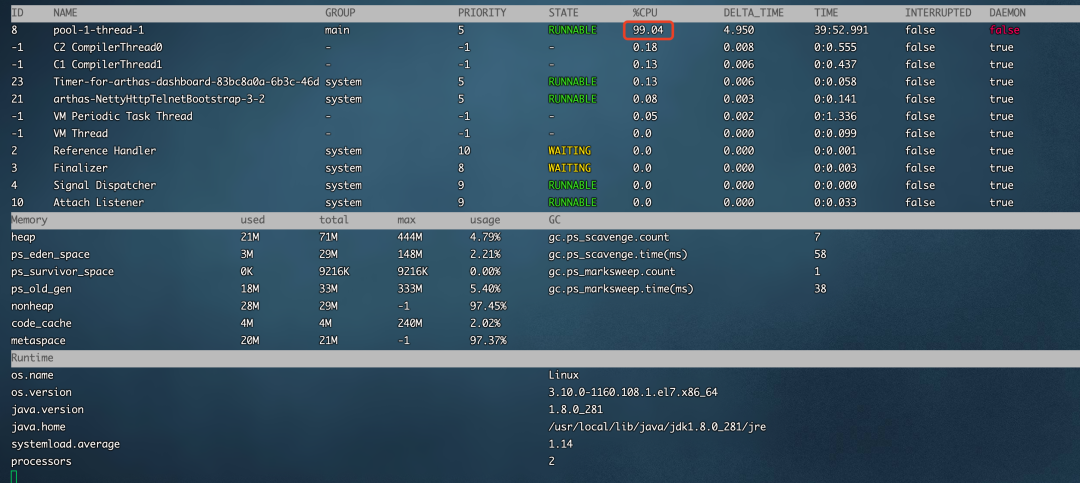
使用arthas解决CPU 100%问题,在方法论上要用到两个命令,
-
dashboard 命令查看TOP N线程,
-
thread 命令查看堆栈信息
先来运行arthas

输入1显示如下
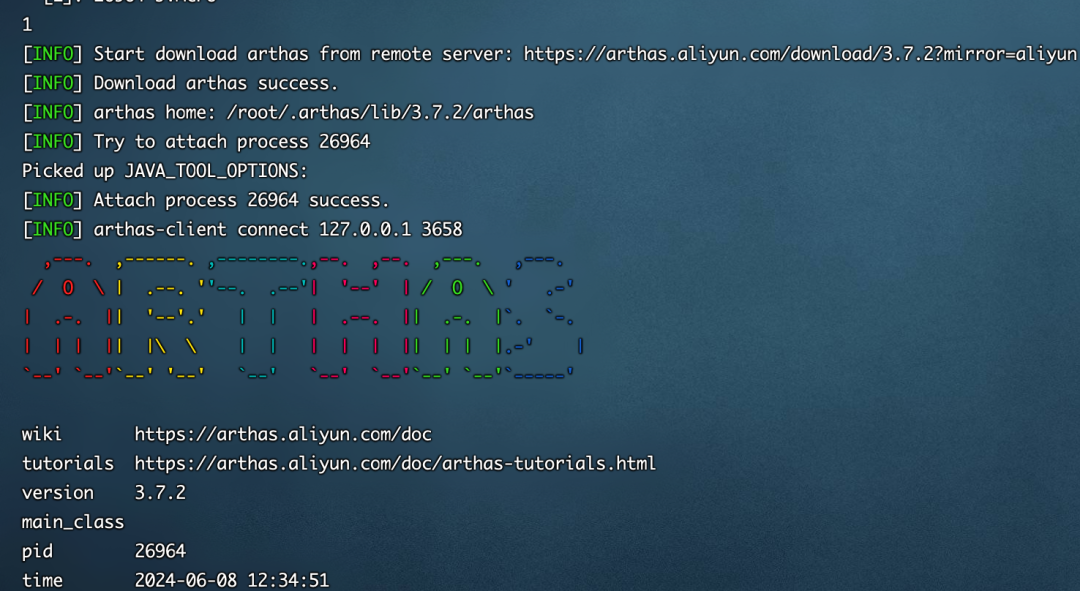
输入dashboard命令可以看到是哪个线程占用cpu最高
接下来输入thread -n 3,表示最忙的前3个线程并打印信息
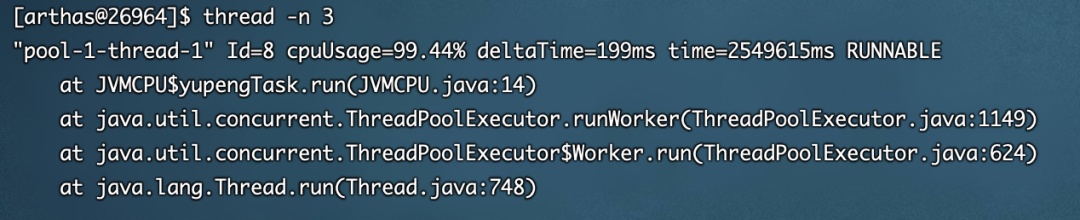
从上面的图中可以看到arthas和jstack展示的信息差不多,都定位到了JVMCPU.java的14行程序
6.死锁导致CPU占用很高的问题分析
public class DeadlockDemo {
// 创建两个锁对象
private static final Object lock1 = new Object();
private static final Object lock2 = new Object();
public static void main(String[] args) {
// 线程1尝试获取lock1,然后获取lock2
Thread thread1 = new Thread(() -> {
synchronized (lock1) {
System.out.println("Thread 1: Holding lock 1...");
try { Thread.sleep(100); }
catch (InterruptedException e) {}
System.out.println("Thread 1: Waiting for lock 2...");
synchronized (lock2) {
System.out.println("Thread 1: Holding lock 1 & 2...");
}
}
});
// 线程2尝试获取lock2,然后获取lock1
Thread thread2 = new Thread(() -> {
synchronized (lock2) {
System.out.println("Thread 2: Holding lock 2...");
try { Thread.sleep(100); }
catch (InterruptedException e) {}
System.out.println("Thread 2: Waiting for lock 1...");
synchronized (lock1) {
System.out.println("Thread 2: Holding lock 2 & 1...");
}
}
});
thread1.start();
thread2.start();
}
}将上面的代码上传到服务器,使用nohuo java DeadlockDemo &运行起来

接下来使用arthas进行分析
这里选择arthas,不选择jstack是因为arthas更加的方便,它的功能也比jstack丰富
输入thread就可以输出线程的统计信息,其中BLOCKED代表当前阻塞的线程数
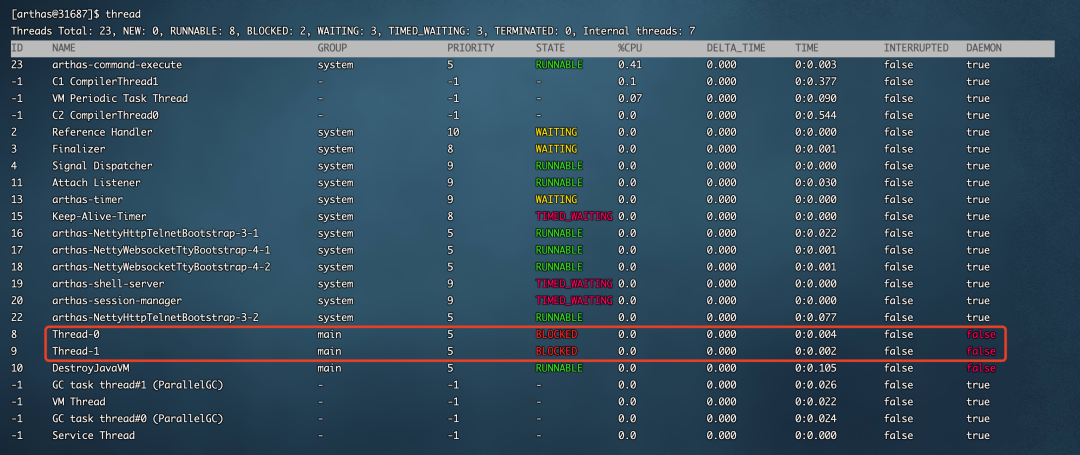
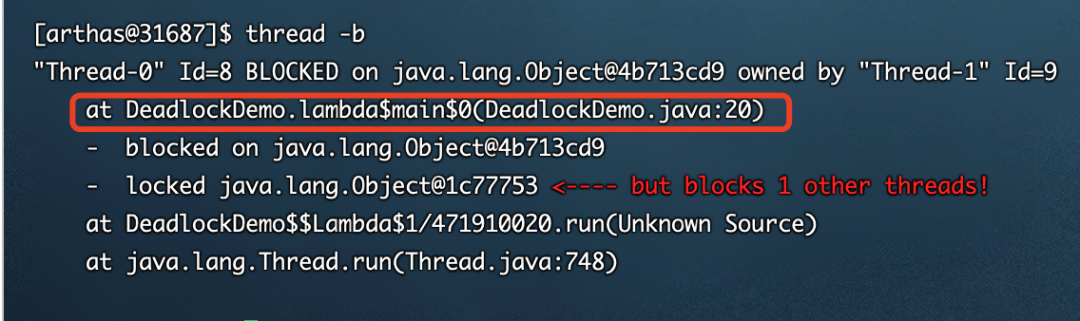
接下来,输入thread -b就可以看到线程具体的情况,在下面的图中已经准确的说明了代码在哪一行
7.小提示
工具的选择建议使用arthas,它还有很多的功能在实际中很有用。
如果遇到cpu被打满该如何排查这样的问题,不要上来就是使用arthas来定位问题,我们的第一反应永远都是回滚版本,因为在实际中代码的问题需要分析,不会像举例子这么简单,代码经过分析改动再上线,会浪费很多时间,而有的业务是绝对不允许这么操作的,比如电商,金融的业务,所以一定要先回滚,再看解决办法。

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









