







Seata 如何实现 RC?保证事务的隔离性?
Seata 事务隔离级别解读
数据库事务的隔离级别,目前数据库事务的隔离级别一共有 4 种,由低到高分别为:
事务的四个隔离级别:
-
未提交读(READ UNCOMMITTED):所有事务都可以看到其他事务未提交的修改。一般很少使用;
-
读已提交(READ COMMITTED):Oracle默认隔离级别,事务之间只能看到彼此已提交的变更修改;
-
可重复读(REPEATABLE READ):MySQL默认隔离级别,同一事务中的多次查询会看到相同的数据行;可以解决不可重复读,但可能出现幻读;
-
可串行化(SERIALIZABLE):最高的隔离级别,事务串行的执行,前一个事务执行完,后面的事务会执行。读取每条数据都会加锁,会导致大量的超时和锁争用问题;

数据库一般默认的隔离级别为 读已提交 RC ,比如 Oracle,也有一些数据的默认隔离级别为 可重复读 RR,比如 MySQL。"可重复读"(Repeatable Read)这个级别确保了对同一字段的多次读取结果是一致的,除非数据是被本身事务自己所修改。它能够防止脏读、不可重复读,但可能会遇到幻读的情况。
MySQL默认的Repeatable Read隔离级别,被改成了RC。 通常,数据库的读已提交(READ COMMITTED)能够满足业务绝大部分场景了。
但是 Seata 却做不到 RC, 只能做到RU。
Seata 的事务是一个全局事务,它包含了若干个分支本地事务,在全局事务执行过程中(全局事务还没执行完),某个本地事务提交了,如果 Seata 没有采取任务措施,则会导致已提交的本地事务被读取,造成脏读,如果数据在全局事务提交前已提交的本地事务被修改,则会造成脏写。
由此可以看出,传统意义的脏读是读到了未提交的数据,Seata 脏读是读到了全局事务下未提交的数据,全局事务可能包含多个本地事务,某个本地事务提交了不代表全局事务提交了。从这个意义上说, seata 的隔离级别是 读未提交。而实际上,这当中又有绝大多数的应用场景,实际上工作在读未提交的隔离级别下同样没有问题。
如何实现 读已提交?默认情况下,Seata 的全局事务是工作在读未提交隔离级别的,保证绝大多数场景的高效性。但是,在极端场景下,应用如果需要达到全局的读已提交,Seata 也提供了全局锁机制实现全局事务读已提交 RC。
Seata 全局锁实现 RC
AT 模式下,会使用 Seata 内部数据源代理 DataSourceProxy,全局锁的实现就是隐藏在这个代理中。接下来看看, seata at分别在执行、提交的过程都做了什么。

如上所示,一个分布式事务的锁获取流程是这样的
-
先获取到本地锁即可修改本地数据,但不能直接提交本地事务
-
为何不能直接提交本地事务呢?因为还未获取全局锁
-
本地锁和全局锁都获得了,才具有全局事务写隔离的保障,本地事务才可以提交,之后释放本地锁
-
当分布式事务执行 2 阶段提交后释放全局锁;这样就可以让其它事务获取全局锁,并提交它们对本地数据的修改了。
至此已明确 Seata 通过将传统 XA 方案的 2 个阶段的本地 DB 锁,拆分成了 本地锁(DB 锁)+ 全局锁的模式 。
如果一个应用所有的事务都用Seata分布式事务,性能一定是很低的。所以在大部分业务场景,并不是所有的操作都要用分布式操作,并不是所有的操作都要用分布式事务, 所以生产场景基本上会是 Seata事务 + 独立事务 组合模式。
那么,在 Seata事务 + 独立事务 场景下,Seata 的全局锁对于外部的独立事务失效了,对于外部事务,本质上是Seata默认的全局事务是读未提交,能读到Seata未提交(Seata分支已提交的分支事务的数据)的数据,于是,本地事务会发生 脏读。
如何实现 Seata事务 + 独立事务 场景的 RC? 如何解决 独立本地事务的 脏读问题?
Seata事务 + 独立事务 场景的 脏读、脏写
AT 模式是一种非侵入式的分布式事务解决方案,Seata 在内部做了对数据库操作的代理层,我们使用 Seata AT 模式时,实际上用的是 Seata 自带的数据源代理 DataSourceProxy。
Seata 在这层DataSourceProxy 代理中加入了很多逻辑,比如:
-
插入回滚 undo_log 日志
-
检查全局锁等。
为什么要检查全局锁呢,这是由于 Seata AT 模式的事务隔离是建立在支事务的本地隔离级别基础之上的,在数据库本地隔离级别读已提交或以上的前提下,Seata 设计了由TC维护的全局写排他锁,来保证事务间的写隔离,实现分布式事务的 RC。
先来看一下Seata事务 + 独立事务 场景,使用 Seata AT 模式是怎么产生脏读的:
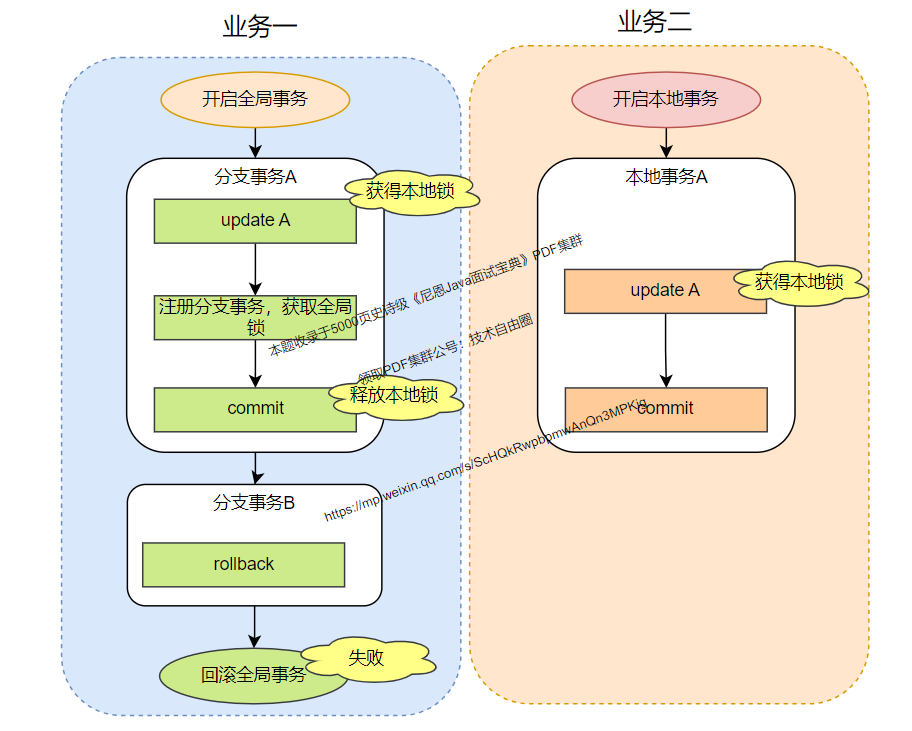
业务一开启seata 分布式事务,其中包含分支事务A(修改 A)和分支事务 B(修改 B),业务二开启本地事务,仅仅修改 A,其中业务一执行分支事务 A 先获取本地锁,业务二则等待业务一执行完分支事务 A 之后,获得本地锁修改 A 并提交,业务一在执行分支事务时发生异常了,由于分支事务 A 的数据被业务二修改,导致业务一的全局事务无法回滚,需要人工干预。
这里发生了两种错误的现象:
-
业务2 发生了脏读
-
业务1 发生了脏写
如何防止脏读 、脏写? 帮助 Seata+ 独立事务 场景实现 RC。
方案有两种:
-
独立事务 升级为分布式事务
-
业务二查询 A 时加 @GlobalLock 注解 + select for update语句
如何防止脏读/脏写
Seata AT 模式的脏读是指在全局事务未提交前,被其它业务读到已提交的分支事务的数据,本质上是Seata默认的全局事务是读未提交。
那么怎么避免脏读、脏写现象呢?
方案一:独立事务执行时加 @GlobalTransactional注解:
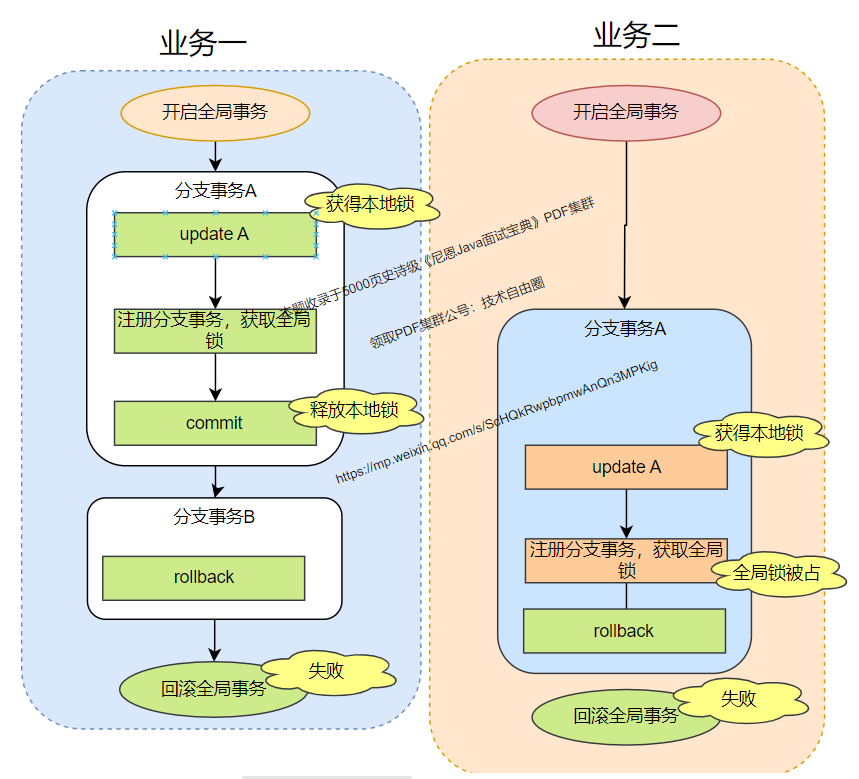
业务二在执行全局事务过程中,分支事务 A 提交前注册分支事务获取全局锁时,发现业务业务一全局锁还没执行完,因此业务二提交不了,抛异常回滚,所以不会发生脏写。
方案二:独立事务业务二执行时加 @GlobalLock注解:
全局事务 很重。
因此,在不需要全局事务、而又需要检查全局锁避免脏读脏写的场景,可以使用@GlobalLock注解实现隔离的功能,@GlobalLock是一个更加轻量的操作。
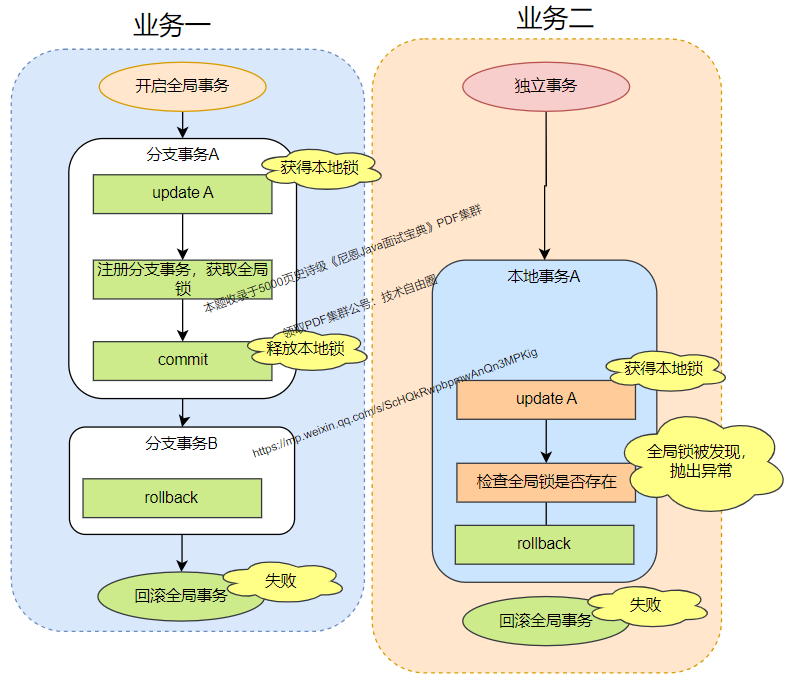
与 @GlobalTransactional注解效果类似,只不过 业务二不需要开启全局事务,只在本地事务提交前,检查全局锁是否存在。如果存在,就抛出异常,从而本地事务回滚。
@GlobalTransactional注解 开启全局事务是一个比较重的操作,需要向 TC 发起开启全局事务等 RPC 过程,而@GlobalLock注解只会在执行过程中查询全局锁是否存在,不会去开启全局事务,
方案三:业务二执行时加 @GlobalLock 注解 + select for update语句:
如果独立事务希望最终能够 提交, 在发现全局锁的过程中, 独立事务希望等待和重试,则可以使用下面的方案:
加 @GlobalLock 注解 + select for update语句
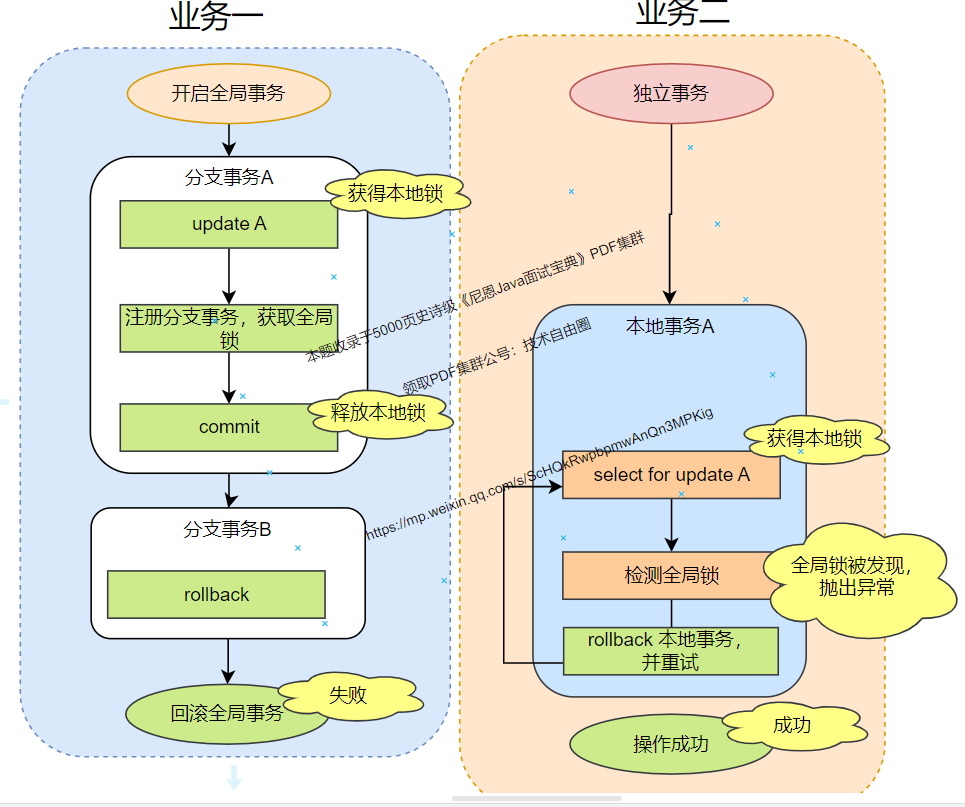
如果加了select for update语句,则会在 update 前检查全局锁是否存在,只有当全局锁释放之后,业务二才能开始执行 updateA 操作。
加select for update语句会在执行 SQL 前检查全局锁是否存在,只有当全局锁完成之后,才能继续执行 SQL,这样就彻底防止了脏读+脏写, 也能保护 独立事务不会 直接回滚。
所以@GlobalLock 注解 加 select for update 也有个好处,就是可以重试。
请设计一个高可用性的软件架构,说明设计思路
HA的目标
高可用,英文单词High Availability,缩写HA,它是分布式系统架构设计中一个重要的度量。
业界通常用多个9来衡量系统的可用性,如下表:
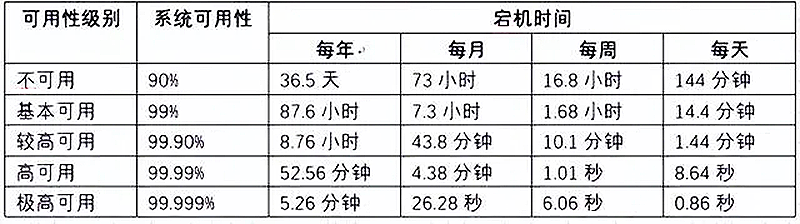
既然有可用率,有一定会存在不可用的情况。不可用一般分为有计划的和无计划的,有计划的如日常维护、系统升级等,无计划的如设备故障、突发断电等。
我们对不可用的问题作如下分类:
-
设备故障:机房断电、硬盘损坏、交换机故障。
-
网络故障:网络带宽拥堵、网络连接中断。
-
安全问题:利用系统漏洞进行网络攻击。
-
性能问题:CPU利用率太高、内存不足、磁盘IO过载、数据库慢SQL。
-
升级维护:由于业务变更或技术改进而引起的系统升级。
-
系统问题:分布式系统中存在服务的依赖而导致数据的不一致性,或是核心服务出现异常。
-
云平台崩溃:2023-11月左右,互联网P0级(宕机几个小时)故障频发:语雀一个月前崩了,接着阿里云崩,阿里云崩完、滴滴崩......而且都是宕机几个小时,影响面广,例如由于滴滴平台不能提供服务。这些事故都是底层基础架构崩溃,比如云平台崩溃导致,问题非常难定
-
机房宕机:2023 年6 月 5 日,唯品会发布关于 329 机房宕机故障处理公告。官方在公告中称,南沙机房重大故障影响时间持续 12 个小时,导致公司业绩损失超亿元,影响客户达 800 多万。公司让对应部门的直接管理者承担此次事故责任,基础平台部负责人予以免职处理。
-
其他问题:其他的引发线上故障的问题。
如何体系化、系统化、彻底化的解决 HA 问题。
总的策略:高可用分而治之
一张图总结架构设计的40个黄金法则,介绍了架构的本质:
典型架构分层设计如下:按照功能处理顺序划分应用,这是面向业务深度的划分。每个公司的架构分层可能不一样,但是目的都是为了统一架构术语,方便团队内部沟通。
-
接入层:主要流量入口,经过简单
-
应用层:直接对外提供产品功能,例如网站、API接口等。应用层不包含复杂的业务逻辑,只做呈现和转换。
-
服务层:根据业务领域每个子域单独一个服务,分而治之。
-
数据层:数据库和NoSQL,文件存储等。
和高并发/大数据的架构设计一样,HA一般是分层进行,有关高并发/大数据的架构设计, 具体请参见:
HA 可以的架构设计 从下面的5大层来建设和分析:
1:接入层:
主要流量入口
2:应用层:
负责具体业务和视图展示;
网站首页、用户中心、商品中心、购物车、红包业务、活动中心等,
3:服务层:
根据业务领域每个子域单独一个服务,分而治之。
服务层为应用层提供服务支持;比如:订单服务、用户管理服务、红包服务、商品服务等
这个是我们重点要关注的架构设计,架构设计不合理,就很难抗住高并发,主要包括各种架构和模块的设计。
4:数据层:
数据库和NoSQL,文件存储等。
关系数据库、nosql数据库等,提供数据存储查询服务。
5:基础设施层:
这个是最基础的依赖,主要是一些服务的部署。
基础设施层一般包含了服务器、中间件、部署方式等等。
第1层:接入层的HA架构方案:
接入层 总的策略:动静分离,分而治之
-
动态资源使用 Nginx+LVS+KeepAlive 进行负载均衡
-
静态资源使用 CDN进行加速
接入层的HA架构方案,包括:
-
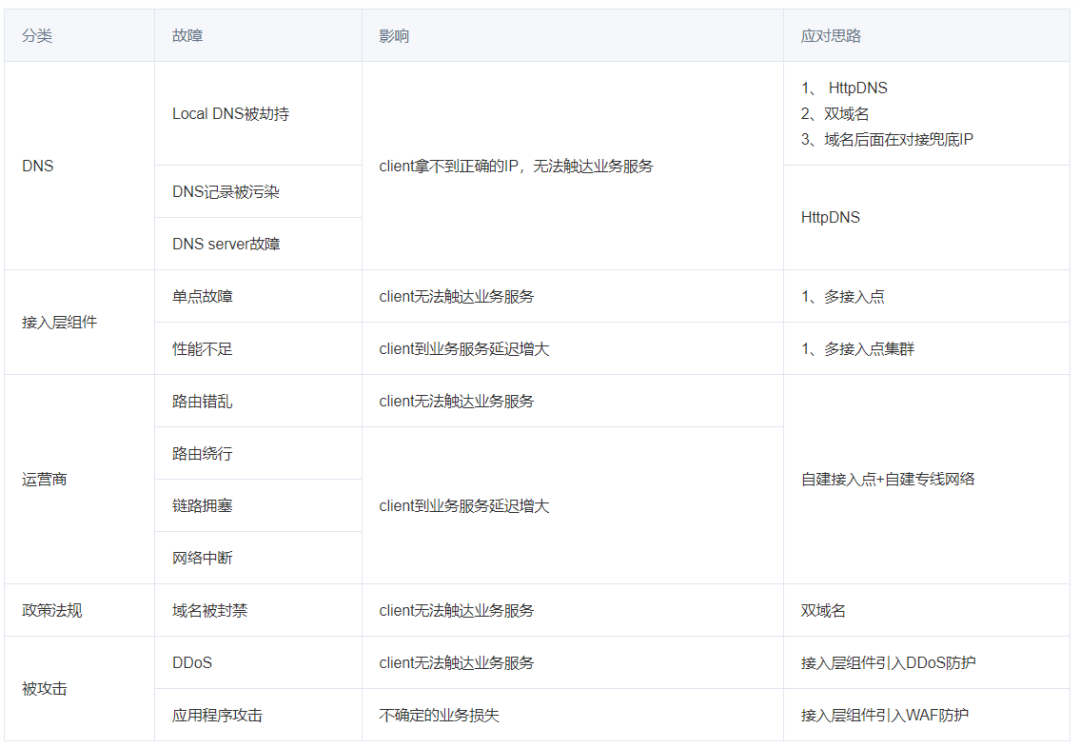
DNS高可用,采用 双域名、 多接入点等措施,避免dns单点故障,和性能不足
-
LVS 高可用
-
Nginx 高可用
DNS高可用 应对措施如下:
LVS 高可用 + Nginx 高可用, 可以参见:
10Wqps网关接入层,LVS+Keepalived(DR模式)如何搭建?
主要策略:采用keepalive 保证 nginx、lvs 的高可用避免单点瓶颈
第2/3层:应用层/服务层HA架构方案:
应用层/服务层HA架构的主要原则:
原则1、可以水平扩展:
首先通过业务解耦、技术解耦, 把大单体架构解耦为 微服务架构。
然后对后端微服务,通过接入层的负载均衡,实现故障自动转移。
原则2、无状态设计:
无状态的系统更利于水平扩展,更利于做负载均衡。
状态是系统的吞吐量、易用性、可用性、性能和可扩展性的大敌,要尽最大可能避免。
原则3、监控预警(可监控):
至少包括三个维度的监控预警:Logging(日志) 的监控 、Tracing(调用链)监控、Metrics(指标)监控。
原则4、灰度发布(可灰度):
结合接入层设计A/B 功能,实现灰度发布,比如按ip,请求参数等分发流量。
原则5、回滚设计(可回滚) :
确保系统可以向后兼容,如果应用服务上线后出现bug,可以紧急回滚。
应用层/服务层HA架构的主要策略:
可以水平扩展 的前提,就是先业务解耦
1:业务解耦
对一个复杂的业务,需要分割成不同的模块单元,分而治之。一个大的问题域,需要分解为很多小的问题域,分而治之。就是是微服务划分、微服务架构。
微服务架构解决大单体架构的的很多问题,比如扩展性、弹性伸缩能力、小规模团队的敏捷开发等等。
如何进行微服务架构,如何划分微服务:
-
高内聚低耦合
-
单一职责
-
可扩展原则
-
等等等等
如何进行业务解耦,如何划分微服务?在实操过程中, 建议使用DDD的建模方法进行建模。
字节面试:微服务一定要DDD,为什么?TDD和DDD 有何关系?
2:横向扩展设计
横向扩展设计,包括:应用集群、服务集群
应对高并发系统,单节点模式都不可能搞定,因此都需要搭建应用集群、服务集群,常见的微服务Provider的自动伸缩策略有以下两种:
1)通过Kubernetes HPA组件实现自动伸缩。
2)通过微服务Provider自动伸缩伺服组件实现自动伸缩。

3:链路隔离、分级冗余
服务层冗余设计最主要原则:服务分级管理
不同的服务,可用性要求不一样,我们需要先这些服务做分级。或者说:不同的链路,可用性要求不一样,我们需要先这些链路做分级。有些是黄金链路, 有的是非核链路。
1、各级服务的HA部署原则:
-
链路隔离
-
分级冗余
黄金链路上的核心服务:进行链路隔离, 独立服务器,且N+1部署。非核链路上的普通服务:集中部署,可以共享服务器部署。
2、各级服务HA上线发布原则:
-
核黄金链路上的核心服务:晚上12点上线。
-
非核链路上的普通服务:随时可上线
4:服务的三可原则落地
原则3、监控预警(可监控):
至少包括三个维度的监控预警:Logging(日志) 的监控 、Tracing(调用链)监控、Metrics(指标)监控。
服务要能接入 elk、 Skywalking 、metric 三大监控底
原则4、灰度发布(可灰度):
结合接入层设计A/B 功能,实现灰度发布,比如按ip,请求参数等分发流量。
原则5、回滚设计(可回滚) :
确保系统可以向后兼容,如果应用服务上线后出现bug,可以紧急回滚。
第四层:数据层HA架构方案
数据库的HA架构设计旨在提供高可用性、高性能和可扩展性的数据库服务。
数据层HA架构方案包括主从复制、自动切换和负载均衡等关键技术,以确保数据的持久性、可靠性和可用性。
一、主从复制
主从复制是一种常见的数据库同步技术,通过将主数据库的数据,实时同步到多个从数据库来实现的。在该架构中,主库负责处理写入操作,而从库则负责处理读取操作。
主从复制的工作原理是,主库接收到写入请求后,将数据变更记录在二进制日志(Binlog)中,并将其同步到从库。从库通过读取主库的Binlog,并将其中的数据变更应用到自身的数据库中。
通过这样的复制机制,从库能够实现与主库的数据同步,从而保证了数据的一致性。
二、自动切换
自动切换是数据库HA架构设计中的另一个关键技术。
当主库发生故障或不可用时,自动切换机制能够快速将从库切换为主库,以确保系统的持续可用性。在自动切换机制中,通常会采用心跳检测的方式来监测主库的状态。
当主库无法正常响应时,自动切换机制会立即启动,并将系统切换到可用的从库上。同时,还需要确保新的主库能够接收和处理写入请求,以保证系统的正常运行。
三、负载均衡
负载均衡是数据库HA架构设计中不可或缺的一环。
通过负载均衡技术,可以将用户的请求均匀地分发到不同的数据库节点上,以实现请求的并行处理和数据的平衡负载。
在负载均衡的实现中,通常会采用多个数据库节点来共同处理用户的请求。
通过将用户请求导入到不同的节点上,并根据节点的负载情况进行动态调整,可以实现对数据库系统的优化和提升。
四、容灾备份
容灾备份是云数据库HA架构设计中的重要环节。
通过将数据进行备份,并将备份数据存储在不同的地理位置,可以在发生灾难性故障时,尽快恢复数据库的可用性。
容灾备份通常会采用异地备份的方式,即将数据备份复制到不同的数据中心或服务器上。
这样一来,即使某个数据中心或服务器发生故障,备份数据仍然可用,从而实现了对数据库系统的灾难恢复能力。
第五层:基础设施层架构
基础设施层架构 包含:
-
监控三大件: logging、tracing、metrics。
-
各种中间件:nacos,redis, rocketmq 等等各类中间件,都要高可用部署
-
ci,cd组件
综合性的措施和机制
除了以上五层,每一层的方案, 需要一些综合性的措施和机制,包括但不限于:
-
360度全方位的监控告警机制
综合措施1:360度全方位的监控告警机制
在高可用服务设计章节提到,核心服务可以监控:服务流量预警、端口存活、进程占用的资源、服务接口功能逻辑是否正常,应用FGC等情况,需要一个完善监控告警机制,并在告警后,通过一定的策略进行处理,以致服务可以快速恢复。例如,监控FGC,如果在一分钟内存出现10次FGC,自动重启服务。
360度全方位的监控告警机制,包括但不限于:
-
网络流量监控 。
-
系统监控:服务器资源和网络相关监控(CPU、内存等)
-
日志监控:统一日志收集(各个服务)监控,跟踪(log2) 。
-
应用监控:端口存活、进程占用的资源,应用FGC等情况
-
业务监控 :服务接口功能逻辑是否正常
-
立体监控 监控数据采集后,除了用作系统性能评估、集群规模伸缩性预测等, 最终目标是还可以根据实时监控数据进行风险预警,并对服务器进行失效转移,自动负载调整,最大化利用集群所有机器的资源。
综合措施2:做好过载保护
-
备份:数据备份(热备,冷备(冗余),异地)
-
过载保护:熔断,限流,降级
-
重试,防雪崩(概率很小,成本很高)
综合措施3:异地容灾,单元化+异地多活设计
单元化+异地多活设计,既是高并发的核武器,也是高可用的核武器
在一些极端场景下,有可能所有服务器都出现故障,例如机房断电、机房火灾、地震等这些不卡抗拒因素会导致系统所有服务器都故障从而导致业务整体瘫痪,而且即使有其他地区的备份,把备份业务系统全部恢复到能够正常提供业务,花费的时间也比较长。
为了满足中心业务连续性,增强抗风险能力,多活作为一种可靠的高可用部署架构,成为各大互联网公司的首要选择。
1:单元化(Set化)设计
一个服务对外的使用方可能有 A 业务、B 业务,那么如何保证 AB 业务不会相互影响,那么就是单元化(Set化)设计。
所谓单元,是指一个能完成所有业务操作的自包含集合,在这个集合中包含了所有业务所需的所有服务,以及单元的数据分片。
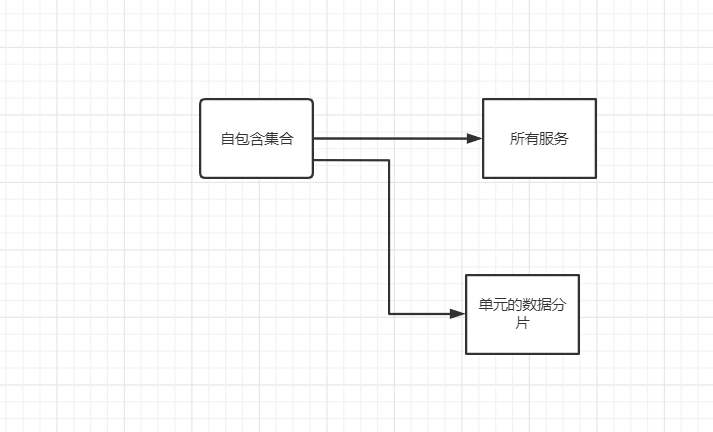
单元化架构就是把单元作为系统部署的基本单位,在全站所有idc机房中部署数个单元.
每个idc机房里的单元数目不定,任意一个单元都部署了系统所需的所有的服务。
任意一个单元的数据是首先拥有分片数据,但是为了切流的方便, 最终需要拥有全量数据。
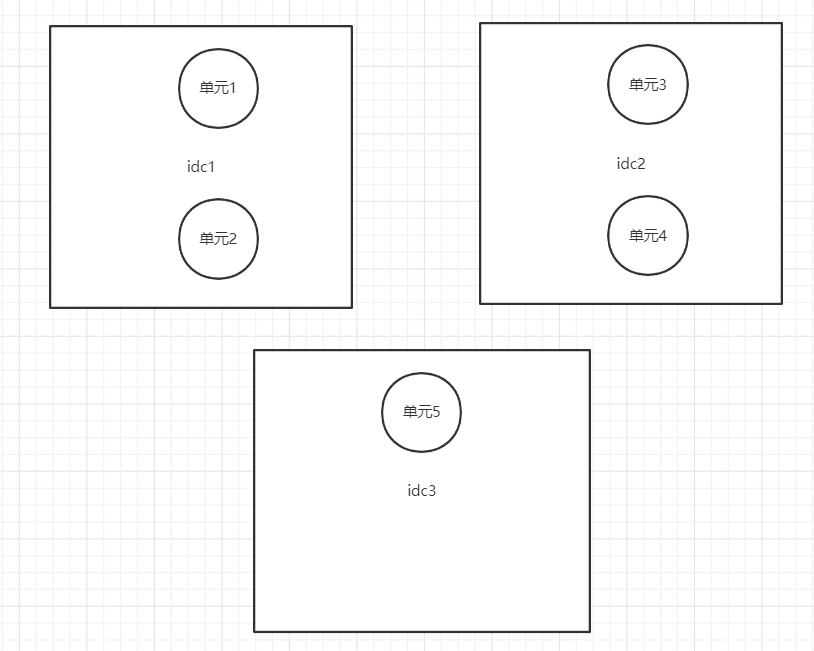
传统意义上的 SOA 化(服务化)架构,服务是分层的,每层的节点数量不尽相同,上层调用下层时,随机选择节点。
单元化架构下,服务仍然是分层的,
不同的是每一层中的任意一个节点都属于且仅属于某一个单元,上层调用下层时,仅会选择本单元内的节点。
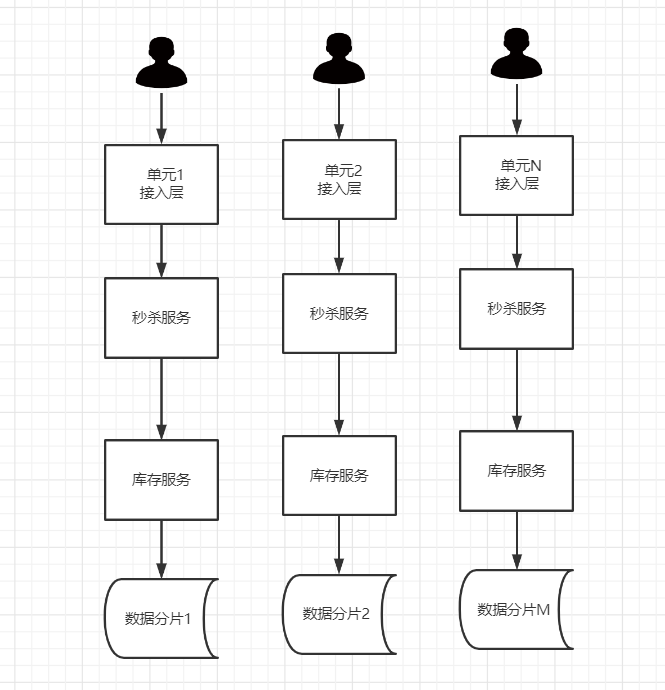
而要做到单元化,必须要满足以下要求:
-
业务必须是可分片的,如 淘宝按照用户分片, 饿了么按照地理位置分片
-
单元内的业务是自包含的,调用尽量封闭
单元化署就是把业务系统分为多个可扩展的逻辑分区,每个 SET 的逻辑分区都可以独立部署并提供服务,SET 也可以理解为 ”逻辑机房“ ,主要目的就是为了进行独立部署并且做到业务上的逻辑隔离。
关于 单元化SET 的具体例子:
-
微信红包用户发一个红包时,微信红包系统生成一个ID作为这个红包的唯一标识。
-
接下来这个红包的所有发红包、抢红包、拆红包、查询红包详情等操作,都根据这个ID关联。
-
红包系统根据这个红包ID,按一定的规则(如按ID尾号取模等),垂直上下切分。
-
切分后,一个垂直链条上的逻辑Server服务器、DB统称为一个SET。
单元化SET 部署之后,系统将所有红包请求这个巨大的洪流分散为多股小流,互不影响,分而治之。
现在稍微有点体量的公司都在做单元化,单元化的好处
- 多AZ(可用区) 容灾、异地多活。
- 服务器体量太大,单一IDC没有足够的机器。
- 提升用户请求访问速度。
2:多 IDC + 异地多活
基础设施层一般包含了服务器、IDC、部署方式等等。
-
多 IDC 部署。比如服务同时在广州、上海两地部署。这个依赖我们的服务是无状态的;
-
其他的参考下异地多活架构等相关部署。
3:流量分片路由+ 流量切换
在接入层之上,再部署一个「路由层」(通常部署在云服务器上),自己可以配置路由规则,把用户「分流」到不同的机房内。
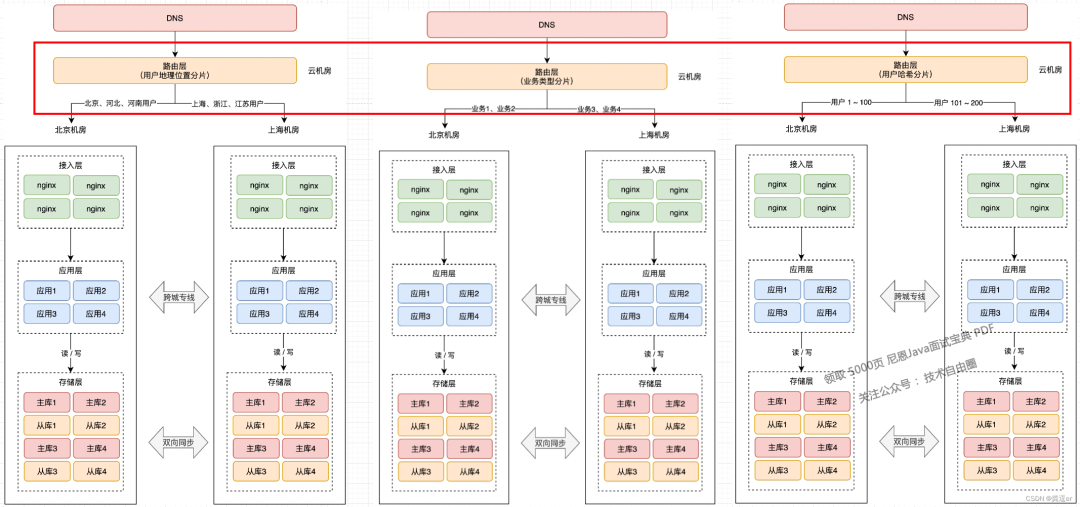
但这个路由规则,具体怎么定呢?有很多种实现方式,最常见的总结了 3 类:
1.按地理位置分片
非常适合与地理位置密切相关的业务,例如打车、外卖服务就非常适合这种方案。
拿外卖服务举例,你要点外卖肯定是「就近」点餐,整个业务范围相关的有商家、用户、骑手,它们都是在相同的地理位置内的。举例:北京、河北地区的用户点餐,请求只会打到北京机房,而上海、浙江地区的用户,请求则只会打到上海机房。这样的分片规则,也能避免数据冲突。
但是,上海机房和 北京机房进行数据复制, 当一个机房发生故障时,路由层把流量切换到 另一个机房。
2.按业务类型分片
假设一共有 4 个应用,北京和上海机房都部署这些应用。但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。
这样一来,应用 1、2 的所有业务请求,只读写北京机房存储,应用 3、4 的所有请求,只会读写上海机房存储。
但是,上海机房和 北京机房进行数据复制, 当一个机房发生故障时,路由层 把流量切换到 另一个机房。
3.直接哈希分片
会根据用户 ID 计算「哈希」取模,然后从路由表中找到对应的机房,之后把请求转发到指定机房内。
举例:一共 200 个用户,根据用户 ID 计算哈希值,然后根据路由规则,把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房,这样,就避免了同一个用户修改同一条数据的情况发生。
但是,上海机房和 北京机房进行数据复制, 当一个机房发生故障时,路由层 把流量切换到 另一个机房。
分片的核心思路在于,让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问。正因为如此,阿里在实施这种方案时,给它起了个名字,叫做「单元化」。
使用Netty架构100Wqps网关
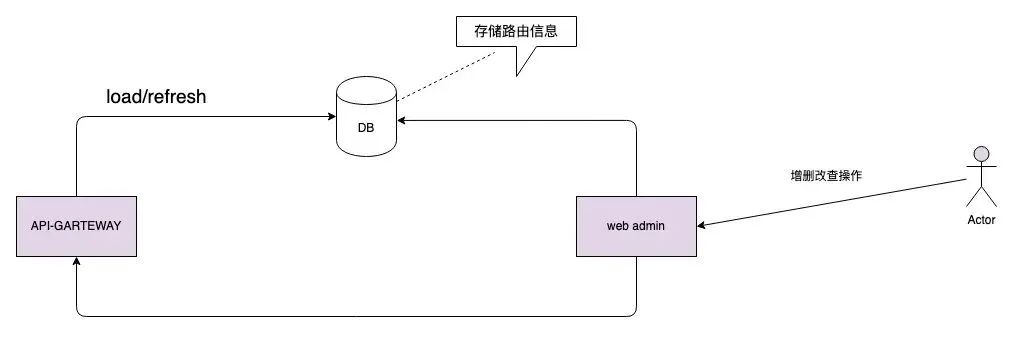
什么是API网关?
API 网关是一种服务器,作为应用程序编程接口 (API) 的入口点,它接收来自外部应用程序的请求,进行处理,并给出恰当的回应。你可以将它看作一个中间件,管理API的访问,并在请求与回应之间进行转换、路由、安全检查等操作。
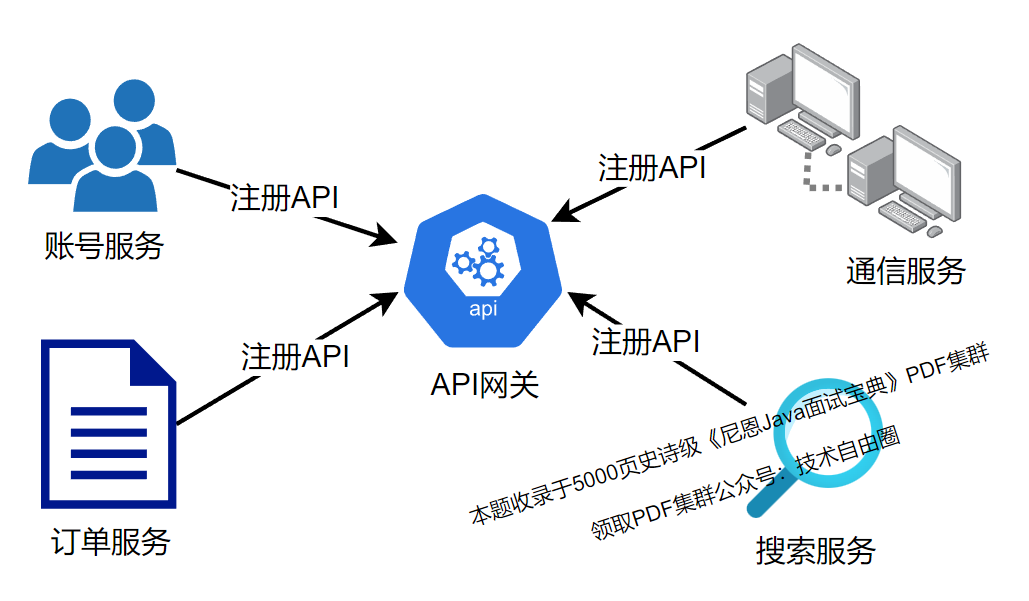
API网关功能
得物自研API网关(DAG)实践之路
一、业务背景
我们之前的网关是基于Spring Cloud Gateway(简称SCG)技术框架搭建的。SCG基于webflux编程范式,webflux是一种响应式编程理念,对于提高系统的吞吐量和性能有很大的帮助,webflux 的底层构建在netty之上, 性能表现优秀;
SCG是spring生态的产物,具有开箱即用的特点,较低的使用成本助力得物早期的业务快速发展;
然而,随着公司业务的快速发展,流量越来越大,网关的业务逻辑越来越多,以及安全审计需求的不断升级和稳定性需求的提高,SCG在以下几个方面逐步暴露了一系列的问题。
SCG的网络安全问题
从网络安全角度来讲,对公网暴露接口无疑是一件风险极高的事情,网关是对外网络流量的重要桥梁,早期的接口暴露采用泛化路由的模式,即通过正则形式( /api/v1/app/order/** )的路由规则开放接口,单个应用服务往往只配置一个泛化路由,后续上线新接口时外部可以直接访问;
这种做法带来了极大的安全风险,很多时候业务开发的接口可能仅仅是内部调用,但是一不小心就被泛化路由开放到了公网,甚至很多时候没人说得清楚某个服务具体有多少接口属于对外,多少对内;
另一方面从监控数据来看,黑产势力也在不断对我们的接口做渗透试探。
网络黑产,也称为网络黑色产业链,主要是指通过互联网技术进行网络攻击、窃取信息、勒索诈骗、盗窃财产、推广色情和赌博等非法网络活动,以及为这些活动提供工具、资源、平台等支持和非法获利变现的渠道和环节。
黑产势力产业具备两个特点,一是,他们的骗局设计非常周密,模仿了互联网平台的客户服务场景,从宣传引导到电话和微信等客服交流,精心设计陷阱让首次接触的消费者难以区分真伪。二是,他们利用移动支付手段,利用了互联网信息管理不完善的漏洞。犯罪分子利用他人信息申请虚拟运营商电话卡,隐藏自己的行踪,使公安机关难以找到犯罪分子的真实信息。此外,二维码等移动支付方式非常便捷,消费者支付后的资金流向往往难以追踪。
在中央网信办、工业和信息化部、公安部、人民银行的指导下,国家互联网应急中心支持相关部门开展网络黑产治理工作。从2019年6月至10月,他们累计治理了561万个活跃手机黑卡,3万余个赌博网站,60个非法网络金融平台,1000余个黑产交流传播群组,11个违规广告联盟,124个浏览器主页劫持恶意软件,60个大型赌博洗钱团伙线索,以及28个DDoS攻击控制端。
SCG的协同效率问题
通过引入接口注册机制,所有对外开放的接口都必须注册到网关,未经注册的接口无法被访问,从而确保了安全性,然而,这种方式也带来了性能问题。SCG采用遍历方式匹配路由规则,接口注册模式推广后路由接口注册数量迅速提升到3W+,路由匹配性能出现严重问题;
在泛化路由时代,每个服务仅需一个路由配置,且变更频率较低,主要由网关开发人员负责配置,这样的效率尚可,但接口注册模式将路由工作移交给了业务开发人员,这就需要建立一个完整的路由审核流程,以提高协同效率;
由于早期所有路由信息都存储在配置中心,这不仅给配置中心带来了巨大压力,也增加了稳定性风险。
SCG的性能与维护成本问题
随着业务迭代的不断增加,API网关积累了大量业务逻辑,这些业务逻辑分散在不同的filter中,为了降低开发成本,网关采用了一套主线分支,不同集群的代码完全相同,然而,不同集群的业务属性不同,所需的filter逻辑也不尽相同;
如内网网关集群几乎没什么业务逻辑,但是App集群可能需要几十个filter的逻辑协同工作;
这样的一套代码对内网网关而言,存在着大量的性能浪费;因此,如何平衡维护成本和运行效率是一个需要深入思考的问题。
SCG的稳定性风险
API网关作为基础服务,承载全站的流量出入,稳定性无疑是第一优先级,然而,其定位决定了绝不可能是一个简单的代理层,在稳定运行的同时依然需要承接大量业务需求,例如,C端用户登录下线能力,App强升能力,B端场景下的鉴权能力等;
很难想象较长一段时间以来,网关都保持着双周一次的发版频率;
频繁的发版也带来了一些问题,实例启动初期有很多资源需要初始化,此时承接的流量处理时间较长,存在着明显的接口超时现象;早期的每次发版几乎都会导致下游服务的接口短时间内超时率大幅提高,而且往往涉及多个服务一起出现类似情况;
为此甚至拉了一个网关发版公告群,提前置顶发版公告,让业务同学和NOC有一个心里预期;在发布升级期间尽可能让业务服务无感知这是个刚需。
SCG的定制能力问题
流量灰度是网关最常见的功能之一,对于新版本迭代,业务服务的某个节点发布新版本后希望引入少部分流量试跑观察,但很遗憾SCG原生并不支持,需要对负载均衡算法进行手动改写才可以,此外基于流量特征的定向节点路由也需要手动开发,由于负载均衡算法是SCG的核心模块,不对外暴露,因此改造成本较高。
此外,B端和C端业务对接口响应时间的需求不同,SCG也无法满足这种定制化需求,B端场景下下载一个报表用户可以接受等待10s或者1分钟,但是C端用户现在没有这个耐心。
作为代理层针对以上的场景,我们需要针对不同接口定制不同的超时时间,原生的SCG显然也不支持。
诸如此类的定制需求还有很多,我们并不寄希望于开源产品能够开箱即用满足全部需求,但至少定制性拓展性足够好。上手改造成本低。
SCG在协同效率、性能、维护成本、稳定性风险和定制能力方面存在一系列问题。这些问题源于接口注册机制带来的性能影响、业务逻辑分散导致的维护成本问题、稳定性风险的挑战、缺乏灵活的定制能力,以及对不同业务需求的不适应。解决这些问题需要重新审视和优化接口注册机制、路由策略、负载均衡算法,以及提高网关的定制性和扩展性,以确保API网关能够高效、稳定地支撑业务发展。
二、SCG的技术痛点
SCG主要基于webflux技术构建,其底层依赖于reactor-netty,而reactor-netty又是基于netty的;
这种架构使得SCG能够与spring cloud的技术组件无缝集成,开箱即用,为得物早期的业务快速发展提供了便利;
然而,使用webflux技术也带来了一些成本,首先它会额外增加编码人员的心智负担,他们需要理解流的概念以及常用的操作函数,诸如map, flatmap, defer 等等;其次,异步非阻塞的编程方式导致代码中充满了回调函数,这可能会割裂业务逻辑的顺序性,增加代码的阅读和理解难度;
进一步评估发现,SCG存在一些缺点:
内存泄露问题
SCG存在多个内存泄漏问题,这些问题的排查困难,且官方迟迟未能修复。长期运行可能导致服务触发OOM并宕机;
以下为github上SCG官方开源仓库的待解决的内存泄漏问题,大约有16个之多。
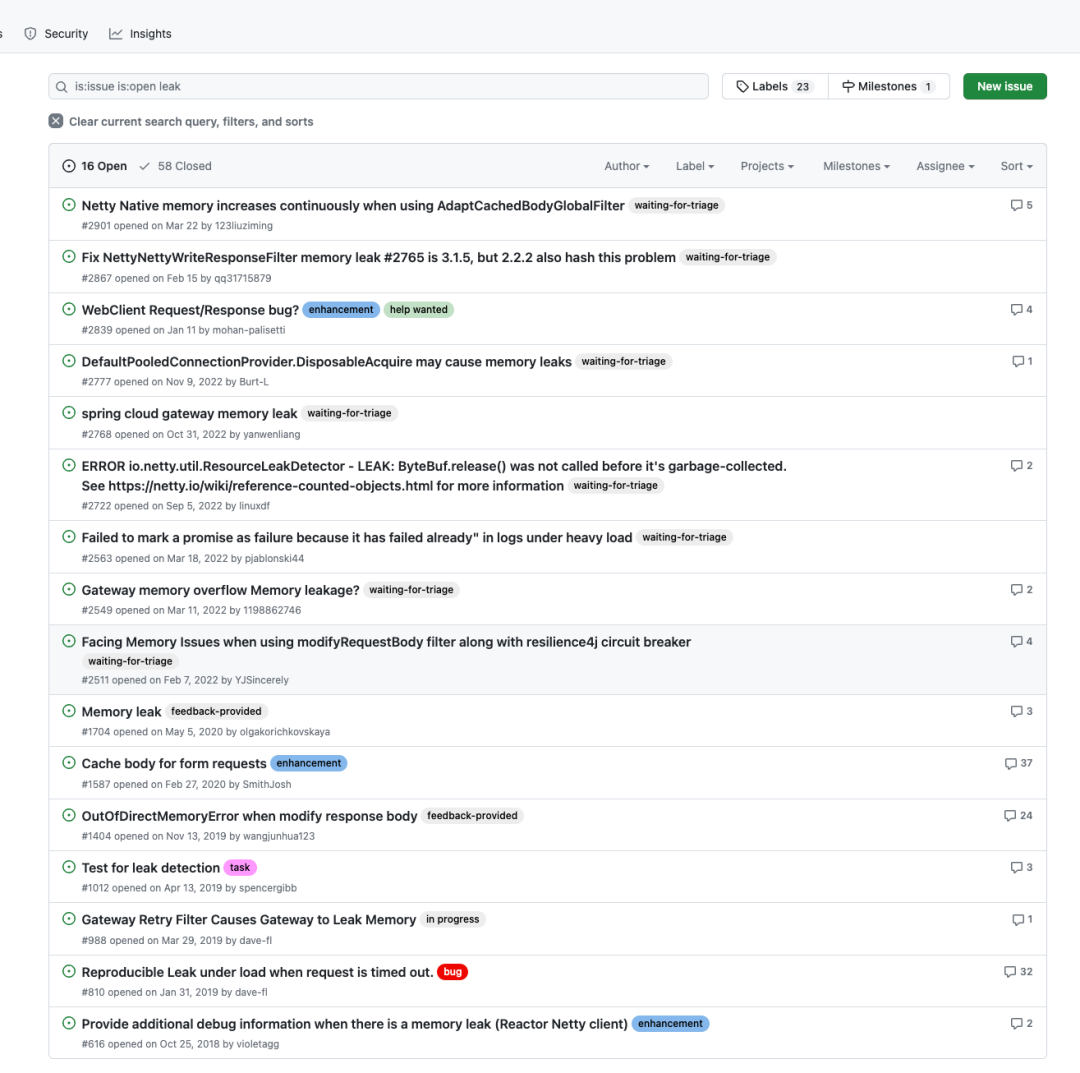
SCG内存泄漏BUG
下图可以看到SCG在长期运行的过程中内存使用一直在增长,当增长到机器内存上限时,当前节点将不可用,联系到网关单节点所承接的QPS 在几千,可想而知节点宕机带来的危害有多大;
一段时间以来我们需要对SCG网关做定期重启。
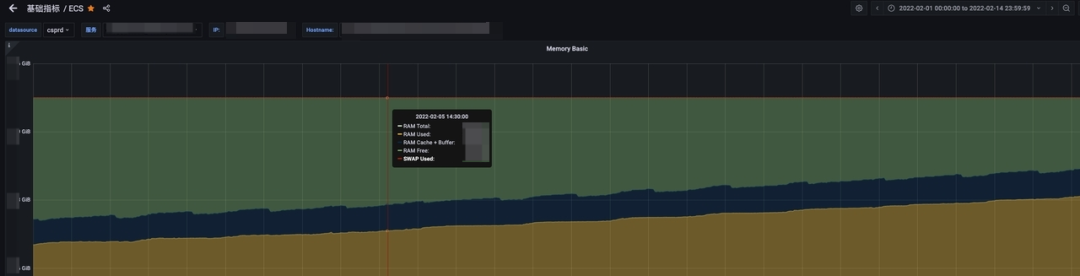
SCG生产实例内存增长趋势
响应式编程范式复杂
基于webflux的flux和mono,在对request和response信息读取修改时,编码复杂度高,代码理解困难,下图是对body信息进行修改时的代码逻辑。
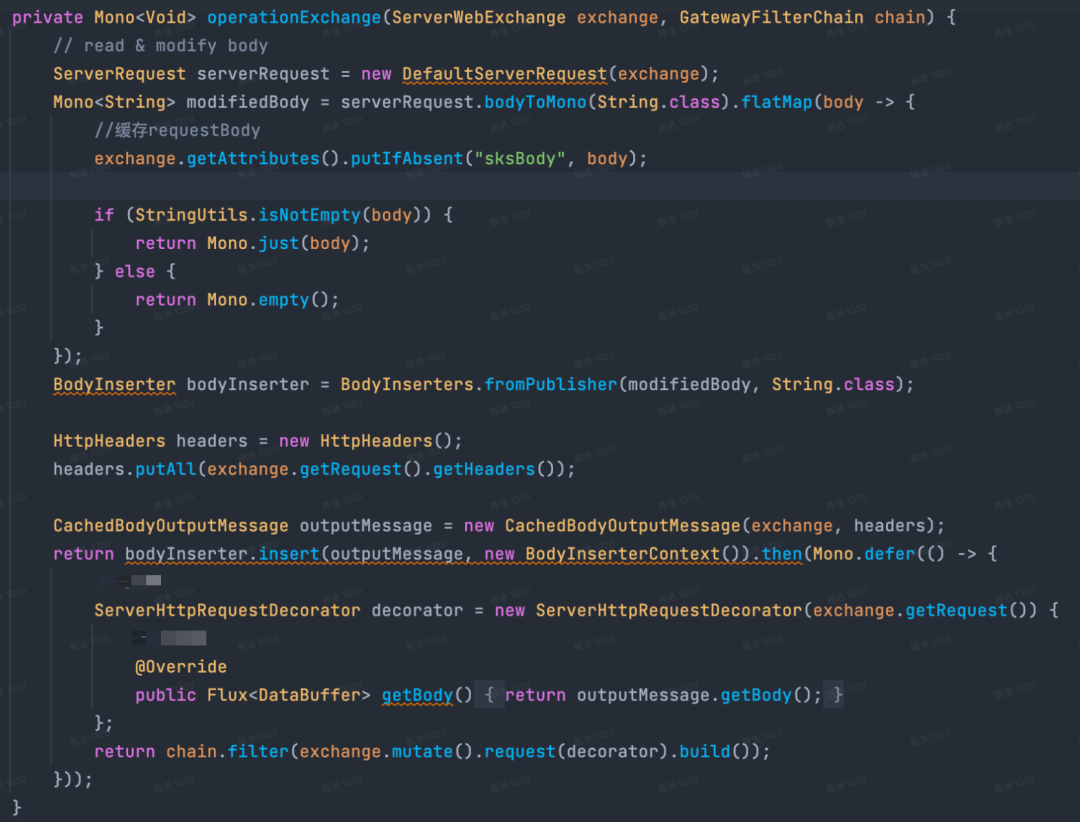
对requestBody 进行修改的方式
多层抽象的性能损耗
尽管相比于传统的阻塞式网关,SCG的性能已经足够优秀,但与原生的netty相比,SCG的性能仍然较低。这是因为SCG依赖于webflux编程范式,而webflux又是构建在reactor-netty之上的,这导致多层抽象存在较大的性能损耗。
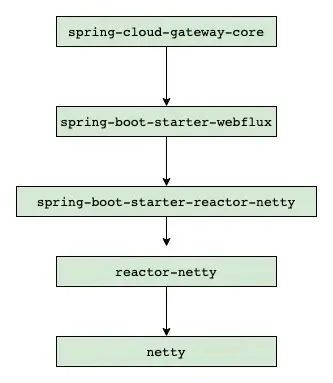
SCG依赖层级
一般认为, 程序调用栈越深性能越差;下图为只有一个filter的情况下的调用栈,可以看到存在大量的 webflux 中的 subscribe() 和onNext() 方法调用,这些方法的执行不关联任何业务逻辑,属于纯粹的框架运行层代码,粗略估算下没有引入任何逻辑的情况下,SCG的调用栈深度在 90+ ,如果引入多个filter处理不同的业务逻辑,线程栈将进一步加深,当前网关的业务复杂度实际栈深度会达到120左右,也就是差不多有四分之三的非业务栈损耗,这个比例是有点夸张的。
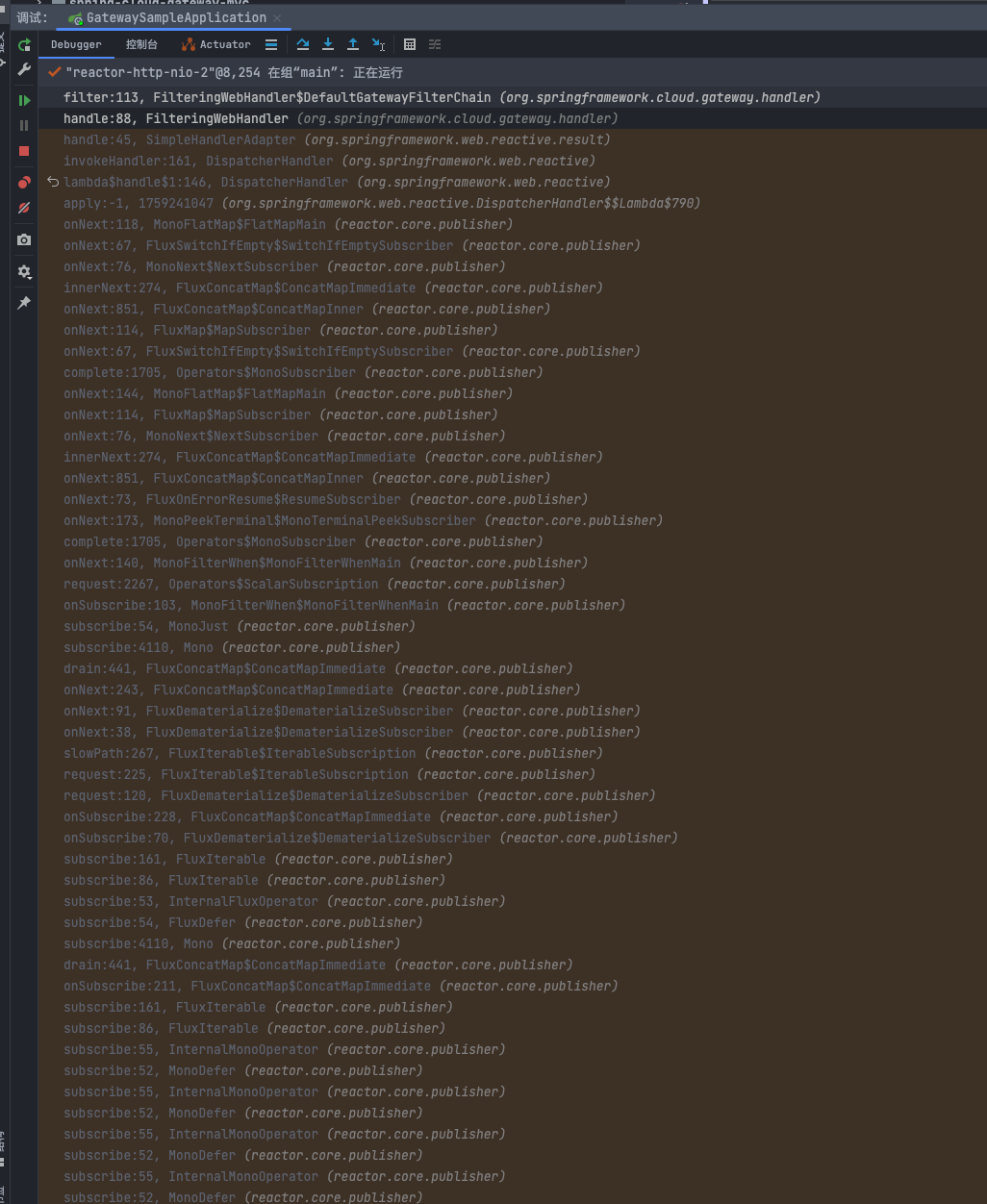
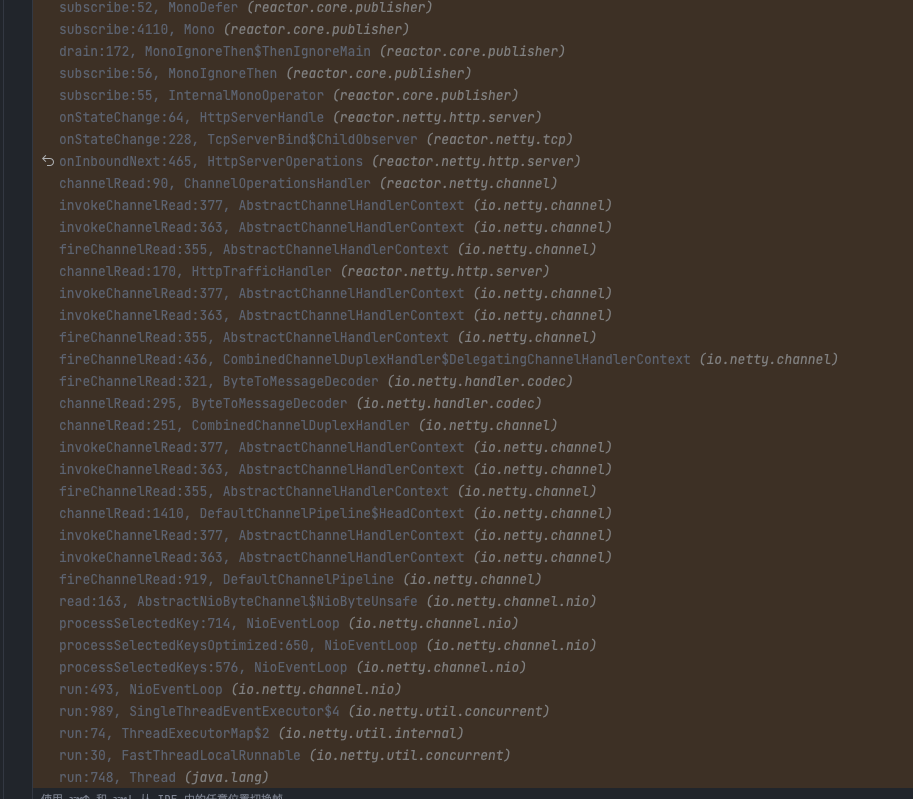
SCG filter 调用栈深度
路由能力不完善
原生的的SCG并不支持动态路由管理,经过改造后,这些配置数据一般放在诸如 Apollo 或者 ark 这样的配置中心,SCG路由的配置信息通过大量的KV配置来做,平均一个路由配置需要三到四条KV配置信息来支撑,即使是添加了新的配置SCG,并不能动态识别,需要引入动态刷新路由配置的能力。
另一方面路由匹配算法通过遍历所有的路由信息逐一匹配的模式,当接口级别的路由数量急剧膨胀时,性能是个严重问题。
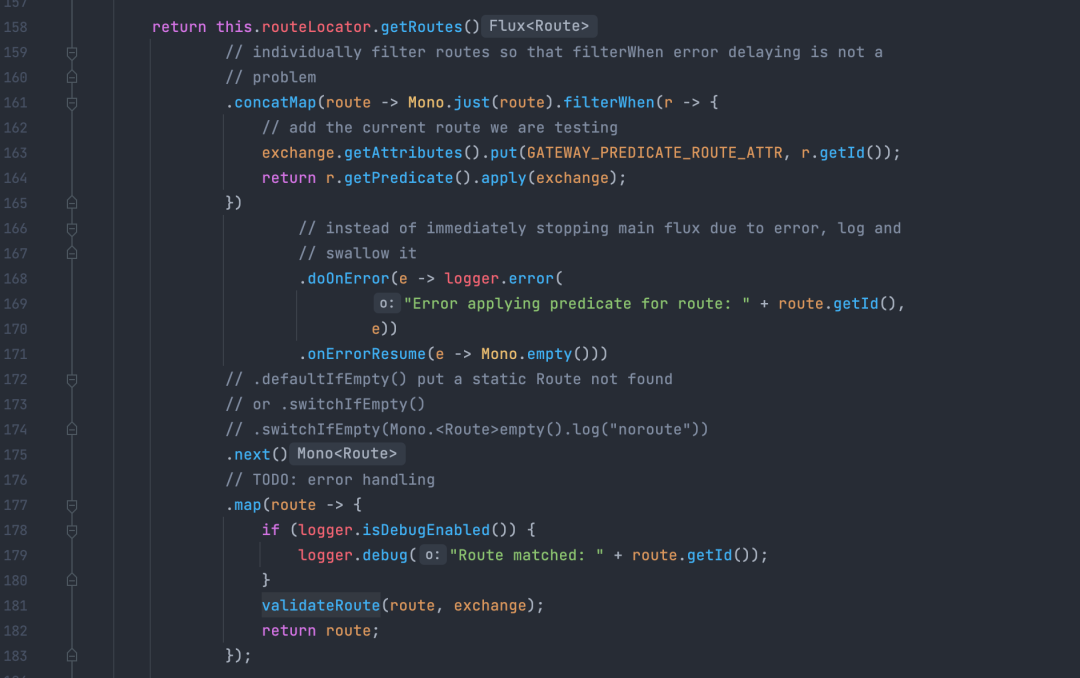
SCG路由匹配算法为On时间复杂度
预热时间长,冷启动RT尖刺大
SCG中LoadBalancerClient 会调用choose方法来选择合适的endpoint 作为本次RPC发起调用的真实地址,由于是懒加载,只有在有真实流量触发时才会加载创建相关资源;
在触发底层的NamedContextFactory#getContext 方法时存在一个全局锁导致,woker线程在该锁上大量等待。
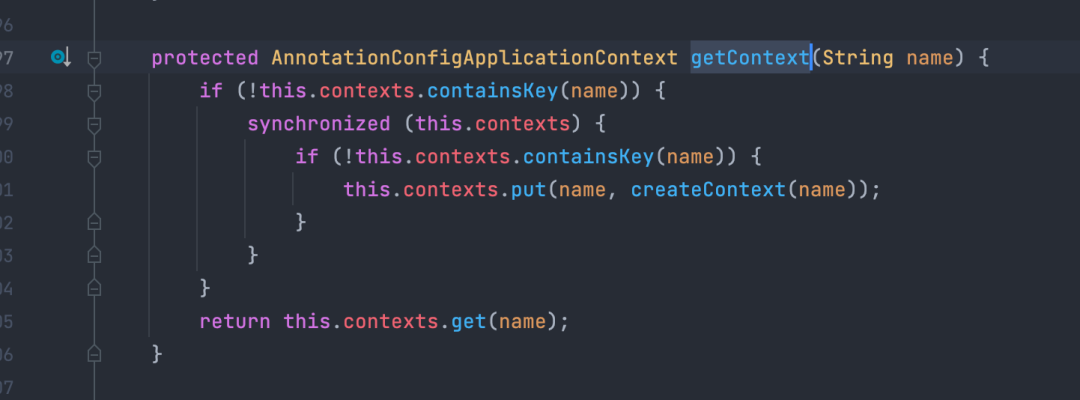
NamedContextFactory#getContext方法存在全局锁
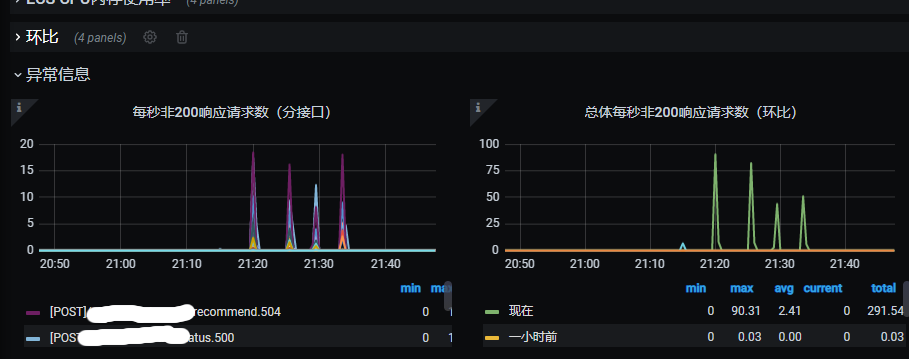
SCG发布时超时报错增多
定制性差,数据流控制耦合
在开发运维过程中,SCG已经出现了较多的针对源码改造场景,如动态路由、路由匹配性能优化等;
其设计理念老旧,控制流和数据流混合使用,架构不清晰。例如,路由管理操作仍然耦合在filter中,即使引入了spring mvc方式管理,依然绑定使用webflux编程范式,同时也无法做到控制流端口独立,存在一定安全风险。
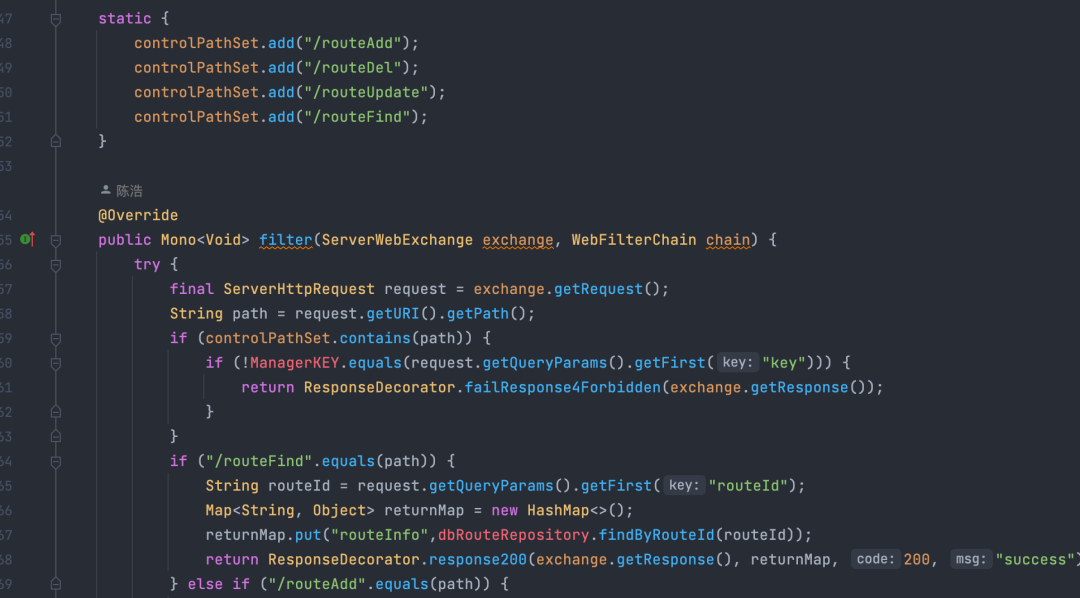
filter中对路由进行管理
SCG在技术上面临诸多挑战,包括内存泄漏、响应式编程的复杂性、多层抽象导致的性能损耗、不完善的路由能力、长的预热时间和冷启动延迟,以及差的可定制性和数据流控制耦合问题。这些问题影响了SCG的稳定性和性能,亟待解决。
三、方案调研
理想中的网关
综合业务需求和技术痛点,我们发现理想型的网关应该是这个样子的:
-
支持海量接口注册,并能够在运行时支持动态添加修改路由信息,具备出色路由匹配性能
-
编程范式尽可能简单,降低开发人员心智负担,同时最好是开发人员较为熟悉的语言
-
性能足够好,至少要等同于目前SCG的性能,RT99线和ART较低
-
稳定性好,无内存泄漏,能够长时间持续稳定运行,发布升级期间要尽可能下游无感
-
拓展能力强,自定义超时机制、多种网络协议如HTTP、Dubbo等,并拥有成熟的生态支持
-
架构设计清晰,数据流与控制流分离,集成UI控制面
开源网关对比
基于以上需求,我们对市面上的常见网关进行了调研,以下几个开源方案对比。
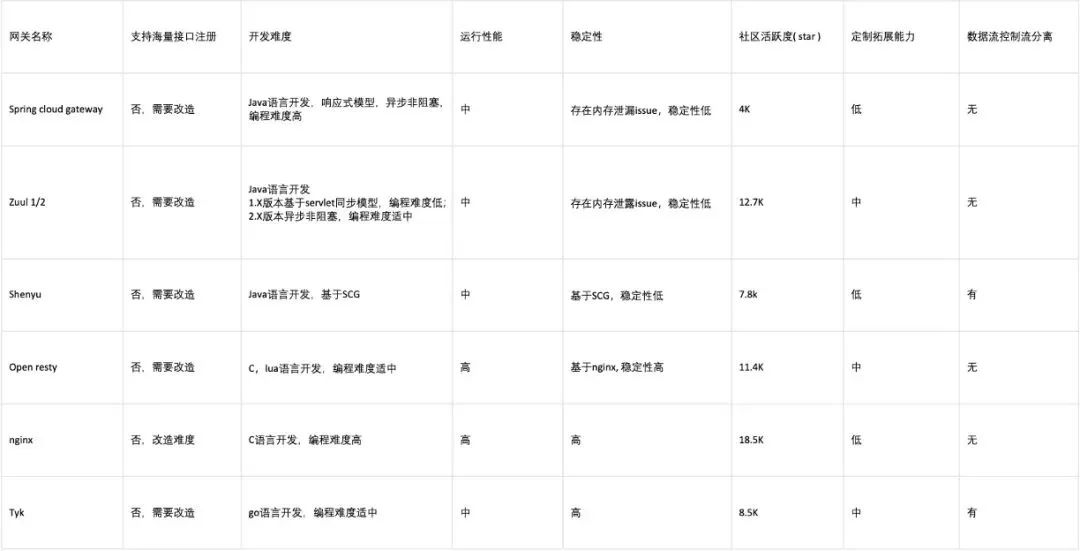
结合当前团队的技术栈,我们倾向于选择Java技术栈的开源产品,尽管zuul2是我们唯一的选择,但它在路由注册和稳定性方面仍无法满足我们的要求,且没有实现数据流与控制流的分离架构设计。
因此唯有走上自研之路。
理想的网关应当是业务和技术双赢的解决方案。它不仅需要具备强大的功能和优秀的性能,还要在稳定性和扩展性上表现出色。在现有开源方案无法完全满足需求的情况下,自研成为了我们的选择。这不仅能够让我们根据自身业务和技术需求进行定制化开发,还能够更好地掌握产品的未来发展,确保长期的适应性和领先性。自研网关的开发将是团队技术实力和创新精神的体现,也是我们对未来业务支撑能力和技术领先地位的投资。
四、自研架构
在代理网关的开发中,我们通常区分透明代理与非透明代理,两者的核心差异体现在对流量的干预程度。具体来说,透明代理不对流量内容做任何修改,而非透明代理则会对请求和响应数据进行必要的调整。
鉴于API Gateway的本质功能,它必须对流转的数据进行适度的处理,常见的调整主要有
-
请求修改: 添加或者修改head 信息,加密或者解密 query params head
-
以及 requestbody 或者responseBody 修改
-
可以说http请求的每一个部分数据都存在修改的可能性
这就要求代理层必须深入解读数据包的细节,而不仅仅是执行简单的路由转发操作。
Reactor多线程架构
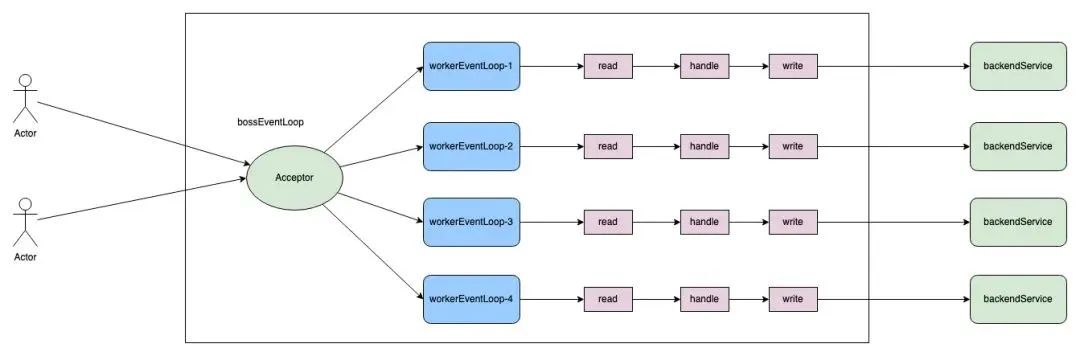
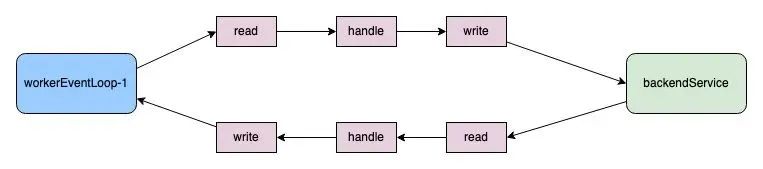
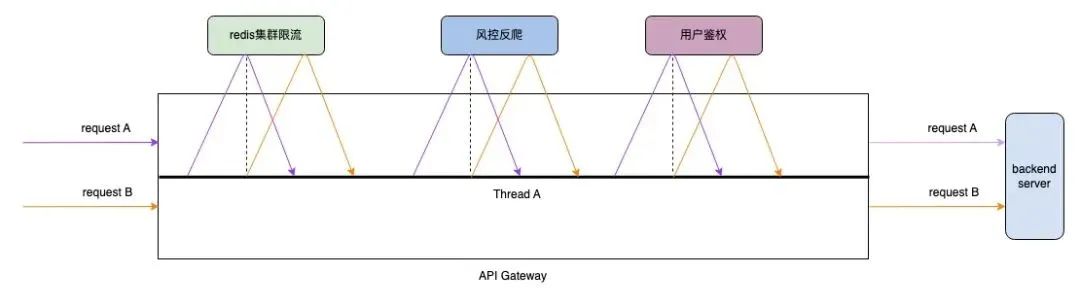
为了达到更高的性能,我们需要减少多线程环境下代码编写时可能出现的竞争问题,在处理请求的过程中,从接收请求开始,经过转发到后端服务,接收后端的响应,再到最终发送给客户端,这一连串的操作被设计成在单个的workerEventLoop线程中完整执行;
这需要worker线程中执行的IO类型操作全部实现异步非阻塞化,确保worker线程的高速运转;
这样的架构和NGINX很类似;我们称之为 request-per-thread模式 (单请求闭环)。
API网关组件架构
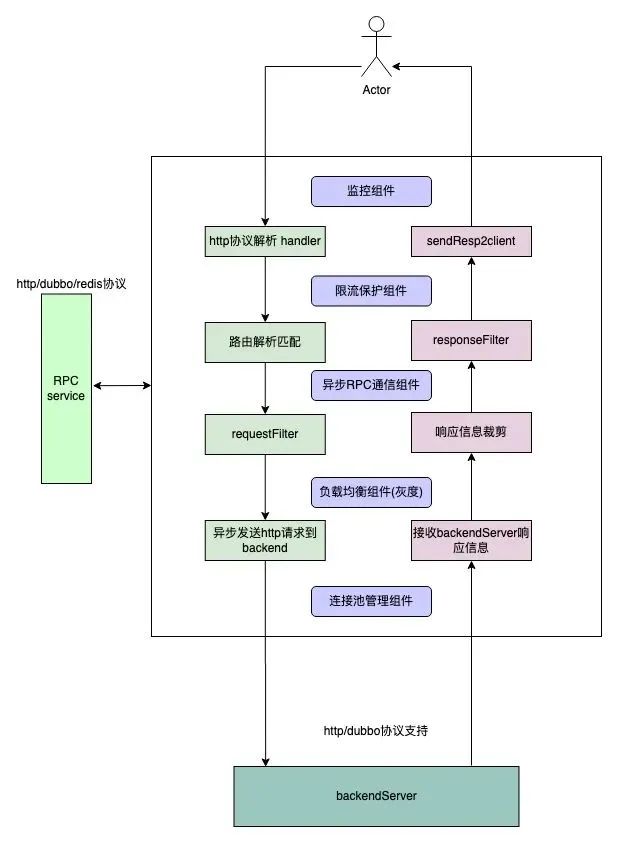
数据流控制流分离
数据面板专注于流量代理,不处理任何admin 类请求,控制流监听独立的端口,接收管理指令。
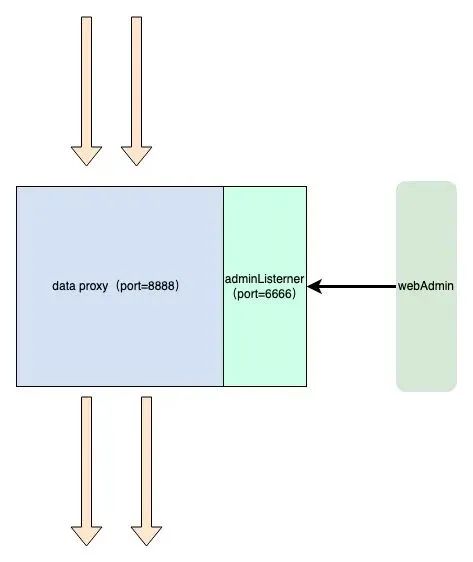
我们通过深入研究代理网关的架构,对透明与非透明代理的差异有了清晰的认识,并明确了API Gateway在数据处理上的需求。通过采用Reactor多线程模型,我们旨在减少线程竞争,提高处理性能。同时,我们将数据流与控制流分离,确保系统的高效稳定运行。这样的设计不仅满足了我们对高性能、高可靠性的需求,而且也为未来的扩展和维护奠定了坚实的基础。通过这些技术策略,我们坚信能够打造出既灵活又强大的API网关,以适应不断变化的业务需求和技术挑战。
五、核心设计
请求上下文封装
在重构API网关的底层架构时,我们保留了基于Netty的坚实基础,并利用其内置的HTTP协议解析handler,省去了繁琐的注册过程。 遵循Netty的编程范式,在初始化阶段,我们无需手动注册每个Handler,因为Netty的 pipeline 机制会自动处理这一过程。
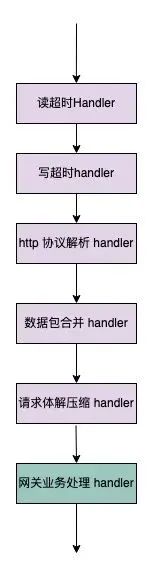
Client到Proxy链路Handler 执行顺序
HttpServerCodec 负责HTTP请求的解析;
-
对于体积较大的Http请求,客户端可能会拆成多个小的数据包进行发送,因此在服务端需要适当的封装拼接,避免收到不完整的http请求;
-
HttpObjectAggregator 负责整个请求的拼装组合。
-
拿到HTTP请求的全部信息后在业务handler 中进行处理;
-
如果请求体积过大直接抛弃;
使用ServerWebExchange 对象封装请求上下文信息,其中包含了
-
client2Proxy的channel,
-
以及负责处理该channel 的eventLoop 线程等信息,
-
引入了getAttributes 方法 用于存储需要传递的数据;考虑到整个请求的处理过程中可能在不同阶段传递一些拓展信息,
为了最小化从SCG迁移到自研网关的改动,ServerWebExchange 接口在设计上尽量保持了与SCG的一致性,具体实现类也是在此基础上进行调整的。可以参考如下代码:
@Getter
public class DefaultServerWebExchange implements ServerWebExchange {
private final Channel client2ProxyChannel;
private final Channel proxy2ClientChannel;
private final EventLoop executor;
private ServerHttpRequest request;
private ServerHttpResponse response;
private final Map<String, Object> attributes;
}
DefaultServerWebExchange
Client2ProxyHttpHandler作为核心的入口handler ,负责将接收到的FullHttpRequest 进行封装和构建ServerWebExchange 对象,其核心逻辑如下。
@Override
protected void channelRead0(ChannelHandlerContext ctx, FullHttpRequest fullHttpRequest) {
try {
Channel client2ProxyChannel = ctx.channel();
DefaultServerHttpRequest serverHttpRequest = new DefaultServerHttpRequest(fullHttpRequest, client2ProxyChannel);
ServerWebExchange serverWebExchange = new DefaultServerWebExchange(client2ProxyChannel,(EventLoop) ctx.executor(), serverHttpRequest, null);
// request filter chain
this.requestFilterChain.filter(serverWebExchange);
}catch (Throwable t){
log.error("Exception caused before filters!\n {}",ExceptionUtils.getStackTrace(t));
ByteBufHelper.safeRelease(fullHttpRequest);
throw t;
}
}
可以看到: 数据读取封装的逻辑较为简单,并没有植入常见的业务逻辑,封装完对象后随即调用 Request filter chain。
这种设计确保了请求处理的灵活性和高效性,同时也为未来的扩展奠定了基础。通过这种封装方式,我们能够确保在迁移现有业务逻辑时,所需的工作量降至最低,大大提高了开发效率和系统的稳定性。这样的设计不仅简化了开发流程,也为API网关的性能优化和功能增强提供了便利,使得整个系统能够更好地适应不断变化的技术环境和业务需求。
FilterChain设计
filter的执行需要定义先后顺序,这里参考了SCG的方案,每个filter返回一个order值。
不同的地方在于DAG的设计不允许 order值重复,因为在order重复的情况下,很难界定到底哪个Filter 先执行,存在模糊地带,这不是我们期望看到的;
DAG中的Filter 执行顺序为order值从小到大,且不允许order值重复。
为了易于理解,这里将Filter拆分为两类:requestFilter和responseFilter,分别对应于请求处理阶段和响应处理阶段;responseFilter也遵循相同的顺序执行规则和唯一性原则。
public interface GatewayFilter extends Ordered {
void filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
public interface ResponseFilter extends GatewayFilter { }
public interface RequestFilter extends GatewayFilter { }
filter接口设计
在API网关的设计中,过滤链的构建是一个关键环节。通过引入顺序值来确定过滤器的执行顺序,我们确保了请求和响应的处理能够按照预定的逻辑顺序进行。DAG的设计避免了执行顺序的模糊性,保证了过滤链的清晰和可预测性。requestFilter和responseFilter的划分,不仅使得过滤链的逻辑更加清晰,而且也便于管理和维护。这种设计思路体现了我们对系统性能和稳定性的追求,同时也为API网关未来的扩展留下了空间,使其能够更好地适应不同的业务场景和技术需求。
路由管理与匹配
以SCG网关注册的路由数量为基准,网关节点的需要支撑的路由规则数量是上万级别的,按照得物目前的业务量,上限不超过5W,为了确保高效的匹配性能,将路由规则存储在分布式缓存中并不可行,它们需要被保留在节点的内存中。
类似于在nginx中配置上万条location规则,这种手动维护的方式不仅难度巨大,即便在配置中心管理起来也是一项繁琐的任务,因此,引入一个独立的路由管理模块变得至关重要。
在匹配的效率上也需要进一步优化,SCG的路由匹配策略为轮询,时间效率为On,在路由规则膨胀到万级别后,SCG性能急剧拉胯,结合得物的接口规范,新网关采用Hash匹配模式,将匹配效率提升到O1;
hash的key为接口的path,需要强调的是在同一个网关集群中,path是唯一的,这里的path并不等价于业务服务的接口path, 绝大多数时候存在一些剪裁,例如在业务服务的编写的/order/detail接口,在网关实际注册的接口可能为/api/v1/app/order/detail;
由于使用了path作为key进行hash匹配。
常见的基于path传参数模式的接口均不支持;
因此,网关保留了类似nginx的前缀匹配支持,但这一功能不对外部开放。这种设计决策旨在确保网关能够高效地处理大量路由规则,同时简化维护工作,并保持良好的性能。通过引入独立的路由管理模块和采用Hash匹配模式,新的网关不仅提高了匹配效率,也增强了系统的可维护性和稳定性,为得物未来的业务扩展打下了坚实的基础。
public class Route implements Ordered {
private final String id;
private final int skipCount;
private final URI uri;
}
单线程闭环
为了更好地利用CPU,以及减少不必要的数据竞争,将单个请求的处理全部闭合在一个线程当中;
这意味着这个请求的业务逻辑处理,RPC调用,权限验证,限流token获取都将始终由某个固定线程处理。
netty中 网络连接被抽象为channel,channel 与eventloop线程的对应关系为 N对1,一个channel 仅能被一个eventloop 线程所处理,这在处理用户请求时没有问题,但是在接收请求完毕向下游转发请求时,我们碰到了一些挑战:
因为下游连接通常由连接池管理,而连接池的管理则由另一组eventLoop线程负责。为了维持闭环处理,我们需要将连接池的线程设置为与当前请求处理线程相同,这意味着只能有一个线程来处理这个请求;
因此,默认情况下启动的N个线程(N与机器核心数相同)将分别负责管理一个连接池;
thread-per-core 模式的性能已经在nginx开源组件上得到验证。
这种模型的核心优势在于它可以减少线程间切换带来的开销,并避免了复杂的数据竞争问题。通过将请求的处理完全局限于一个线程,我们能够确保请求的处理流程更加直接和高效。
连接管理优化
为了满足单线程闭环,需要将连接池的管理线程设置为当前的 eventloop 线程,最终我们通过threadlocal 进行线程与连接池的绑定;
在大多数场景下,netty自带的FixedChannelPool连接池能够满足我们的需求,并且它也适用于多线程环境;
由于新网关使用thread-per-core模式并将请求处理的全生命周期闭合在单个线程中,所有为了线程安全的额外操作不再必要且存在性能浪费;为此需要对原生连接池做一些优化, 连接的获取和释放简化为对链表结构的简单getFirst , addLast。
对于RPC 而言,无论是HTTP,还是Dubbo,Redis等最终底层都需要用到TCP连接,将构建在TCP连接上的数据解析协议与连接剥离后,纯粹的连接管理是可以复用的,对于连接池来说,它不需要了解具体连接的用途,只需要保持到特定endpoint的连接稳定即可。因此,即使是RPC服务的连接,也可以放入连接池中进行托管;
最终的连接池设计架构图。
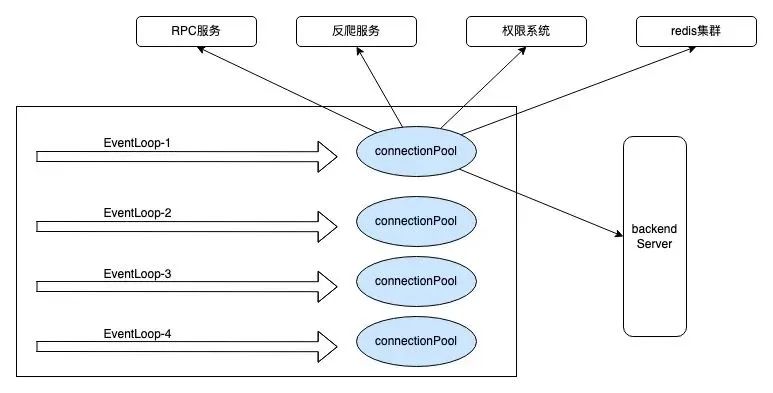
通过这些优化,API网关能够更加高效地管理连接,同时减少了资源消耗,为得物平台提供了更加稳定和高效的网络服务。这些改进不仅提高了性能,也为未来的可扩展性和维护性打下了基础。
AsyncClient设计
鉴于七层流量几乎全部基于Http请求,RPC请求中Http协议也占据了绝大多数,同时还会涉及到少量的dubbo, Redis 等协议通信的场景。
因此,有必要构建一个异步调用框架来提供支持。这个框架需要具备超时处理、回调执行、错误报告等功能,并且必须与协议无关,还需要支持链式调用以便于使用。
发起一次RPC调用通常可以分为以下几步:
-
获取目标地址和使用的协议, 目标服务为集群部署时,需要使用loadbalance模块
-
封装发送的请求,这样的请求在应用层可以具体化为某个Request类,网络层序列化为二进制数据流
-
出于性能考虑选择非阻塞式发送,发送动作完成后开始计算超时
-
接收数据响应,由于采用非阻塞模式,这里的发送线程并不会以block的方式等待数据
-
在超时时间内完成数据处理,或者触发超时导致连接取消或者关闭
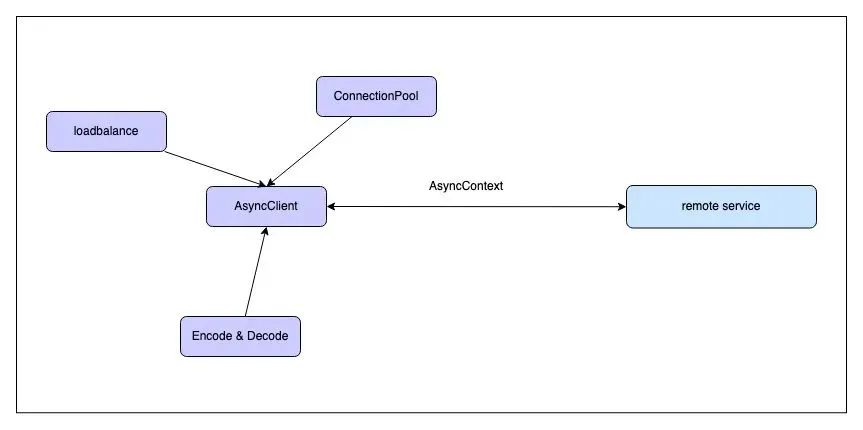
AsyncClient 模块内容并不复杂,AsyncClient为抽象类不区分使用的网络协议;
ConnectionPool 作为连接的管理者被client所引用,获取连接的key 使用 protocol+ip+port 再适合不过;
通常在某个具体的连接初始化阶段就已经确定了该channel 所使用的协议,因此初始化时会直接绑定协议Handler;当协议为HTTP请求时,HttpClientCodec 为HTTP请求的编解码handler;也可以是构建在TCP协议上的 Dubbo, Mysql ,Redis 等协议的handler。
首先对于一个请求的不同执行阶段需要引入状态定位,这里引入了 STATE 枚举:
enum STATE{
INIT,SENDING,SEND,SEND_SUCCESS,FAILED,TIMEOUT,RECEIVED
}
其次在执行过程中设计了 AsyncContext作为信息存储的载体,内部包含request和response信息,作用类似于上文提到的ServerWebExchange;channel资源从连接池中获取,使用完成后需要自动放回。
public class AsyncContext<Req, Resp> implements Cloneable{
STATE state = STATE.INIT;
final Channel usedChannel;
final ChannelPool usedChannelPool;
final EventExecutor executor;
final AsyncClient<Req, Resp> agent;
Req request;
Resp response;
ResponseCallback<Resp> responseCallback;
ExceptionCallback exceptionCallback;
int timeout;
long deadline;
long sendTimestamp;
Promise<Resp> responsePromise;
}
AsyncContext
AsyncClient 封装了基本的网络通信能力,不拘泥于某个固定的协议,可以是Redis, http,Dubbo 等。
当将数据写出去之后,该channel的非阻塞调用立即结束,在没有收到响应之前无法对AsyncContext 封装的数据做进一步处理,如何在收到数据时将接收到的响应和之前的请求管理起来这是需要面对的问题,channel 对象 的attr 方法可以用于临时绑定一些信息,以便于上下文切换时传递数据,可以在发送数据时将AsyncContext对象绑定到该channel的某个固定key上。
当channel收到响应信息时,在相关的 AsyncClientHandler 里面取出AsyncContext。
public abstract class AsyncClient<Req, Resp> implements Client {
private static final int defaultTimeout = 5000;
private final boolean doTryAgain = false;
private final ChannelPoolManager channelPoolManager = ChannelPoolManager.getChannelPoolManager();
protected static AttributeKey<AsyncRequest> ASYNC_REQUEST_KEY = AttributeKey.valueOf("ASYNC_REQUEST");
public abstract ApplicationProtocol getProtocol();
public AsyncContext<Req, Resp> newRequest(EventExecutor executor, String endpoint, Req request) {
final ChannelPoolKey poolKey = genPoolKey(endpoint);
ChannelPool usedChannelPool = channelPoolManager.acquireChannelPool(executor, poolKey);
return new AsyncContext<>(this,executor,usedChannelPool,request, defaultTimeout, executor.newPromise());
}
public void submitSend(AsyncContext<Req, Resp> asyncContext){
asyncContext.state = AsyncContext.STATE.SENDING;
asyncContext.deadline = asyncContext.timeout + System.currentTimeMillis();
ReferenceCountUtil.retain(asyncContext.request);
Future<Resp> responseFuture = trySend(asyncContext);
responseFuture.addListener((GenericFutureListener<Future<Resp>>) future -> {
if(future.isSuccess()){
ReferenceCountUtil.release(asyncContext.request);
Resp response = future.getNow();
asyncContext.responseCallback.callback(response);
}
});
}
/**
* 尝试从连接池中获取连接并发送请求,若失败返回错误
*/
private Promise<Resp> trySend(AsyncContext<Req, Resp> asyncContext){
Future<Channel> acquireFuture = asyncContext.usedChannelPool.acquire();
asyncContext.responsePromise = asyncContext.executor.newPromise();
acquireFuture.addListener(new GenericFutureListener<Future<Channel>>() {
@Override
public void operationComplete(Future<Channel> channelFuture) throws Exception {
sendNow(asyncContext,channelFuture);
}
});
return asyncContext.responsePromise;
}
private void sendNow(AsyncContext<Req, Resp> asyncContext, Future<Channel> acquireFuture){
boolean released = false;
try {
if (acquireFuture.isSuccess()) {
NioSocketChannel channel = (NioSocketChannel) acquireFuture.getNow();
released = true;
assert channel.attr(ASYNC_REQUEST_KEY).get() == null;
asyncContext.usedChannel = channel;
asyncContext.state = AsyncContext.STATE.SEND;
asyncContext.sendTimestamp = System.currentTimeMillis();
channel.attr(ASYNC_REQUEST_KEY).set(asyncContext);
ChannelFuture writeFuture = channel.writeAndFlush(asyncContext.request);
channel.eventLoop().schedule(()-> doTimeout(asyncContext), asyncContext.timeout, TimeUnit.MILLISECONDS);
} else {
asyncContext.responsePromise.setFailure(acquireFuture.cause());
}
} catch (Exception e){
throw new Error("Unexpected Exception.............!");
}finally {
if(!released) {
ReferenceCountUtil.safeRelease(asyncContext.request);
}
}
}
}
AsyncClient核心源码
public class AsyncClientHandler extends SimpleChannelInboundHandler {
@Override
protected void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception {
AsyncContext asyncContext = ctx.attr(AsyncClient.ASYNC_REQUEST_KEY).get();
try {
asyncContext.state = AsyncContext.STATE.RECEIVED;
asyncContext.releaseChannel();
asyncContext.responsePromise.setSuccess(msg);
}catch (Throwable t){
log.error("Exception raised when set Success callback. Exception \n: {}", ExceptionUtils.getFullStackTrace(t));
ByteBufHelper.safeRelease(msg);
throw t;
}
}
}
AsyncClientHandler
通过上面几个类的封装得到了一个易用使用的 AsyncClient,下面的代码为调用权限系统的案例:
final FullHttpRequest httpRequest = HttpRequestUtil.getDefaultFullHttpRequest(newAuthReq, serviceInstance, "/auth/newCheckSls");
asyncClient.newRequest(exchange.getExecutor(), endPoint,httpRequest)
.timeout(timeout)
.onComplete(response -> {
String checkResultJson = response.content().toString(CharsetUtil.UTF_8);
response.release();
NewAuthResult result = Jsons.parse(checkResultJson,NewAuthResult.class);
TokenResult tokenResult = this.buildTokenResult(result);
String body = exchange.getAttribute(DAGApplicationConfig.REQUEST_BODY);
if (tokenResult.getUserInfoResp() != null) {
UserInfoResp userInfo = tokenResult.getUserInfoResp();
headers.set("userid", userInfo.getUserid() == null ? "" : String.valueOf(userInfo.getUserid()));
headers.set("username", StringUtils.isEmpty(userInfo.getUsername()) ? "" : userInfo.getUsername());
headers.set("name", StringUtils.isEmpty(userInfo.getName()) ? "" : userInfo.getName());
chain.filter(exchange);
} else {
log.error("{},heads: {},response: {}", path, headers, tokenResult);
int code = tokenResult.getCode() != null ? tokenResult.getCode().intValue() : ResultCode.UNAUTHO.code;
ResponseDecorator.failResponse(exchange, code, tokenResult.getMsg());
}
})
.onError(throwable -> {
log.error("Request service {},occur an exception {}",endPoint, throwable);
ResponseDecorator.failResponseWithStatus(exchange,HttpResponseStatus.INTERNAL_SERVER_ERROR,"AuthFilter 验证失败");
})
.sendRequest();
asyncClient的使用
通过AsyncContext的管理,异步客户端能够在接收到响应时有效地处理请求和响应之间的关系。这种设计不仅提高了网络通信的效率,也增强了系统的可扩展性和灵活性,为得物平台的网络通信提供了强大的支持。
请求超时管理
一个请求的处理时间不能无限期拉长, 超过某个阈值的情况下App的页面会被取消 ,长时间的加载卡顿不如快速报错带来的体验良好;
因此,网关必须对接口调用实施超时管理,特别是在向后端服务发起调用的过程中。通常,我们会设定一个默认的超时阈值,比如3秒。若超过此阈值,网关将向客户端返回超时失败的信息。考虑到网关下游服务多样性,包括对响应时间敏感的C端业务、逻辑复杂的B端服务接口,以及涉及大量计算的监控接口,不同接口对超时时间的需求各不相同。因此,应为每个接口单独设置超时时间,而非采用单一的配置值。
asyncClient.newRequest(exchange.getExecutor(), endPoint,httpRequest)
.timeout(timeout)
.onComplete(response -> {
String checkResultJson = response.content().toString(CharsetUtil.UTF_8);
//..........
})
.onError(throwable -> {
log.error("Request service {},occur an exception {}",endPoint, throwable);
ResponseDecorator.failResponseWithStatus(exchange,HttpResponseStatus.INTERNAL_SERVER_ERROR,"AuthFilter 验证失败");
})
.sendRequest();
asyncClient 的链式调用设计了 timeout方法,用于传递超时时间,我们可以通过一个全局Map来配置这样的信息。
Map<String,Integer> 其key为全路径的path 信息,V为设定的超时时间,单位为ms, 至于Map的信息在实际配置过程中如何承载,使用ARK配置或者Mysql 都很容易实现。
处于并发安全和性能的极致追求,超时事件的设定和调度最好能够在与当前channel绑定的线程中执行,庆幸的是 EventLoop线程自带schedule 方法。具体来看上文的 AsyncClient 的56行。
schedule 方法内部以堆结构的方式实现了对超时时间进行管理,整体性能尚可。
通过使用异步客户端的链式调用和全局映射表,可以方便地管理接口超时时间。同时,为了保证并发安全和性能,超时事件的处理应当在EventLoop线程中进行。这种设计不仅提高了系统的响应速度,也增强了用户体验,确保了得物平台在处理网络请求时的稳定性和效率。
堆外内存管理优化
常见的堆外内存手动管理方式,是引用计数,堆外内存在回收的时候条件只有一个,就是RC值为0 ,释放的时候对 RC (引用计数) 的值做调整,然而,随着业务复杂性的增加,在处理业务的某个环节后,已经不记得当前的引用计数值是多少了,甚至是前面的RC增加了,后面的RC忘记减少了;
我们引入一个safeRelase的思路 , 在数据回写给客户端后,把这个请求整个生命周期所申请的堆外内存全部释放掉,也就是在最终的release的时候,如果当前的RC>0 就不停的 release ,直至为0;
public static void safeRelease(Object msg){
if(msg instanceof ReferenceCounted){
ReferenceCounted ref = (ReferenceCounted) msg;
int refCount = ref.refCnt();
for(int i=0; i<refCount; i++){
ref.release();
}
}
}
因此只要把这样的逻辑放在netty的最后一个Handler中即可保证内存得到有效释放。
传统的引用计数法在业务复杂时可能会出现问题,因此我们提出了在数据回写后一次性释放整个生命周期堆外内存的策略。通过在Netty的最终处理器中实现这一逻辑,可以确保堆外内存被有效管理,避免了内存泄漏的风险,提高了系统的稳定性和可靠性。
集群限流改造优化
首先来看DAG 启动后sentinel相关线程,类似的问题,线程数量非常多,需要针对性优化。
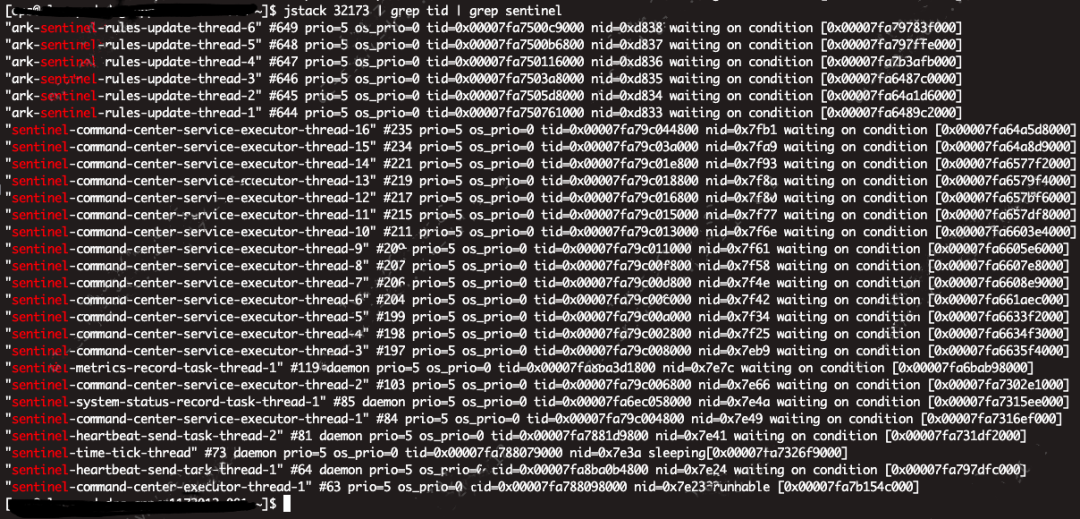
Sentinel 线程数
sentinel线程分析优化:
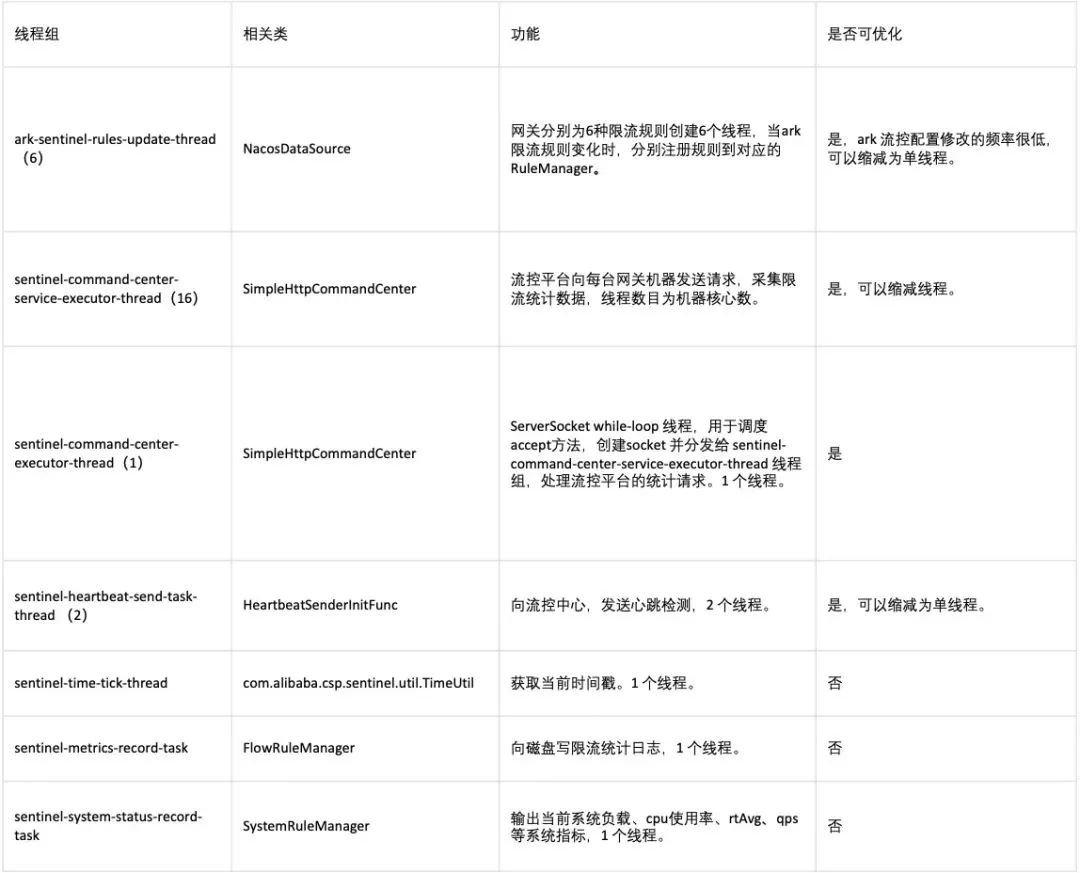

最终优化后的线程数量为4个
sentinel原生限流源码分析如下,进一步分析SphU#entry方法发现其底调用 FlowRuleCheck#passClusterCheck;
在passClusterCheck方法中发现底层网络IO调用为阻塞式, 由于该方法的执行线程为workerEventLoop,因此需要使用上文提到的AsyncClient 进行优化。
private void doSentinelFlowControl(ServerWebExchange exchange, GatewayFilterChain chain, String resource){
Entry urlEntry = null;
try {
if (!StringUtil.isEmpty(resource)) {
//1. 检测是否限流
urlEntry = SphU.entry(resource, ResourceTypeConstants.COMMON_WEB, EntryType.IN);
}
//2. 通过,走业务逻辑
chain.filter(exchange);
} catch (BlockException e) {
//3. 拦截,直接返回503
ResponseDecorator.failResponseWithStatus(exchange, HttpResponseStatus.SERVICE_UNAVAILABLE, ResultCode.SERVICE_UNAVAILABLE.message);
} catch (RuntimeException e2) {
Tracer.traceEntry(e2, urlEntry);
log.error(ExceptionUtils.getFullStackTrace(e2));
ResponseDecorator.failResponseWithStatus(exchange, HttpResponseStatus.INTERNAL_SERVER_ERROR,HttpResponseStatus.INTERNAL_SERVER_ERROR.reasonPhrase());
} finally {
if (urlEntry != null) {
urlEntry.exit();
}
ContextUtil.exit();
}
}
SentinelGatewayFilter(sentinel 适配SCG的逻辑)
public class RedisTokenService implements InitializingBean {
private final RedisAsyncClient client = new RedisAsyncClient();
private final RedisChannelPoolKey connectionKey;
public RedisTokenService(String host, int port, String password, int database, boolean ssl){
connectionKey = new RedisChannelPoolKey(String host, int port, String password, int database, boolean ssl);
}
//请求token
public Future<TokenResult> asyncRequestToken(ClusterFlowRule rule){
....
sendMessage(redisReqMsg,this.connectionKey)
}
private Future<TokenResult> sendMessage(RedisMessage requestMessage, EventExecutor executor, RedisChannelPoolKey poolKey){
AsyncRequest<RedisMessage,RedisMessage> request = client.newRequest(executor, poolKey,requestMessage);
DefaultPromise<TokenResult> tokenResultFuture = new DefaultPromise<>(request.getExecutor());
request.timeout(timeout)
.onComplete(response -> {
...
tokenResultFuture.setSuccess(response);
})
.onError(throwable -> {
...
tokenResultFuture.setFailure(throwable);
}).sendRequest();
return tokenResultFuture;
}
}
RedisTokenService
最终的限流Filter代码如下:
public class SentinelGatewayFilter implements RequestFilter {
@Resource
RedisTokenService tokenService;
@Override
public void filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//当前为 netty NioEventloop 线程
ServerHttpRequest request = exchange.getRequest();
String resource = request.getPath() != null ? request.getPath() : "";
//判断是否有集群限流规则
ClusterFlowRule rule = ClusterFlowManager.getClusterFlowRule(resource);
if (rule != null) {
//异步非阻塞请求token
tokenService.asyncRequestToken(rule,exchange.getExecutor())
.addListener(future -> {
TokenResult tokenResult;
if (future.isSuccess()) {
tokenResult = (TokenResult) future.getNow();
} else {
tokenResult = RedisTokenService.FAIL;
}
if(tokenResult == RedisTokenService.FAIL || tokenResult == RedisTokenService.ERROR){
log.error("Request cluster token failed, will back to local flowRule check");
}
ClusterFlowManager.setTokenResult(rule.getRuleId(), tokenResult);
doSentinelFlowControl(exchange, chain, resource);
});
} else {
doSentinelFlowControl(exchange, chain, resource);
}
}
}
改造后适配DAG的SentinelGatewayFilter
六、压测性能
DAG高压表现
wrk -t32 -c1000 -d60s -s param-delay1ms.lua --latency http://a.b.c.d:xxxxx
DAG网关的QPS、实时RT、错误率、CPU、内存监控图;
在CPU占用80% 情况下,能够支撑的QPS在4.5W。
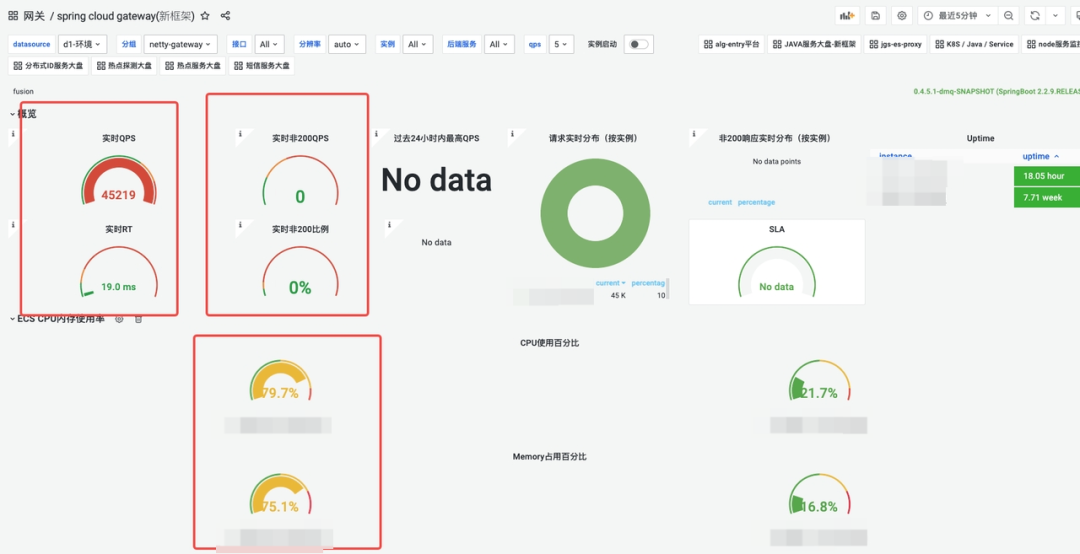
DAG网关的QPS、RT 折线图
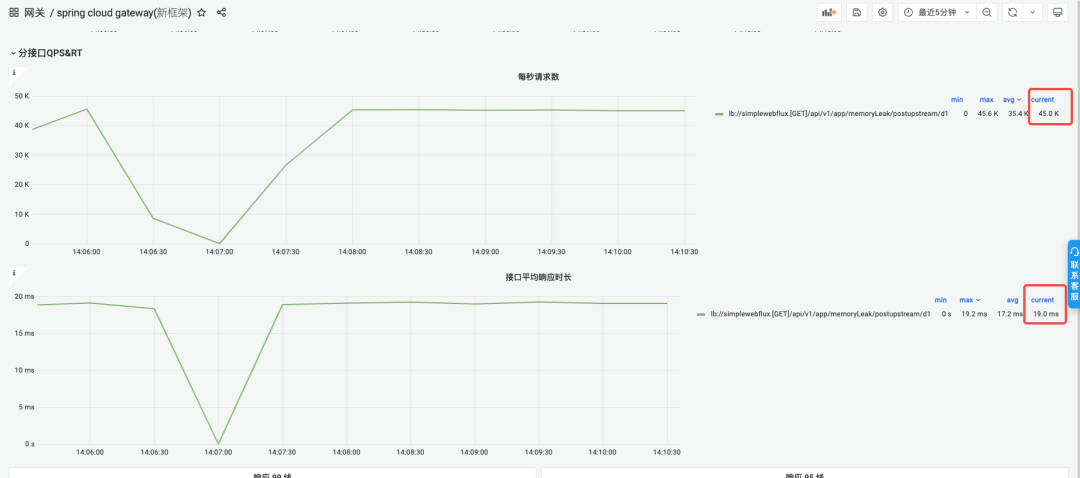
DAG在CPU占用80% 情况下,能够支撑的QPS在4.5W,ART 19ms
SCG高压表现
wrk -t32 -c1000 -d60s -s param-delay1ms.lua --latency http://a.b.c.d:xxxxx
SCG网关的QPS、实时RT、错误率、CPU、内存监控图:
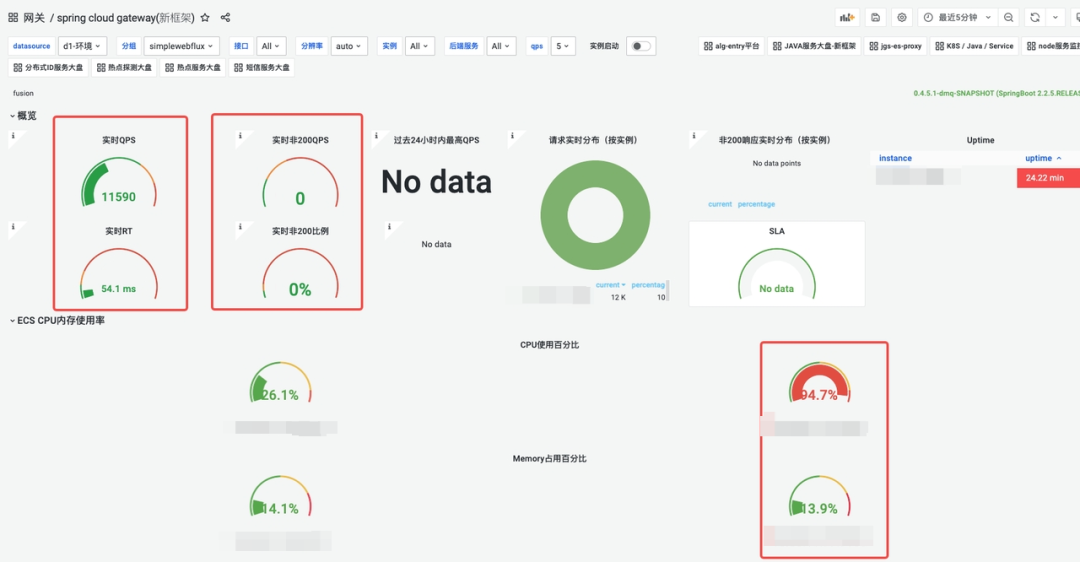
SCG网关的QPS、RT 折线图:
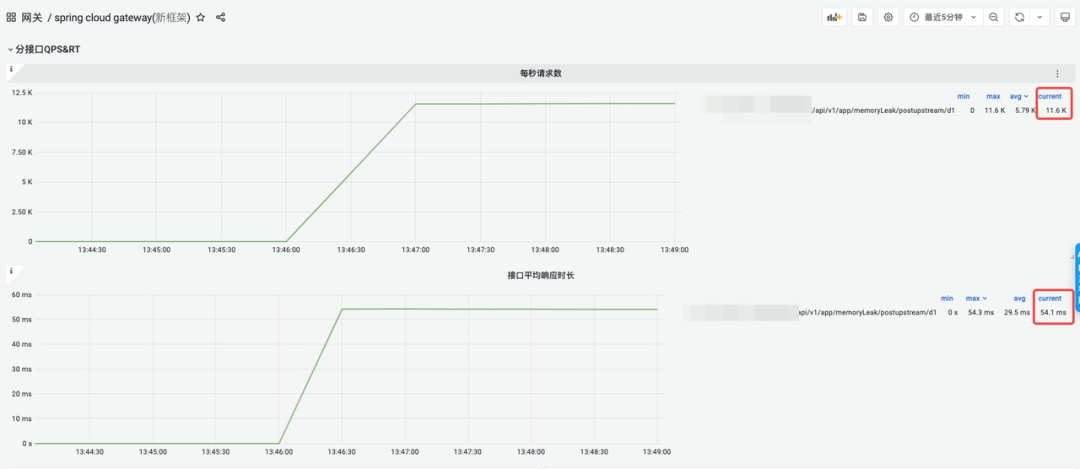
SCG在CPU占用95% 情况下,能够支撑的QPS在1.1W,ART 54.1ms
DAG低压表现
wrk -t5 -c20 -d120s -s param-delay1ms.lua --latency http://a.b.c.d:xxxxx
DAG网关的QPS、实时RT、错误率、CPU、内存:
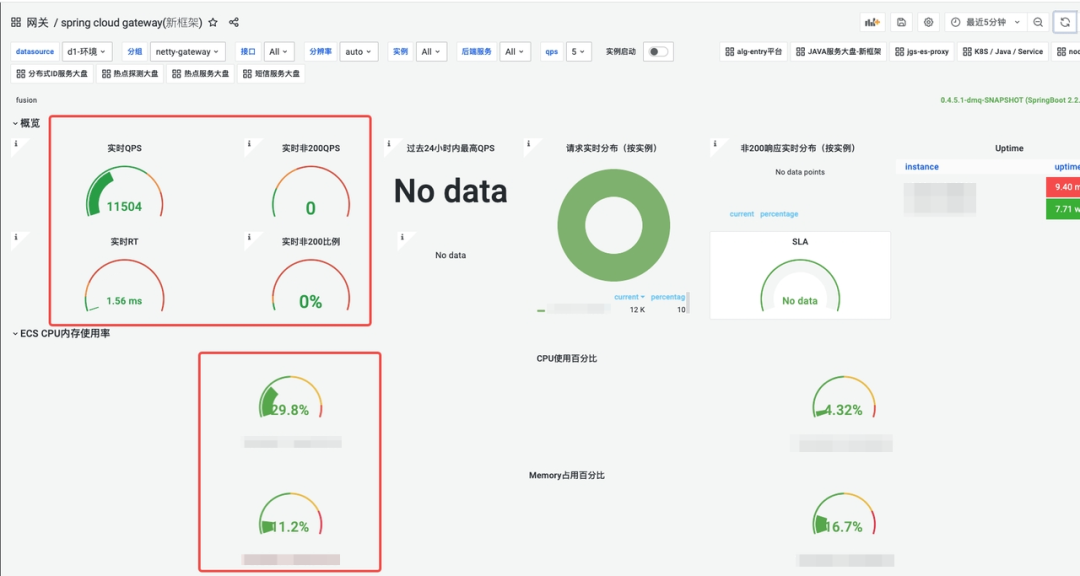
DAG网关的QPS、RT 折线图:
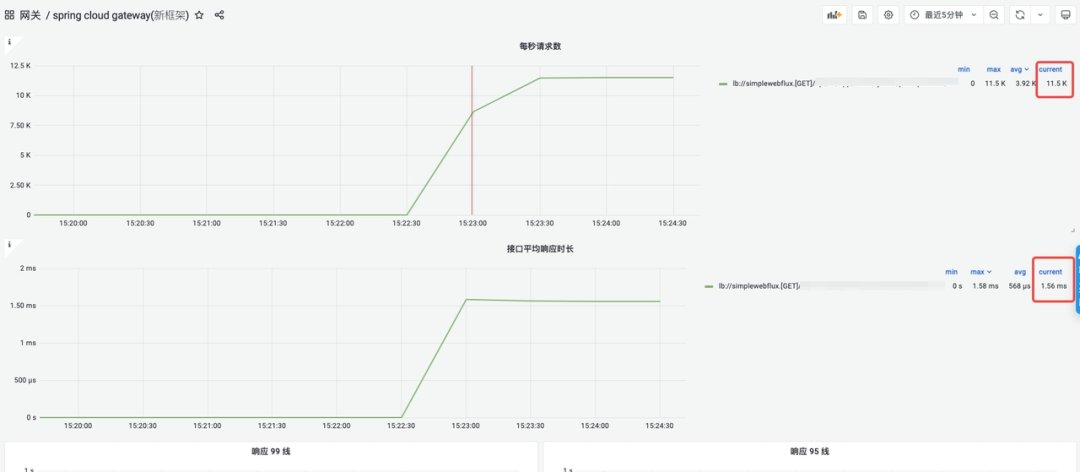
DAG在QPS 1.1W情况下,CPU占用30%,ART 1.56ms
数据对比
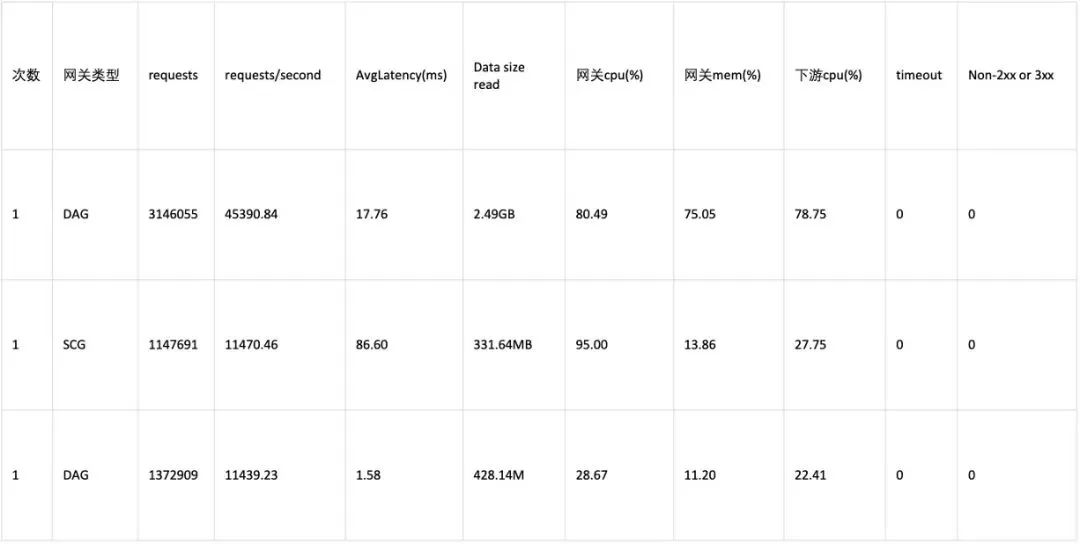
DAG和SCG的对比结论
满负载情况下,DAG要比SCG的吞吐量高很多,QPS几乎是4倍,RT反而消耗更低,SCG在CPU被打满后,RT表现出现严重性能劣化。
DAG的吞吐控制和SCG一样情况下,CPU和RT损耗下降了更多。
DAG在最大压力下,内存消耗比较高,达到了75%左右,不过到峰值后,就不再会有大幅变动了。对比压测结果,结论令人欣喜,++SCG作为Java生态当前使用最广泛的网关,其性能属于一线水准,DAG的性能达到其4倍以上也是远超意料。
七、投产收益
安全性提升
完善的接口级路由管理
基于接口注册模式的全新路由上线,包含了接口注册的申请人,申请时间,接口场景备注信息等,接口管理更加严谨规范;
结合路由组功能可以方便的查询当前服务的所有对外接口信息,某种程度上具备一定的API查询管理能力;同时为了缓解用户需要检索的接口太多的尴尬,引入了一键收藏功能,大部分时候用户只需要切换到已关注列表即可。
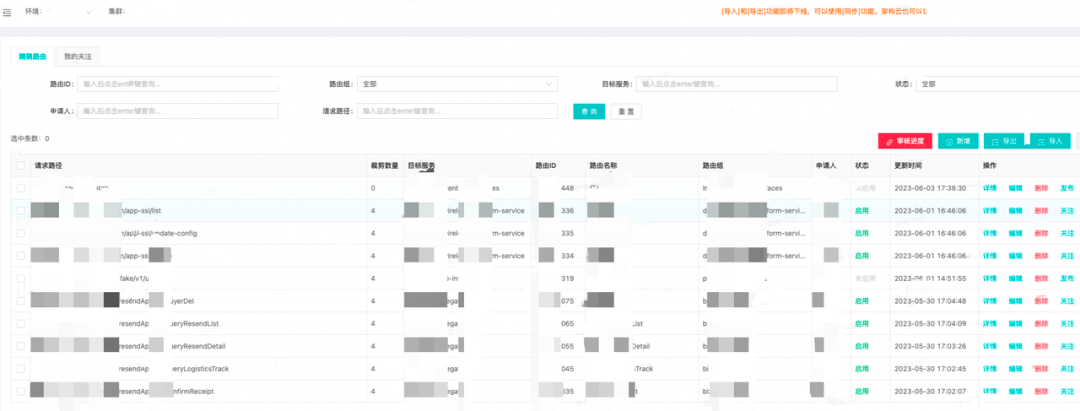
注册接口列表
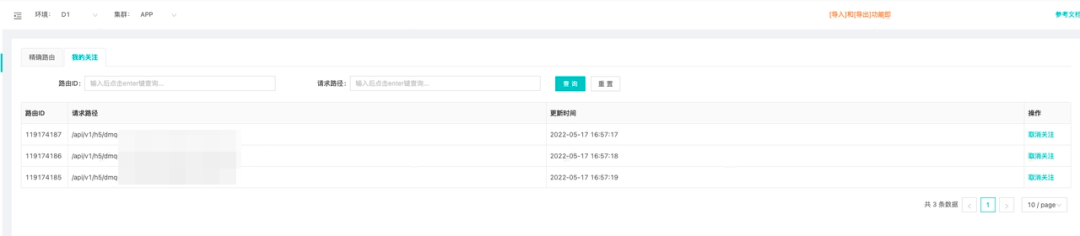
接口收藏
防渗透能力极大增强
早期的泛化路由,给黑产的渗透带来了极大的想象空间和安全隐患,甚至可以在外网直接访问某些业务的配置信息。

黑产接口渗透
接口注册模式启用后,所有未注册的接口均无法访问,防渗透能力提升一个台阶,同时自动推送异常接口访问信息。
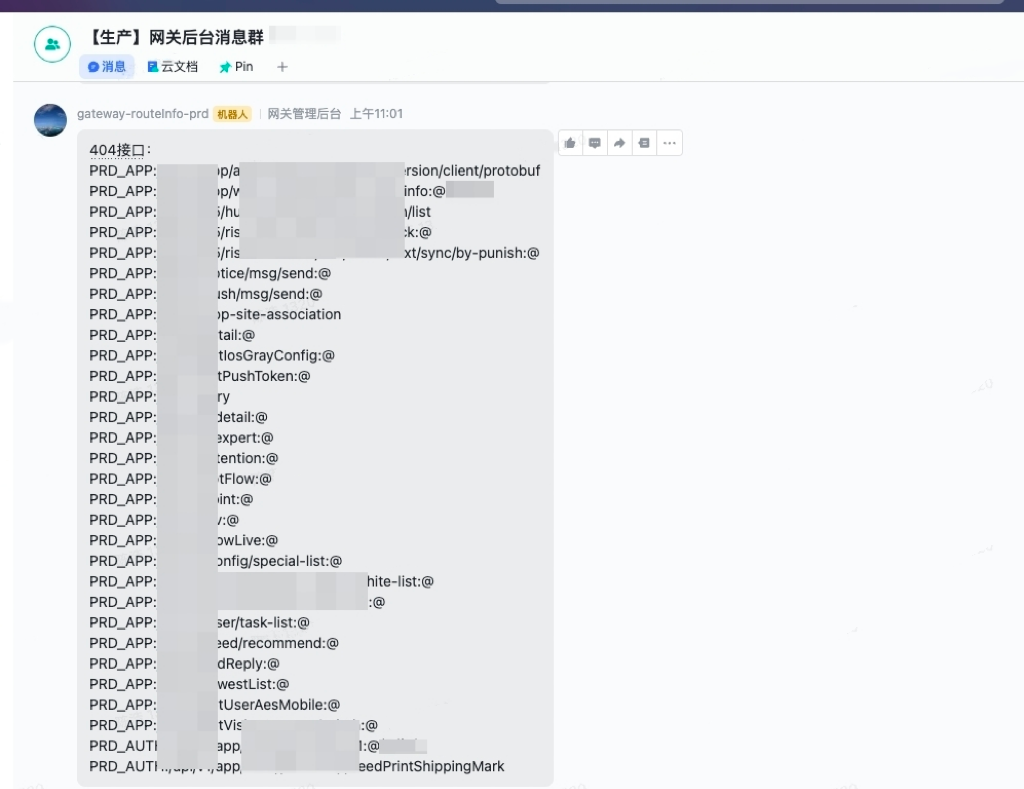
404接口访问异常推送
稳定性增强
内存泄漏问题解决
通过一系列手段改进优化和严格的测试,新网关的内存使用更加稳健,内存增长曲线直接拉平,彻底解决了泄漏问题。
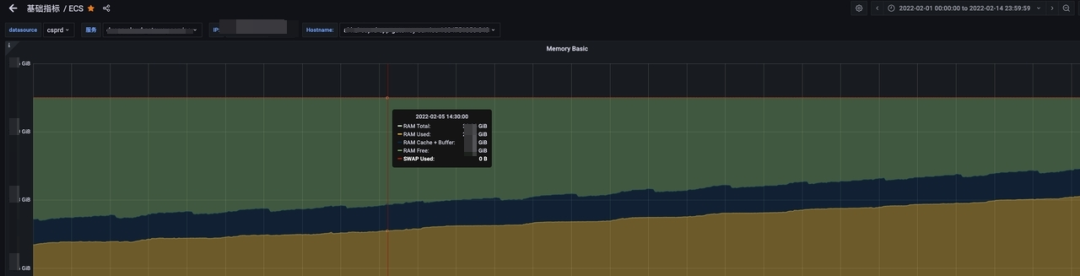
老网关内存增长趋势
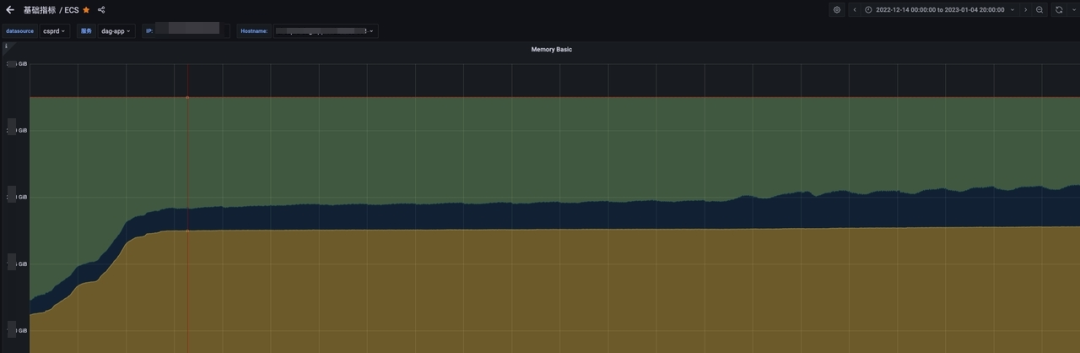
新网关内存增长趋势
降本增效
资源占用下降50% +
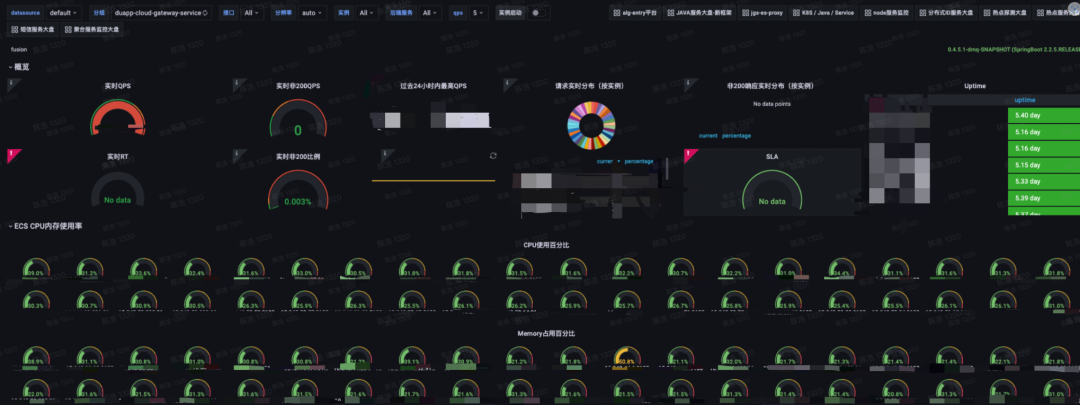
SCG平均CPU占用
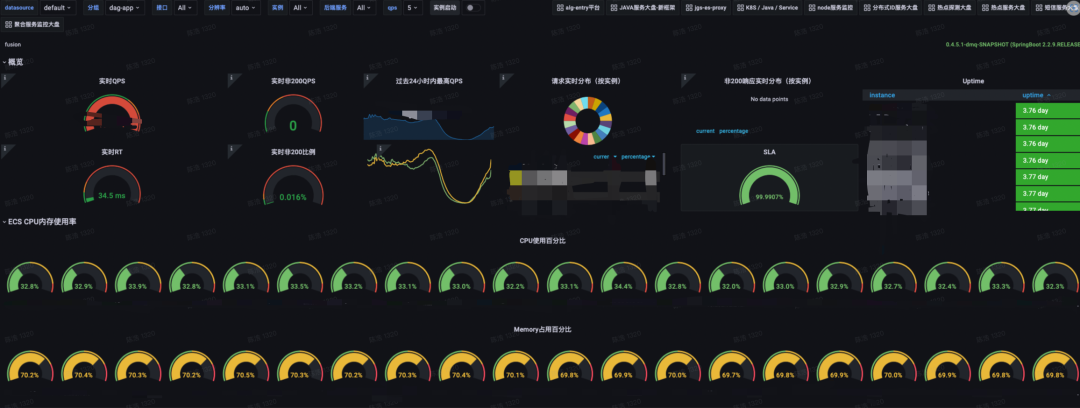
DAG资源占用
得益于ZGC的优秀算法,JVM17 在GC暂停时间上取得了出色的成果,网关作为延迟敏感型应用对GC的暂停时间尤为看重,为此我们组织升级了JDK17 版本;下面为同等流量压力情况下的配置不同GC的效果对比,++可以看到GC的暂停时间从平均70ms 降低到1ms 内,RT99线得到大幅度提升;吞吐量不再受流量波动而大幅度变化,性能表现更加稳定;同时网关的平均响应时间损耗降低5%。
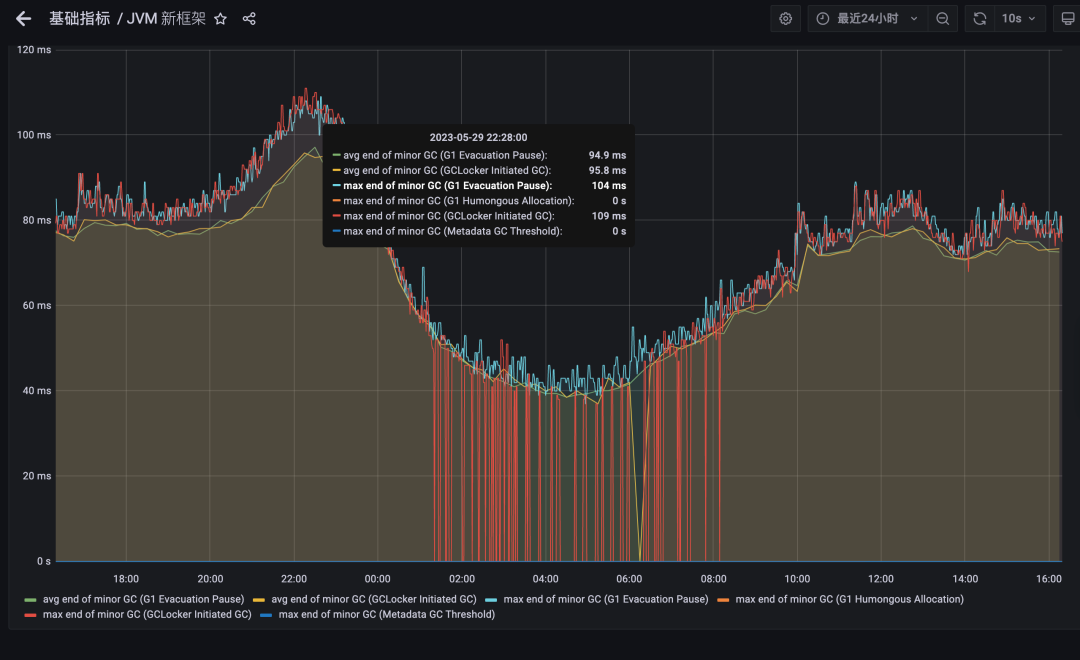
JDK8-G1 暂停时间表现
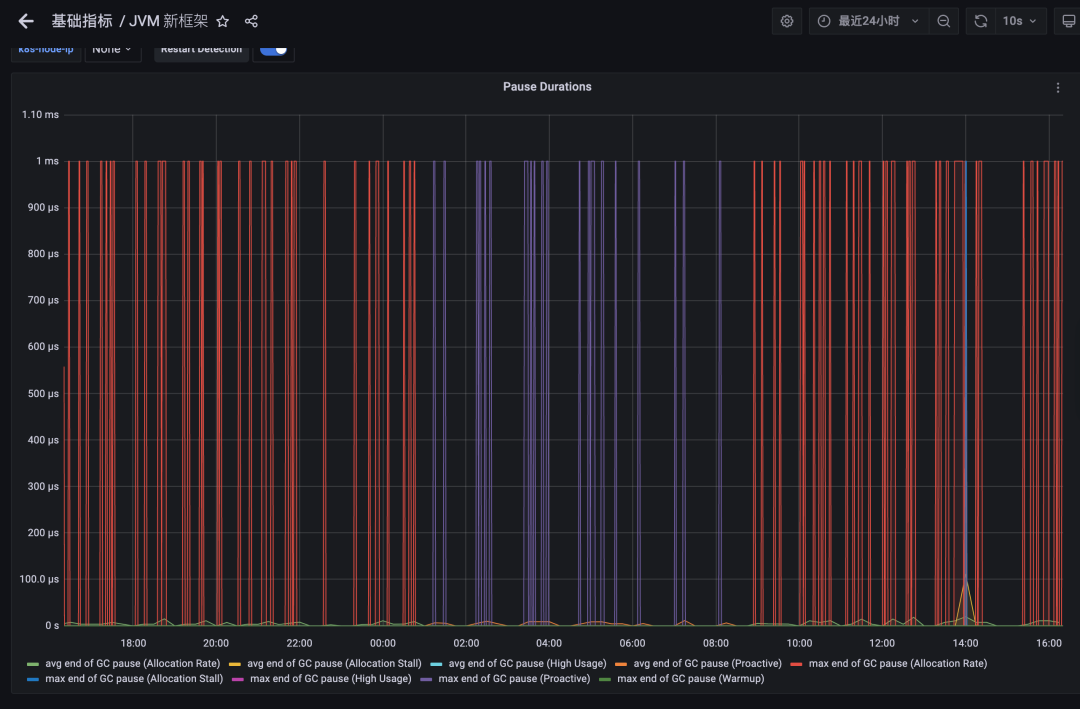
JDK17-ZGC暂停时间表现
吞吐量方面,G1伴随流量的变化呈现出一定的波动趋势,均线在99.3%左右。ZGC的吞吐量则比较稳定,维持在无限接近100%的水平。
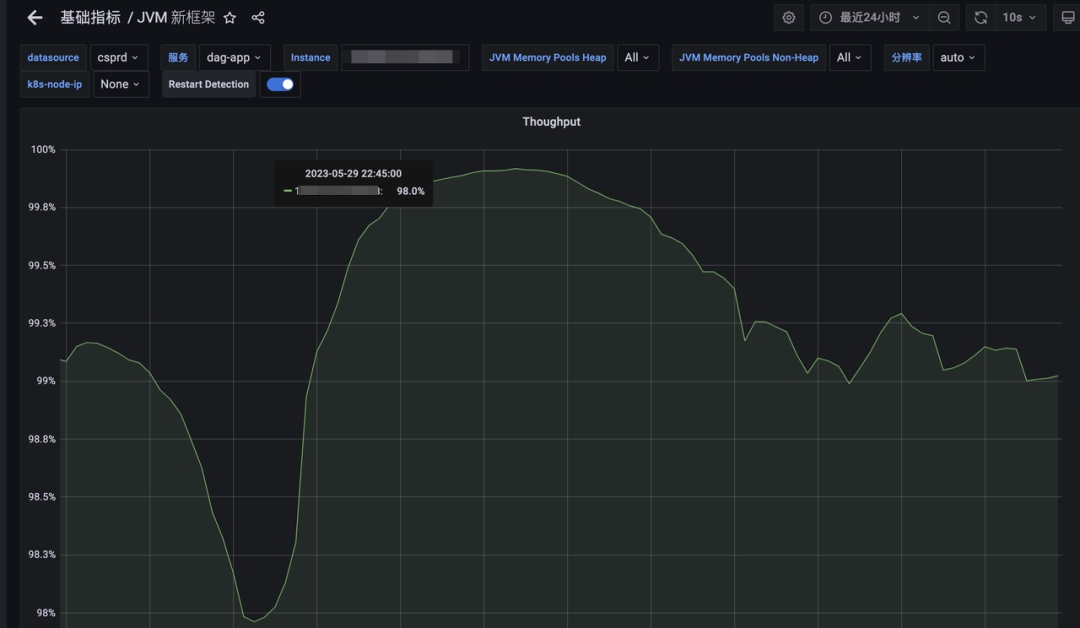
JDK8-G1 吞吐量
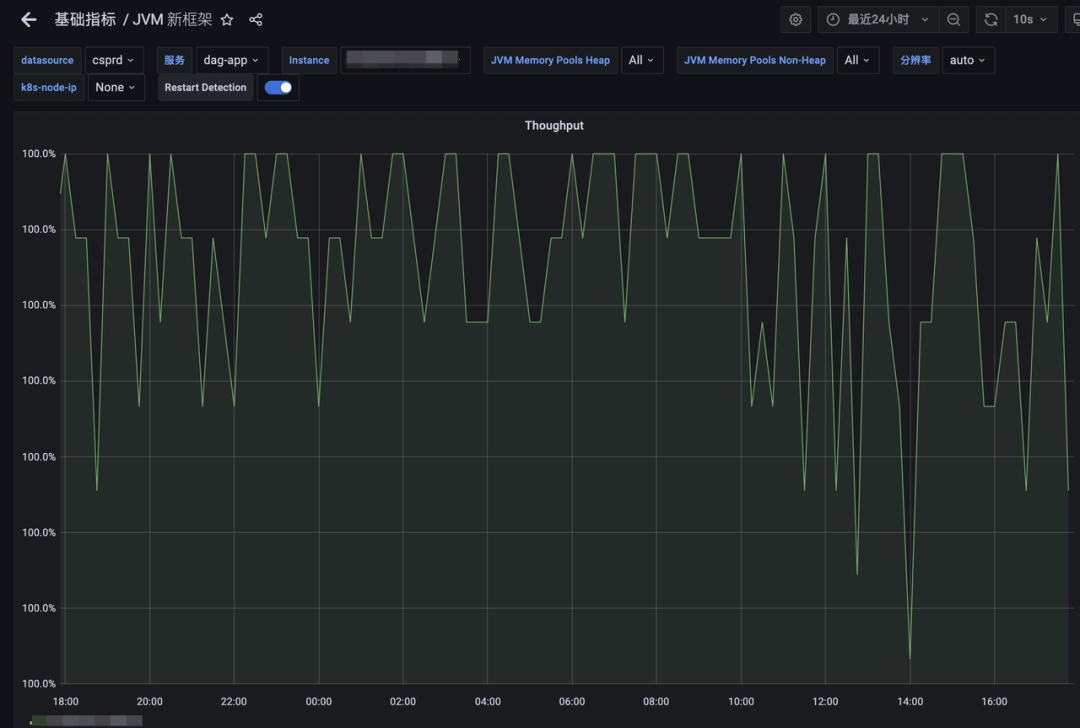
JDK17-ZGC吞吐量
对于实际业务接口的影响,从下图中可以看到平均响应时间有所下降,这里的RT差值表示接口经过网关层的损耗时间;不同接口的RT差值损耗是不同的,这可能和请求响应体的大小,是否经过登录验证,风控验证等业务逻辑有关。
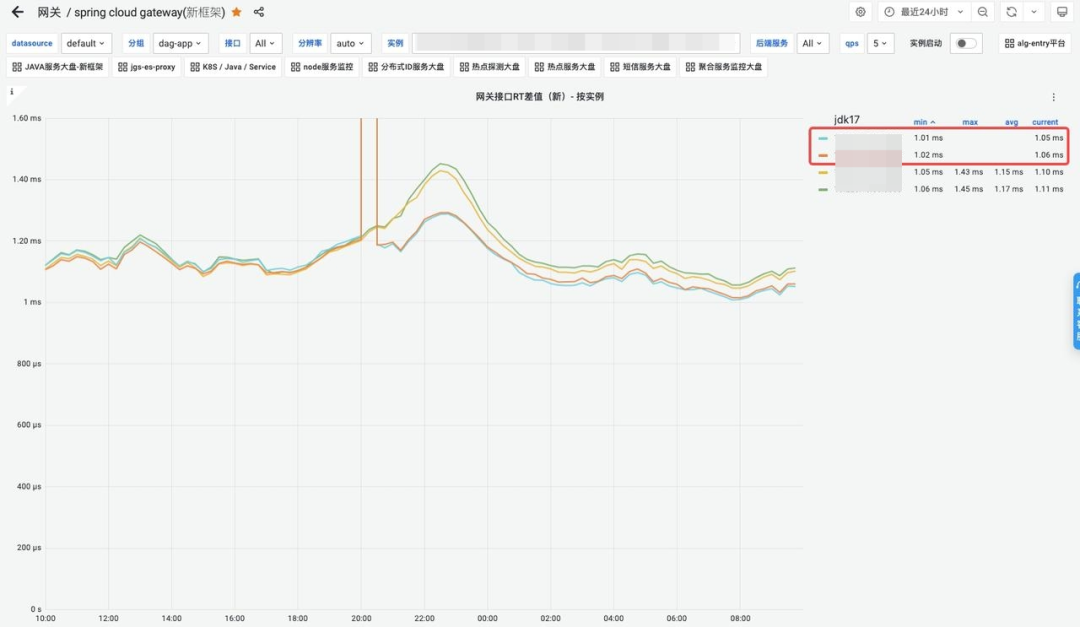
JDK17与JDK8 ART对比
需要指出的是ZGC对于一般的RT敏感型应用有很大提升, 服务的RT 99线得到显著改善。但是如果当前应用大量使用了堆外内存的方式,则提升相对较弱,如大量使用netty框架的应用, 因为这些应用的大部分数据都是通过手动释放的方式进行管理。
八、思考总结
架构演进
API网关的自研并非一蹴而就,而是经历了多次业务迭代循序渐进的过程;从早期的泛化路由引发的安全问题处理,到后面的大量路由注册,带来的匹配性能下降 ,以及最终压垮老网关最后一根稻草的内存泄漏问题;在不同阶段需要使用不同的应对策略,早期业务快速迭代,大量的需求堆积,最快的时候一个功能点的改动需要三四天内上线 ,我们很难有足够的精力去做一些深层次的改造,这个时候需求导向为优先,功能性建设完善优先,是一个快速奔跑的建设期;伴随体量的增长安全和稳定性的重视程度逐步拔高,继而推进了这些方面的大量建设;从拓展SCG的原有功能到改进框架源码,以及最终的自研重写,可以说新的API网关是一个业务推进而演化出来的产物,也只有这样 ”生长“ 出来的架构产品才能更好的契合业务发展的需要。
稳定性把控
自研基础组件是一项浩大的工程,可以预见代码量会极为庞大,如何有效管理新项目的代码质量是个棘手的问题; 原有业务逻辑的改造也需要回归测试;
现实的情况是中间件团队没有专职的测试,质量保证完全依赖开发人员;这就对开发人员的代码质量提出了极高的要求,一方面我们通过与老网关适配相同的代理引擎接口,降低迁移成本和业务逻辑出现bug的概率;另一方面还对编码质量提出了高标准,平均每周两到三次的CodeReview;80%的单元测试行覆盖率要求。
网关作为流量入口,承接全司最高流量,对稳定性的要求极为苛刻。最理想的状态是在业务服务没有任何感知的情况下,我们将新网关逐步替换上去;为此我们对新网关上线的过程做了充分的准备,严格控制上线过程;具体来看整个上线流程分为以下几个阶段:
第一阶段
我们在压测环境长时间高负载压测,持续运行时间24小时以上,以检测内存泄漏等稳定性问题。同时利用性能检测工具抓取热点火焰图,做针对性优化。
第二阶段
发布测试环境试跑,采用并行试跑的方式,新老网关同时对外提供服务(流量比例1 :1,初期新网关承接流量可能只有十分之一),一旦用户反馈的问题可能跟新网关有关,或者发现异常case,立即关停新网关的流量。待查明原因并确认修复后,重新引流。
第三阶段
上线预发,小得物环境试跑,由于这些环境流量不大,依然可以并行长时间试跑,发现问题解决问题。
第四阶段
生产引流,单节点从万分之一比例开始灰度,逐步引流放大,每个阶段停留24小时以上,观察修正后再放大,循环此过程;基于单节点承担正常比例流量后,再次抓取火焰图,基于真实流量场景下的性能热点做针对性优化。
自研过程是一个逐步完善的过程,从解决安全问题到提高性能,再到解决内存泄漏,每个阶段都有其特定的问题和要求。在稳定性控制方面,我们依靠开发人员的代码质量和对新网关上线流程的严格控制,确保了网关的高可用性和稳定性。通过逐步替换和灰度测试,我们确保了新网关能够在不影响现有业务的情况下平稳上线。这个过程中,我们学到了很多,也取得了显著的成果,为得物平台的发展奠定了坚实的基础。















 4506
4506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









