







Python与C++不同点:
1、代码块分隔
不需要用{ }来区分代码块,直接用缩进格式,没有要求缩进几个空格,至少1个,一般是4个。
if 5 > 2:
print("Five is greater than two!") #如果这一行没有缩进就会报错
2、变量
不需要声明变量,需要使用变量的时候,直接给变量赋值即可,变量类型可变,大小写敏感,字符串用单引号或者双引号都可。
3、注释
单行注释用#,没有多行注释,可以用多行字符串(三个单引号或双引号对)实现多行注释,因为如果多行字符串没有赋值给一个变量,Python就不处理它,那就相当于一个多行注释了。
"""
This is a comment
written in
more than just one line
"""
4、可同时给多个变量分别赋值,或者一个值付给多个变量
x, y, z = "Orange", "Banana", "Cherry" #同时给多个变量分别赋值
print(x) #Orange
print(y) #Banana
print(z) #Cherry
x = y = z = "Orange" #一个值赋给多个变量
5、用元组、列表给变量赋值
可以直接分解一个列表、元组的内容给多个变量
fruits = ["apple", "banana", "cherry"]
x, y, z = fruits
print(x)
print(y)
print(z)
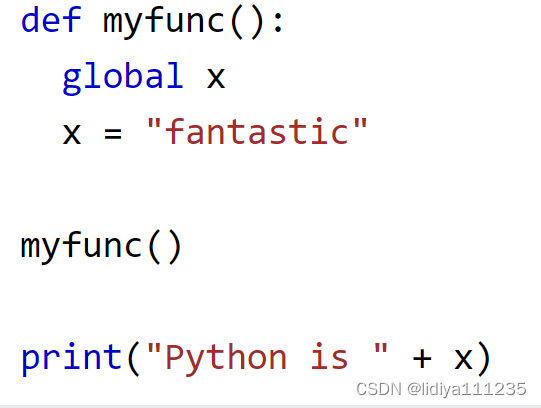
6、全局变量
一般声明在函数外边的变量是全局变量,如果要在函数里声明全局变量,可以用关键字global。
7、Python的数据类型


可用如下格式进行强制类型转换

8、随机数
Python没有随机数函数,但是有个随机数模块,如下代码即可生成1-9的随机数。
import random
print(random.randrange(1, 10))
random模块的随机数函数见https://www.w3schools.com/python/module_random.asp


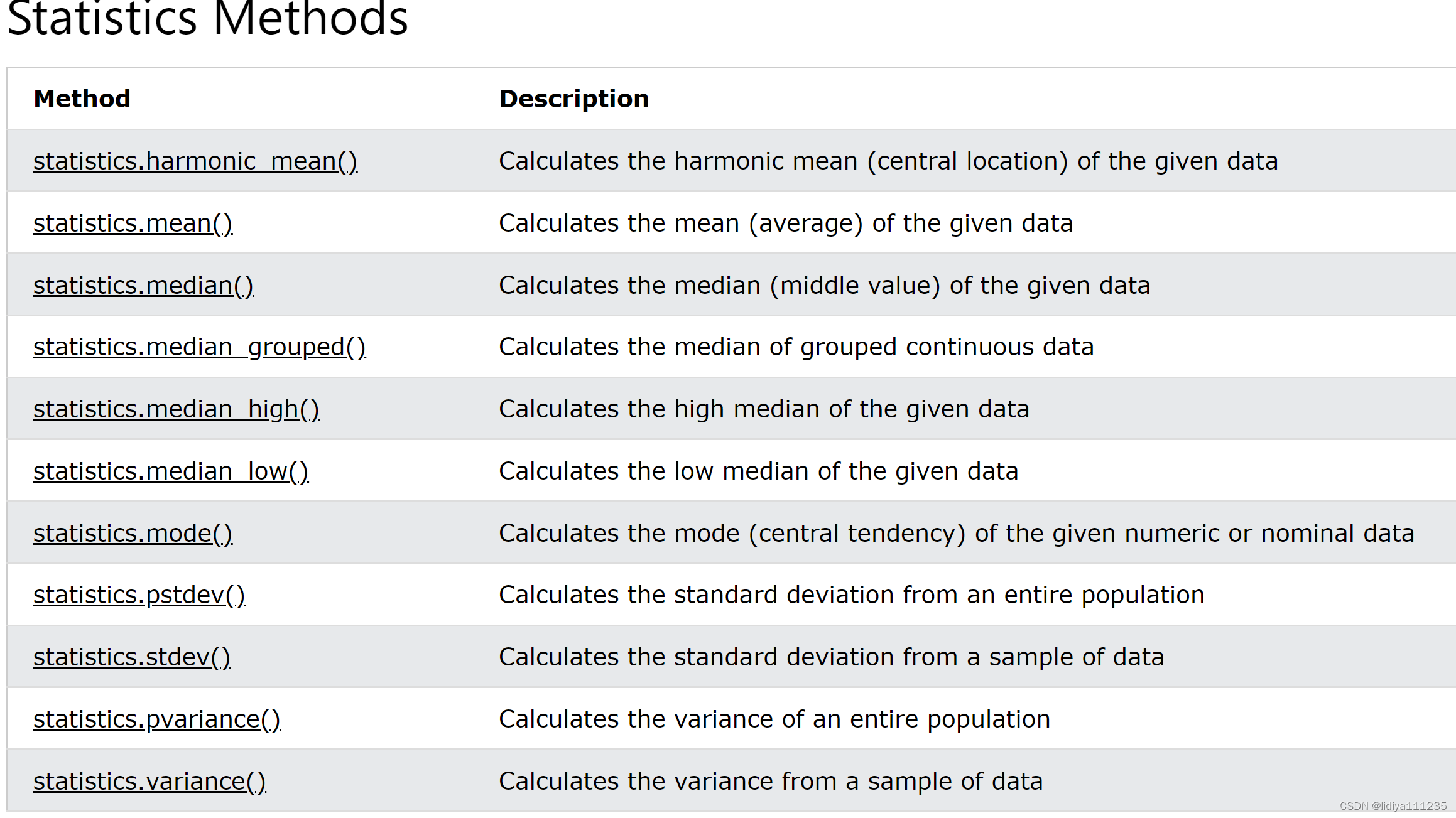
9、数理统计模块(可统计方差等)
可调用库函数统计均值、方差、标准差等数理统计https://www.w3schools.com/python/module_statistics.asp

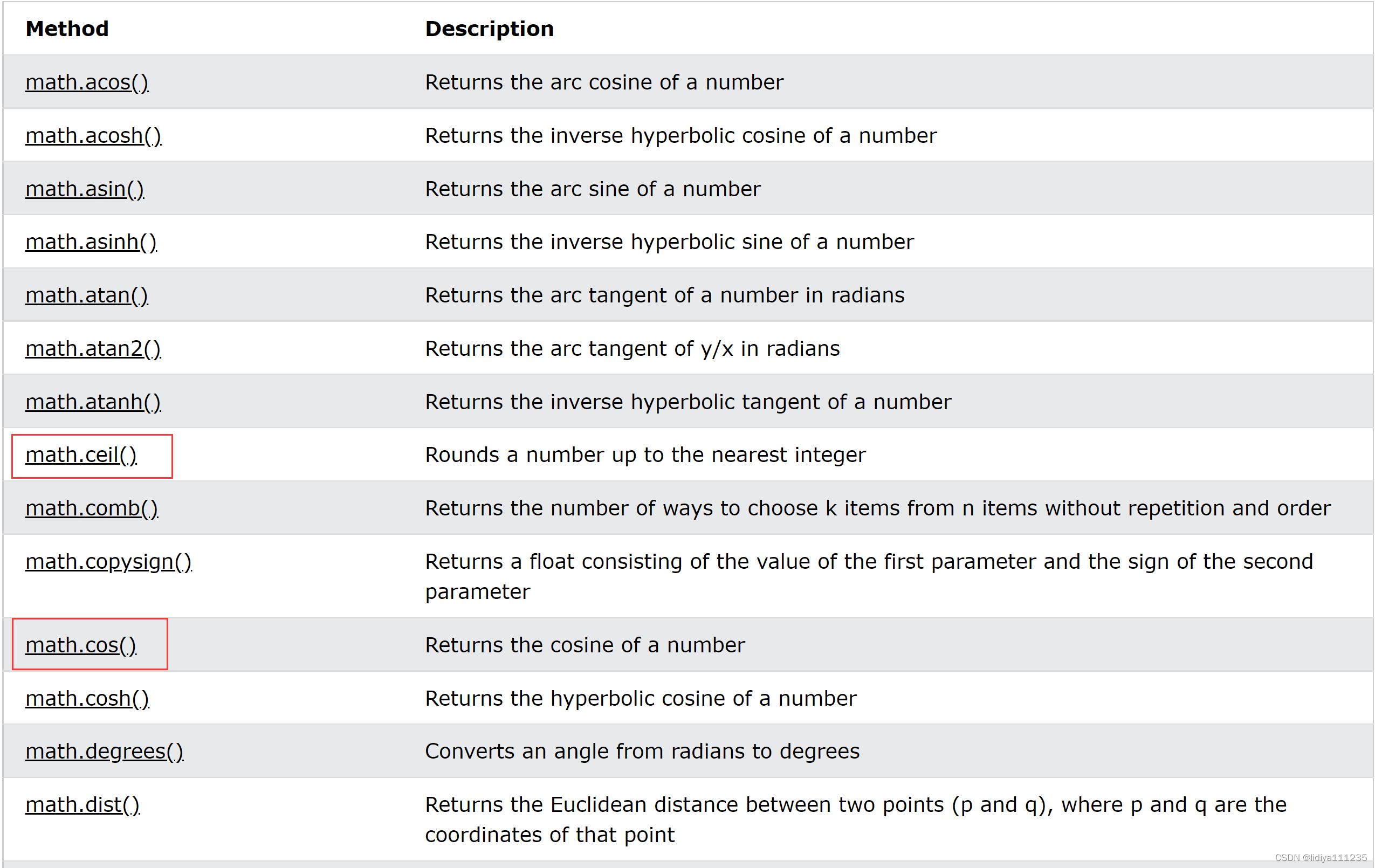
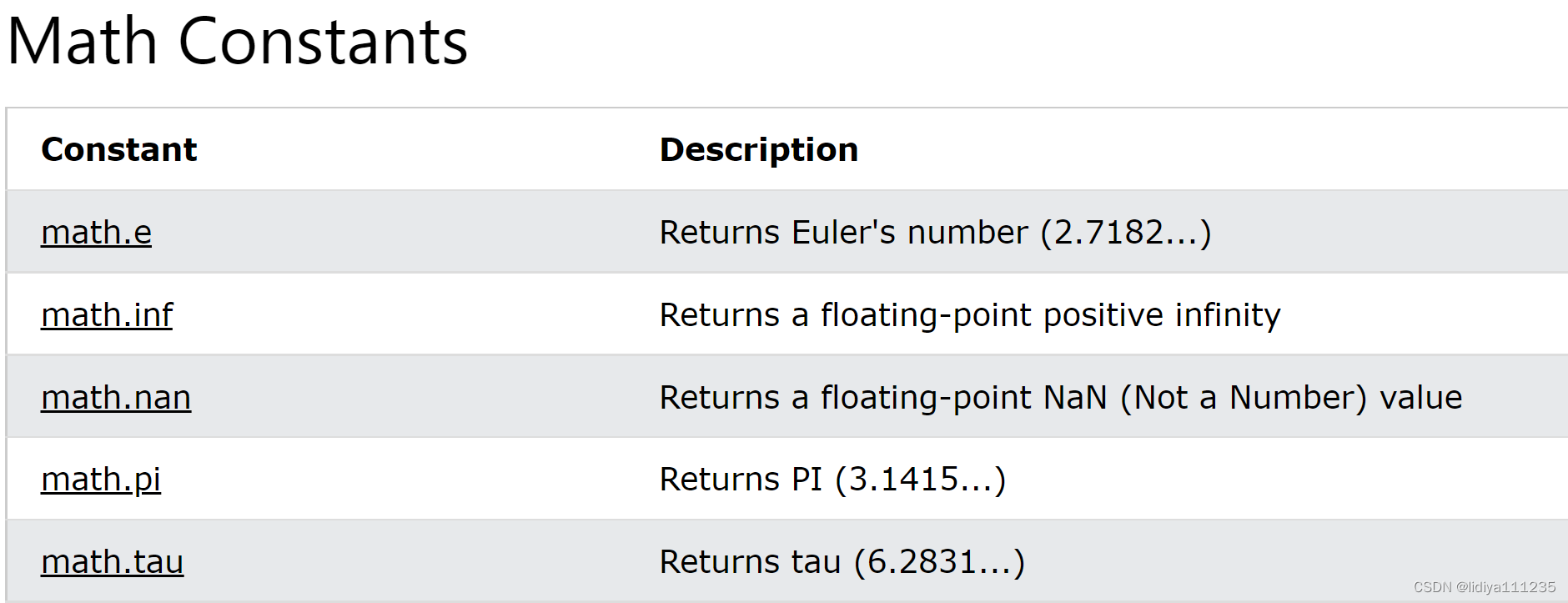
10、math模块(提供了很多数学函数)
math模块提供了cos、sin、开方、向上取整、向下取整等函数
还有一个cmath库,里边是跟复数相关的一些函数,具体见https://www.w3schools.com/python/module_cmath.asp


11、 如何去除列表中的重复项
如下例子mylist是一个有重复项的list,创建一个字典,使用List项作为键。这将自动删除任何重复的键,因为字典不能有重复的键,然后,将字典转换回列表,就得到一个没有重复项的列表。
mylist = ["a", "b", "a", "c", "c"]
mylist = list(dict.fromkeys(mylist))
print(mylist) #['a', 'b', 'c']
12、字符串逆序
Python没有专门的函数来实现字符串逆序,可使用一个步长为-1的向后的切片,如下:
txt = "Hello World"[::-1]
print(txt) #dlroW olleH
the slice statement [::-1] means start at the end of the string and end at position 0, move with the step -1, negative one, which means one step backwards.
还可以把该功能写成一个函数:

13、键盘输入(input函数)

14、截取字符串中个别字符
b = "Hello, World!"
print(b[2:5]) #llo
15、字符串常用操作
字符串的首字母大写、去除首尾空格等函数等函数见python库函数文档Built-in Types — Python 3.11.1 documentation
(1)首字母大写:str.capitalize()
(2)全部转小写:str.casefold() ; str.lower()
(3)查找子字符串的位置:str.find(sub[, start[, end]])
(4)格式化输出:str.format(*args, **kwargs),可以把字符串中部分内容用{}留空,具体内容用
a="world"
c="I like Python"
"hello {}! {}".format(a,c) # 'hello world! I like Python'
(5)判断字符串是不是都是数字:str.isdecimal()
(6)判断字符是不是都是小写/大写:str.islower() str.isupper()
(7)字符串替换:str.replace(old, new[, count])
a = "Hello, World!"
print(a.replace("H", "J"))
(8)拆分字符串:str.rsplit(sep=None, maxsplit=- 1) ; str.split(sep=None, maxsplit=- 1)
a = "Hello, World!"
b = a.split(",")
print(b) #['Hello', ' World!']
(9)大小写转换:str.swapcase()
(10)去除首尾部空格:str.strip()
a = " Hello, World! "
print(a.strip())
(11)字符串长度:len(str)
16、列表相关操作
(1)判断列表中是否有某项
thislist = ["apple", "banana", "cherry"]
if "apple" in thislist:
print("Yes, 'apple' is in the fruits list")
(2)循环访问列表元素
thislist = ["apple", "banana", "cherry"]
for x in thislist:
print(x)
(3)列表中添加元素
thislist = ["apple", "banana", "cherry"]
thislist.append("orange") #列表尾部添加元素
thislist.insert(1, "orange") #列表中间插入元素
print(thislist)
(4)求列表长度
thislist = ["apple", "banana", "cherry"]
print(len(thislist))
(5)删除列表元素
thislist = ["apple", "banana", "cherry"]
thislist.remove("banana") #删除指定元素
thislist.pop() #删除最后一个元素
del thislist[0] #删除指定位置上的元素
thislist.clear() #清空列表
print(thislist)
(6)创建列表
thislist = ['apple', 'banana', 'cherry']
thislist = list(("apple", "banana", "cherry")) #使用构造函数创建列表
print(thislist) #['apple', 'banana', 'cherry']
17、元组相关操作
(1)创建元组
thistuple = ("apple", "banana", "cherry")
thistuple = tuple(("apple", "banana", "cherry")) #用构造函数创建元组
print(thistuple)
(2)访问元组元素
thistuple = ("apple", "banana", "cherry")
print(thistuple[1]) #banana
(3)修改元组的值
thistuple = ("apple", "banana", "cherry")
thistuple[1] = "blackcurrant"
# the value is still the same:因为tuple不支持增、删、改操作
print(thistuple) #('apple', 'banana', 'cherry')
(4)循环元素元素
thistuple = ("apple", "banana", "cherry")
for x in thistuple:
print(x)
(5)删除元组
thistuple = ("apple", "banana", "cherry")
del thistuple
print(thistuple) #this will raise an error because the tuple no longer exists
18、字典相关操作
(1)创建字典
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print(thisdict) #{'brand': 'Ford', 'model': 'Mustang', 'year': 1964}
thisdict = dict(brand="Ford", model="Mustang", year=1964) #用构造函数创建字典
# note that keywords are not string literals
# note the use of equals rather than colon for the assignment
print(thisdict) #{'brand': 'Ford', 'model': 'Mustang', 'year': 1964}
(2)访问字典元素
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
x = thisdict["model"]
print(x) #Mustang
(3)改变字典元素
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict["year"] = 2018
print(thisdict) #{'brand': 'Ford', 'model': 'Mustang', 'year': 2018}
(4)访问字典的所有键
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
for x in thisdict:
print(x)
输出:
brand
model
year
(5)访问字典中的所有值
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
for x in thisdict:
print(thisdict[x])
以下代码效果相同:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
for x in thisdict.values():
print(x)
输出:
Ford
Mustang
1964
(6)同时访问字典的键值对
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
for x, y in thisdict.items():
print(x, y)
输出:
brand Ford
model Mustang
year 1964
(7)查找字典的某个键
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
if "model" in thisdict:
print("Yes, 'model' is one of the keys in the thisdict dictionary")
(8)字典长度
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print(len(thisdict)) #3
(9)字典中添加元素
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict["color"] = "red"
print(thisdict) #{'brand': 'Ford', 'model': 'Mustang', 'year': 1964, 'color': 'red'}
(10)删除一个字典元素
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict.pop("model")
thisdict.clear() #清空字典元素
print(thisdict)
19、循环结构、选择结构
条件部分都不需要用括号了。
(1)if...else
a = 33
b = 200
单分支:
if b > a:
print("b is greater than a")
还可以简写为:if a > b: print("a is greater than b")
双分支:
if b > a:
print("b is greater than a")
elif a == b:
print("a and b are equal")
还可以简写为:print("A") if a > b else print("B")
多分支:
if b > a:
print("b is greater than a")
elif a == b:
print("a and b are equal")
else:
print("a is greater than b")
(2)while循环
i = 1
while i < 6:
print(i)
i += 1
使用break跳出循环:
while i < 6:
print(i)
if (i == 3):
break
i += 1
使用continue继续循环:
i = 0
while i < 6:
i += 1
if i == 3:
continue
print(i)
# Note that number 3 is missing in the result
结果:
1
2
4
5
6
(3)for循环
可以像while循环一样使用break和continue。
fruits = ["apple", "banana", "cherry"]
for x in fruits:
print(x)
输出:
apple
banana
cherry
在字符串中循环,输出每个字符
for x in "banana":
print(x)
for x in range(6):
print(x)
(4)for循环中使用else
for x in range(6):
print(x)
else:
print("Finally finished!")
输出:
0
1
2
3
4
5
Finally finished!
(5)for循环嵌套
adj = ["red", "big", "tasty"]
fruits = ["apple", "banana", "cherry"]
for x in adj:
for y in fruits:
print(x, y)
输出:
red apple
red banana
red cherry
big apple
big banana
big cherry
tasty apple
tasty banana
tasty cherry
20、函数的使用
(1)定义、调用函数
def my_function(): #定义函数
print("Hello from a function")
my_function() #调用函数,输出Hello from a function
(2)函数参数
def my_function(fname): #不需要声明函数参数的类型
print(fname + " Refsnes")
my_function("Emil")
my_function("Tobias")
my_function("Linus")
(3)函数参数默认值
def my_function(country = "Norway"):
print("I am from " + country)
my_function("Sweden")
my_function("India")
my_function()
(4)有返回值的函数
def my_function(x):
return 5 * x
print(my_function(3))
print(my_function(5))
print(my_function(9))
(5)递归
def tri_recursion(k):
if(k > 0):
result = k + tri_recursion(k - 1)
print(result)
else:
result = 0
return result
print("\n\nRecursion Example Results")
tri_recursion(6)
输出:
Recursion Example Results
1
3
6
10
15
21
21、数组相关操作
(1)创建数组
cars = ["Ford", "Volvo", "BMW"]
print(cars) #['Ford', 'Volvo', 'BMW']
(2)访问数组元素
cars = ["Ford", "Volvo", "BMW"]
x = cars[0]
print(x)
cars = ["Ford", "Volvo", "BMW"]
for x in cars:
print(x)
(3)修改数组元素值
cars = ["Ford", "Volvo", "BMW"]
cars[0] = "Toyota"
print(cars)
(4)数组元素个数
cars = ["Ford", "Volvo", "BMW"]
x = len(cars)
print(x) #3
(5)数组中添加元素
cars = ["Ford", "Volvo", "BMW"]
cars.append("Honda")
print(cars)
(6)删除某个数组元素
cars = ["Ford", "Volvo", "BMW"]
cars.pop(1) #把索引为1的数组元素删除
print(cars) #['Ford', 'BMW']
22、类和对象
(1)创建类和对象
class MyClass:
x = 5
print(MyClass) #<class '__main__.MyClass'>
创建对象:
p1 = MyClass()
print(p1.x) #5
(2)初始化init函数
class Person:
def __init__(self, name, age): #注意init前后是两个下划线
self.name = name
self.age = age
p1 = Person("John", 36)
print(p1.name)
print(p1.age)
1、__init__ 方法的第一个参数永远是 self ,表示正在创建的实例/对象本身,因此,在 __init__ 方法的内部,就可以把各种属性绑定到 self,因为 self 就指向创建的实例本身。
2、使用了 __init__ 方法,在创建实例的时候就不能传入 空的参数了,必须传入与 __init__ 方法匹配的参数,但是 self 不需要传,python解释器会自己把实例变量传进去。
(3)类中的函数定义和调用
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self): #如果函数中要调用类的其他数据或函数,就需要参数self
print("Hello my name is " + self.name)
def myfunc2(self): #如果函数中要调用类的其他数据或函数,就需要参数self
print(self.myfunc())
print(myfunc()) #这样写就会报错,调用自身的函数,必须要用self参数来调用
p1 = Person("John", 36)
p1.myfunc()
1、在Python类中规定,函数的第一个参数是实例对象本身,并且约定俗成,把其名字写为self(也可以用其他变量名,为了好识别,一般都用self),表示正在创建的对象。其作用相当于java中的this,表示当前类的对象,可以调用当前类中的属性和方法。
(4)self参数可以用其他名字
python默认函数的第一个参数就是表示对象本身,所以即使参数名不是self也不影响它表示对象这个功能,所以可以重新命名,但是一般习惯性都用self。
class Person:
def __init__(mysillyobject, name, age):
mysillyobject.name = name
mysillyobject.age = age
def myfunc(abc):
print("Hello my name is " + abc.name)
p1 = Person("John", 36)
p1.myfunc() #Hello my name is John
(5)删除对象属性
del删除的只是当前对象的属性,不是删除类的属性,再定义其他对象时,该属性依然存在。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self):
print("Hello my name is " + self.name)
p1 = Person("John", 36)
del p1.age
#print(p1.age) #会报错
p2 = Person("mary", 22)
print(p2.age) #正常执行
(6)删除对象
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self):
print("Hello my name is " + self.name)
p1 = Person("John", 36)
del p1
print(p1)
(7)python中的特殊情况
1、私有变量(private),只有内部可以访问,外部不能访问,私有变量是在名称前以两个下划线开头,如:__name,其实私有变量也不是完全不能被外部访问,不能直接访问是因为python解释器对外把 __name 变量改成了 _类名__name,所仍然可以通过 _类名__name 来访问 __name。
2、在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
3、以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
23、迭代器
参考:https://www.runoob.com/python3/python3-iterator-generator.html
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
实例(Python 3.0+)
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
>>>
迭代器对象可以使用常规for语句进行遍历:
实例(Python 3.0+)
#!/usr/bin/python3
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
执行以上程序,输出结果如下:
1 2 3 4
也可以使用 next() 函数:
实例(Python 3.0+)
#!/usr/bin/python3
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
24、日期相关函数
(1)导入datatime模块并显示当前时间
import datetime
x = datetime.datetime.now()
print(x) #2023-01-27 18:03:18.055971
(2)显示年和星期
import datetime
x = datetime.datetime.now()
print(x.year)
print(x.strftime("%A"))
(3)创建时间对象
import datetime
x = datetime.datetime(2020, 5, 17)
print(x) #2020-05-17 00:00:00
其他函数具体参考datetime --- 基本日期和时间类型 — Python 3.11.1 文档
25、json解析
(1)json转python
import json
# some JSON:
x = '{ "name":"John", "age":30, "city":"New York"}'
# parse x:
y = json.loads(x)
# the result is a Python dictionary:
print(y["age"]) #30
(2)python转json
import json
# a Python object (dict):
x = {
"name": "John",
"age": 30,
"city": "New York"
}
# convert into JSON:
y = json.dumps(x)
# the result is a JSON string:
print(y) #{"name": "John", "age": 30, "city": "New York"}
(3)python对象转json字符串
import json
print(json.dumps({"name": "John", "age": 30}))
print(json.dumps(["apple", "bananas"]))
print(json.dumps(("apple", "bananas")))
print(json.dumps("hello"))
print(json.dumps(42))
print(json.dumps(31.76))
print(json.dumps(True))
print(json.dumps(False))
print(json.dumps(None))
输出:
{"name": "John", "age": 30}
["apple", "bananas"]
["apple", "bananas"]
"hello"
42
31.76
true
false
null
(4)python对象转换json,有效数据都转
import json
x = {
"name": "John",
"age": 30,
"married": True,
"divorced": False,
"children": ("Ann","Billy"),
"pets": None,
"cars": [
{"model": "BMW 230", "mpg": 27.5},
{"model": "Ford Edge", "mpg": 24.1}
]
}
# convert into JSON:
y = json.dumps(x)
# the result is a JSON string:
print(y)
输出:
{"name": "John", "age": 30, "married": true, "divorced": false, "children": ["Ann","Billy"], "pets": null, "cars": [{"model": "BMW 230", "mpg": 27.5}, {"model": "Ford Edge", "mpg": 24.1}]}
(5)使用缩进格式转换python对象
import json
x = {
"name": "John",
"age": 30,
"married": True,
"divorced": False,
"children": ("Ann","Billy"),
"pets": None,
"cars": [
{"model": "BMW 230", "mpg": 27.5},
{"model": "Ford Edge", "mpg": 24.1}
]
}
# use four indents to make it easier to read the result:
print(json.dumps(x, indent=4))
输出:
{
"name": "John",
"age": 30,
"married": true,
"divorced": false,
"children": [
"Ann",
"Billy"
],
"pets": null,
"cars": [
{
"model": "BMW 230",
"mpg": 27.5
},
{
"model": "Ford Edge",
"mpg": 24.1
}
]
}
(6)python转json时的分隔符替换
import json
x = {
"name": "John",
"age": 30,
"married": True,
"divorced": False,
"children": ("Ann","Billy"),
"pets": None,
"cars": [
{"model": "BMW 230", "mpg": 27.5},
{"model": "Ford Edge", "mpg": 24.1}
]
}
# use . and a space to separate objects, and a space, a = and a space to separate keys from their values:
print(json.dumps(x, indent=4, separators=(". ", " = ")))
输出:
{
"name" = "John".
"age" = 30.
"married" = true.
"divorced" = false.
"children" = [
"Ann".
"Billy"
].
"pets" = null.
"cars" = [
{
"model" = "BMW 230".
"mpg" = 27.5
}.
{
"model" = "Ford Edge".
"mpg" = 24.1
}
]
}
26、正则表达式
(1)查找的正则表达式
import re #使用正则表达式需要引入该模块
#Check if the string starts with "The" and ends with "Spain":
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
if x:
print("YES! We have a match!")
else:
print("No match")
(2)正则表达式中符号的含义

(3)正则表达式中一些特殊符号的意义


(4)re模块中的一些函数
re模块中提供了一些字符串查找,替换或者分割等方法,具体见Python RegEx

27、异常处理
捕获try代码块的异常,如果发生异常,则执行except代码块的内容

如果可能发生多个异常,可以用多个except模块捕捉,按照顺序匹配,如果前边的都没有匹配到,最后一个通用的except就被执行

异常处理模块还可以和else搭配使用,如果try块中出现异常,执行except模块代码,如果没有异常,则执行else代码块中的代码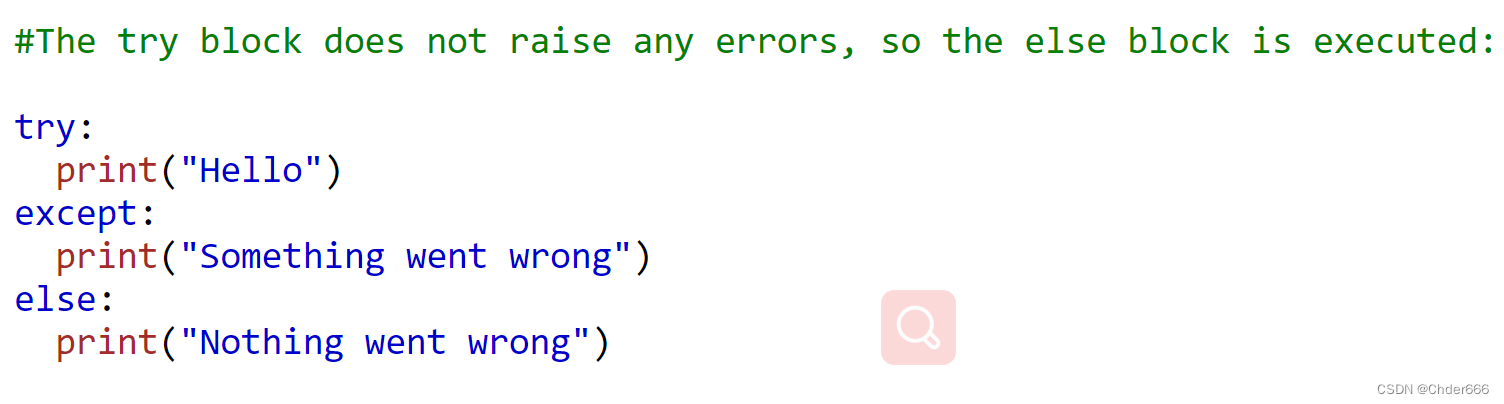
不关try块中有没有异常,finally中的代码都会执行,即如果try块有异常,则except中的代码和finally中的代码都执行,如果没有异常,except的代码不执行,finally中的代码执行

28、文件读取
f = open("demofile.txt", "r") #打开文件
print(f.read()) #read()函数读取文件全部内容
print(f.read(5)) #read()函数读取文件的5个字符
print(f.readline()) #read()函数读取文件的一行内容
for x in f: #该for循环将文件中的内容按字符逐个读取出来
print(x)
f.close() #关闭文件

使用with...open结构,就不需要调用close关闭文件,with块执行完会自动关闭文件

29、连接MySQL数据库
导入mysql(或其他数据库)的connector,然后调用connect函数即可建立和数据库的连接。
import mysql.connector
mydb = mysql.connector.connect(
host="localhost", #数据库地址
user="myusername", #数据库用户名
password="mypassword" #数据库密码
)
mycursor = mydb.cursor()
mycursor.execute("CREATE DATABASE mydatabase") #创建数据库
数据库创建好以后,连接的时候就指定连接的数据库,然后就可以创建数据表
mydb = mysql.connector.connect(
host="localhost",
user="myusername",
password="mypassword",
database="mydatabase"
)
mycursor = mydb.cursor()
mycursor.execute("CREATE TABLE customers (name VARCHAR(255), address VARCHAR(255))") #创建数据表
mycursor.execute("CREATE TABLE customers (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), address VARCHAR(255))") #创建带有主键的数据表
以下四句插入一条记录
sql = "INSERT INTO customers (name, address) VALUES (%s, %s)"
val = ("John", "Highway 21")
mycursor.execute(sql, val)
mydb.commit() #执行插入命令
以下指令插入多行记录
sql = "INSERT INTO customers (name, address) VALUES (%s, %s)"
val = [
('Peter', 'Lowstreet 4'),
('Amy', 'Apple st 652'),
('Hannah', 'Mountain 21'),
('Michael', 'Valley 345'),
('Sandy', 'Ocean blvd 2'),
('Betty', 'Green Grass 1'),
('Richard', 'Sky st 331'),
('Susan', 'One way 98'),
('Vicky', 'Yellow Garden 2'),
('Ben', 'Park Lane 38'),
('William', 'Central st 954'),
('Chuck', 'Main Road 989'),
('Viola', 'Sideway 1633')
]
mycursor.executemany(sql, val)
mydb.commit()
print("the last ID is :", mycursor.lastrowid) #获取最后一条记录的ID
查找数据表所有字段
mycursor.execute("SELECT * FROM customers")
myresult = mycursor.fetchall()
for x in myresult:
print(x) #以这种形式逐行显示所有记录(1, 'John', 'Highway 21')
查找数据表部分字段
mycursor.execute("SELECT name, address FROM customers")
myresult = mycursor.fetchall()
for x in myresult:
print(x)
只获取一行记录
mycursor.execute("SELECT * FROM customers")
myresult = mycursor.fetchone()
print(myresult)
条件搜索
sql = "SELECT * FROM customers WHERE address = 'Park Lane 38'"
mycursor.execute(sql)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
模糊搜索,搜索地址中还有way的所有记录
sql = "SELECT * FROM customers WHERE address Like '%way%'"
mycursor.execute(sql)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
用变量传入条件的条件搜索
sql = "SELECT * FROM customers WHERE address = %s"
adr = ("Yellow Garden 2", )
mycursor.execute(sql, adr)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
搜索并排序
sql = "SELECT * FROM customers ORDER BY name" #这句是升序
sql = "SELECT * FROM customers ORDER BY name DESC" #这句是降序
mycursor.execute(sql)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
删除记录
sql = "DELETE FROM customers WHERE address = 'Mountain 21'"
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, "record(s) deleted")
删除一个表格
sql = "DROP TABLE customers" #直接删除一个已经存在的表格
sql = "DROP TABLE IF EXISTS customers" #如果表格存在则删除
mycursor.execute(sql)
更新表格记录
sql = "UPDATE customers SET address = 'Canyon 123' WHERE address = 'Valley 345'"
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, "record(s) affected")
更新的变量以参数传入
sql = "UPDATE customers SET address = %s WHERE address = %s"
val = ("Valley 345", "Canyon 123")
mycursor.execute(sql, val)
mydb.commit()
限制每次查询的记录条数
mycursor.execute("SELECT * FROM customers LIMIT 5")
myresult = mycursor.fetchall() #只能查到最多5条记录
for x in myresult:
print(x)
多表联合查询inner
关于inner、left、right联合查询可参考sql之left join、right join、inner join的区别 - PCJIM - 博客园
sql = "SELECT \
users.name AS user, \
products.name AS favorite \
FROM users \
INNER JOIN products ON users.fav = products.id"
mycursor.execute(sql)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
把两个表中的users.fav = products.id的所有users.name、products.name输出:
('John', 'Chocolate Heaven')
('Peter', 'Chocolate Heaven')
('Amy', 'Tasty Lemon')
left join联合查询
sql = "SELECT \
users.name AS user, \
products.name AS favorite \
FROM users \
LEFT JOIN products ON users.fav = products.id"
mycursor.execute(sql)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
以左表(users)为准,左表的记录将会全部表示出来,而右表只会显示符合搜索条件(users.fav = products.id)的记录,不符合条件的部分用None代替:
('John', 'Chocolate Heaven')
('Peter', 'Chocolate Heaven')
('Amy', 'Tasty Lemon')
('Hannah', None)
('Michael', None)
right join联合查询
sql = "SELECT \
users.name AS user, \
products.name AS favorite \
FROM users \
RIGHT JOIN products ON users.fav = products.id"
mycursor.execute(sql)
myresult = mycursor.fetchall()
for x in myresult:
print(x)
以右表(products)为准,右表的记录将会全部表示出来,而左表只会显示符合搜索条件(users.fav = products.id)的记录,不符合条件的部分用None代替:
('John', 'Chocolate Heaven')
('Peter', 'Chocolate Heaven')
('Amy', 'Tasty Lemon')
(None, 'Vanilla Dreams')














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









