






 序列相似度(identity)衡量两个序列的匹配程度,本文探讨了Gap-excluded、BLAST和Gap-compressed三种身份计算方法,以及罚分如何影响比对结果。文中举例并指出在讨论相似度时明确算法选择的重要性。
序列相似度(identity)衡量两个序列的匹配程度,本文探讨了Gap-excluded、BLAST和Gap-compressed三种身份计算方法,以及罚分如何影响比对结果。文中举例并指出在讨论相似度时明确算法选择的重要性。
序列相似度(identity)是两个序列之间相似度的度量值。在测序数据中一般是测序错误率的反面。当我们说“两个物种的差异是。。”或者“测序错误是。。”,事实上有不同的相似度的计算方法,这里我们讨论了集中算法,每次在说相似度时,要搞清楚用的是那种算法。
首先举个例子说明,下面两条序列的相似度是多少呢?
CCAGTGTGGCCGATACCCCAGGTTGGCACGCATCGTTGCCTTGGTAAGC
CCAGTGTGGCCGATGCCCGTGCTACGCATCGTTGCCTTGGTAAGC
计算相似度,通常先要进行比对,我们使用match=1,mismatch=-2, gapOpen=-2 and gapExt=-1的参数进行比对,得到如下结果
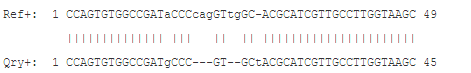
有43个matching的碱基,1个mismatch,5个deletion,1个insertion,CIGAR是18M3D2M2D2M1I22M.
Gap-excluded identity
这种计算法,我们首先排除比对中gapped列,也就是只保留match,和mismatch,相似度就=matches / (matches + mismatches)。上面例子的相似度就是43/(43+1)=97.7%.
这种计算方法明显的问题就是没有考虑gaps。然而这还是一种经常使用的定义。经常有人说“人和大猩猩基因组只有百分之几的差异”,这种说法就是使用的这种计算方法。论文(first chimpanzee genomepaper)中的原句是“Single-nucleotide substitutions occur at a mean rate of 1.23% between copies of the human and chimpanzee genome”,意思是“任何大猩猩基因组的单碱基替换率平均为1.23%”
BLAST identity
BLAST相似度定义为matching的碱基占总的比对列数的比例。上例中,比对的列数一共50列,相似度为43/50=86%。在Sam格式中,比对的列数可以用CIGAR字符串计算(M/I/D的综述),matching碱基等于比对总列数减去NM tag,可以用下面Perl一行命令计算BLAST特异性
perl -ane 'if(/NM:i:(\d+)/){$n=$1;$l=0;$l+=$1 while/(\d+)[MID]/g;print(($l-$n)/$l,"\n")}'$n是Mismath/I/D的总和,$l是比对的长度。PAF格式中,第10列初一第11列就是BLAST相似度
BLAST相似度也许是最普遍的定义,但是我们也必须谨慎的用它来过滤比对数据。假设我们用一条带有~300bp 插入偏大的1000bp序列进行比对。相似度大约70%,我们可能就把他过滤掉了。但是在进化过程中这个插入可能只是一次插入事件,而不是300次,因此把他当成300bp的差异就会有一些问题。
Gap-compressed identity
对于过滤这也许是比较好的定义:我们把连续的gaps认为是一个差异,把连续的gap压缩成一个,例如把握们的例子压缩成如下的比对。
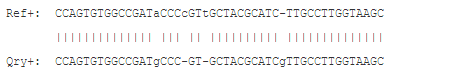
相似度为43/(50-2-1)=91.5%。我已经在几个任务中使用这种定义。最新版的minimap2在de:f tag里输出这种特异性。也可以用下面的perl命令计算
perl -ane 'if(/NM:i:(\d+)/){$n=$1;$m=$g=$o=0;$m+=$1 while/(\d+)M/g;$g+=$1,++$o while/(\d+)[ID]/g;print(1-($n-$g+$o)/($m+$o),"\n")}'$m是M的综合,$g是I和D的和,$o是gap open的数字。
罚分的影响
罚分会影响比对的结果和相似度。如果我们使用gapOpen=-4比对上面的两条序列,会得到如下的比对结果

BLAST 相似度 83.7% ,gap-compressed相似度89.1%。即使我们使用同一定义,不同的罚分也会得到不同的特异性。
结论
不同的定义和不同的罚分都会得到不同的相似度或错误率。所有当和别人讨论“测序错误”或“相似度”等的时候,先问清楚采用的那种定义,罚分怎么设置的,这样才有可比性。如果自己评估可以使用下面的命令
minimap2 -c ref.fa query.fa | perl -ane 'if(/tp:A:P/&&/NM:i:(\d+)/){$n+=$1;$m+=$1 while/(\d+)M/g;$g+=$1,++$o while/(\d+)[ID]/g}END{print(($n-$g+$o)/($m+$o),"\n")}'

















 6218
6218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









