






需求:系统A向系统B通过接口同步数据,在B接口生成数据的时候,系统C会自动过来拿系统B的数据,由于从A到B的数据量很大,生成的比较慢,而C又很轻快,一秒过来看一看,没有数据,无奈走了,五秒又过来看看,发现又没有数据,20秒过来看看,有数据了,于是就取走了,但是当他用的时候,发现这些数据不完整的。也就是B还没有完全生成,他就猴急猴急的取走了。于是C不干了,质问B它是怎么取数据的啊?于是B一边抱怨数据量大,一边抱怨C太轻快,一边在看代码。
以前,整体的代码逻辑是很简单的,首先是将XML转为datatable,然后进行数据筛选,然后查询数据库中是否存在这条语句,不存在就插入,存在的就更新中间库的内容。
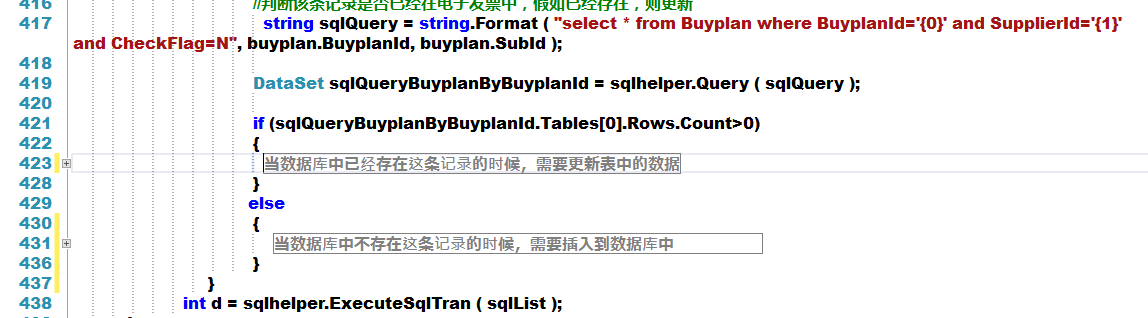
假如有一万条数据,首先我的查询语句就需要打开1万次的数据库,虽然是单表查询,但是也受不了,接下来是一个批量插入的语句,虽然仅仅打开了一次的数据库,但是数据量也是很大的啊。
改进办法1:
由于A接口传给我的是XML,能不能将XML直接扔在数据库中?也就是用存储过程将XML直接插入到库中,这种方法可行。
改进方法2:
datatable和xml插入到数据库的时间进行比较,还是datatable比较快,于是首先将XML转换为datatable,然后将整个不经过任何加工的datatable通过存储过程,给了数据库,然后在数据库中进行查询等操作。
首先,需要在数据库中添加表类型,也就是要传过来的数据的表的样子,结构要和传过来的表结构相同:
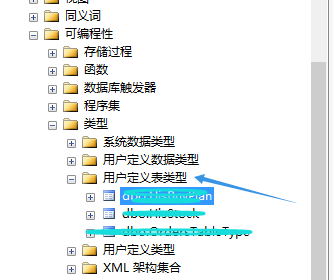
接下来就是我们的存储过程了,接受到了一个参数为table的,我们通过 update set from where in 的sql语句来写,很简单。
ALTER PROCEDURE [dbo].[TableTest]
(
@table [HisBuyPlan] READONLY
)
AS
update b set b.planNo = t.planNo ,b.planNumber=t.planNumber,b.companyCode=t.companyCode, b.drugCode=t.drugCode,b.approvePrice=t.approvePrice
from BuyPlanTest b , @table t
where t .planNo in (select b.BuyplanId from BuyPlanTes b)
insert into BuyPlanTest
select t.planNo, t.planNumber,t.companyCode,t.drugCode,t.approvePrice,t.drugDeptCode,t.operDate,t.planInsum
from @table t
where t.planNo not in (select b.BuyplanId from Buyplan b)就这样,测试成功后上线了。。。。。。















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









