








第一章 背景:机器人学习的“视觉困境”与突破
1.1 视觉数据的局限性
机器人通过观看人类动作学习执行任务时,传统方法依赖纯视觉输入。然而,许多精细操作(如轻握钥匙旋转、用力插入插头)的关键细节(如力控参数)无法被视觉捕捉。以拧瓶盖为例,视觉仅能记录手部移动轨迹,却无法感知手指施加的扭矩强度。
1.2 多模态数据的价值
人体肌肉活动与物体交互声成为破局关键。例如,肌肉电信号能反映指尖压力变化,而插头插入时的“咔嗒”声则暗示接触力度。这些信号填补了视觉缺失的信息维度,使机器人得以理解操作的“隐含规则”。
1.3 视觉语言模型(VLM)的进化
近期VLM(如Gemini)已具备处理长序列输入的能力,能够同时分析视频帧、音频波形和生物电信号。这一进展为多模态推理提供了技术基础。
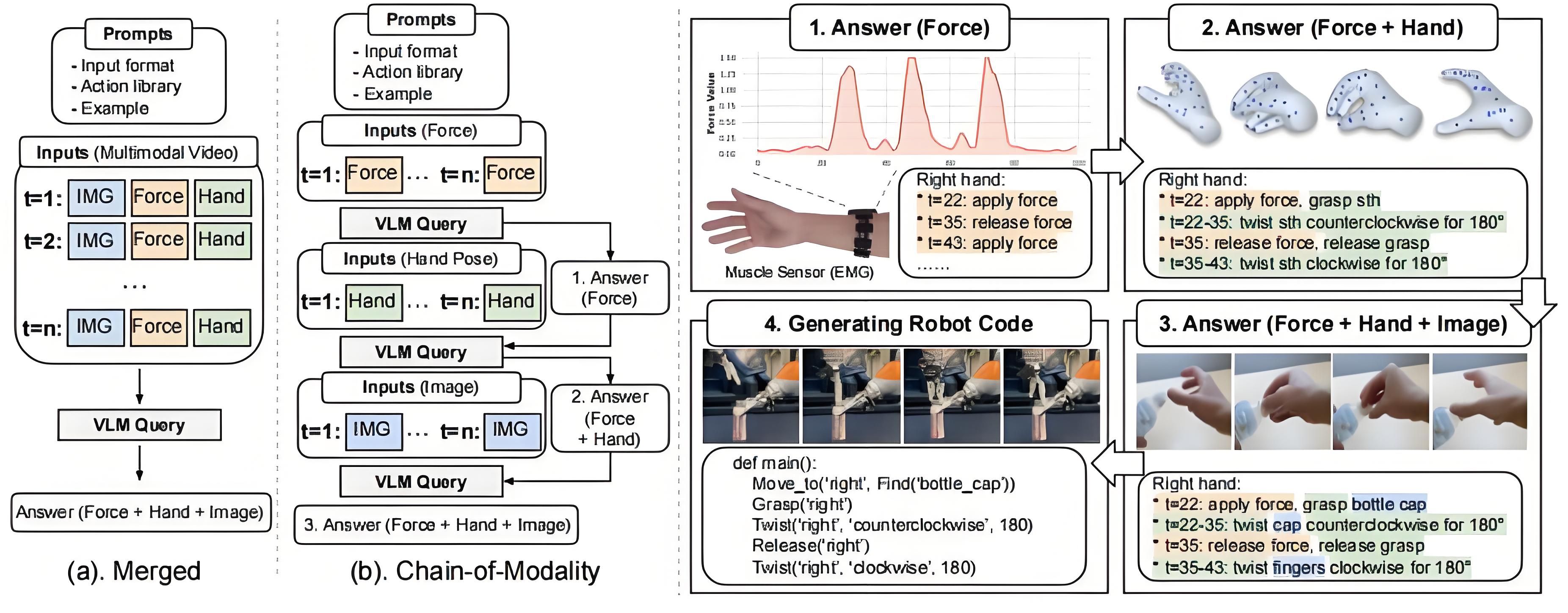
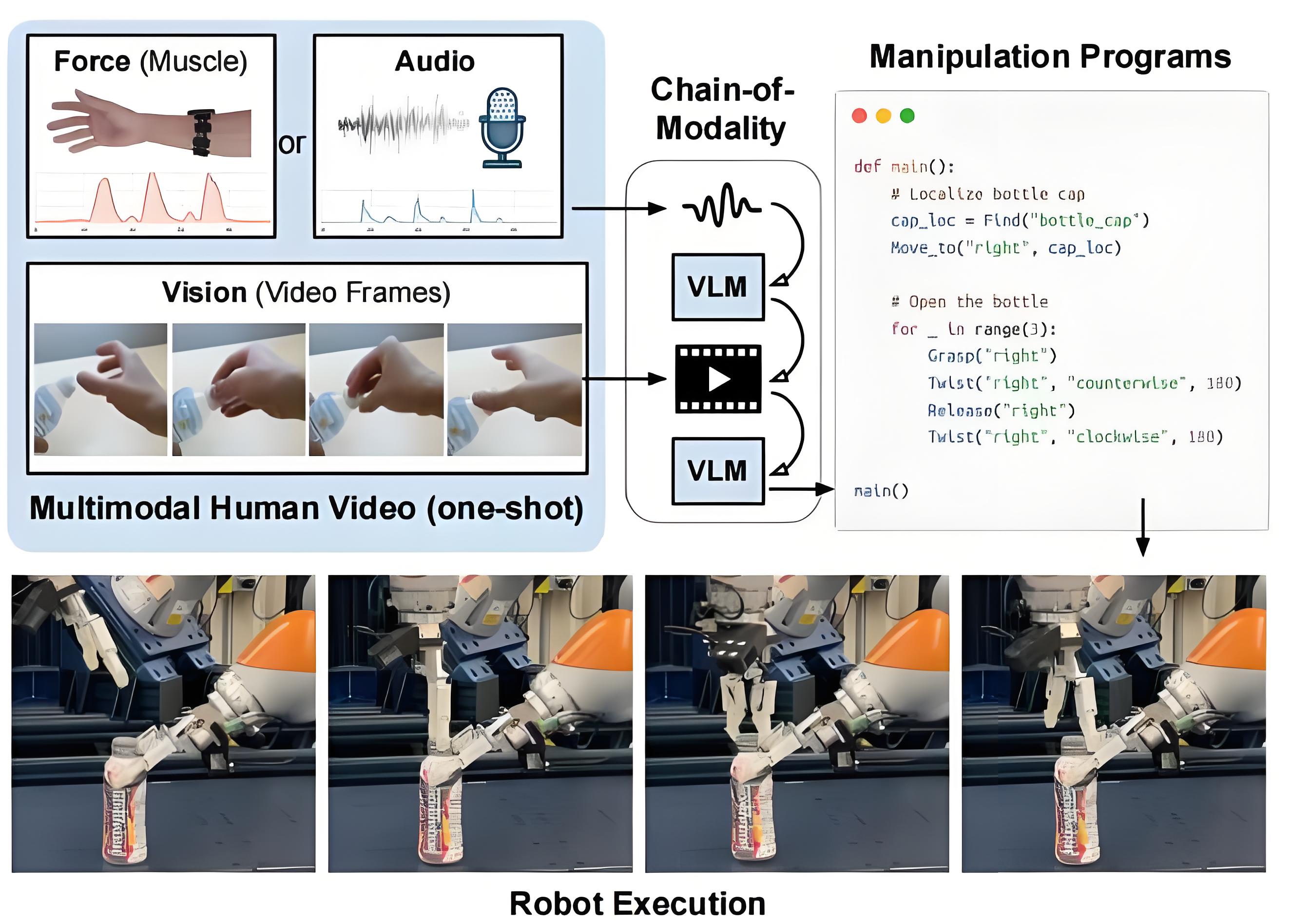
第二章 技术核心:模态链(CoM)的运作机制
2.1 多模态数据采集与预处理
- 硬件配置:佩戴式肌电传感器捕捉手臂肌肉活动,麦克风记录操作声,RGB相机同步拍摄动作视频。
- 数据对齐:通过时间戳将三类信号精确同步,形成时空一致的多模态流。
2.2 CoM的分层推理策略
2.2.1 视觉解析层
VLM首先分析视频帧,生成初步任务描述(如“左手握住瓶盖顺时针旋转”)。此时,视觉信息提供空间定位与动作序列框架。
2.2.2 力控增强层
结合肌电信号与音频特征,VLM修正初始判断。例如,当听到插头插入声时,模型自动关联“施加5N压力”的控制指令;若检测到肌肉紧张峰值,则推断需“短暂加大扭矩”。
2.2.3 综合决策层
整合三层信息后,CoM生成包含动作类型、参数及触发条件的完整程序。例如:
def open_bottle():
grasp('left_hand', 'bottle_neck', force=3N)
rotate(90°, torque=8Nm, duration=2s)

第三章 实验验证:从实验室到真实世界的跨越
3.1 对比实验设计
| 方法 | 视觉+肌电 | 视觉+音频 | CoM(全模态) |
|---|---|---|---|
| 任务计划准确率 | 65% | 68% | 92% |
| 控制参数误差 | ±15% | ±12% | ±5% |
3.2 真实场景测试案例
场景1:异形插头适配
- 人类演示者手持非标准三角插头插入插座,伴随金属摩擦声。
- CoM解析出“先倾斜45°预校准,再垂直施压”的复合动作,成功率达91%。
场景2:柔性材料处理
- 操作对象为硅胶密封圈,需轻柔拉伸。
- 肌电信号揭示手腕微调细节,最终完成度较基线方法提升3倍。
第四章 展望:具身智能的下一步
4.1 技术瓶颈与突破方向
- 闭环控制:当前方案基于开环执行,未来需引入触觉反馈实时调整参数。
- 多模态融合深度:探索脑电波等更高阶生理信号的集成可能性。
4.2 社会影响与伦理思考
- 工业领域:制造业流水线工人可快速训练协作机器人,缩短产线切换周期。
- 医疗辅助:康复训练师的动作示范可转化为外骨骼设备的控制指令。
- 隐私边界:需制定规范防止生物信号滥用,保障演示者的知情权。
模态链成就未来
模态链(CoM)通过系统性整合多模态数据,使机器人真正理解“怎么做”而非仅模仿“做了什么”。其200%的性能提升不仅是技术里程碑,更标志着AI正从“观察者”向“实践者”蜕变。未来,当机器人能像人类学徒般领悟操作精髓,我们将迎来人机协作的新纪元。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











