







HDFS读写流程分析
结合《Hadoop权威指南》 + Hadoop源码 + 《Hadoop 2.X HDFS源码剖析》,对HDFS读写流程和源代码做了总结
内容提要
- HDFS读写流程
- 源代码分析和真实生产环境debug案例
1. HDFS读流程
《Hadoop权威指南》:
HDFS读操作,一般是客户端通过RPC 调用namenode以确定问价按块起始位置,对于每一个块,namenode返回保存该块副本的datanode地址(返回结果具有优先顺序),客户端通过DistributedFileSystem返回的FSDataInputStream对象,调用read方法将数据从datanode传回客户端。
几点说明:
-
节点之间的通信协议
client/namenode/datanode之间的互动,轻量级的都是rpc方式,比如索取数据块地址,上报失效数据块,删除数据块等等。client/datanode之间互传数据,则是用基于TCP的流式接口。namenode和备用namenode之间用的是HTTP流式接口。 -
几个计量单位
block : 128MB datanode数据块的大小
packet : 64KB tcp传输的基本单位
chunk: 512Byte tcp传输数据校验的基本单位
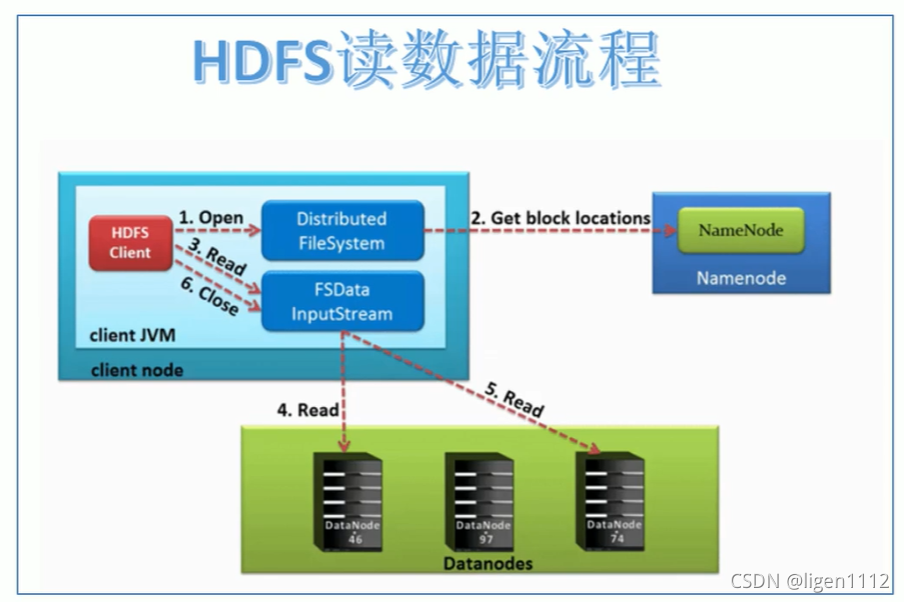
流程
- 客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 客户端挑选网络距离最近的一台DataNode服务器,请求读取数据。
- DataNode传输数据给客户端
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件
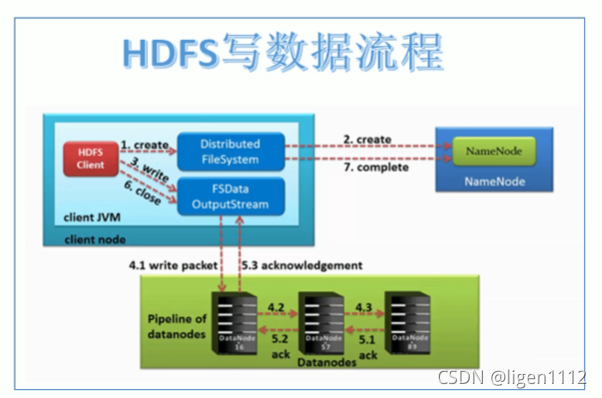
2. HDFS写流程
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
3. 读流程源码分析
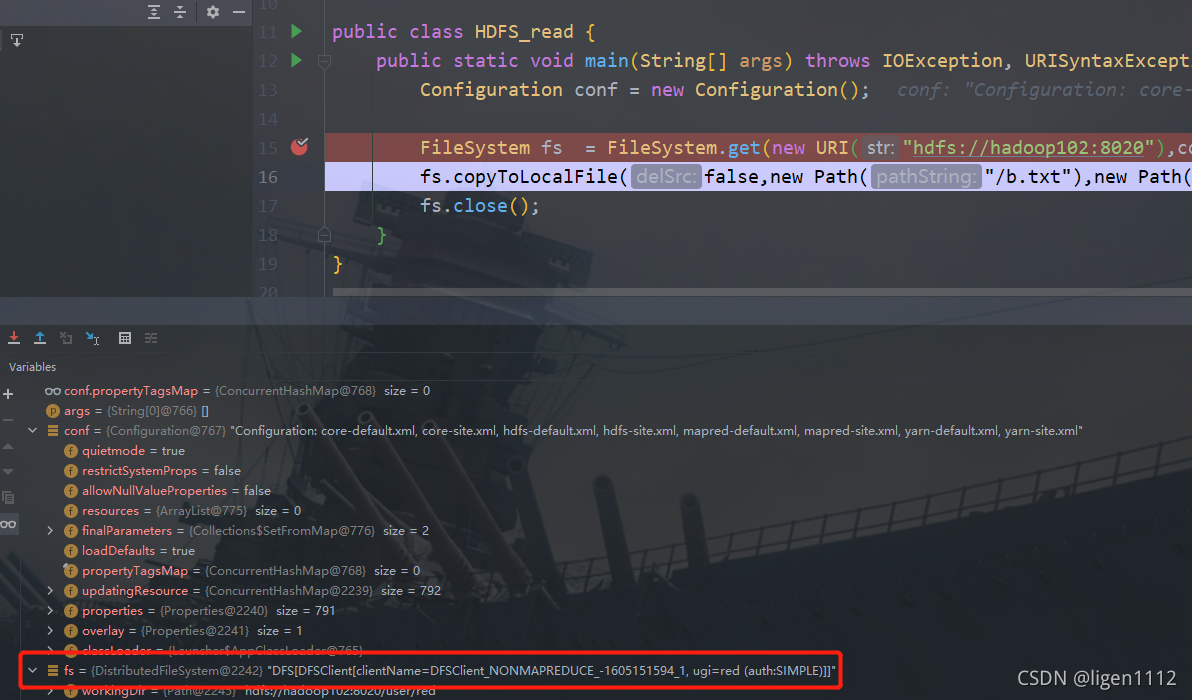
这是一段朴实无华的文件从HDFS下载到本地的客户端代码,既然是文件传输到本地,中间的copyToLocalFile方法里面必然包含读的逻辑,debug大法一步一步看
public class HDFS_read {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),conf,"red");
fs.copyToLocalFile(false,new Path("/b.txt"),new Path("E:\\b.txt"),true);
fs.close();
}
}
2.1 FileSystem的创建
- 这步通过用户的配置文件生成相应的文件系统
step1 :get方法进入首先读取kerberos认证缓存得到UserGroupInformation
step2 : 创建FileSystem的核心逻辑FileSystem的静态方法get
关键步骤注释写在代码中
public static FileSystem get(URI uri, Configuration conf) throws IOException {
//对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file,来源于用户自己输入的URI
String scheme = uri.getScheme();
//authority 是namenode的域名和端口号 hadoop102:8020
String authority = uri.getAuthority();
//如果没指定某些信息,就去conf里面找,再没有就用FileSystem默认的
if (scheme == null && authority == null) { // use default FS
return get(conf);
}
if (scheme != null && authority == null) { // no authority
URI defaultUri = getDefaultUri(conf);
if (scheme.equals(defaultUri.getScheme()) // if scheme matches default
&& defaultUri.getAuthority() != null) { // & default has authority
return get(defaultUri, conf); // return default
}
}
//这步挺有意思拼接好disableCacheName后去conf里面看看用户是否指定
String disableCacheName = String.format("fs.%s.impl.disable.cache", scheme);
if (conf.getBoolean(disableCacheName, false)) {
LOGGER.debug("Bypassing cache to create filesystem {}", uri);
return createFileSystem(uri, conf);
}
//去缓存中查看,没有就新建FileSystem 实例返回
return CACHE.get(uri, conf);
}
拓展案例
disableCacheName:fs.hdfs.impl.disable.cache相关真实案例,和上面源码有关值得一看
链接
再来个hive相关的
链接
2.2 fs.copyToLocalFile
转到FileUtil 的copy方法
in = srcFS.open(src);
out = dstFS.create(dst, overwrite);
IOUtils.copyBytes(in, out, conf, true);
open调用dfs的open得到FSInputStream,里面包裹着DFSInputStream
open调用localFS的create得到FSOutputStream,里面包裹着DFSInputStream
FSInputStream和FSOutputStream对接传输数据
dfs.open(getPathName(p), bufferSize, verifyChecksum);
DFSInputStream构建之前调用了getLocatedBlocks,得到了数据块的位置。这个位置的用clientprotocal 客户端rpc调用的namenode方法返回块信息(块信息按照距离客户端的网络距离排序了)
public DFSInputStream open(String src, int buffersize, boolean verifyChecksum)
throws IOException {
checkOpen();
// Get block info from namenode
try (TraceScope ignored = newPathTraceScope("newDFSInputStream", src)) {
LocatedBlocks locatedBlocks = getLocatedBlocks(src, 0);
return openInternal(locatedBlocks, src, verifyChecksum);
}
}
3. 写流程源码分析
这是一段朴实无华的向HDFS写文件的代码
public class HDFS_write {
public static void main(String[] args) throws IOException {
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop102:8020");
FileSystem fs = FileSystem.get(conf);
fs.copyFromLocalFile(false,true,new Path("E:\\b.txt"),new Path("/b.txt"));
}
}
写方法重点看下 dstFS.create(dst, overwrite)
在create中最终找到新建DFSOutputStream的方法,里面又新建了一个streamer
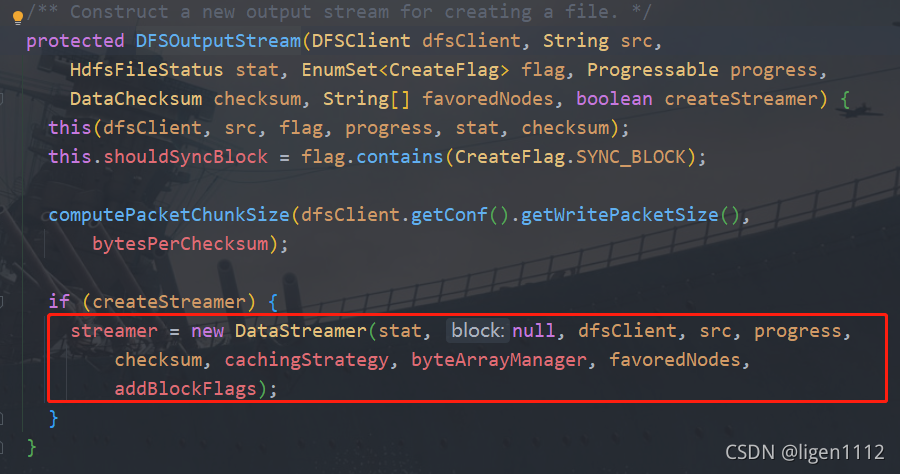
这个streamer继承了线程,然后启动起来了
streamer其实就是干活的
streamer 的dataQueue数据队列存放着写入的数据
streamer 的ackQueue数据队列存放着确认数据,收到datanode的确认信息后才会清空
从队列拿到packet
one = dataQueue.getFirst();
采用pipeline模式发送数据
setPipeline(nextBlockOutputStream());
initDataStreaming();
最终closeInternal方法清空dataQueue和ackQueue














 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









