







1.前言
想不想自己实现一下分布式的主从选举算法?reids,tidb,kafka主从协调都用到了raft一致性算法。mit6.824分布式系统的第二次作业lab2A就是用golang实现一个简易版的主从选举,本篇讲这个作业的实现,挺有趣的。可以做到在规定时间内选出leader,leader挂掉后选出新的leader,挂掉的leader,follower重新加入集群后不影响现在的leader。
听着简单,真要自己实现就复杂了。所有规则在raft论文里面都说了,一板一眼的复现就能通过作业,但是只有在自己踩坑一步一步填上的过程才能体会论文里面规则的意义。
raft论文地址
https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
lab2A作业描述地址
https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
从第一步到最后通过所有测试,我记了个流水账,把一些关键思考步骤通过示意图/要点总结了。我的做法是把论文的规则拆解成自己能理解的人话,然后写到代码当成提示一步步复现,比如这样

- 任务总览
- 你讲要建立一个可容错的kv存储系统。复现raft。
- 一个复制服务可以通过在多个服务器储存数据保持容错。一些节点挂了照样能提供服务。最大的挑战是失效会造成副本的数据不一致。
- raft将客户端的请求弄成一个序列(log),并且确保所有副本看到相同的log。每个副本按照log顺序执行任务。一个副本失效后又恢复,raft给他安排上,让他尽快恢复正常进度。只要集群内布大部分server存活且互相通信畅通,raft就能工作。
- 在这个作业中,raft实例通过rpc通信来复制log。你的raft实例需要支持一系列含有数字的命令(log entries)。entries通过index number标记。带有特定index的日志会最终提交,你的raft需要传送出去这个log。
- 特别看下raft论文的第二章。
- src/raft/raft.go 提供了一个骨架,还有一些测试 src/raft/test_test.go
你的复现需要能满足如下接口
// create a new Raft server instance:
rf := Make(peers, me, persister, applyCh)
// start agreement on a new log entry:
rf.Start(command interface{}) (index, term, isleader)
// ask a Raft for its current term, and whether it thinks it is leader
rf.GetState() (term, isLeader)
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester).
type ApplyMsg
Make(peers,me …) 建造raft peer。
peer是 用rpc通信的"节点"
me是 peer的序号
Start是raft开始处理进来的log
需要发送ApplyMsg 来处理每个新到channel的log
-
raft.go有发送rpc的样例代码sendRequestVote()。 处理接收到的rpc的RequestVote()。raft peers应该用src/labrpc交换rpc
-
tester可以让labrpc延迟rpc,重排序,彻底干掉模拟断网, 最终要保持labrpc原样
-
raft实例只能通过rpc通信,不能用共享文件之类的
- lab2A 的提示
复现raft leader选举和心跳(没有数据的 AppendEntries rpc请求)。这个lab2A的目标是选出leader,leader挂掉或者断网后新的leader上位
提示
- 不能直接运行raft,要通过tester go test -run 2A -race
- 根据第二章,收发选举rpc和状态
- raft.go的ruft struct中添加leader election的状态,还要定义一个struct来存储log长度
- RequestVoteArgs 和RequestVoteReply中的create 方法创造后台线程,该goroutine将在有一段时间没有收到其他对等方的消息时,通过发送RequestVote RPC定期启动领导人选举。通过这种方式,peer将了解谁是leader,或者自己成为leader。实现RequestVote()RPC处理程序,以便服务器可以相互投票。
- 为了实现心跳,定义一个 AppendEntries rpc struct,让leader定期发送出去,这个也可以用在已经选好leader的情况下,让别的peeer不再去搞选举。
- 选举超时不要在相同时间触发,不然所有peer都给自己投票了
- tester要求leader一秒钟内不要发送超过十次心跳
- tester要求raft在老leader挂掉5秒内选出leader,如果出现瓜分选票,领导人选举可能需要多轮投票(如果数据包丢失或候选人不幸选择了相同的随机退避时间,则可能会发生这种情况)。必须选择足够短的选举超时(以及心跳间隔),即使需要多轮投票,选举也很可能在不到五秒钟内完成。
- 5.2章说选举超时时间在150到300毫秒之间。只有当领导者发送心跳的频率远远超过每150毫秒一次时,这样的范围才有意义。由于测试仪将您的心跳限制为每秒10次,因此您必须使用大于纸张的150到300毫秒的选举超时,但不能太大,因为这样您可能无法在5秒钟内选举领导人
- 需要编写定期或延迟后执行操作的代码。最简单的方法是创建一个goroutine,其中包含一个调用时间的循环。sleep();(请参见Make()为此创建的ticker()goroutine)。不要用time.Timer或者time.ticker
- rpc只发送首字母是大写的struct,子struct也要大写
- 作业实现历程
4.1 先把lab2A结构看懂
先把代码结构看懂,在raft的make方法里面起了一个守护线程ticker,在ticker里面随便打印下东西然后运行go test -run 2A 感受感受三个raft分别在打印自己ticker里面的东西。(别在make方法构造里面尝试选举,我一开始犯了这个错误)
咱先看看ticker函数干啥的,上面有注释"start ticker goroutine to start elections",写个句子打印下当前raft对象的编号属性,看到不断打印每个raft的编号,构造了三个,012来回打印,然后测试失败,因为啥也没做呢。

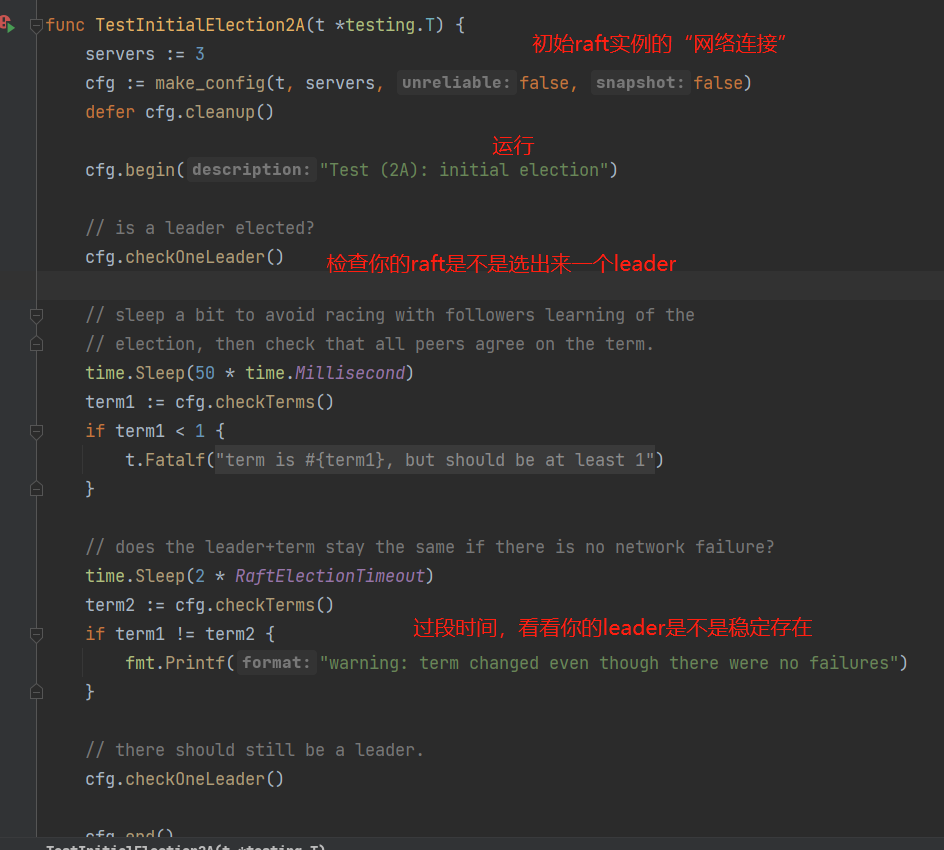
再看下测试test_test.go里面的TestInitialElection2A是怎么考察你的raft的,后面几个测试就是模拟更多情况看你的选举能否经受考验,大同小异。
心里有数了,需要在ticker里面搞事情。其实你指定第一个raft实例直接当leader就能过第一个测试,但是这样显然在别的测试情况就凉了,按照raft论文来,拆解下选举的流程和思路才是正道。
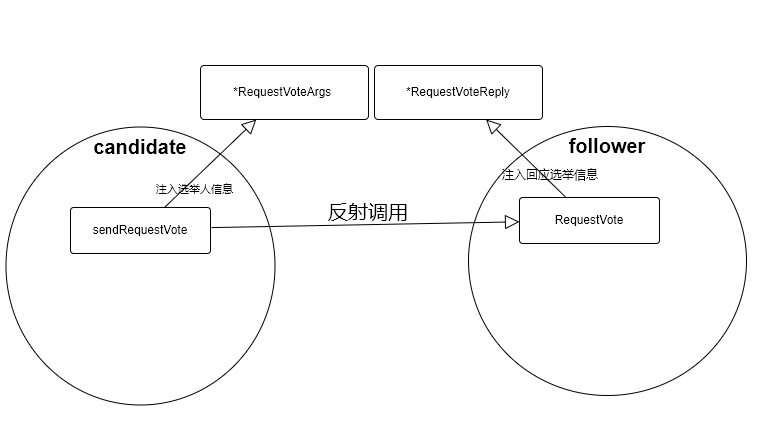
raft之间是怎么联系的,有了lab1的经验,知道sendRequestVote通过反射调用另一个raft的方法
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
做了一个示意图,可以看下,官方作业封装了一堆功能对raft,raft之间的连接进行各种操作来模拟现实环境的网络partition,机器挂掉等等情况,还实现了检查你的raft系统里面主从状态的函数。面向测试用例编程。
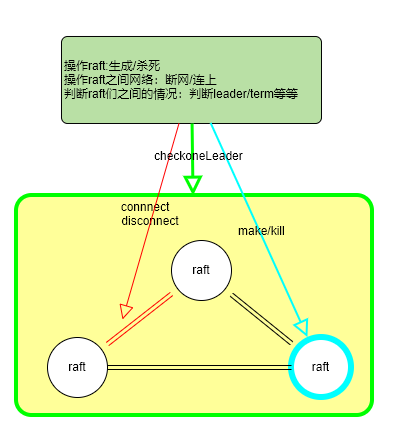
4.2 缕一缕选举思路
翻译下论文,看看咋选举的
leader选举细节
raft用心跳出发选举。当服务器启动时会初始化为follower。只要它们能够收到来自leader或者candidate的有效 RPC,服务器会一直保持follower的状态。leader会向所有follower周期性发送心跳(heartbeat,不带有任何日志条目的 AppendEntries RPC)来保证leader地位。如果一个追随者在一个周期内没有收到心跳信息,就叫做选举超时(election timeout),然后它就会假定没有可用的领导人并且开始一次选举来选出一个新的leader。
为了开始选举,follower会自增它的当前任期并且转换状态为candidate,给自己投票并且给集群中的其他服务器发送 RequestVote RPC。一个候选人会一直处于该状态,直到下列三种情形之一发生:
- 赢得了选举;
- 另一台服务器赢得了选举;
- 一段时间后没有任何一台服务器赢得了选举
(赢得了选举) 一个candidate在任期内收到了来自集群中大多数服务器的投票就会赢得选举。然后它会像其他服务器发送心跳信息来建立自己的领导地位并且阻止新的选举。
(另一台服务器宣称胜选) 当一个candidate等待别人的选票时,它有可能会收到来自其他服务器发来的声明其为领导人的 AppendEntries RPC。如果这个领导人的任期(包含在它的 RPC 中)比当前候选人的当前任期要大,则候选人认为该领导人合法,并且转换自己的状态为追随者。如果在这个 RPC 中的任期小于候选人的当前任期,则候选人会拒绝此次 RPC, 继续保持候选人状态。
(一段时间后没有任何一台服务器赢得了选举) 如果许多追随者在同一时刻都成为了候选人,选票会被分散,可能没有候选人能获得大多数的选票。当这种情形发生时,每一个候选人都会超时,并且通过自增任期号和发起另一轮 RequestVote RPC 来开始新的选举。然而,如果没有其它手段来分配选票的话,这种情形可能会无限的重复下去。Raft 使用随机的选举超时时间来确保这情况很少发生,并且能够快速解决。为了防止在一开始是选票就被瓜分,选举超时时间是在一个固定的间隔内随机出来的(例如,150~300ms)。这种机制使得在大多数情况下只有一个服务器会率先超时,它会在其它服务器超时之前赢得选举并且向其它服务器发送心跳信息。
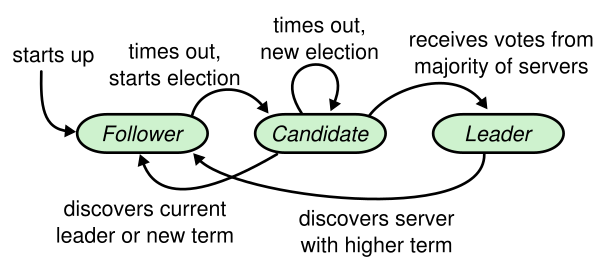
首先raft三种状态:follower,candidate,leader。按照上面的状态转换,妥妥实现选举。
4.3 随机超时的实现
先整个小目标:开局三个follower,超时变candidate
论文提示了,每个raft都投自己一票,每个人都手握一票那没有获胜者,因此要随机超时。随机超时需要raft在一变身follower时候,在当前时间戳随机加一个时间得到超时时间,ticker线程不断检查是否到期,到期就打印下。
- 给raft加状态属性(follower,candidate,leader),make方法指定开局是follower
- 给raft加 下一个超时时间戳属性
论文说
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)
所以选举拉票要比超时时间小很多才能稳定选举,否则票还没拉就超时了。分布式主从一般都是rpc心跳互相感知。在raft似乎心跳和后面的日志请求是一起发送的,也就是选举拉票是借着心跳实现的。
关于这个超时时间的设置,看了下,test_test.go,里面指定的选举超时是
const RaftElectionTimeout = 1000 * time.Millisecond
也就是说1秒内得选出来,心跳时间(一次拉票时间)也不能太长,设计个50毫秒。
raft初始化时候,需要指定一个随机时间点赋值给下一个超时时间戳属性,弄成raft的一个方法,方便后面复用
ticker打印 rf.me, 状态,下次超时时间,判断是否超时,超时了打印出来,可以看到三个raft超时时间各不相同,小目标实现
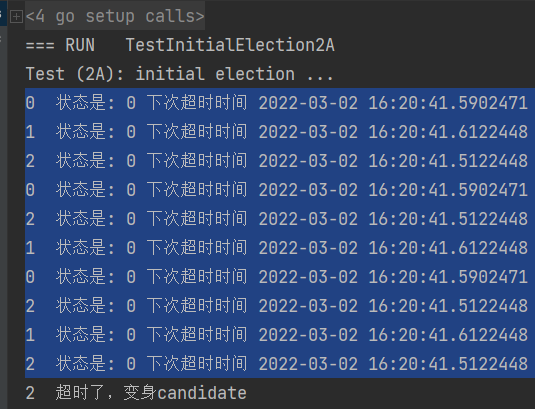
4.4 candidate拉票
再整个小目标:candidate拉票,变成leader
最先超时的follower变candidate马上投自己一票,为了抢在别的follower之前变成leader,需要马上轮询其他raft要选票,3个raft拿到2票就算皿煮当选。想了下,不能raft直接去操作另一个raft的某种属性,一定要发送接收这种双向的,因为需要判断拉票得票合法性,raft的世界是个迷雾丛林,你不知道发来消息的节点是僵尸还是队友。
试想一个情景:一堆raft都选好主从了,有一个raft,我们叫他 小丑A ,机器不给力,在上一轮变candidate时候突然死机,很久才活过来,才发出来拉票请求,这个过时的rpc不能影响整个系统
怎么判断rpc是否合法呢,论文用term 任期来分辨。
所以大概这个rpc的信息至少要包含
是否是拉票(拉票和日志请求共用心跳,需要跟日志请求区别下),我是谁,我任期
rpc去反射回复者做出选择,回复者要判断这人值不值得我投出手上这票
回复者是个follower
这人任期比我小不行,落后节点干扰,拒绝他
这人任期跟我一样,我要是没投票赶紧投他,我们这届的选举人,如果票已经投了别人就拒绝他
这人任期比我大,这是个强者,不管有没有投过,给他投票,任期看齐他
回复者是个candidate/leader
这人任期不比我大,拒绝他
这人任期比我大,小丑竟是我自己,投票+自己退化成follower+任期看齐他
想一下 小丑A,他落后于系统,不但不能干扰选举,还得自觉变成follower,他咋知道自己落后于时代?一个办法就是他去拉票,得到的回复包含了更大的任期(理所当然拉票被拒绝)
因此回复者的回复rpc的信息要包含
我给不给你投票
我任期号,帮助落后者意识到自己落后了
最后,回复者反射调用得票者,得票者还得判断一波
任期和我一样,给我投票,我的票数+1
任期比我小,是个落后者,我不能得这票
得落后者这一票目前没想明白会有什么隐患,暂且设计不得
每受到回复者的回复后,检查下自己是否得票超过半数,过半就当选leader
发现这些角色互相转化代码可以简化
照着上面的做好,运行程序
打印【raft编号】 状态是:xx term 是 xx
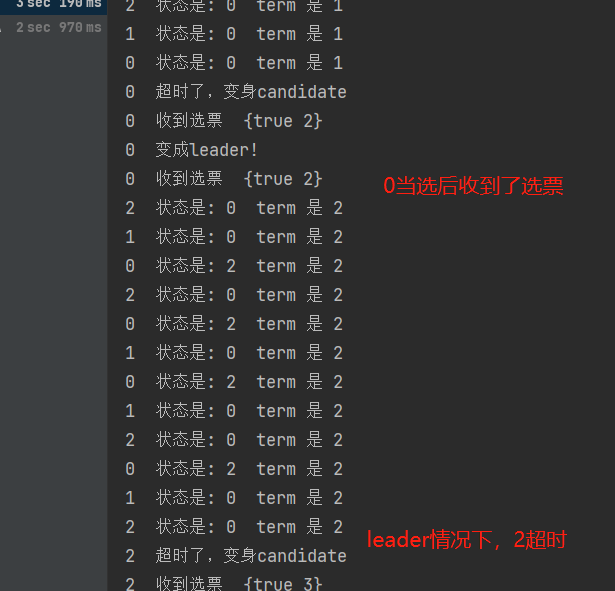
问题出现在0当选后,2还超时选举了,为了解决这个问题,需要让0当选后发送心跳压制蠢蠢欲动的peers告诉他们谁才是当期term的老大。
leader发送的压制心跳
我的任期
我的号
raft peer 收到心跳
我的任期<=对方任期, 对方是强leader,term看齐,投票votedFor记对方,变follower
我的任期>对方任期,不用理会
再次运行,发现当选后压制住了follower,稳定的leader了,小目标达成,2A的第一个测试通过了。
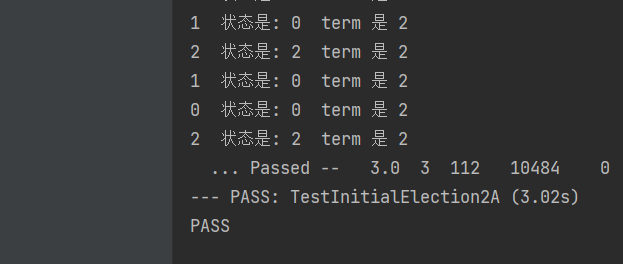
4.5 2A第二个第三个测试
第二个测试看下,是选举后干掉leader,看看能不能选出新的。再leader回归,不会影响其他成员且老leader退化成follower,再干掉大多数测试是否还有leader,为了看得更清楚加点注释。第三个是起了一堆server。
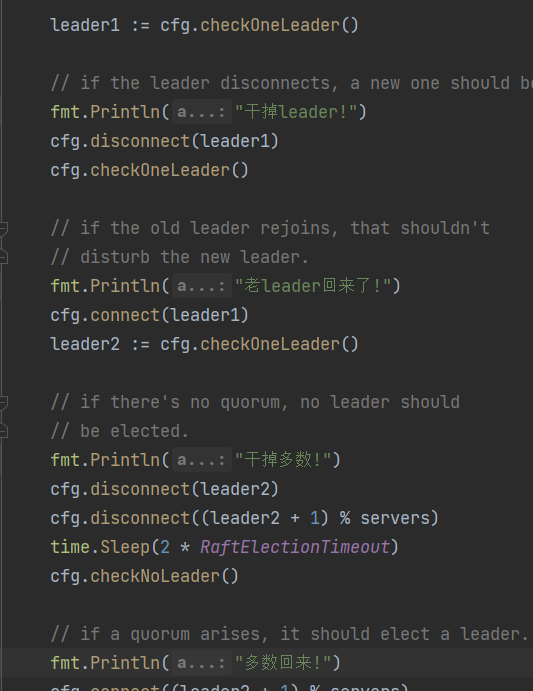
呃,因为前面考虑的比较全面,居然都通过了。
坑1:2A第二个测试,因为raft下线导致的卡住问题
无论是选举还是压制心跳,都是轮询模式,如果不再单独起一个线程,会卡住的。
for serverId := range rf.peers {
if serverId != rf.me {
go rf.candidateRequestVote(serverId, &arg, &voteCount)
}
}
坑2:2A第二个测试,回调函数
另外也要善用那个回调函数。一开始我踩的坑就是起一个线程,并不知道结果和时返回,我直接sleep两秒,等那个结果。可想而知这个不可行的。最后发现回调函数能很好达到"通知"效果。
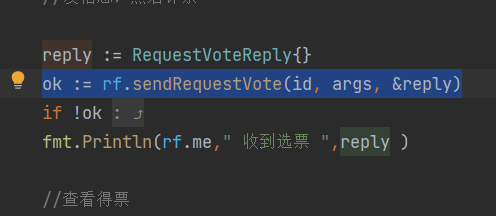
4.6 并发问题
直接点test_test.go里面的运行没任何问题,但是运行 go test -run 2A -race,会发现有data race。
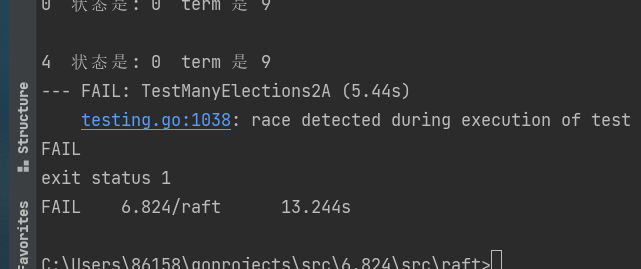
这个在之前看打出来的信息早有预感有问题,比如这里,2在一个任期居然投票了两个人,也就是votedFor=-1时候进来两个投票请求
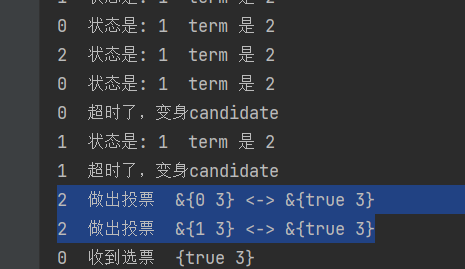
比如这里,投票的重置超时和ticker的读发生data race
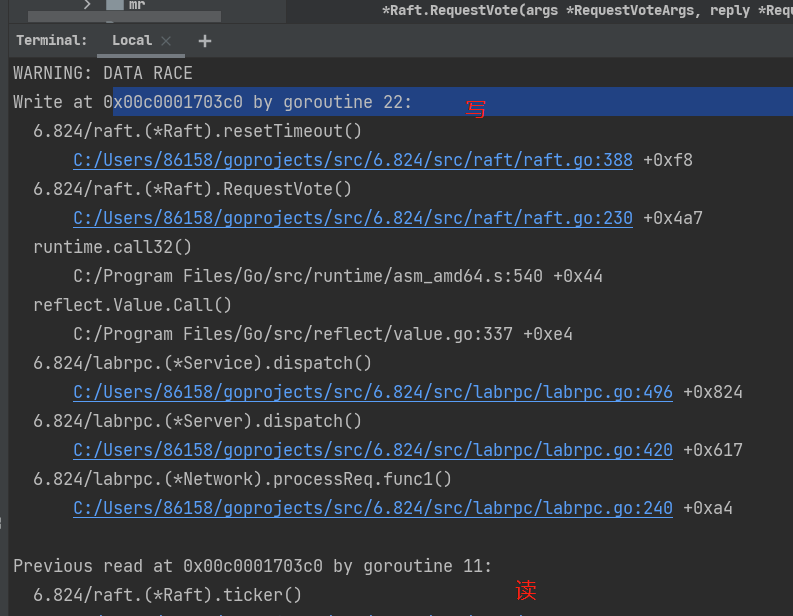
经过一番折腾,终于通过实验
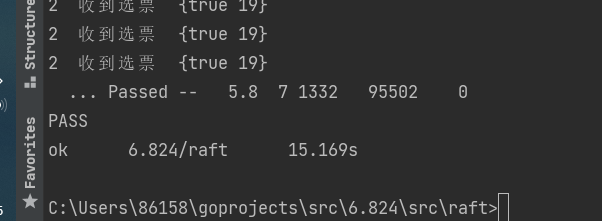
说实话对并发不太了解,就是看data race报错定位各个读写发生在同时的问题。ticker,getState各种和选举中的修改属性的反射方法和主线程的自身属性写入冲突。appendEntry和candidateRequestVote这样的,直接给raft上锁。一口气各种乱上会死锁,看着报错一步步调过了,不像别的大佬写的时候心里就有数。(我代码是通过的,但这块我讲不太清楚,就不乱讲了)。














 6603
6603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









