









币小站日志3–简单爬虫第一步,下载网页,然后分析
前言
我的《币小站》上线具体已经一周有余了,来记录下当前网站的状态。
根据统计显示
- 1、这个网站目前基本没有人访问(本周浏览量438,ip数18,我虽然屏蔽了自己的ip,但我估计大量的浏览量还是我自己访问的,尴尬。。。)
- 2、github的地址基本也没人访问(本周一共6个clone,这么烂的才学的技术,没人来访问也是正常的)
- 3、这些重要么?重要。。。这算是虚荣心作祟吧。
中间遇到了许多困难,到现在也没完全解决,但是我相信会越做越好的,今天先来记录下这个网站内容来源:爬虫,是怎么做的。
前置知识
我在做该网站之前的职业是,我是c++程序员,写过mfc,linux驱动,写过qt应用,在工业自动化领域和监控摄像头领域耕耘了7,8年了,现在开始做互联网相关的东东,基础算是比较薄弱的。在写这个网站的爬虫之前,我只知道爬虫就是把网页源码下载下来,然后分析里面的词。
我所使用的爬虫以及工具
- python3
- urllib
- PyQuery
- jieba
关于python3
python3在网上资料特别多,语法也不难,所以如果有经验的程序员,应该看1,2个小时就可以开始上手写了。在这里我只想介绍一个python3对于c++程序员的一个巨坑,就是c++所有的=符号都是传递的所指向对象的地址,有点类似于c++的智能指针。而不是我所熟悉的按值传递。例如
#对于列表这种复杂点的对象
a=[1,2,3,4]
b=a
#此时a的值为[1, 2, 3, 4]
#此时b的值为[1, 2, 3, 4]
a[0]=10
#此时a的值为[10, 2, 3, 4]
#此时b的值为[10, 2, 3, 4]
#=========================
#对于普通数字这种对象
x=10
y=10
#此时x的值为10
#此时y的值为10
x=20
#此时x的值为20
#此时y的值为10
关于urllib
这是一个内置在python3中很强的能够爬取网页内容的库
先写一个简单的示例,来爬取我的《B小站》在github页面的中的描述文字
如下图所示
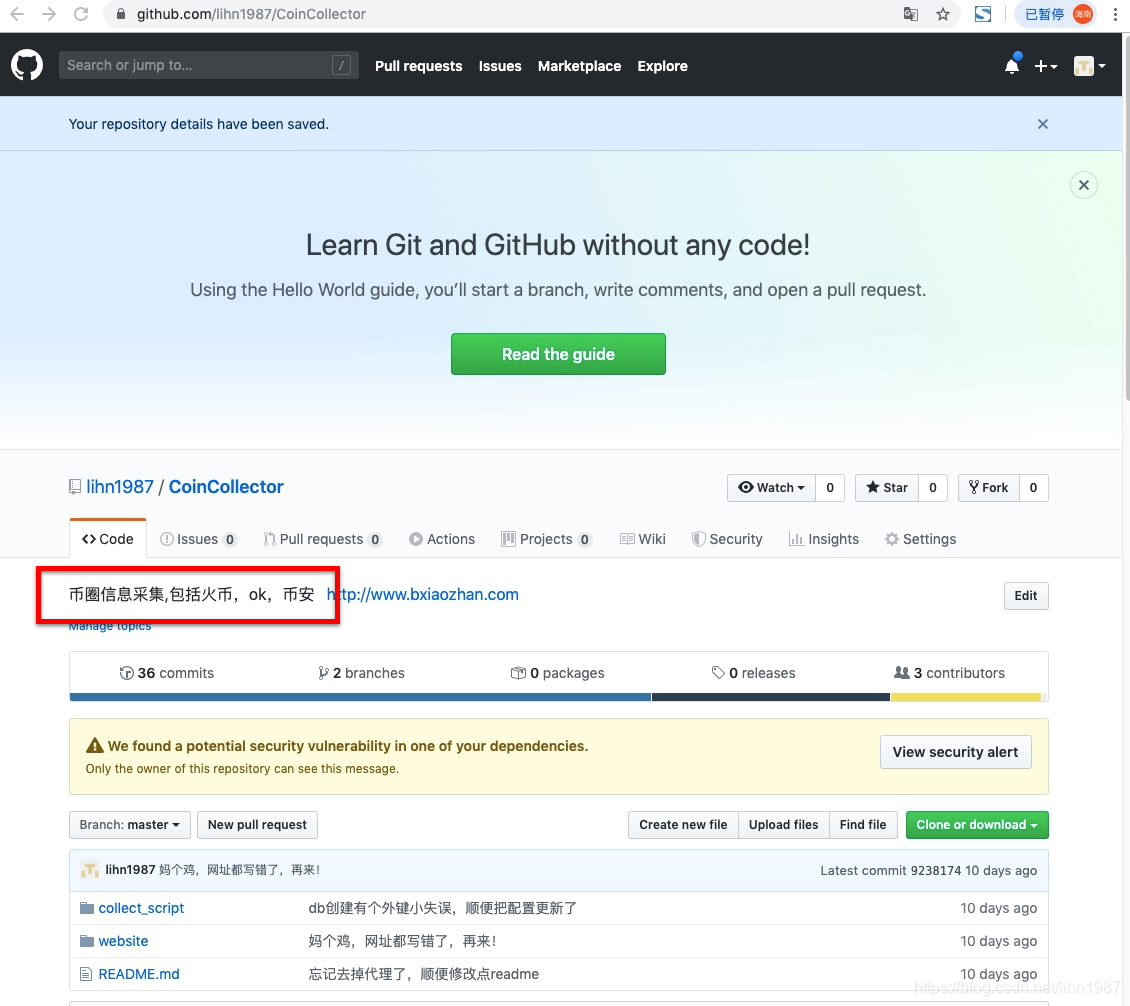
那么这里第一步我么需要利用urllib将该页面的源码先爬取下来,然后在进行分析。
由于该网站位于https://github.com/lihn1987/CoinCollector
所以我们的代码这样写
#首先导入库
import urllib.request
#使用urllib将网页源码抓取下来
response = urllib.request.urlopen("https://github.com/lihn1987/CoinCollector").read().decode('utf-8')
#打印网页源码
print(response)
输出的结果是类似于这样的一段
<!-- 这上面有好多好多的东东,这里就省略补贴出来了 -->
<span class="text-gray-dark mr-2" itemprop="about">
币圈信息采集,包括火币,ok,币安
</span>
<!-- 这下面也有好多好多的东东这里就不贴出来了,这里就省略补贴出来了 -->
可以发现被
<span class="text-gray-dark mr-2" itemprop="about">
和
</span>
夹着的一段内容就是我们想要的,于是既然我们拿到了字符串就可以对其进行分析了
先查找到<span class="text-gray-dark mr-2" itemprop="about">在网页源码中的位置,在查找</span>在网页源码中的位置,中间的就是我们要爬取的数据了!
于是有了以下代码
#首先导入库
import urllib.request
#使用urllib将网页源码抓取下来
response = urllib.request.urlopen("https://github.com/lihn1987/CoinCollector").read().decode('utf-8')
#设置两个标记字符串,用于定位要查找字符串的位置
flag1 = '<span class="text-gray-dark mr-2" itemprop="about">'
flag2 = '</span>'
#找到标记字符串所处的位置
index1 = response.index(flag1)+len(flag1)
index2 = response.index(flag2, index1)
#从网页源码中解析出要查找的字符串
result=response[index1:index2]
#打印爬取出的字符串
print(result)
至此,顺利爬出
币圈信息采集,包括火币,ok,币安的信息
总结
虽然能够找出来,但是~~~~~
- 这方法是不是太笨了?
- github不稳定,偶尔采集失败怎么办?
下次博客再写!
博客中所说的币小站的地址位于http://www.bxiaozhan.com
github地址位于https://github.com/lihn1987/CoinCollector














 3896
3896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









