










第一章:人工智能之不同数据类型及其特点梳理
第二章:自然语言处理(NLP):文本向量化从文字到数字的原理
第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)
第四章:循环神经网络RNN、LSTM以及GRU 对比(附代码)
第五章:理解Seq2Seq的工作机制与应用场景中英互译(附代码)
第六章:深度学习架构Seq2Seq-添加并理解注意力机制(一)
第七章:深度学习架构Seq2Seq-添加并理解注意力机制(二)
第八章:深度学习模型Transformer初步认识整体架构
第九章:深度学习模型Transformer核心组件—自注意力机制
第十章:理解梯度下降、链式法则、梯度消失/爆炸
第十一章:Transformer核心组件—残差连接与层归一化
第十二章:Transformer核心组件—位置编码
第十三章:Transformer核心组件—前馈网络FFN
第十四章:深度学习模型Transformer 手写核心架构一
第十五章:深度学习模型Transformer 手写核心架构二
一、位置编码简介
在Transformer模型中,位置编码(Positional Encoding)的作用是为序列中的每个位置提供独特的位置信息,以弥补自注意力机制本身不具备的位置感知能力。
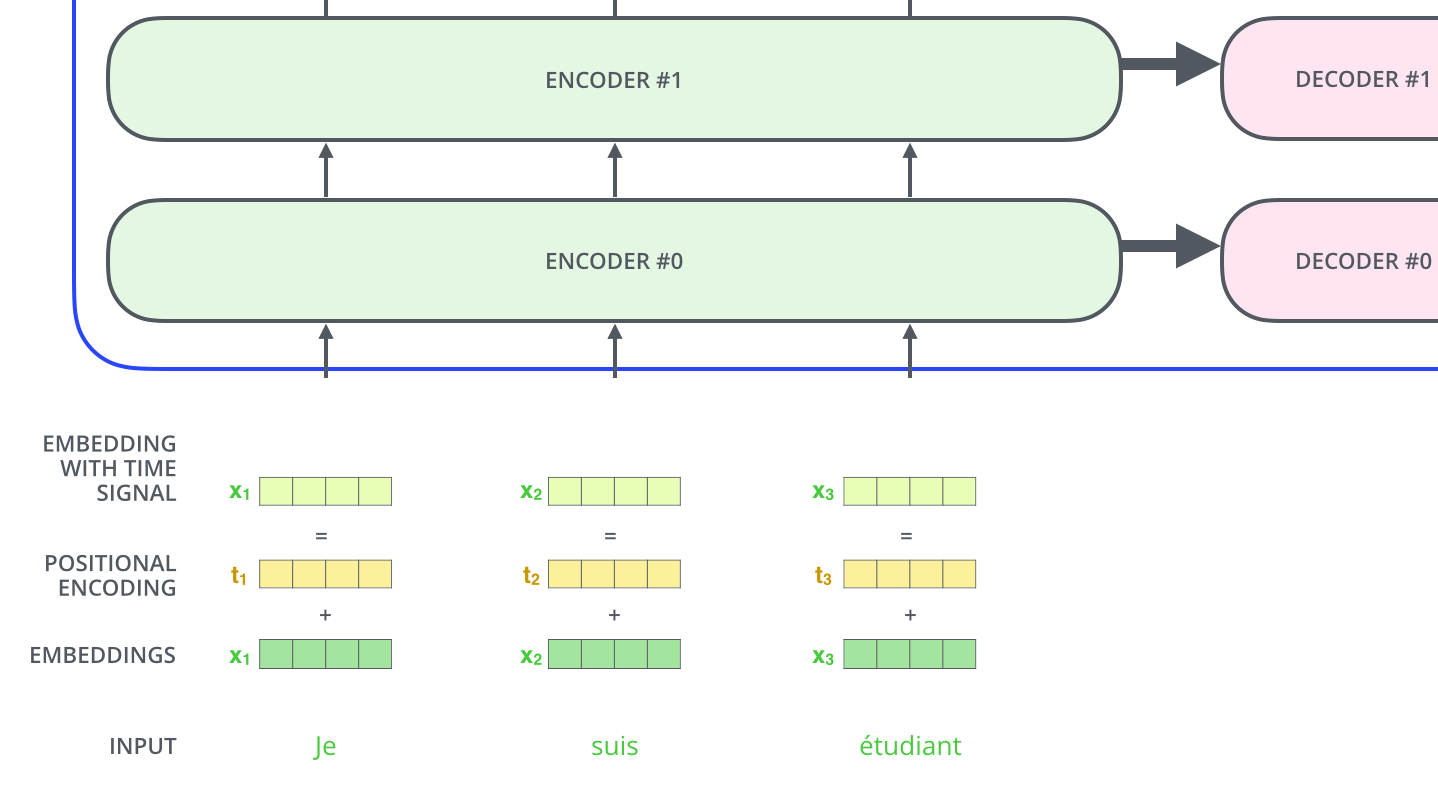
如上图所示,首先把输入向量,通过 embedding 生成词向量,接着把词向量和位置编码 positional encoding相加,生成一个新的带有位置的向量,通过这种方式添加位置编码,模型能够更好地理解每个词在其序列中的位置信息,从而更准确地处理和生成具有正确语法和语义的输出。这使得即使是在无序的自注意力机制中,也能有效捕捉序列中的顺序关系。
假设嵌入的维度是4,那么实际的位置编码将会看起来像这样:
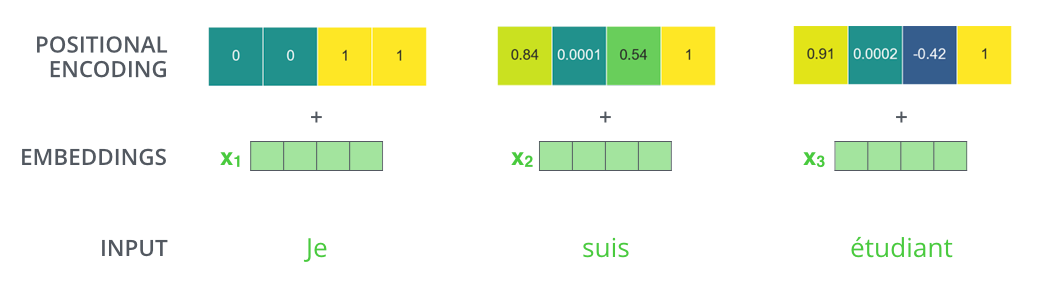
二、为什么需要位置编码?
-
自注意力的缺陷:
- 自注意力机制通过计算词与词之间的相关性来捕捉上下文,但它本身无法区分词序。
- 例如,句子“猫追老鼠”和“老鼠追猫”的语义完全不同,但若无位置信息,自注意力无法区分这两种顺序。
-
位置编码的意义:
- 为每个词的位置生成唯一的编码,使模型能够感知词序。
- 将位置编码与词嵌入(Word Embedding)相加,作为模型的输入。
示例数据
使用具体的句子来说明自注意力机制在没有位置编码的情况下为什么不具备位置感知能力。使用句子“我喜欢猫”。
假设我们有以下词嵌入向量(这些数值是随意设定的,用于示例):
- “我”的词嵌入向量: E 我 = [ 0.1 , 0.2 , 0.3 ] E_{\text{我}} = [0.1, 0.2, 0.3] E我=[0.1,0.2,0.3]
- “喜欢”的词嵌入向量: E 喜欢 = [ 0.4 , 0.5 , 0.6 ] E_{\text{喜欢}} = [0.4, 0.5, 0.6] E喜欢=[0.4,0.5,0.6]
- “猫”的词嵌入向量: E 猫 = [ 0.7 , 0.8 , 0.9 ] E_{\text{猫}} = [0.7, 0.8, 0.9] E猫=[0.7,0.8,0.9]
因此,对于输入序列“我喜欢猫”,其对应的词嵌入矩阵 X X X 是:
X = [ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 ] X = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \end{bmatrix} X= 0.10.40.70.20.50.80.30.60.9
自注意力机制计算
在自注意力机制中,首先需要通过线性变换得到查询 Q Q Q、键 K K K和值 V V V向量。假设这些变换矩阵 W Q W_Q WQ, W K W_K WK, 和 W V W_V WV 是相同的,并且为了简化,我们也使用同样的数值:
W Q = W K = W V = [ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 ] W_Q = W_K = W_V = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \end{bmatrix} WQ=WK=WV= 0.10.40.70.20.50.80.30.60.9
接下来,我们计算 Q Q Q, K K K, 和 V V V:
Q
=
X
W
Q
=
[
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
]
[
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
]
Q = XW_Q = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \end{bmatrix} \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \end{bmatrix}
Q=XWQ=
0.10.40.70.20.50.80.30.60.9
0.10.40.70.20.50.80.30.60.9
=
[
0.3
0.38
0.46
0.6
0.77
0.94
0.9
1.16
1.33
]
= \begin{bmatrix} 0.3 & 0.38 & 0.46 \\ 0.6 & 0.77 & 0.94 \\ 0.9 & 1.16 & 1.33 \end{bmatrix}
=
0.30.60.90.380.771.160.460.941.33
类似地, K K K 和 V V V 的计算结果与 Q Q Q 相同,因为 W Q W_Q WQ, W K W_K WK, 和 W V W_V WV 相同。
计算注意力得分
接下来,我们计算注意力得分 Q K ⊤ QK^\top QK⊤:
Q K ⊤ = [ 0.3 0.38 0.46 0.6 0.77 0.94 0.9 1.16 1.33 ] [ 0.3 0.6 0.9 0.38 0.77 1.16 0.46 0.94 1.33 ] QK^\top = \begin{bmatrix} 0.3 & 0.38 & 0.46 \\ 0.6 & 0.77 & 0.94 \\ 0.9 & 1.16 & 1.33 \end{bmatrix} \begin{bmatrix} 0.3 & 0.6 & 0.9 \\ 0.38 & 0.77 & 1.16 \\ 0.46 & 0.94 & 1.33 \end{bmatrix} QK⊤= 0.30.60.90.380.771.160.460.941.33 0.30.380.460.60.770.940.91.161.33
Q K ⊤ = [ 0.34 0.68 1.02 0.68 1.36 2.04 1.02 2.04 3.06 ] QK^\top = \begin{bmatrix} 0.34 & 0.68 & 1.02 \\ 0.68 & 1.36 & 2.04 \\ 1.02 & 2.04 & 3.06 \end{bmatrix} QK⊤= 0.340.681.020.681.362.041.022.043.06
应用Softmax函数到每一行上,得到注意力权重矩阵:
softmax ( Q K ⊤ ) ≈ [ 0.09 0.24 0.67 0.09 0.24 0.67 0.09 0.24 0.67 ] \text{softmax}(QK^\top) \approx \begin{bmatrix} 0.09 & 0.24 & 0.67 \\ 0.09 & 0.24 & 0.67 \\ 0.09 & 0.24 & 0.67 \end{bmatrix} softmax(QK⊤)≈ 0.090.090.090.240.240.240.670.670.67
结果分析
从上面的注意力权重矩阵可以看到,每个位置的注意力分布几乎相同,即每个词都倾向于关注序列中的第三个词(“猫”)。这是因为在这个例子中,由于所有词嵌入向量之间没有考虑到它们的位置信息,导致模型无法区分不同位置上的相同词。
缺乏位置感知的问题
如果我们考虑一个顺序不同的句子,“猫喜欢我”,其词嵌入矩阵为:
X ′ = [ 0.7 0.8 0.9 0.4 0.5 0.6 0.1 0.2 0.3 ] X' = \begin{bmatrix} 0.7 & 0.8 & 0.9 \\ 0.4 & 0.5 & 0.6 \\ 0.1 & 0.2 & 0.3 \end{bmatrix} X′= 0.70.40.10.80.50.20.90.60.3
按照同样的计算方法,我们会发现即使词的顺序改变了,由于缺乏位置信息,最终生成的注意力权重矩阵将与原句“我喜欢猫”相同或非常相似。这意味着模型无法区分这两种不同的语义结构。
加入位置编码后的改进
为了使模型能够区分不同位置上的相同词,我们需要加入位置编码。例如,假设我们使用固定的位置编码公式来生成位置编码向量:
- 对于位置1:“我”的位置编码: P E 1 = [ 0.841 , 0.995 , 0.010 ] PE_1 = [0.841, 0.995, 0.010] PE1=[0.841,0.995,0.010]
- 对于位置2:“喜欢”的位置编码: P E 2 = [ 0.409 , 1.580 , − 0.680 ] PE_2 = [0.409, 1.580, -0.680] PE2=[0.409,1.580,−0.680]
- 对于位置3:“猫”的位置编码: P E 3 = [ 1.041 , − 0.045 , 1.130 ] PE_3 = [1.041, -0.045, 1.130] PE3=[1.041,−0.045,1.130]
将位置编码加到对应的词嵌入向量上:
X with PE = [ 0.1 + 0.841 0.2 + 0.995 0.3 + 0.010 0.4 + 0.409 0.5 + 1.580 0.6 − 0.680 0.7 + 1.041 0.8 − 0.045 0.9 + 1.130 ] X_{\text{with PE}} = \begin{bmatrix} 0.1 + 0.841 & 0.2 + 0.995 & 0.3 + 0.010 \\ 0.4 + 0.409 & 0.5 + 1.580 & 0.6 - 0.680 \\ 0.7 + 1.041 & 0.8 - 0.045 & 0.9 + 1.130 \end{bmatrix} Xwith PE= 0.1+0.8410.4+0.4090.7+1.0410.2+0.9950.5+1.5800.8−0.0450.3+0.0100.6−0.6800.9+1.130
X with PE = [ 0.941 1.195 0.310 0.809 2.080 − 0.080 1.741 0.755 2.030 ] X_{\text{with PE}} = \begin{bmatrix} 0.941 & 1.195 & 0.310 \\ 0.809 & 2.080 & -0.080 \\ 1.741 & 0.755 & 2.030 \end{bmatrix} Xwith PE= 0.9410.8091.7411.1952.0800.7550.310−0.0802.030
重新进行自注意力计算时,由于每个词现在都有了独特的位置编码,模型可以更好地捕捉到词之间的相对位置关系,从而提升对序列的理解能力。这样,即使是相同的词但在不同的位置,模型也能正确地区分它们的角色和意义。
三、位置编码的原理
3.1. 位置编码的设计
位置编码的公式如下:
PE ( p o s , 2 i ) = sin ( p o s 10000 2 i / d model ) \text{PE}(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
PE ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d model ) \text{PE}(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
- 参数解释:
- p o s pos pos:词在序列中的位置(如第1个词、第2个词)。
- i i i:编码向量的维度索引(如 d model = 512 d_{\text{model}} = 512 dmodel=512时, i ∈ [ 0 , 255 ] i \in [0, 255] i∈[0,255])。
- d model d_{\text{model}} dmodel:词嵌入的维度。
3.2. 与词嵌入的结合
- 输入向量:词嵌入
E
E
E 与位置编码
P
E
PE
PE 逐元素相加:
Input = E + P E \text{Input} = E + PE Input=E+PE - 示例:
- 词“猫”的嵌入: E 猫 ∈ R 512 E_{\text{猫}} \in \mathbb{R}^{512} E猫∈R512
- 位置1的编码: P E ( 1 ) ∈ R 512 PE(1) \in \mathbb{R}^{512} PE(1)∈R512
- 最终输入: E 猫 + P E ( 1 ) E_{\text{猫}} + PE(1) E猫+PE(1)
| 关键点 | 说明 |
|---|---|
| 弥补自注意力缺陷 | 提供位置信息,使模型感知词序 |
| 正弦/余弦函数设计 | 支持相对位置编码,外推长序列 |
| 与词嵌入相加 | 结合语义和位置信息,作为输入 |
| 变体与扩展 | 可学习编码、相对位置编码等适应不同场景 |
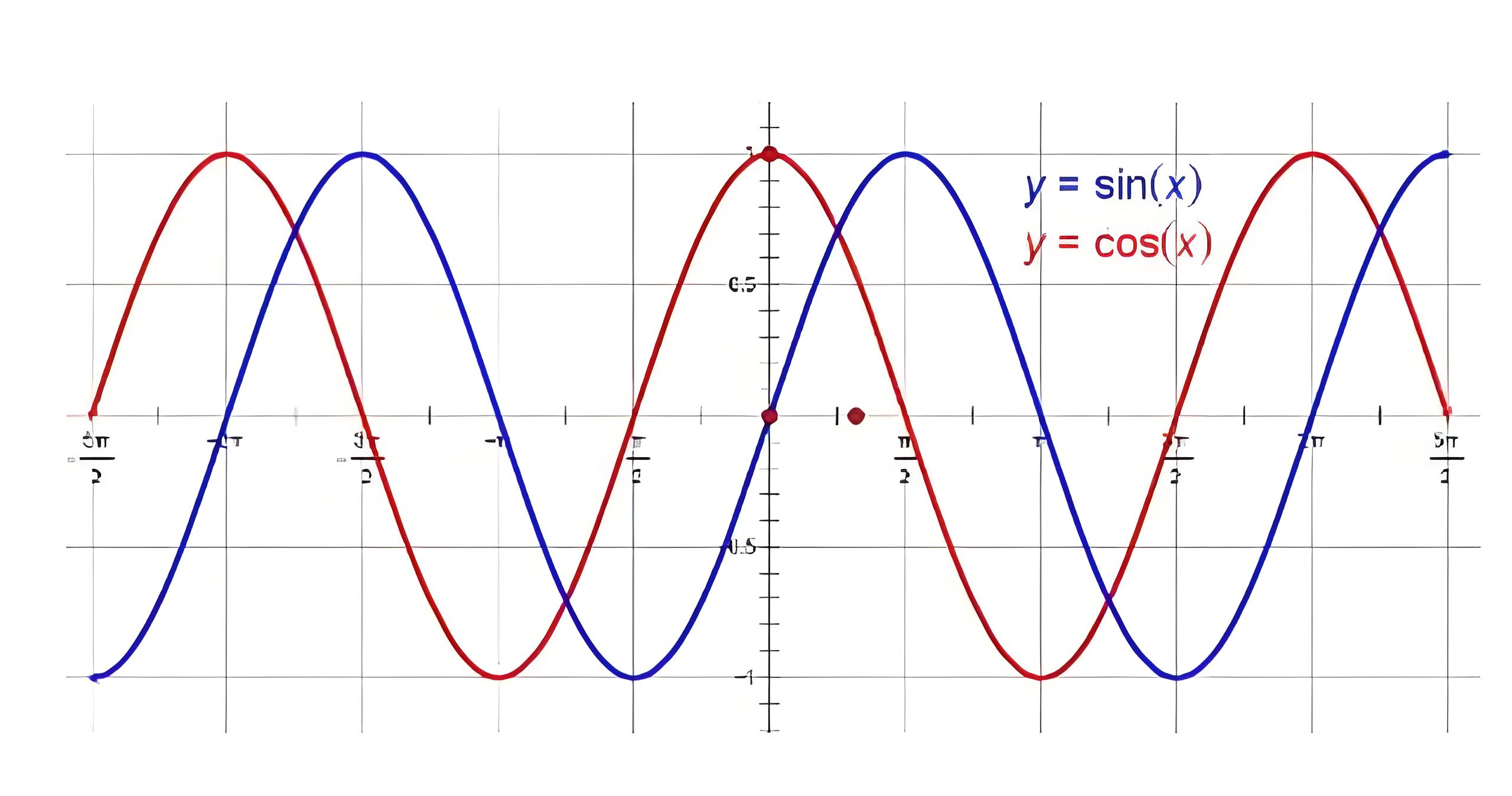
四、为什么采用正弦(sin)和余弦(cos)函数
Transformer的位置编码设计巧妙结合了数学性质和实际需求,其公式采用正弦(sin)和余弦(cos)函数,并引入指数衰减因子。
设计动机与核心思想
1. 捕捉相对位置关系
- 三角函数的加法公式:
对任意偏移量 k k k,存在线性变换 M k M_k Mk,使得:
PE ( p o s + k ) = PE ( p o s ) ⋅ M k \text{PE}(pos + k) = \text{PE}(pos) \cdot M_k PE(pos+k)=PE(pos)⋅Mk
这意味着模型可以通过学习 M k M_k Mk 隐式捕捉相对位置,而无需显式编码位置差。 - 示例:
若“吃”在“我”后1位,模型可通过 M 1 M_1 M1 将“我”的位置编码转换为“吃”的位置编码。
2. 多尺度位置感知
- 频率多样性:
不同维度 i i i 对应不同的波长(频率),低维(小 i i i)对应高频(短距离位置变化),高维(大 i i i)对应低频(长距离依赖)。
波长公式:
λ i = 2 π ⋅ 10000 2 i / d model \lambda_i = 2\pi \cdot 10000^{2i/d_{\text{model}}} λi=2π⋅100002i/dmodel- 当 d model = 512 d_{\text{model}}=512 dmodel=512 时,波长范围从约 6.28 6.28 6.28(高频)到 20000 π 20000\pi 20000π(低频)。
3. 外推能力
- 周期性函数:
sin和cos的周期性使位置编码能处理任意长度序列,即使序列长度远超训练时的最大长度。
公式设计细节
1. 正弦与余弦交替
- 相邻维度互补:
每个位置编码向量的相邻维度使用sin和cos,形成正交基,增强位置信息的表达能力。
示例: d m o d e l = 4 d_{model}= 4 dmodel=4时的位置编码向量,
P E ( p o s ) = [ s i n ( f 0 ) , c o s ( f 0 ) , s i n ( f 1 ) , c o s ( f 1 ) ] PE(pos) = [sin(f_0), cos(f_0), sin(f_1), cos(f_1)] PE(pos)=[sin(f0),cos(f0),sin(f1),cos(f1)], f i = p o s / 10000 2 i / d m o d e l f_i = pos / 10000^{2i/d_{model}} fi=pos/100002i/dmodel
2. 指数衰减因子
- 分母设计:
10000 2 i / d model 10000^{2i/d_{\text{model}}} 100002i/dmodel 使不同维度的波长呈几何级数增长,覆盖从短到长的位置关系。- 低频维度(大 i i i):波长长,捕捉段落、句子级依赖。
- 高频维度(小 i i i):波长短,捕捉局部词序关系。
3. 数值范围控制
- 输出范围:
sin和cos的输出值在 ([-1, 1]) 之间,与词嵌入(通常L2归一化)范围匹配,避免位置编码主导语义信息。
对比其他设计
| 编码方式 | 优点 | 缺点 |
|---|---|---|
| 可学习的位置嵌入 | 灵活适配任务 | 无法外推超长序列,需预设最大长度 |
| 相对位置编码 | 直接建模相对位置 | 计算复杂度高,实现复杂 |
| 正弦位置编码 | 外推性强,理论保障相对位置建模 | 对绝对位置敏感度较低 |
具体示例
假设 d model = 4 d_{\text{model}} = 4 dmodel=4,位置 p o s = 2 pos = 2 pos=2:
- 计算各维度频率:
- i = 0 i=0 i=0: 10000 0 / 4 = 1 10000^{0/4} = 1 100000/4=1 → f 0 = 2 / 1 = 2 f_0 = 2/1 = 2 f0=2/1=2
- i = 1 i=1 i=1: 10000 2 / 4 = 100 10000^{2/4} = 100 100002/4=100 → f 1 = 2 / 100 = 0.02 f_1 = 2/100 = 0.02 f1=2/100=0.02
- 生成位置编码:
- PE ( 2 , 0 ) = sin ( 2 ) ≈ 0.909 \text{PE}(2, 0) = \sin(2) \approx 0.909 PE(2,0)=sin(2)≈0.909
- PE ( 2 , 1 ) = cos ( 2 ) ≈ − 0.416 \text{PE}(2, 1) = \cos(2) \approx -0.416 PE(2,1)=cos(2)≈−0.416
- PE ( 2 , 2 ) = sin ( 0.02 ) ≈ 0.020 \text{PE}(2, 2) = \sin(0.02) \approx 0.020 PE(2,2)=sin(0.02)≈0.020
- PE ( 2 , 3 ) = cos ( 0.02 ) ≈ 0.999 \text{PE}(2, 3) = \cos(0.02) \approx 0.999 PE(2,3)=cos(0.02)≈0.999
- 最终编码:
[0.909, -0.416, 0.020, 0.999]
这种设计平衡了绝对位置感知、相对位置建模和计算效率,是Transformer成功处理序列数据的关键创新之一。
| 设计特性 | 实际意义 |
|---|---|
| 正弦/余弦交替 | 增强位置信息表达能力,支持相对位置建模 |
| 指数衰减分母 | 多尺度捕捉短程和长程依赖 |
| 周期性函数 | 支持外推到任意长度序列 |
| 数值范围控制 | 与词嵌入兼容,避免位置信息淹没语义信息 |
五、位置编码与词嵌入结合示例
使用具体数值演示 位置编码(Positional Encoding) 与 词嵌入(Word Embedding) 结合过程的详细示例。
示例设定
- 句子:
猫 吃 鱼(3个词,位置索引为0、1、2) - 词嵌入维度: d model = 4 d_{\text{model}} = 4 dmodel=4(简化维度)
- 词嵌入向量(随机初始化):
猫:[0.5, 0.2, -0.1, 0.3]吃:[0.3, -0.4, 0.6, 0.1]鱼:[-0.2, 0.7, 0.4, -0.5]
- 位置编码公式(简化版,使用基数100代替10000):
PE ( p o s , 2 i ) = sin ( p o s 100 2 i / 4 ) , PE ( p o s , 2 i + 1 ) = cos ( p o s 100 2 i / 4 ) \text{PE}(pos, 2i) = \sin\left(\frac{pos}{100^{2i/4}}\right), \quad \text{PE}(pos, 2i+1) = \cos\left(\frac{pos}{100^{2i/4}}\right) PE(pos,2i)=sin(1002i/4pos),PE(pos,2i+1)=cos(1002i/4pos)
生成位置编码
1. 位置0(“猫”)
- 维度0(
i
=
0
i=0
i=0):
PE ( 0 , 0 ) = sin ( 0 100 0 ) = sin ( 0 ) = 0.0 PE ( 0 , 1 ) = cos ( 0 100 0 ) = cos ( 0 ) = 1.0 \text{PE}(0, 0) = \sin\left(\frac{0}{100^{0}}\right) = \sin(0) = 0.0 \\ \text{PE}(0, 1) = \cos\left(\frac{0}{100^{0}}\right) = \cos(0) = 1.0 PE(0,0)=sin(10000)=sin(0)=0.0PE(0,1)=cos(10000)=cos(0)=1.0 - 维度1(
i
=
1
i=1
i=1):
PE ( 0 , 2 ) = sin ( 0 100 0.5 ) = sin ( 0 ) = 0.0 PE ( 0 , 3 ) = cos ( 0 100 0.5 ) = cos ( 0 ) = 1.0 \text{PE}(0, 2) = \sin\left(\frac{0}{100^{0.5}}\right) = \sin(0) = 0.0 \\ \text{PE}(0, 3) = \cos\left(\frac{0}{100^{0.5}}\right) = \cos(0) = 1.0 PE(0,2)=sin(1000.50)=sin(0)=0.0PE(0,3)=cos(1000.50)=cos(0)=1.0 - 位置0编码:
[0.0, 1.0, 0.0, 1.0]
2. 位置1(“吃”)
- 维度0(
i
=
0
i=0
i=0):
PE ( 1 , 0 ) = sin ( 1 100 0 ) = sin ( 1 ) ≈ 0.841 PE ( 1 , 1 ) = cos ( 1 100 0 ) = cos ( 1 ) ≈ 0.540 \text{PE}(1, 0) = \sin\left(\frac{1}{100^{0}}\right) = \sin(1) \approx 0.841 \\ \text{PE}(1, 1) = \cos\left(\frac{1}{100^{0}}\right) = \cos(1) \approx 0.540 PE(1,0)=sin(10001)=sin(1)≈0.841PE(1,1)=cos(10001)=cos(1)≈0.540 - 维度1(
i
=
1
i=1
i=1):
PE ( 1 , 2 ) = sin ( 1 100 0.5 ) = sin ( 1 10 ) ≈ 0.0998 PE ( 1 , 3 ) = cos ( 1 100 0.5 ) = cos ( 1 10 ) ≈ 0.995 \text{PE}(1, 2) = \sin\left(\frac{1}{100^{0.5}}\right) = \sin\left(\frac{1}{10}\right) \approx 0.0998 \\ \text{PE}(1, 3) = \cos\left(\frac{1}{100^{0.5}}\right) = \cos\left(\frac{1}{10}\right) \approx 0.995 PE(1,2)=sin(1000.51)=sin(101)≈0.0998PE(1,3)=cos(1000.51)=cos(101)≈0.995 - 位置1编码:
[0.841, 0.540, 0.0998, 0.995]
3. 位置2(“鱼”)
- 维度0(
i
=
0
i=0
i=0):
PE ( 2 , 0 ) = sin ( 2 100 0 ) = sin ( 2 ) ≈ 0.909 PE ( 2 , 1 ) = cos ( 2 100 0 ) = cos ( 2 ) ≈ − 0.416 \text{PE}(2, 0) = \sin\left(\frac{2}{100^{0}}\right) = \sin(2) \approx 0.909 \\ \text{PE}(2, 1) = \cos\left(\frac{2}{100^{0}}\right) = \cos(2) \approx -0.416 PE(2,0)=sin(10002)=sin(2)≈0.909PE(2,1)=cos(10002)=cos(2)≈−0.416 - 维度1(
i
=
1
i=1
i=1):
PE ( 2 , 2 ) = sin ( 2 100 0.5 ) = sin ( 2 10 ) ≈ 0.198 PE ( 2 , 3 ) = cos ( 2 100 0.5 ) = cos ( 2 10 ) ≈ 0.980 \text{PE}(2, 2) = \sin\left(\frac{2}{100^{0.5}}\right) = \sin\left(\frac{2}{10}\right) \approx 0.198 \\ \text{PE}(2, 3) = \cos\left(\frac{2}{100^{0.5}}\right) = \cos\left(\frac{2}{10}\right) \approx 0.980 PE(2,2)=sin(1000.52)=sin(102)≈0.198PE(2,3)=cos(1000.52)=cos(102)≈0.980 - 位置2编码:
[0.909, -0.416, 0.198, 0.980]
词嵌入与位置编码的结合
将词嵌入向量与位置编码 逐元素相加,生成输入向量。
1. 词“猫”(位置0)
- 词嵌入:
[0.5, 0.2, -0.1, 0.3] - 位置编码:
[0.0, 1.0, 0.0, 1.0] - 输入向量:
[ 0.5 + 0.0 , 0.2 + 1.0 , − 0.1 + 0.0 , 0.3 + 1.0 ] = [ 0.5 , 1.2 , − 0.1 , 1.3 ] [0.5+0.0, 0.2+1.0, -0.1+0.0, 0.3+1.0] = [0.5, 1.2, -0.1, 1.3] [0.5+0.0,0.2+1.0,−0.1+0.0,0.3+1.0]=[0.5,1.2,−0.1,1.3]
2. 词“吃”(位置1)
- 词嵌入:
[0.3, -0.4, 0.6, 0.1] - 位置编码:
[0.841, 0.540, 0.0998, 0.995] - 输入向量:
[ 0.3 + 0.841 , − 0.4 + 0.540 , 0.6 + 0.0998 , 0.1 + 0.995 ] ≈ [ 1.141 , 0.140 , 0.700 , 1.095 ] [0.3+0.841, -0.4+0.540, 0.6+0.0998, 0.1+0.995] \approx [1.141, 0.140, 0.700, 1.095] [0.3+0.841,−0.4+0.540,0.6+0.0998,0.1+0.995]≈[1.141,0.140,0.700,1.095]
3. 词“鱼”(位置2)
- 词嵌入:
[-0.2, 0.7, 0.4, -0.5] - 位置编码:
[0.909, -0.416, 0.198, 0.980] - 输入向量:
[ − 0.2 + 0.909 , 0.7 + ( − 0.416 ) , 0.4 + 0.198 , − 0.5 + 0.980 ] ≈ [ 0.709 , 0.284 , 0.598 , 0.480 ] [-0.2+0.909, 0.7+(-0.416), 0.4+0.198, -0.5+0.980] \approx [0.709, 0.284, 0.598, 0.480] [−0.2+0.909,0.7+(−0.416),0.4+0.198,−0.5+0.980]≈[0.709,0.284,0.598,0.480]
编码设计的关键特性
1. 位置唯一性
每个位置的编码是唯一的,例如:
- 位置0的编码是
[0.0, 1.0, 0.0, 1.0] - 位置1的编码是
[0.841, 0.540, 0.0998, 0.995] - 位置2的编码是
[0.909, -0.416, 0.198, 0.980]
2. 相对位置感知
通过三角函数的性质,模型可以捕捉相对位置。例如:
- 位置差为1(1-0=1)的编码关系:
PE ( 1 ) ≈ PE ( 0 ) ⋅ M ( 1 ) + PE ( 1 ) \text{PE}(1) \approx \text{PE}(0) \cdot M(1) + \text{PE}(1) PE(1)≈PE(0)⋅M(1)+PE(1)
其中 M ( 1 ) M(1) M(1) 是模型通过注意力机制学习的变换矩阵。
3. 数值范围可控
位置编码的幅值与词嵌入相似(如均值为0、方差为1),避免位置信息主导语义信息。
最终输入向量
| 词 | 输入向量(词嵌入 + 位置编码) |
|---|---|
| 猫 | [0.5, 1.2, -0.1, 1.3] |
| 吃 | [1.141, 0.140, 0.700, 1.095] |
| 鱼 | [0.709, 0.284, 0.598, 0.480] |
总结
- 结合方式:词嵌入(语义)与位置编码(顺序)直接相加。
- 数学意义:通过正弦/余弦函数生成位置编码,确保位置信息可被模型解析。
- 实际效果:输入向量同时包含语义和位置信息,使Transformer能够处理序列顺序。
通过这种设计,模型既能理解“猫吃鱼”的语义,也能区分“鱼吃猫”的逆序,从而正确建模自然语言的顺序依赖性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









