







在推荐系统或搜索系统中,“粗排”和“精排”是排序(Ranking)流程中的两个关键阶段,主要用于从海量候选集中筛选出最符合用户需求的条目。两者的核心区别在于计算效率与精度的权衡。
一、粗排(粗粒度排序,Pre-Ranking)
1. 定义与作用
- 目标:从召回阶段(Recall)提供的数千至百万级候选集中(如商品、视频、文章),快速筛选出 Top 几百到几千条,减少后续精排的计算压力。通过简单的规则或模型,快速淘汰明显不相关的候选项,保留可能与用户兴趣匹配的候选项。
- 特点:
- 轻量模型:逻辑回归(Logistic Regression)、浅层神经网络(如单层或双层神经网络)、基于向量内积的简单计算。或规则(如热度、点击率)。
- 低延迟:单条处理时间通常低于1ms,适合高并发场景。
- 特征简化:通常使用基础特征(如用户的基本属性、物品的热度、基础行为统计等),不涉及复杂的用户-物品交互特征。
2. 示例
假设召回阶段返回了10万条短视频候选,粗排阶段通过以下步骤筛选出Top 1000条:
- 规则过滤:剔除用户已看过的视频、低质量内容。
- 快速打分:用轻量模型预测点击率(CTR),保留得分最高的1000条。
二、精排(精细化排序,Ranking)
1. 定义与作用
- 目标:对粗排筛选出的几百到几千条候选(如1000条),精细化打分并排序,输出最终展示的Top结果(如前20条)。
- 特点:
- 复杂模型:使用深度学习模型(如Wide & Deep、DeepFM、Transformer)。
- 特征丰富:引入用户行为序列、上下文特征、交叉特征等。
- 高精度:模型参数量大,计算耗时较长(单条约10-100ms)。
2. 精排的原理
精排的核心是通过高阶特征交互和复杂模型结构捕捉用户与内容的深层关联。以下是典型技术原理:
特征工程
- 特征类型:
- 用户特征:年龄、性别、历史行为(点击、购买、浏览时长)、实时兴趣(如最近搜索关键词)。
- 物品特征:类别、价格、品牌、内容深度、作者影响力、实时反馈(如点赞、评论)。
- 上下文特征:时间、地理位置、设备类型。
- 交叉特征:用户与物品的交互特征(如用户对某类商品的偏好与当前物品类别的匹配度)。
- 特征编码:
- 数值特征:归一化或分桶。
- 类别特征:Embedding映射为稠密向量。
三、粗排 vs 精排对比
| 维度 | 粗排 | 精排 |
|---|---|---|
| 候选数量 | 10万 → 1000 | 1000 → 20 |
| 模型复杂度 | LR、浅层DNN | DeepFM、Transformer |
| 特征数量 | 10-100维 | 1000-10000维 |
| 延迟要求 | <1ms/条 | 10-100ms/条 |
| 目标 | 快速过滤低质量候选 | 精细化排序,最大化用户满意度 |
比如短视频推荐系统流程
- 召回:从亿级视频库中用协同过滤、Embedding检索等方法召回10万条候选。
- 粗排:用轻量模型筛选出Top 1000条(耗时约1秒)。
- 精排:用复杂模型对1000条打分排序,输出Top 20(耗时约2秒)。
- 重排:业务规则调整(如多样性控制、打散同类型视频)。
粗排与精排总结
- 粗排:通过效率优先的模型快速缩小候选范围,解决“从海量到百千级”的筛选问题。
- 精排:通过复杂模型和丰富特征实现精准排序,解决“从千级到个位数”的最优选择问题。
四、电商搜索示例
以电商搜索“2轮电动车”为例详解召回、粗排、精排流程
4.1. 召回(Recall)阶段
目标:从千万级商品库中快速筛选出与查询相关的候选商品(如1万条)。
核心方法:
- 关键词匹配:
- 匹配标题/描述中的关键词(如“2轮电动车”“两轮电动车”),考虑同义词(“电瓶车”、“电动自行车”)。
- 使用倒排索引技术快速检索。
- 语义召回:
- 将查询词“2轮电动车”转换为Embedding向量,通过向量数据库(如Faiss)检索语义相似商品(如“新国标电动车”、“锂电轻便电摩”)。
- 行为召回:
- 根据用户历史行为补充候选(如用户曾浏览过“雅迪”品牌,召回雅迪相关车型)。
输出:约10,000条候选商品(包含直接匹配、语义相关、用户偏好商品)。
4.2. 粗排(Pre-Ranking)阶段
目标:从1万条候选商品中筛选出Top 500条,降低后续计算压力。
核心方法:
- 规则过滤:
- 剔除无效商品(如库存为0、已下架)。
- 过滤低质量商品(如评分<3.5星、投诉率>5%)。
- 轻量模型打分:
- 使用逻辑回归(LR)或浅层神经网络预测点击率(CTR),特征包括:
- 用户特征:基础画像(性别、城市)、近期搜索记录。
- 商品特征:价格、销量、历史CTR、品牌知名度。
- 上下文特征:搜索时间(白天/夜间)、设备类型(手机/PC)。
- 保留得分最高的500条商品。
- 使用逻辑回归(LR)或浅层神经网络预测点击率(CTR),特征包括:
示例:
- 高销量但低评分的商品可能被过滤。
- 用户所在城市禁摩,则剔除“电摩”类商品。
为什么在轻量模型打分的时候,需要输入用户的特征呢?
在粗排阶段,用户特征(如性别、城市、近期搜索记录)指的是当前发起搜索的用户的特征。
用户特征的作用
粗排阶段的用户特征用于实现个性化筛选,通过以下方式提升候选物品的相关性:
- 基础画像(性别、城市):
- 性别:影响商品偏好(如女性用户可能更关注美妆,男性用户关注电子产品)。
- 城市:地理位置决定物流可行性(如某些商品仅支持特定地区配送)或本地化需求(如北方用户冬季更关注羽绒服)。
- 近期搜索记录:
- 反映用户的即时兴趣(如用户连续搜索“瑜伽垫”,可能对运动装备更感兴趣)。
- 帮助捕捉短期行为模式(如节日促销期间频繁搜索“礼物”)。
为什么需要当前用户的信息?
- 个性化需求:不同用户对同一搜索词可能有不同偏好。
示例:- 用户A(男性,北京)搜索“咖啡机” → 优先推荐商用大容量机型(适合家庭/办公室)。
- 用户B(女性,上海)搜索“咖啡机” → 推荐迷你便携款(适合小户型)。
- 实时性要求:用户的兴趣可能随时间变化(如近期搜索“旅行箱”后,对旅行相关商品更敏感)。
实际案例
场景:用户(女性,杭州,近期搜索“防晒霜”“遮阳帽”)搜索“连衣裙”。
粗排逻辑:
- 用户画像:
- 性别 → 女性:倾向于女性款式。
- 城市 → 杭州:夏季炎热,偏好轻薄面料。
- 近期搜索 → 防晒相关:可能偏好长袖/防晒材质的连衣裙。
- 候选筛选:
- 优先展示“雪纺长袖连衣裙”“防晒沙滩裙”等高匹配商品。
- 过滤掉厚重款式(如羊毛连衣裙)或男性款式。
总之,在粗排阶段,用户特征专指当前搜索用户的画像与行为数据,其核心价值在于:
- 提升个性化:根据用户属性与实时兴趣筛选候选。
- 平衡效率与效果:轻量模型快速处理用户特征,避免精排阶段过载。
- 动态适应:通过近期行为捕捉用户意图变化(如从“笔记本电脑”转向“电脑包”)。
4.2.1. 逻辑回归计算得分
粗排阶段,如何使用逻辑回归(LR)计算得分?
1. 特征工程
逻辑回归的输入是数值型特征向量,需将用户、查询、上下文和商品的原始特征转换为数值形式。以下是具体步骤:
1. 特征类型:
- 用户特征:
- 基础属性:年龄、性别(独热编码)、地理位置(如省份ID)。
- 行为统计:历史点击率、浏览时长、最近搜索关键词(如“电动车”)。
- 查询特征:
- 搜索词的词向量(如“2轮电动车”通过Word2Vec或预训练模型生成)。
- 查询词的语义标签(如“轮数=2”、“类型=电动车”)。
- 商品特征:
- 属性:轮数(数值)、价格(归一化)、品牌信誉分(如品牌A=0.8)。
- 内容:标题关键词匹配度(如标题是否包含“2轮”)、描述中的关键词密度。
- 统计指标:历史点击率、转化率、收藏加购率。
- 上下文特征:
- 时间:是否为促销期(如“618=1”)、当前时段(如“上午=1”)。
- 设备:移动端/PC端(独热编码)。
2. 特征转换方法:
- 数值特征:直接使用或进行归一化(如价格缩放到[0,1])。
- 类别特征:
- 独热编码(One-Hot):如品牌(品牌A=1,其他=0)。
- 嵌入(Embedding):将高维稀疏特征(如商品ID)映射为低维稠密向量。
- 文本特征:
- 词袋(Bag-of-Words)或TF-IDF:将查询词、商品标题转化为向量。
- 预训练词向量(如Word2Vec):将查询词和商品描述转化为固定长度向量。
4.2.2. 训练逻辑回归模型
模型结构
逻辑回归的数学形式为:
s
=
σ
(
w
T
x
+
b
)
s = \sigma\left( \mathbf{w}^T \mathbf{x} + b \right)
s=σ(wTx+b)
其中:
- x \mathbf{x} x:特征向量(将用户、查询、商品、上下文的特征拼接成一维向量)。
- w \mathbf{w} w:权重向量(通过训练学习到的参数)。
- b b b:偏置项。
- σ \sigma σ:Sigmoid函数,将线性组合映射到0-1的概率区间: σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
- s s s:最终得分,表示用户点击该商品的概率(或排序分)。
训练数据:
- 正样本:用户点击过的商品(标签为1)。指的是用户实际点击过的商品。例如,在电商搜索场景中,如果用户搜索了“2轮电动车”,然后从搜索结果页面点击进入了某款电动车的详情页,那么这款电动车就是一个正样本。这意味着该商品对这个用户来说是有吸引力的,符合他的需求或兴趣。
- 负样本:用户未点击但曝光过的商品(标签为0)。是指用户未点击但曾被展示给用户的商品。继续上面的例子,如果搜索结果页面展示了10款电动车,但用户只点击了其中一款,则其余9款未被点击的商品可以作为负样本。这些商品可能是因为不符合用户的兴趣、价格不合适等原因而没有被点击。
- 特征构造:将上述特征组合成向量,标签为是否点击。
优化目标:
-
损失函数:对数损失(Log Loss),最小化预测概率与真实标签的差异:
L = − 1 N ∑ i = 1 N [ y i ln ( y ^ i ) + ( 1 − y i ) ln ( 1 − y ^ i ) ] L = -\frac{1}{N}\sum_{i=1}^N \left[ y_i \ln(\hat{y}_i) + (1 - y_i) \ln(1 - \hat{y}_i) \right] L=−N1∑i=1N[yiln(y^i)+(1−yi)ln(1−y^i)]
其中, y ^ i = σ ( w T x i + b ) \hat{y}_i = \sigma(\mathbf{w}^T \mathbf{x}_i + b) y^i=σ(wTxi+b)。 -
优化方法:梯度下降或其变体(如Adam),通过反向传播更新参数(\mathbf{w})和(b)。
4.2.3. 线上预测流程
输入:
- 用户查询“2轮电动车”。
- 召回的候选商品列表(如数千条)。
计算步骤:
- 特征提取:
- 对每个候选商品,提取用户、查询、商品、上下文的特征,并拼接成特征向量 x \mathbf{x} x。
- 线性加权:
- 计算线性组合: z = w T x + b z = \mathbf{w}^T \mathbf{x} + b z=wTx+b。
- 概率计算:
- 通过Sigmoid函数得到点击概率: s = σ ( z ) s = \sigma(z) s=σ(z)。
- 排序与筛选:
- 根据 s s s对商品排序,选取前几百条作为粗排结果。
4.2.4. 实际应用中的注意事项
特征工程技巧:
- 交叉特征:手动构造特征组合(如用户历史点击品牌与当前商品品牌的匹配度)。
- 特征选择:通过统计方法(如卡方检验、IV值)筛选重要特征,减少维度。
- 实时特征:加入上下文特征(如促销标签)以提升时效性。
模型优化:
- 类别权重:对类别不平衡(如点击率低)的数据,调整正负样本权重。
- 特征归一化:对价格、销量等数值特征进行标准化(如Z-Score)。
业务规则融合:
- 基础分调整:在LR得分基础上,叠加业务规则(如促销商品+10分)。
- 排除逻辑:对明显不相关商品(如三轮车)直接过滤。
4.2.5. 搜索“2轮电动车”的粗排计算
假设某商品的特征向量为:
- 用户特征:历史点击电动车=1,年龄=30(标准化后为0.7)。
- 查询特征:搜索词“2轮电动车”的词向量(如[0.2, 0.5, …])。
- 商品特征:轮数=2(匹配得分+0.8),价格=2000元(归一化后0.6),品牌信誉=0.9。
- 上下文特征:促销期=1。
通过逻辑回归模型计算:
s
=
σ
(
w
1
×
用户特征
+
w
2
×
查询特征
+
w
3
×
商品特征
+
w
4
×
上下文特征
+
b
)
s = \sigma\left( w_1 \times \text{用户特征} + w_2 \times \text{查询特征} + w_3 \times \text{商品特征} + w_4 \times \text{上下文特征} + b \right)
s=σ(w1×用户特征+w2×查询特征+w3×商品特征+w4×上下文特征+b)
假设训练得到的权重使该商品得分最高,最终被保留在粗排结果中。
逻辑回归在粗排阶段的优势在于:
- 高效性:线性计算,适合实时预测。
- 可解释性:通过特征权重分析关键影响因素(如品牌信誉对得分贡献大)。
- 鲁棒性:对高维稀疏特征(如商品ID)处理友好。
但需注意其局限性:无法自动捕捉高阶特征交互(如用户与商品的协同效应),需依赖人工特征工程。因此,粗排后通常需要精排模型进一步优化。
4.3. 精排(Ranking)阶段
目标:对500条候选商品精细化排序,输出最终展示的Top 20条。
核心方法:
(1) 特征工程
- 用户深度画像:
- 长期兴趣(过去半年购买过电动车配件)。
- 实时行为(本次搜索前点击了“长续航”筛选条件)。
- 商品多维度特征:
- 详细属性:电池容量(48V/60V)、续航里程、电机功率。
- 图文质量:标题吸引力、主图清晰度、详情页完整性。
- 交叉特征:
- 用户价格敏感度与商品价格的匹配度(如用户常浏览低价商品,则高价商品降权)。
(2) 复杂模型推理
以 多任务深度学习模型 为例:
- 模型结构:
- 输入层:用户、商品、上下文特征的Embedding拼接。
- 多塔网络:分别学习点击率(CTR)、转化率(CVR)、停留时长等目标。
- 输出层:加权综合得分(如 Score = 0.6 × CTR + 0.4 × CVR \text{Score} = 0.6 \times \text{CTR} + 0.4 \times \text{CVR} Score=0.6×CTR+0.4×CVR)。
- 实时特征:
- 当前商品库存剩余量(库存紧张的商品加权)。
- 用户实时点击反馈(如本次会话中已点击类似商品,则相似品降权)。
(3) 排序与多样性控制
- 个性化排序:
- 对续航敏感用户,优先展示“100km长续航”车型。
- 对价格敏感用户,按“价格从低到高”排序。
- 打散策略:
- 同一品牌最多展示3款,避免结果单一化。
- 混合不同价格段(如穿插1款高端车型吸引潜在升级需求)。
示例输出排序:
- 高性价比车型(雅迪DE2,售价2999元,销量10万+,续航80km)。
- 长续航车型(小牛NQi GT,售价8999元,续航120km)。
- 新国标轻便款(九号A30C,售价1999元,适合城市通勤)。
… - 高端电摩(速柯CPX,售价14999元,强调性能)。
4.4. 重排(Re-Ranking)阶段
目标:业务规则最终调整排序结果。
- 人工干预:
- 置顶促销商品(如“618限时折扣”)。
- 插入广告位(如合作品牌“绿源电动车”广告)。
- 实时过滤:
- 剔除用户已购买过的商品。
- 根据库存更新移除已售罄商品。
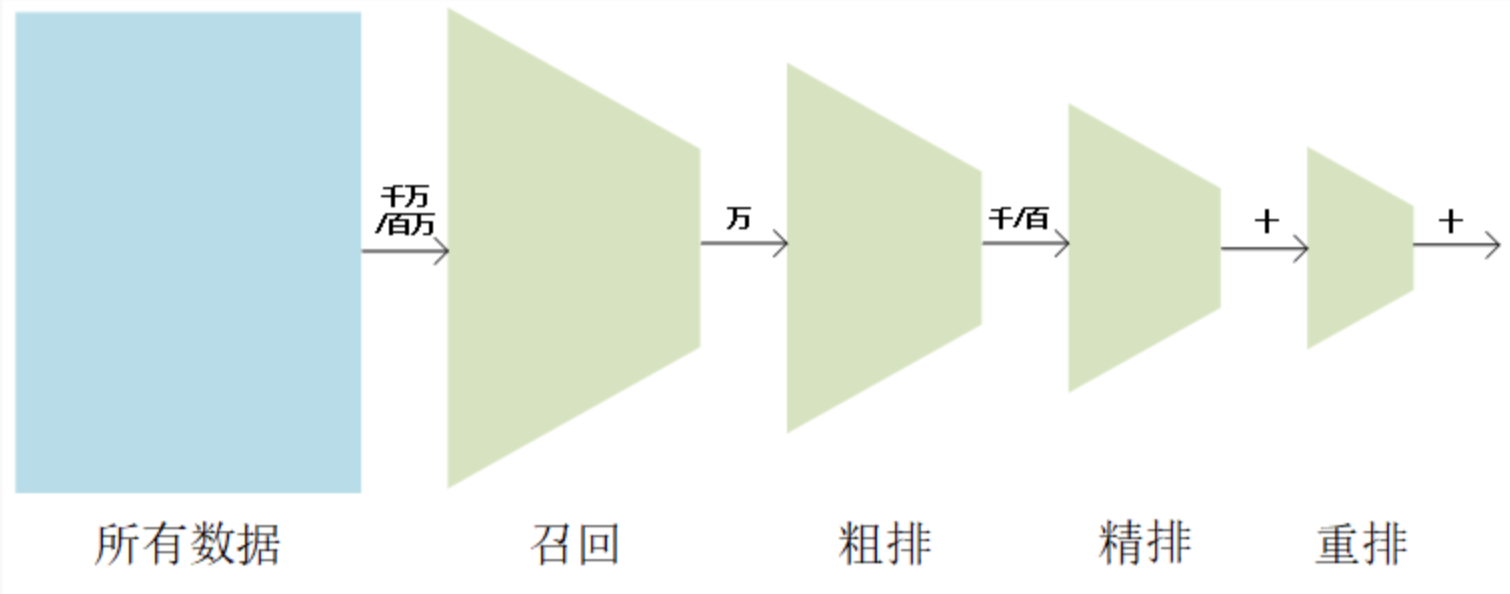
五、 全流程总结
| 阶段 | 候选数量 | 核心逻辑 | 耗时 | 示例决策 |
|---|---|---|---|---|
| 召回 | 1千万 → 1万 | 关键词+语义+行为召回 | 50-200ms | 匹配“2轮电动车”“电摩”等广义相关商品 |
| 粗排 | 1万 → 500 | 规则过滤 + 轻量CTR模型 | 10-50ms | 过滤低评分、高投诉商品 |
| 精排 | 500 → 20 | 多任务模型 + 个性化权重 + 多样性控制 | 100-500ms | 优先展示高性价比、长续航车型 |
| 重排 | 20 → 最终10 | 业务规则调整(促销、广告) | <10ms | 插入广告、置顶促销信息 |
通过这一流程,用户搜索“2轮电动车”时,既能快速获得结果,又能看到贴合自身需求的高质量商品排序。
六、粗排模型LR训练
在搜索阶段,需要提供给当前用户的数据和召回的商品清单,那么在训练粗排模型的时候,比如LR,样本数据的特征和标签分别是什么?
在搜索系统中,粗排模型的训练数据构建需结合用户行为日志和系统反馈。以下是逻辑回归(LR)等轻量模型训练时的样本特征与标签定义:
6.1. 标签(Label):用户行为反馈
- 定义:标签表示用户对某个候选商品的即时反馈,通常为二分类问题:
- 正样本(Label=1):用户点击/购买了该商品。
- 负样本(Label=0):商品曝光但用户未点击。
- 数据来源:
从搜索日志中提取用户请求(Query)及对应的召回商品列表,记录曝光与点击行为。
示例:
用户搜索“运动鞋”,系统召回100个商品,用户点击了其中3个,则生成3条正样本和97条负样本。
6.2. 特征(Features):多维信息编码
特征需覆盖用户、商品、上下文及交互信息,分为以下四类:
(1) 用户特征
- 基础画像:性别、年龄、城市、注册时长、消费等级。
- 行为序列:
- 短期行为:近1小时/天的搜索词、点击商品类别、加购记录。
- 长期行为:过去30天的购买频次、偏好品牌、常购价格区间。
- 统计特征:
- 历史点击率(CTR)、转化率(CVR)。
- 特定类目活跃度(如“运动鞋”类目点击占比)。
特征示例:
- 用户性别:
gender_female=1(One-Hot编码)。 - 用户所在城市:
city=北京→ 映射为城市经济等级(如city_level=1)。 - 近期搜索词:提取TF-IDF向量或关键词Embedding。
(2) 商品特征
- 静态属性:商品ID、类别、品牌、价格、标题关键词、上架时间。
- 动态表现:
- 历史点击率(过去7天)、销量、库存状态、好评率。
- 商品Embedding(通过协同过滤或内容模型生成)。
特征示例:
- 商品价格分桶:
price_bucket=500-1000元。 - 品牌热度:
brand_popularity=0.8(归一化值)。
(3) 上下文特征
- 搜索场景:搜索词(Query)、搜索时间(工作日/周末)、设备类型(手机/PC)。
- 环境信息:网络状态(WiFi/4G)、地理位置(GPS或IP解析)。
特征示例:
- 搜索词与商品标题的匹配度:
query_match_score=0.75。 - 时间特征:小时(
hour=18)通过周期编码(sin(18/24*2π))。
(4) 交叉特征
- 用户-商品交互:
- 用户历史是否点击过同品牌商品(
user_clicked_same_brand=1)。 - 用户偏好价格与商品价格的差异(
price_diff=|用户均价 - 商品价格|)。
- 用户历史是否点击过同品牌商品(
- 用户-搜索词交互:
- 用户过去对搜索词“运动鞋”的点击率(
user_query_ctr=0.12)。
- 用户过去对搜索词“运动鞋”的点击率(
6.3. 训练样本的构建流程
- 数据收集:
- 从日志系统提取用户搜索会话(Session),包含Query、召回商品列表、曝光及点击记录。
- 负采样:
- 仅使用曝光未点击的样本作为负样本(避免选择未曝光商品的噪声)。
- 针对正负样本不均衡问题,可对负样本进行下采样或对正样本加权。
- 特征拼接:
- 将用户特征、商品特征、上下文特征拼接为一条样本的特征向量。
示例样本结构:
| Label | User_Gender | User_City_Level | Item_Price | Query_Match_Score | … |
|---|---|---|---|---|---|
| 1 | 1 | 3 | 799 | 0.82 | … |
| 0 | 0 | 2 | 1200 | 0.45 | … |
6.4. 模型训练与线上推理
(1) 逻辑回归(LR)模型
- 输入:特征向量 X ∈ R d X \in \mathbb{R}^d X∈Rd,权重 W ∈ R d W \in \mathbb{R}^d W∈Rd,偏置 b b b。
- 输出:点击概率 CTR = σ ( W T X + b ) \text{CTR} = \sigma(W^T X + b) CTR=σ(WTX+b),其中 σ \sigma σ 为Sigmoid函数。
- 训练目标:最小化交叉熵损失函数。
(2) 线上推理
- 实时获取用户特征(如城市、近期行为)、商品特征(如价格、类目)、上下文特征(如搜索词)。
- 拼接特征后输入模型,输出CTR得分,按得分排序筛选Top候选。
6.5. 关键注意事项
- 特征实时性:
- 用户近期行为(如近1小时点击)需实时更新,可通过Redis缓存加速。
- 线上线下一致性:
- 离线训练与线上推理的特征处理逻辑(如分桶、Embedding)必须完全一致。
- 冷启动处理:
- 新商品:使用类目平均CTR或内容特征(标题关键词)填充。
- 新用户:依赖基础画像(如城市、设备类型)和默认行为统计。
- 模型评估:
- 离线指标:AUC(衡量排序能力)、Log Loss(衡量概率校准度)。
- 线上指标:曝光点击率(CTR)、转化率(CVR)。
6.6. 训练模型的样本总结
- 标签:用户对召回商品的点击行为(0/1)。
- 特征:用户画像、商品属性、上下文信息及交叉关系的多维编码。
- 目标:通过轻量模型(如LR)快速预测CTR,高效筛选高潜候选,为精排阶段提供优质输入。

















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









