






任务描述
将循环任务(RNN)应用在图像分割上,需要对网络结构进行设计。
任务选择:文本情感分类(正向,负向)
选择的网络结构:LSTM
语言:python
框架选择:pytorch(主框架,构建网络结构)
其他辅助框架:pickle(python 的文件库。由于数据集的一部分放在pkl文件里,需要pickle库进行读取)
tqdm (UI方面的库,用于添加进度条,方便观察计算的进度)
数据集:aclImdb(大型电影评论数据集)
原理
什么是RNN
RNN是循环神经网络。
为了区别RNN,需要将RNN和简单的全连接神经网络做比较。
全连接神经网络:

全连接神经网络都是由三个层构成的,输入层用于输入数据,数据可以是图片,文本等任意形式,一般需要经过预处理转化成特征格式进行输入。隐藏层就是由各个神经元构成,隐藏层可以是一层,也可以是多层,层与层之间一般是全连接的,上一层的输出会全部传给下一层的每个神经元作为输入,每一层的神经元输入输出大小不同,每一条链接的权值不同。最后是输出层,输出的数据一般是特征提取过后的数据,将测试集的输出结果与训练好的结果进行比较,得出最相似的答案。类似于人类大脑的(联想)。
循环神经网络

循环神经网络也分为三层。输入层,隐藏层,输出层的意义,分工和全链接神经网络相同。
不同的是,如上图,隐藏层被化成了一个循环。数据会在隐藏层的神经元中进行循环。
对于第i次循环,都有两个输入和两个输出。输入分别是Xi和S(i-1),这个Xi是输入数据的第i个,U表述权值矩阵,因此真正接受到的数据是Xi*Ui,另一个输入是S(i-1)是上一次循环的输出。输出的两个数,一个是w,作为下一次循环的一个输入,即w=Si,另一个输出是传给输出层的,V也表示一个权值矩阵,因此同理,输出层得到的数字是Vi*Si。
在每一次循环中,x不一定总是相同的,而且U代表的是一个权值矩阵。经过了可以自定义的若干次循环之后,得出了输出结果。
为了便于理解,可以将RNN展开成如下图的样子:

简而言之,RNN就是:循环迭代,加权输入,加权输出。
LSTM原理
LSTM是一种特殊的RNN结构,先看一下LSTM的结构:

与上面的RNN展开结构对比,会发现由两处地方是不同的。
第一处:隐藏层的内部结构。隐藏层不是简单的一个元,而是出现了运算结构,后面会分析每个部分的具体作用。
第二处:层与层之间的输入输出交换。从一个(即上文提到的si)变成了两个,很明显层与层之间由两条黑色箭头链接。
接下来解析隐藏层内部结构的作用:
遗忘门

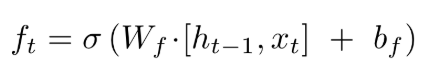
通过上一层的输出h和输入层的加权输入x,用以上公式算出的f,是一个在0到1之间的数字,将这个数字传递给c中的每一个数字,决定其是否被遗忘。0表示丢弃,1表示完全不遗忘。
更新门

下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量c,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
然后使用下图的结构继续运算:

把旧状态与 ft 相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*c。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
丢弃旧代词的性别信息并添加新的信息的地方。
输出门

运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1到 1之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
实现方法
代码见这里
注:数据集所含txt文件过多,已经压缩成zip文件,是多分卷压缩,在当前目录解压即可运行。
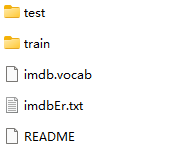
项目文件摆放结构
本次选用的数据库是aclImab,是一个大型电影评论数据库。
本项目的摆放结构如下:

其中data里面是aclImdb数据集:

数据集内部是:
model里面是一些pkl文件,初始时只有ws.pkl,运行完成后会生成其他的,作为辅助记录文件。
设置参数
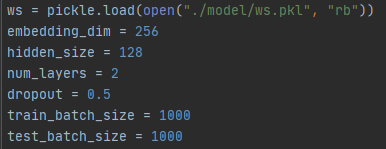
ws是用WordSequence结构体打开文件并序列化。
hidden_size=128表示循环的次数是128.
batch_size是每一批进入网络的数据个数,由于都是文本,比较小,因此设为1000.
eopch在main函数的循环里,这里由于计算资源有限,设为5,进行5个训练周期。
输入数据库
先用如下结构体将文件序列化,方便输入。

再用如下函数,读取序列化之后的数据内容。

最后,用如下函数,将数据内容转化成输入层需要的样子,进行输入。

构建模型

以上代码通过pytorch库里自带的LSTM函数构建了LSTM模型。其中forword函数表示将循环次数向前推进,作为输入也需要上一层的输出值。
运行结果

可以看出随着周期数的增多,准确度也在不断增多,最后大约在84%。
如果拥有更多的计算资源和时间,可以达到99%以上的准确度。















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









