










数据集
利用Kaggle上的一个公开数据集,下载连接如下:
https://www.kaggle.com/datasets/alxmamaev/flowers-recognition
其是一些花的照片,共有5类,四千多张照片。
数据处理
整个数据集并不大,因此可以将其先读入到内存(显存中),而不再需要每次要用到的时候再从硬盘中读取,能够有效地提升运行速度。
而图片的数量并不多,因此还需要用到图片增广技术。
读取数据集
Kaggle上的数据已经按照文件夹将图片分好类了,因此读取图片的时候,需要按照文件夹来归类。
class Flower_Dataset(Dataset):
def __init__(self, path , is_train, augs):
data_root = pathlib.Path(path)
all_image_paths = list(data_root.glob('*/*'))
self.all_image_paths = [str(path) for path in all_image_paths]
label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir())
label_to_index = dict((label, index) for index, label in enumerate(label_names))
self.all_image = [cv.imread(path) for path in self.all_image_paths]
self.all_image_labels = [label_to_index[path.parent.name] for path in all_image_paths]
图片增广
考虑花的图片,水平变换之后仍然是一朵花,因此可以使用此种增广方式。
此为,亮度、对比度等调整均可使用。
color_aug = torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
augs = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), color_aug])
迭代器
每次从数据集中抽取一个批量的大小。
一般情况下使用打乱顺序的方式。
train_iter = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers= 4)
test_iter = DataLoader(test_set, batch_size=batch_size, num_workers= 4)
CNN模型
采用经典的resnet模型,由于数据集大小有限,不宜采用过于复杂的网络,故在此选用了resnet18,其共有68层,不算太深,具体结构如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 5] 2,565
================================================================
Total params: 11,179,077
Trainable params: 11,179,077
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 42.64
Estimated Total Size (MB): 106.00
----------------------------------------------------------------
微调技术
考虑到此数据集中的图片与ImageNet比较类似,故可以使用该技术。
唯一需要修改的地方,就是最后一层,将原有的输出设为5。
此外每层的学习率也需要同样修改。
net = torchvision.models.resnet18(pretrained=True)
net.fc = nn.Linear(net.fc.in_features, 5)
nn.init.xavier_uniform_(net.fc.weight)
summary(net , input_size=(3,224,224) , device="cpu")
lr = 0.0005
loss = nn.CrossEntropyLoss(reduction="mean")
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': lr * 80}],lr=lr, weight_decay=0.001)
训练
此部分与其他神经网络较为类似,就不在赘述。
from tqdm import tqdm
import numpy as np
#Training
Accuracies = []
Losses = []
T_Accuracies = []
T_Losses = []
for epoch in range(epochs):
net.train()
loop = tqdm(enumerate(train_iter), total = len(train_iter)) # 定义进度条
loop.set_description(f'Epoch [{epoch+ 1}/{epochs}]')# 设置开头
T_Accuracies.append(0)
T_Losses.append(0)
for index, (X, Y) in loop:
scores = net(X)
l = loss(scores, Y)
trainer.zero_grad()
l.backward()
_ , predictions = scores.max(1)
num_correct = (predictions == Y).sum()
running_train_acc = float(num_correct) / float(X.shape[0])
if index == 0:
T_Accuracies[-1] = running_train_acc
T_Losses[-1] = l.item()
else:
T_Accuracies[-1] = T_Accuracies[-1] * 0.9 + 0.1 * running_train_acc
T_Losses[-1] = T_Losses[-1] * 0.9 + 0.1 * l.item()
loop.set_postfix(loss='{:.3f}'.format(T_Losses[-1]), accuracy='{:.3f}'.format(T_Accuracies[-1] )) # 定义结尾
trainer.step()
pass
a , b = testing()
Accuracies.append(a)
Losses.append(b)
结果
根据训练集与测试集的数据,绘制出如下图像:
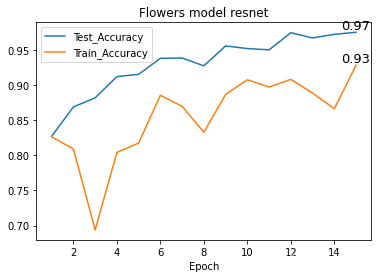
可以看到无论是训练集还是测试集的正确率都比较高,说明微调技术是有用的。
而且测试正确率在第五轮的时候已经超过了90%,可以说在短时间内就达到了一个较高的水平。
此外,训练集正确率相比于测试集正确率偏低,这是由于在训练集上使用了图像增广而测试集没有的。















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









