







 本文提炼了Lowe的SIFT论文,介绍了SIFT特征的检测、定位、方向分配及描述符构造过程。通过尺度空间极值检测确定关键点,然后进行精确定位,排除边缘响应。为关键点分配方向实现旋转不变性,并给出128维局部图像描述符。应用于对象识别时,采用关键点匹配和近似最近邻搜索策略。
本文提炼了Lowe的SIFT论文,介绍了SIFT特征的检测、定位、方向分配及描述符构造过程。通过尺度空间极值检测确定关键点,然后进行精确定位,排除边缘响应。为关键点分配方向实现旋转不变性,并给出128维局部图像描述符。应用于对象识别时,采用关键点匹配和近似最近邻搜索策略。
Distinctive Image Featuresfrom Scale-Invariant Keypoints
本文主要是对Lowe SIFT论文的提炼,标注自己阅读论文时需要重点理解的知识点,以备日后回顾时,无需从头看论文。(仅供他人参考)
1. Introduction
- Scale-space extrema detection:
- Keypoint localization
- Orientation assignment
- Keypoint descriptor
2. Related research
…..
3. Detection of scale-space extrema
Detecting locations that areinvariant to scale change of the image can be accomplished by searching for stable featuresacross all possible scales, using a continuous function of scale known as scale space (Witkin,1983).
- 构建尺度空间
- LoG近似DoG找到关键点<检测DOG尺度空间极值点>

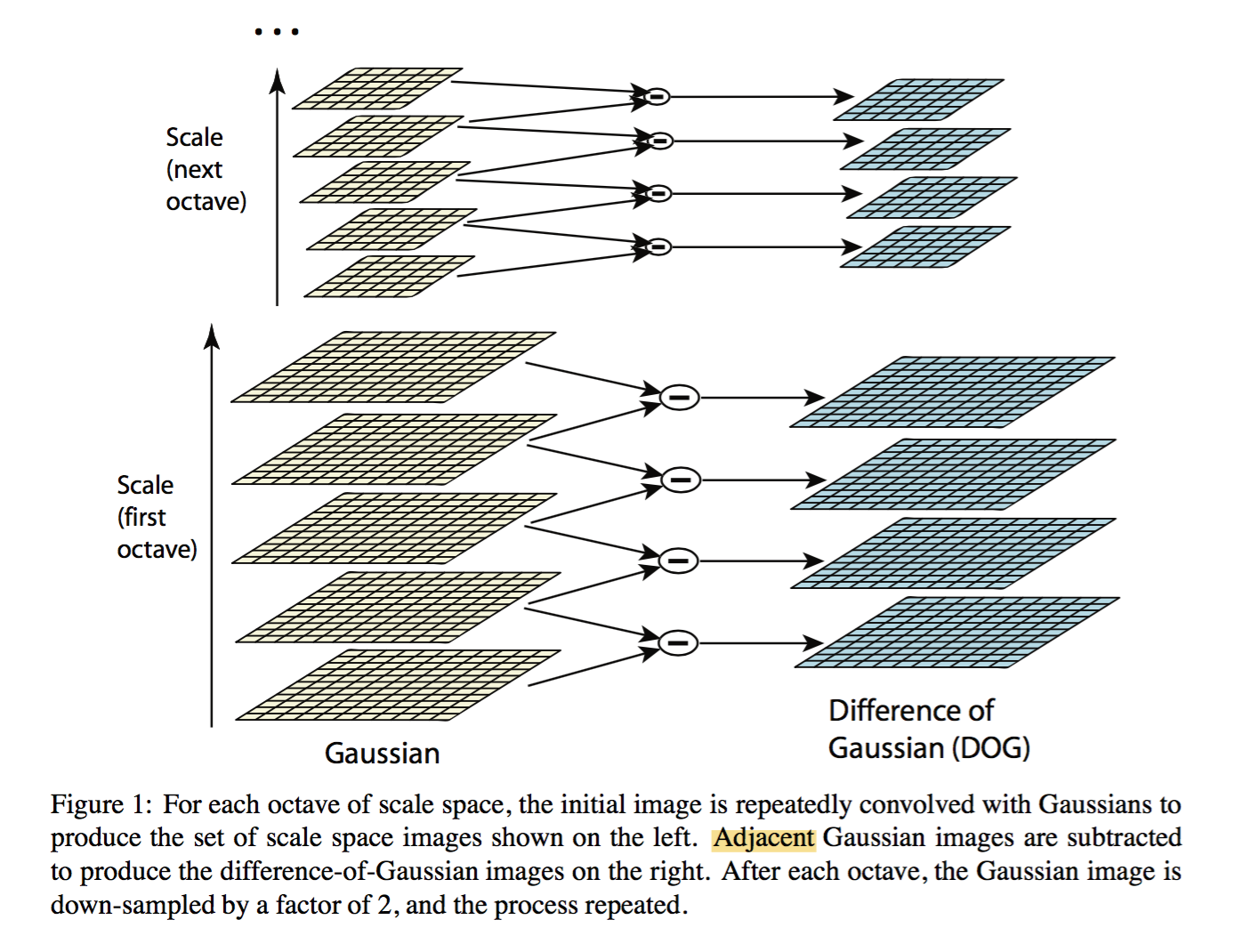
3.1 Local extrema detection
In order to detect the local maxima and minima of D(x, y, σ), each sample point is comparedto its eight neighbors in the current image and nine neighbors in the scale above and below(see Figure 2). It is selected only if it is larger than all of these neighbors or smaller than allof them. The cost of this check is reasonably low due to the fact that most sample points willbe eliminated following the first few checks.

3.2 Frequency of sampling in scale
To summarize, these ex
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7610
7610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









