






决策树基础
决策树理论简单介绍
决策树是数据挖掘十大算法之一,其流程大致可总结为:是否满足某类条件?是则属于1类;否则属于2类。类似于IF…ELSE的问题。正如西瓜书中所说:“我们要判断这个瓜是好瓜还是坏瓜,可以先判断其色泽,若是青绿色再判断其根蒂,若是蜷缩状再判断其敲声,若是浊响则可得出这个瓜为好瓜”。接下来先从决策树的基本理论开始说起,看看决策树是如何解决问题的。
仅作为个人学习过程笔记记录使用
Reference:《机器学习》(西瓜书),《python数据分析与挖掘》
分支依据
通常情况下,决策树判断问题并不会一跃而就,而是需要通过层层递进的方式进行判断,那么就会有个问题:如何进行分支?仍然是前文的例子,为何色泽这个属性其青绿色就要分支?分支的依据是什么?接下来就看看决策树的几种常用的分类依据。
信息熵
话不多说直接给定义:
E
n
t
(
D
)
=
−
∑
k
=
1
∣
y
∣
p
k
l
o
g
2
p
k
Ent(D) = -\sum_{k = 1}^{|y|} p_{k} log_{2}p_{k}
Ent(D)=−k=1∑∣y∣pklog2pk
其中,k的取值为1,2,…,|y|,
D
D
D表示当前的样本集合,
E
n
t
(
D
)
Ent(D)
Ent(D)的数值越小,表示D的信息的纯度越大。
信息增益
信息熵的定义如上,其为表示信息的集合纯度最常见的一种指标。考虑到一个样本中可能有V个指标,则可能会产生V个分支节点,若记第v个分支节点上的样本为
D
v
D^{v}
Dv,其信息熵则可轻易算出;再考虑到不同的分支节点中的样本数可能不同,则赋予其权重:
∣
D
v
∣
∣
D
∣
\frac{|D^{v}|}{|D|}
∣D∣∣Dv∣,即样本数越多则对分支节点的影响就越大,则定义一个新的指标:信息增益,定义如下:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
n
d
(
D
v
)
Gain(D, a) = Ent(D) - \sum_{v = 1}^{V}\frac{|D^{v}|}{|D|}End(D^{v})
Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣End(Dv)
其中,a表示属性取值。一般来说,信息增益越大则使用属性a来进行划分所获得的“纯度”得到较大的提升。ID3算法也是选择了信息增益来等进行划分属性。
增益率
从信息增益的定义可以看出,该指标对于样本数较多的属性具有一定的偏好,为减少这种偏好所可能带来的不良影响,可引入增益率的概念。C4.5决策树便是基于该种算法作为分支条件的,其定义如下:
G
a
i
n
R
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
GainRatio(D, a) = \frac{Gain(D, a)}{IV(a)}
GainRatio(D,a)=IV(a)Gain(D,a)
其中
I
V
(
a
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
l
o
g
2
∣
D
v
∣
∣
D
∣
IV(a) = -\sum_{v = 1}^{V} \frac{|D^v|}{|D|} log_2 \frac{|D^v|}{|D|}
IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣称为属性a的“固有值”。属性a的可能取值数目越多,则
I
V
(
a
)
IV(a)
IV(a)的数值越大。
值得注意的是,增益率可能可能取值数目较少的属性有所偏好,因此C4.5算法并不是直接选择增益率最大的候选划分属性,而是通过一种启发式算法:先从候选划分属性种找出信息增益高于平均水平的属性再从中选择增益率最高的。
基尼系数
著名的CART决策树算法便是采用了基尼系数来选择划分属性的,我们这样定义基尼系数:
G
i
n
i
(
D
)
=
∑
k
=
1
∣
γ
∣
∑
k
′
≠
k
p
k
p
k
′
=
1
−
∑
k
=
1
∣
γ
∣
p
k
2
Gini(D) = \sum_{k = 1}^{|\gamma|}\sum_{k' \neq k} p_k p_{k'} = 1 - \sum_{k = 1}^{|\gamma|} p_k^2
Gini(D)=k=1∑∣γ∣k′=k∑pkpk′=1−k=1∑∣γ∣pk2
直观来说,
G
i
n
i
(
D
)
Gini(D)
Gini(D)反映了数据集D种随机抽取两个样本,其类别标记不一致的概率。因此
G
i
n
i
(
D
)
Gini(D)
Gini(D)越小,表示D的纯度越高。
对于属性a,其基尼系数表示为:
G
i
n
i
I
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
GiniIndex(D, a) = \sum_{v = 1} ^{V}\frac{|D^v|}{|D|}Gini(D^v)
GiniIndex(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
于是,对于A的各个候选集合中选取基尼系数最小的a属性作为分支属性。
剪枝思想简介
在决策树中,常常会出现“分支过细”的情况,这就是所谓的过拟合。而剪枝处理顾名思义便是将过细的、无用的分支进行剪除,这是解决决策树过拟合的主要手段。
预剪枝
即在进行分支之前,对其分支策略进行评估,判断是否对性能提升有所帮助。
例如,对于某个决策树模型,进行某种划分方式之前的模型精度为78%,而进行该种划分方式之后的模型精度为68%,显然该种划分使得模型精度下降了,故不做划分。这种思想就被称为预剪枝
正所谓有得必有失,预剪枝虽然可避免过拟合,但该种剪枝方式可能会给模型带来欠拟合的风险。
后剪枝
作为预剪枝的对立面,后剪枝则是在决策树建立完成后进行的。对每个已进行的分支进行“是否剪枝”的评估。举个例子,若一个决策树模型建立好后的模型精度为48%,对1号叶子节点进行评估:剪枝后总体模型的精度将变为12%,显然不剪枝;对2号叶子节点进行评估:剪枝后总体模型的精度将变为76%,显然需要进行剪枝。
后剪枝决策树的欠拟合风险很小,泛化能力往往优于预剪枝决策树,但其进行的剪枝评估需要自底向上地进行逐一考察,其所带来的开销比预剪枝和未剪枝决策树都大得多。
python实现
分类问题的应用
本节例题将选用数据挖掘中经典数据集——泰坦尼克号乘客信息分析生存与否的问题,并通过决策树算法解决该分类问题。基本流程:数据预处理、交叉验证选取最优超参数、建立模型、可视化以及预测。
数据预处理
· 部分数据展示:
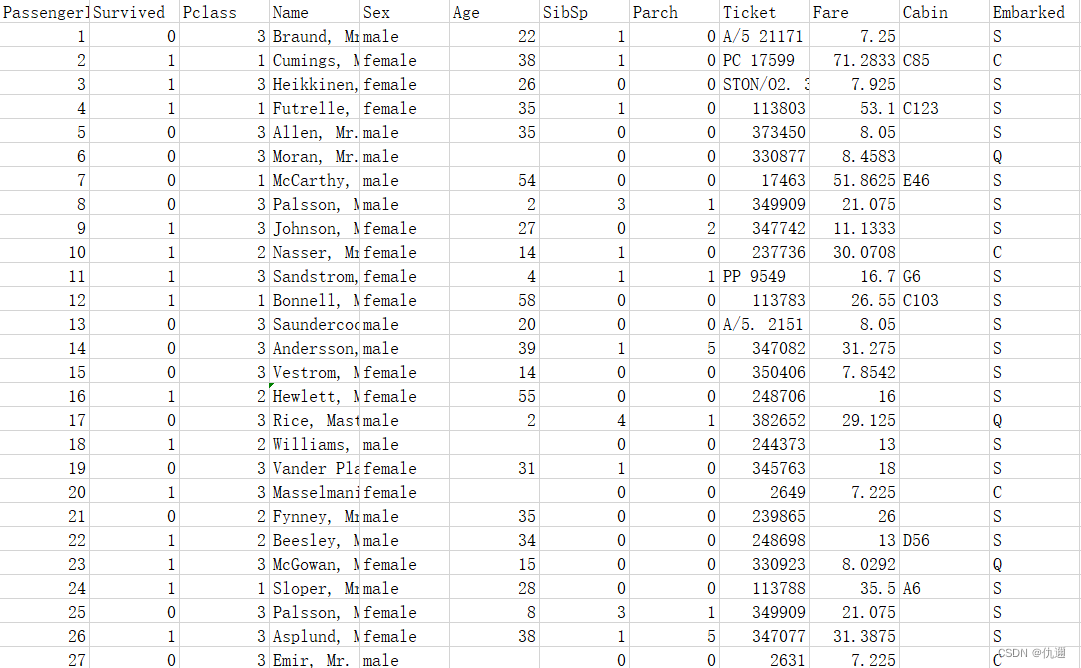
· 数据预处理:
①删除无用变量: 将数据中的无用变量进行删除,采用pandas库中的.drop()函数,将数据集的“乘客ID”,“姓名”,“船票信息”以及“客舱信息”进行删除。
②缺失值填充: 通过.isnull()函数将各个变量的缺失值个数进行分析,结果如下。发现age数据空缺最多,embarked数据有少量空缺。
对于age:对不同的性别的平均年龄进行填补空缺值。
对于embarked:使用其众数进行填充。
[5 rows x 12 columns]
Survived 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
Embarked 2
dtype: int64
③ 哑变量的处理: 对于数据集中的一些分类变量进行处理,将其化作哑变量再进行建模。
数据清洗部分代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Titanic = pd.read_csv(r'Titanic.csv')
print(Titanic.head())
## 数据清洗:
## 乘客编号,姓名,船票信息,客舱信息为无用变量
## 船舱等级为哑变量,需要做类别的哑变量处理
## Sex and Embarked均为离散的字符型变量,需要重新编码,因子化处理、one-Hot编码或哑变量等
## 数据清晰代码:
Titanic.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis = 1, inplace=True)
print(Titanic.isnull().sum(axis = 0)) #检查每个属性下的缺失值个数
# 确实值采用众数填充的方式 and 均值填充:age缺失值较多不直接用均值填充,而是按照性别对客户的缺失
# 年龄进行分组填充
fillna_Titanic = []
for i in Titanic.Sex.unique():
update = Titanic.loc[Titanic.Sex == i, ].fillna(value = {'Age':
Titanic.Age[Titanic.Sex == i].mean()}) #将该性别下的平均年龄作为空缺值填充
fillna_Titanic.append(update)
Titanic = pd.concat(fillna_Titanic)
# 使用embarked的众数填充:
Titanic.fillna(value = {'Embarked': Titanic.Embarked.mode()[0]}, inplace=True)
# 哑变量处理:
# 将Pclass属性的数据转变为类别型变量
Titanic.Pclass = Titanic.Pclass.astype('category')
# 哑变量:
dummy = pd.get_dummies(Titanic[['Sex', 'Embarked', 'Pclass']])
Titanic = pd.concat([Titanic, dummy], axis = 1)
Titanic.drop(['Sex', 'Embarked', 'Pclass'], inplace = True, axis = 1)
最优超参数搜寻
决策树的超参数:树的最大深度(max_depth)、树的每个节点能够分割的最小数值(min_samples_split)以及每棵决策树叶节点最小样本量(min_samples_leaf)
采用网格搜索法,使用GridSearchCV()函数进行搜寻。代码如下:
# 决策树模型建立:
from sklearn import model_selection
predictors = Titanic.columns[1:] #是否生存作为需要预测的值
X_train, X_test, y_train, y_test = model_selection.train_test_split(
Titanic[predictors], Titanic.Survived, test_size = 0.25, random_state = 1234)
from sklearn.model_selection import GridSearchCV ##网格法的类
from sklearn import tree
# 预设各参数的不同选项值
max_depth = [2, 3, 4, 5, 6] #决策树的最大深度取值
min_samples_split = [2, 4, 6, 8] # 决策树每个节点能够分割的最小数,默认为2
min_samples_leaf = [2, 4, 8, 10, 12] # 每棵决策树叶节点最小样本量,默认为1
# 将各个参数以字典形式组织起来:
parameters = {'max_depth': max_depth, 'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
# 网格搜索法,测试不同的参数值:
grid_dcateg = GridSearchCV(estimator=tree.DecisionTreeClassifier(),
param_grid=parameters, cv = 10)
# 学习器;学习器的超参数取值;cv = k,k为k折交叉验证的k
grid_dcateg.fit(X_train, y_train)
print("最佳组合的参数值:", grid_dcateg.best_params_)
# 经过10次交叉验证,得到最佳参数值
# OutPut:最佳组合的参数值: {'max_depth': 6, 'min_samples_leaf': 8, 'min_samples_split': 6}
注. grid_dcateg = GridSearchCV(estimator= , param_grid= , cv= )其中的参数分别为:需要搜寻的模型、超参数取值字典、k折交叉验证迭代次数。将这三个参数设置好后,即为建立好网格搜索模型。
grid_dcateg.fit(X_train, y_train),利用训练集对数据进行初步训练,目的是得到最优的参数组合。
grid_dcateg.best_params_可将最优的参数组合进行输出。
模型建立
通过前文搜寻出的最优超参数组合,设置.DecisionTreeClassifier()函数,建立CART决策树。并通过.fit()函数利用训练集数据进行训练,并分别求出预测集和训练集上的准确率。
# 构建分类决策树:
CART_Class = tree.DecisionTreeClassifier(max_depth=6, min_samples_leaf=8,
min_samples_split=6)
# 模型拟合:
decision_tree = CART_Class.fit(X_train, y_train)
# 模型在测试集上的预测
pred = CART_Class.predict(X_test)
# 模型的准确率:
from sklearn import metrics
print('预测集上的准确率:', metrics.accuracy_score(y_test, pred))
print('训练集上的准确率:', metrics.accuracy_score(y_train, CART_Class.predict(X_train)))
### OutPut:预测集上的准确率: 0.8475336322869955,训练集上的准确率: 0.8383233532934131
模型评价——ROC
通过建立ROC曲线,来说明模型的准确性。
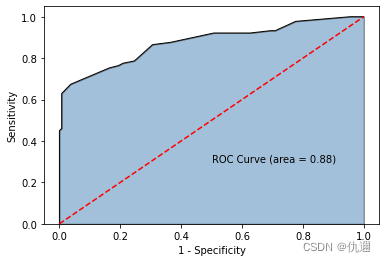
# 绘制ROC曲线
y_score = CART_Class.predict_proba(X_test)[:, 1]
fpr, tpr, threshold = metrics.roc_curve(y_test, y_score)
#计算AUC数值:
roc_auc = metrics.auc(fpr, tpr)
#绘制面积图:
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线和对角线:
plt.plot(fpr, tpr, color = 'black', lw = 1)
plt.plot([0, 1], [0, 1], color = 'red', linestyle = '--')
# 添加文本:
plt.text(0.5, 0.3, 'ROC Curve (area = %0.2f)' %roc_auc)
#添加x轴和y轴:
plt.xlabel('1 - Specificity')
plt.ylabel('Sensitivity')
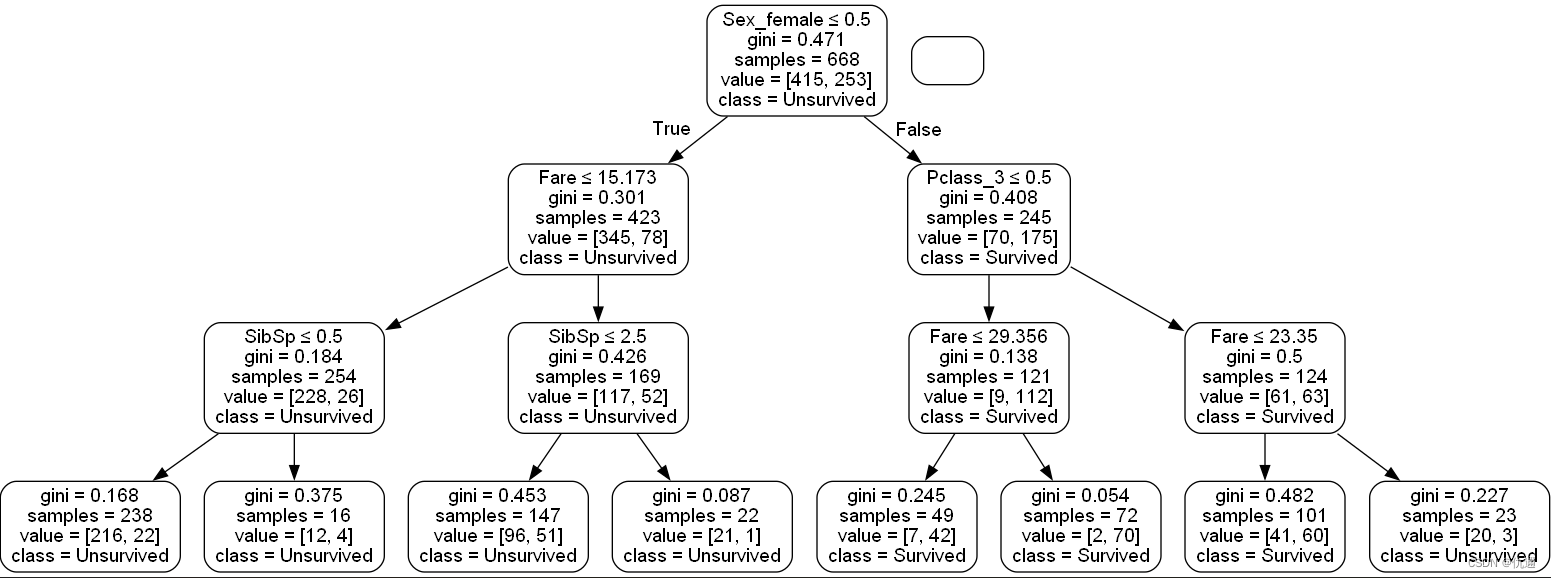
模型可视化
通过Graphviz工具进行可视化,代码及结果如下。
from sklearn.tree import export_graphviz
from IPython.display import Image
import pydotplus
from six import StringIO
dot_data = StringIO()
export_graphviz(
decision_tree,
out_file=dot_data,
feature_names=predictors,
class_names=['Unsurvived','Survived'],
# filled=True,
rounded=True,
special_characters=True
)
# 决策树展现
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
res = Image(graph.create_png())
# 图象保存
graph.write_png("dtr.png")
注.此处为方便展示,将参数进行了缩小,准确率浮动了2%左右
随机森林建立
简介
随机森林是集成算法,其为多个决策树组成的森林,随机体现在了数据的随机生成:从训练集中采用Bootstrap方法进行抽样。其准确率高、运行速度快,被誉为“代表集成学习技术水平的方法”,至今仍是常用的集成学习算法之一。
实现
同样的数据集,接着如下代码:使用ensemble中的RF随机森林函数进行拟合。n_extimators表示RF中的决策树的个数。
###### 随即森林
from sklearn import ensemble
# 构建随机森林
RF_class = ensemble.RandomForestClassifier(n_estimators=200, random_state=1234)
#随机森林拟合
RF_class.fit(X_train, y_train)
#模型在预测集上的预测
RFclass_pred = RF_class.predict(X_test)
#准确率
print('模型在测试集上的准确率:', metrics.accuracy_score(y_test, RFclass_pred))
# OutPut:模型在测试集上的准确率: 0.852017937219731
模型评估及结果分析
通过绘制ROC曲线分析模型的稳定性。发现其AUC数值相比于单个决策树算法有所提升。
y_score = RF_class.predict_proba(X_test)[:, 1]
fpr, tpr, threshold = metrics.roc_curve(y_test, y_score)
roc_auc = metrics.auc(fpr, tpr)
plt.stackplot(fpr, tpr, color = 'steelblue', alpha=0.5, edgecolor = 'black')
plt.plot(fpr, tpr, color = 'black', lw = 1)
plt.plot([0,1], [0, 1], color = 'red', linestyle='--')
plt.text(0.5, 0.3, 'ROC curve area = %0.2f' %roc_auc)
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
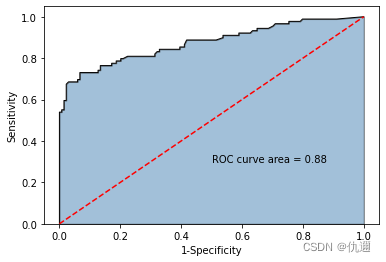
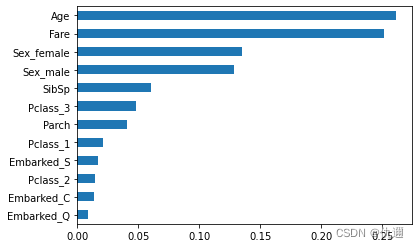
结果分析: 通过对变量的重要性进行排序,前三个变量分别为年龄、性别以及是否为女性,从一定程度上体现了当时在泰坦尼克号上的妇女儿童优先的救援精神。
######结果分析#######
# 变量的重要性数值
importance = RF_class.feature_importances_
# 构建含序列用于绘图
Impt_Series = pd.Series(importance, index = X_train.columns)
# 对序列排序绘图
Impt_Series.sort_values(ascending=True).plot(kind = 'barh')














 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









