









CART:Classfication And Regression Trees分类回归树
# coding=utf-8
#Created on Feb 4, 2011
#Tree-Based Regression Methods
#@author: Peter Harrington
#
from numpy import *
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine)) #map all elements to float()
dataMat.append(fltLine)
return dataMat
def binSplitDataSet(dataSet, feature, value):
mat0 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:] #[0] #根据特征值取样
#'nozero()取:(特征feature列的值>value)的行号、列号,+【0】取行号'
mat1 = dataSet[nonzero(dataSet[:,feature] > value)[0],:] #[0]
return mat0,mat1
def regLeaf(dataSet):#returns the value used for each leaf
return mean(dataSet[:,-1]) #在回归数中,叶节点的模型就是目标变量的均值
def regErr(dataSet):
return var(dataSet[:,-1]) * shape(dataSet)[0] #样本总方差
#Var()-样本的二阶中心矩;var( ,ddof = 1)才是样本方差,
#######将叶节点由常数改成线性函数模型,将数据集格式化成自变量X和目标变量Y,并得到线性回归系数ws#######
def linearSolve(dataSet): #helper function used in two places
m,n = shape(dataSet)
X = mat(ones((m,n))); Y = mat(ones((m,1)))#create a copy of data with 1 in 0th postion
X[:,1:n] = dataSet[:,0:n-1]; Y = dataSet[:,-1]#and strip out Y
xTx = X.T*X
if linalg.det(xTx) == 0.0:
raise NameError('This matrix is singular, cannot do inverse,\n\
try increasing the second value of ops')
ws = xTx.I * (X.T * Y)
return ws,X,Y
def modelLeaf(dataSet):#create linear model and return coeficients
ws,X,Y = linearSolve(dataSet)
return ws
def modelErr(dataSet):
ws,X,Y = linearSolve(dataSet)
yHat = X * ws
return sum(power(Y - yHat,2))
###############找到最佳二元切分方式:特征值唯一、方差最小、样本最小(而不是熵降低最多)############
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
tolS = ops[0]; tolN = ops[1]
#tolS是容许的误差下降值,tolN是切分的最小样本数,均是为了控制函数的停止时机
#if all the target variables are the same value: quit and return value
if len(set(dataSet[:,-1].T.tolist()[0])) == 1: #exit cond 1
return None, leafType(dataSet)
m,n = shape(dataSet)
#the choice of the best feature is driven by Reduction in RSS error from mean
S = errType(dataSet)
bestS = inf; bestIndex = 0; bestValue = 0
#对每一特征下的每一个值进行二元切分,切分后误差越低越好,
for featIndex in range(n-1):
for splitVal in set((dataSet[:,featIndex].T.A.tolist())[0]):#splitVal in set(dataSet[:,featIndex])=>
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)#TypeError: unhashable type: 'matrix'
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
newS = errType(mat0) + errType(mat1)
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#if the decrease (S-bestS) is less than a threshold don't do the split
if (S - bestS) < tolS:
return None, leafType(dataSet) #exit cond 2
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): #exit cond 3
return None, leafType(dataSet)
return bestIndex,bestValue#returns the best feature to split on
#and the value used for that split
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filtering
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)#choose the best split
if feat == None: return val #if the splitting hit a stop condition return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree
#############################################################################
###上面用tolS和tolN控制tree切分的程度,为预剪枝,下面是后剪枝:用trainData训练出tree后,testData来测试,
####若合并叶节点能降低误差,则进行合并(剪枝)
def isTree(obj):
return (type(obj).__name__=='dict')
def getMean(tree):
if isTree(tree['right']): tree['right'] = getMean(tree['right'])
if isTree(tree['left']): tree['left'] = getMean(tree['left'])
return (tree['left']+tree['right'])/2.0
def prune(tree, testData):
if shape(testData)[0] == 0: return getMean(tree) #if we have no test data collapse the tree
if (isTree(tree['right']) or isTree(tree['left'])):#if the branches are not trees try to prune them
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet)
if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet)
#if they are now both leafs, see if we can merge them
if not isTree(tree['left']) and not isTree(tree['right']):
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) +\
sum(power(rSet[:,-1] - tree['right'],2))
treeMean = (tree['left']+tree['right'])/2.0
errorMerge = sum(power(testData[:,-1] - treeMean,2))
if errorMerge < errorNoMerge:
print ("merging")
return treeMean
else: return tree
else: return tree
#######################预测代码 ######################
def regTreeEval(model, inDat):#回归树节点计算
return float(model)
def modelTreeEval(model, inDat):#模型树节点计算
n = shape(inDat)[1]
X = mat(ones((1,n+1)))
X[:,1:n+1]=inDat
return float(X*model)
def treeForeCast(tree, inData, modelEval=regTreeEval):#计算一个数据inData的预测
if not isTree(tree): return modelEval(tree, inData)
if inData[tree['spInd']] <= tree['spVal']:
if isTree(tree['left']): return treeForeCast(tree['left'], inData, modelEval)
else: return modelEval(tree['left'], inData)
else:
if isTree(tree['right']): return treeForeCast(tree['right'], inData, modelEval)
else: return modelEval(tree['right'], inData)
def createForeCast(tree, testData, modelEval=regTreeEval):#由tree预测testData的yHat
m=len(testData)
yHat = mat(zeros((m,1)))
for i in range(m):
yHat[i,0] = treeForeCast(tree, mat(testData[i]), modelEval)
return yHat
#corrcoef(yHat,testData[:,-1],rowvar=0)[0,1] #相关系数越靠近1越好
############################################
#myData=loadDataSet(r'C:\Users\li\Downloads\machinelearninginaction\Ch09\ex0.txt')
#myMat=mat(myData)
#retTree=createTree(myMat)
#print(retTree)
##############################################################
##########用TKinter创建GUI###############################
from tkinter import *
import matplotlib
matplotlib.use('TkAgg')
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
from matplotlib.figure import Figure
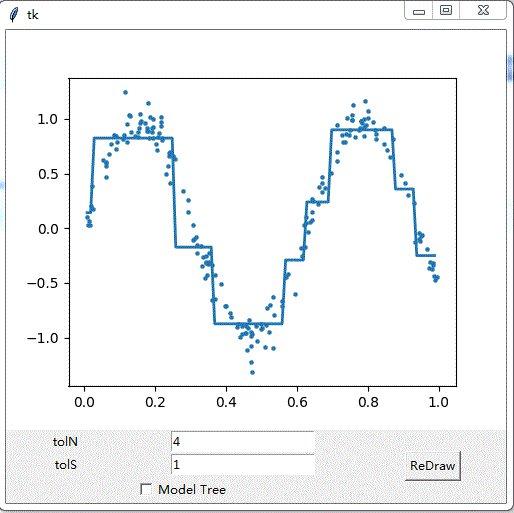
def reDraw(tolS,tolN):
reDraw.f.clf() # clear the figure
reDraw.a = reDraw.f.add_subplot(111)
if chkBtnVar.get():
if tolN < 2: tolN = 2
myTree=createTree(reDraw.rawDat, modelLeaf,\
modelErr, (tolS,tolN))
yHat = createForeCast(myTree, reDraw.testDat, \
modelTreeEval)
else:
myTree=createTree(reDraw.rawDat, ops=(tolS,tolN))
yHat = createForeCast(myTree, reDraw.testDat)
reDraw.a.scatter(reDraw.rawDat[:,0].A.T, reDraw.rawDat[:,1].A.T, s=5) #use scatter for data set
reDraw.a.plot(reDraw.testDat, yHat, linewidth=2.0) #use plot for yHat
reDraw.canvas.show()
def getInputs():
try: tolN = int(tolNentry.get())
except:
tolN = 10
print ("enter Integer for tolN")
tolNentry.delete(0, END)
tolNentry.insert(0,'10')
try: tolS = float(tolSentry.get())
except:
tolS = 1.0
print ("enter Float for tolS")
tolSentry.delete(0, END)
tolSentry.insert(0,'1.0')
return tolN,tolS
def drawNewTree():
tolN,tolS = getInputs()#get values from Entry boxes
reDraw(tolS,tolN)
root=Tk()
reDraw.f = Figure(figsize=(5,4), dpi=100) #create canvas
reDraw.canvas = FigureCanvasTkAgg(reDraw.f, master=root)
reDraw.canvas.show()
reDraw.canvas.get_tk_widget().grid(row=0, columnspan=3)
Label(root, text="tolN").grid(row=1, column=0)
tolNentry = Entry(root)
tolNentry.grid(row=1, column=1)
tolNentry.insert(0,'10')
Label(root, text="tolS").grid(row=2, column=0)
tolSentry = Entry(root)
tolSentry.grid(row=2, column=1)
tolSentry.insert(0,'1.0')
Button(root, text="ReDraw", command=drawNewTree).grid(row=1, column=2, rowspan=3)
chkBtnVar = IntVar()
chkBtn = Checkbutton(root, text="Model Tree", variable = chkBtnVar)
chkBtn.grid(row=3, column=0, columnspan=2)
reDraw.rawDat = mat(loadDataSet(r'C:\Users\li\Downloads\machinelearninginaction\Ch09\sine.txt'))
reDraw.testDat = arange(min(reDraw.rawDat[:,0]),max(reDraw.rawDat[:,0]),0.01)
reDraw(1.0, 10)
root.mainloop()















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









