






文/AI科技前沿观察
2025年4月29日,阿里巴巴正式推出新一代大语言模型通义千问Qwen3,并宣布全面开源!这一消息瞬间引爆AI圈,被誉为“开源大模型王座再易主”的里程碑事件。作为国内首个支持“混合推理”的模型,Qwen3不仅在技术上实现颠覆性创新,更以开源生态加速行业变革。本文将从技术突破、性能表现、应用场景及行业影响四大维度深度解析Qwen3的划时代意义。
一、技术突破:混合推理与超大规模训练
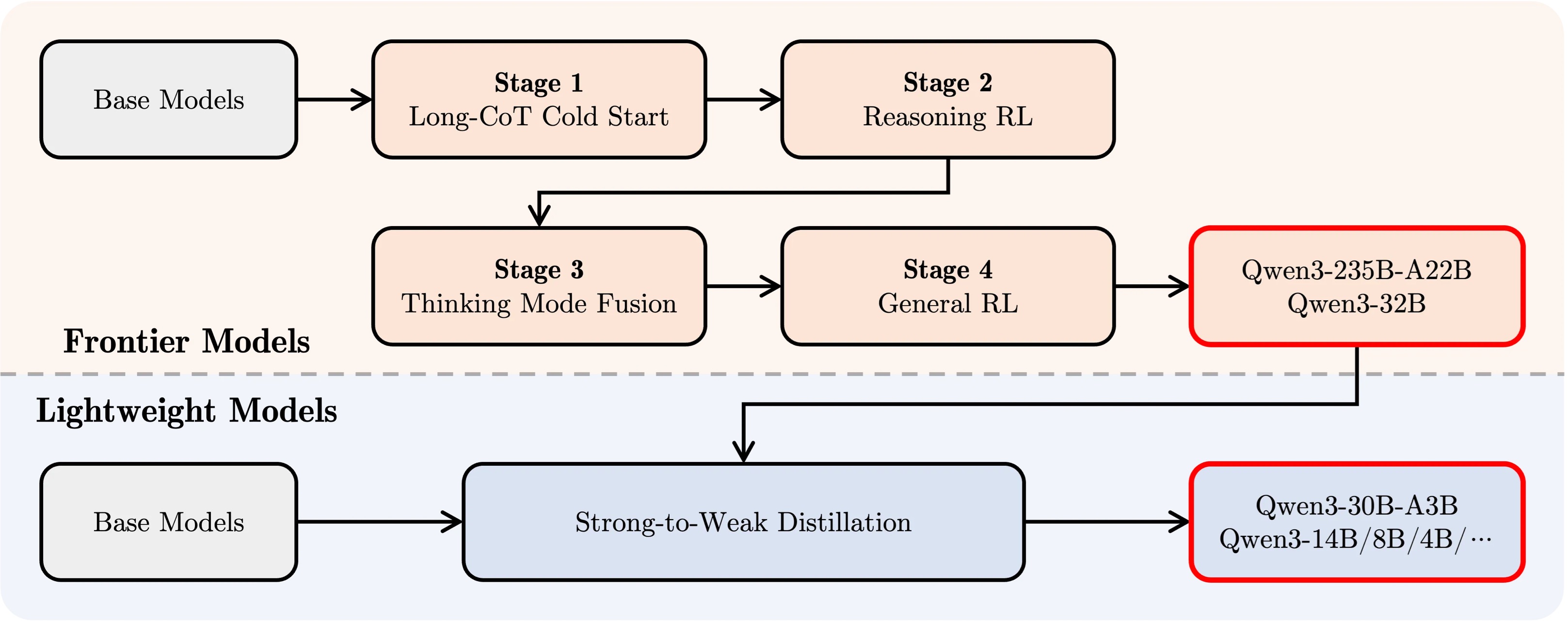
1. 首创“双模式”推理,算力效率翻倍
Qwen3最引人注目的创新是“思考模式”与“非思考模式”动态切换,用户可通过指令(如/think或/no_think)灵活控制模型的推理深度。 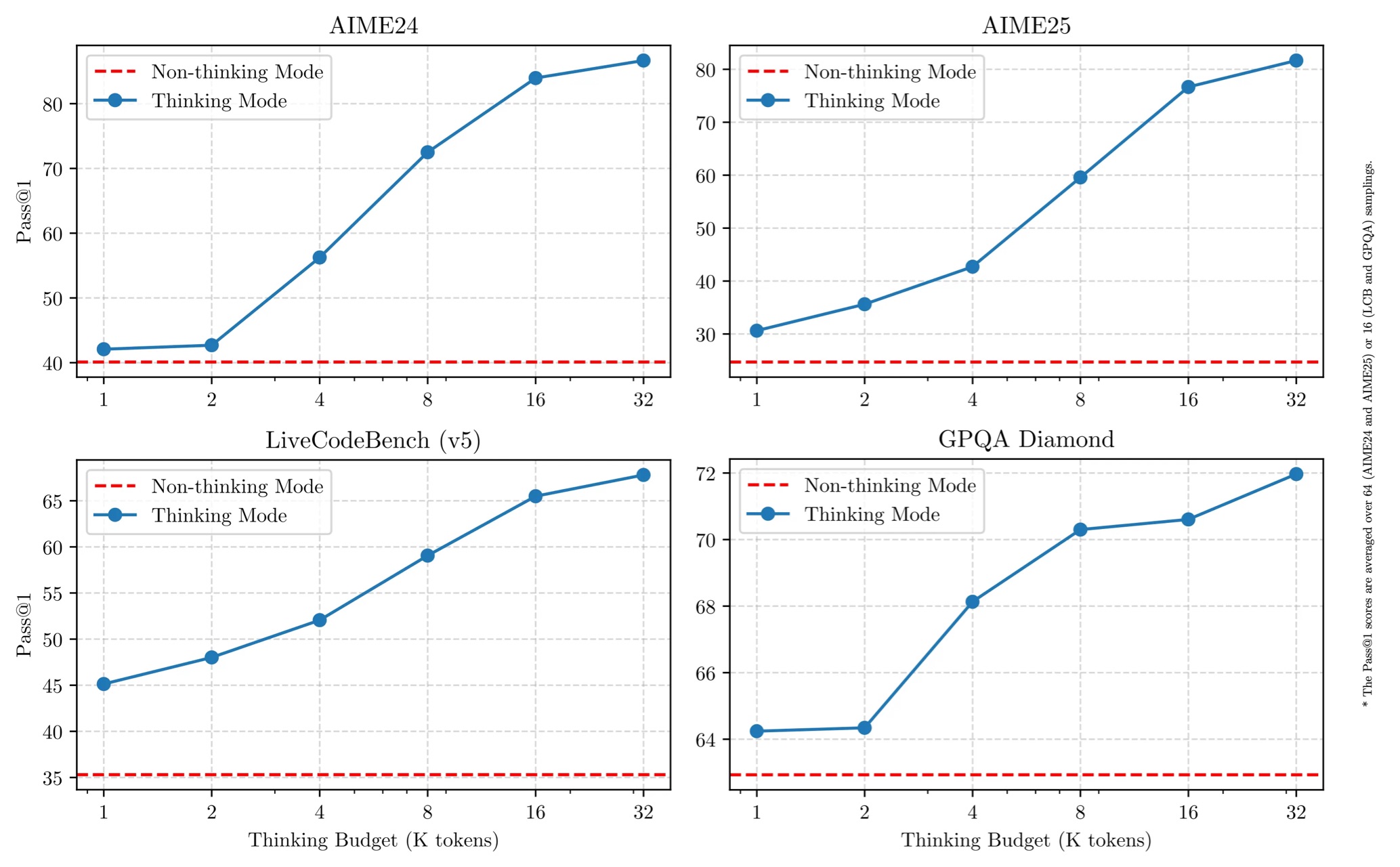
- 思考模式:针对数学推理、代码生成等复杂任务,模型通过长思维链逐步推演,生成精准答案;
- 非思考模式:适用于信息检索、简单对话等场景,模型响应速度提升50%以上,显著降低算力消耗。
这种设计打破了传统大模型“一刀切”的算力分配模式,实现性能与效率的完美平衡。
2. MoE+Dense并行架构,参数效率碾压前代
Qwen3系列包含混合专家模型(MoE)与稠密模型(Dense)两大分支: 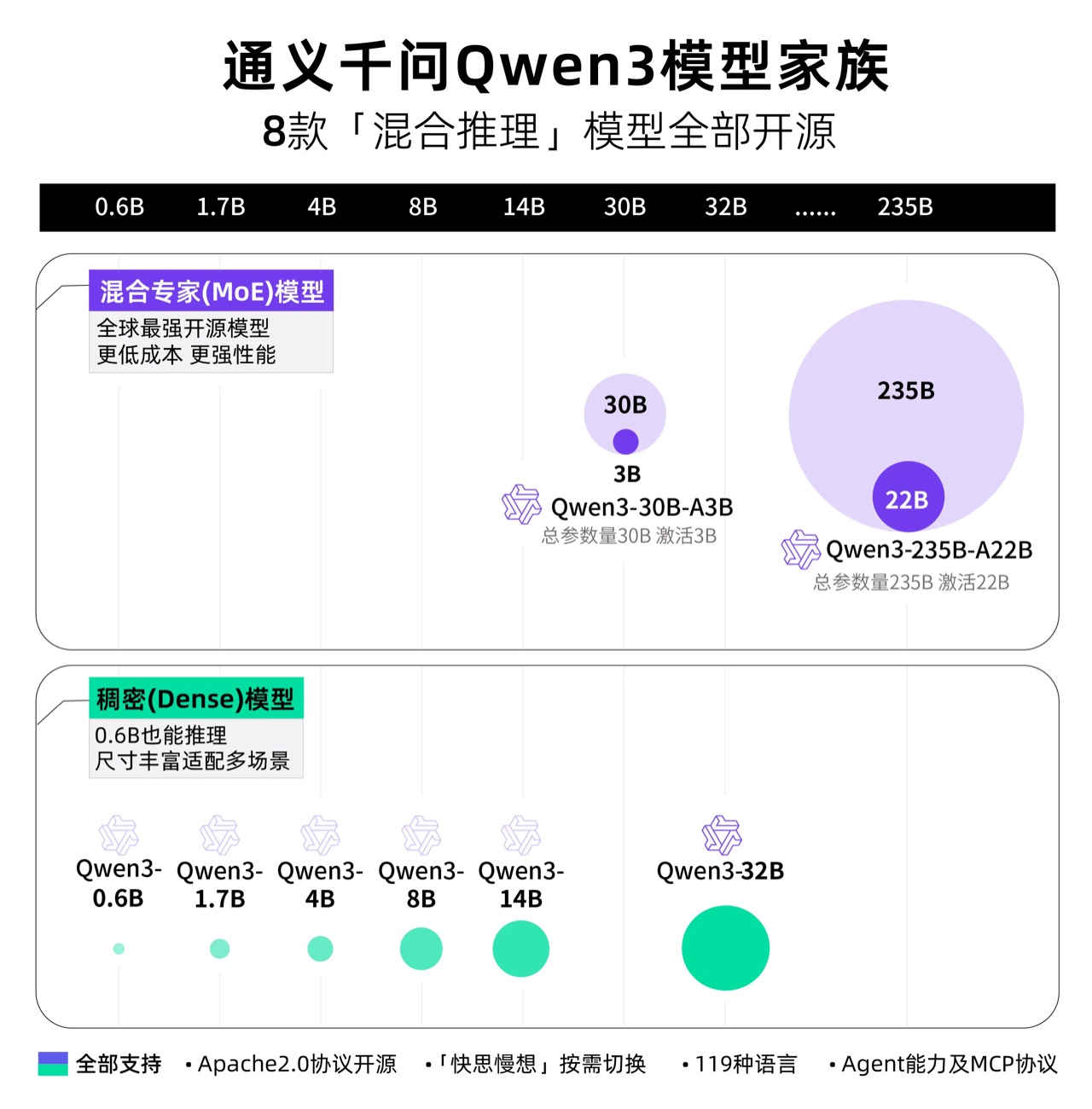
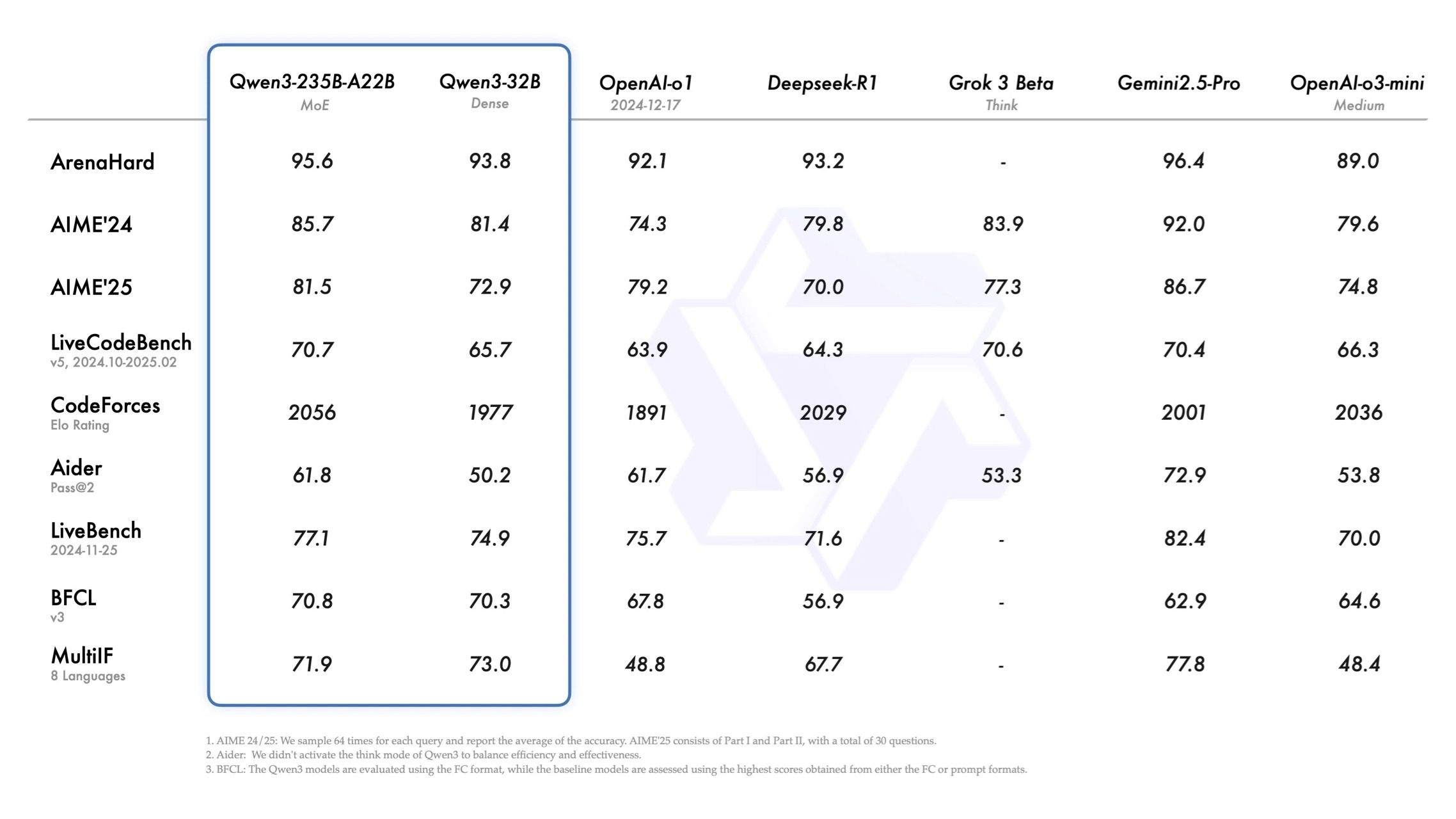
- 旗舰MoE模型:Qwen3-235B-A22B(总参数2350亿,激活参数220亿)在代码、数学任务中媲美DeepSeek-R1、GPT-4o等顶尖模型;
- 小规模MoE:Qwen3-30B-A3B激活参数仅30亿,性能却超越前代Qwen2.5-72B,参数效率提升10倍。
同时,Dense模型覆盖0.6B至32B参数,适配从端侧到云端的全场景需求。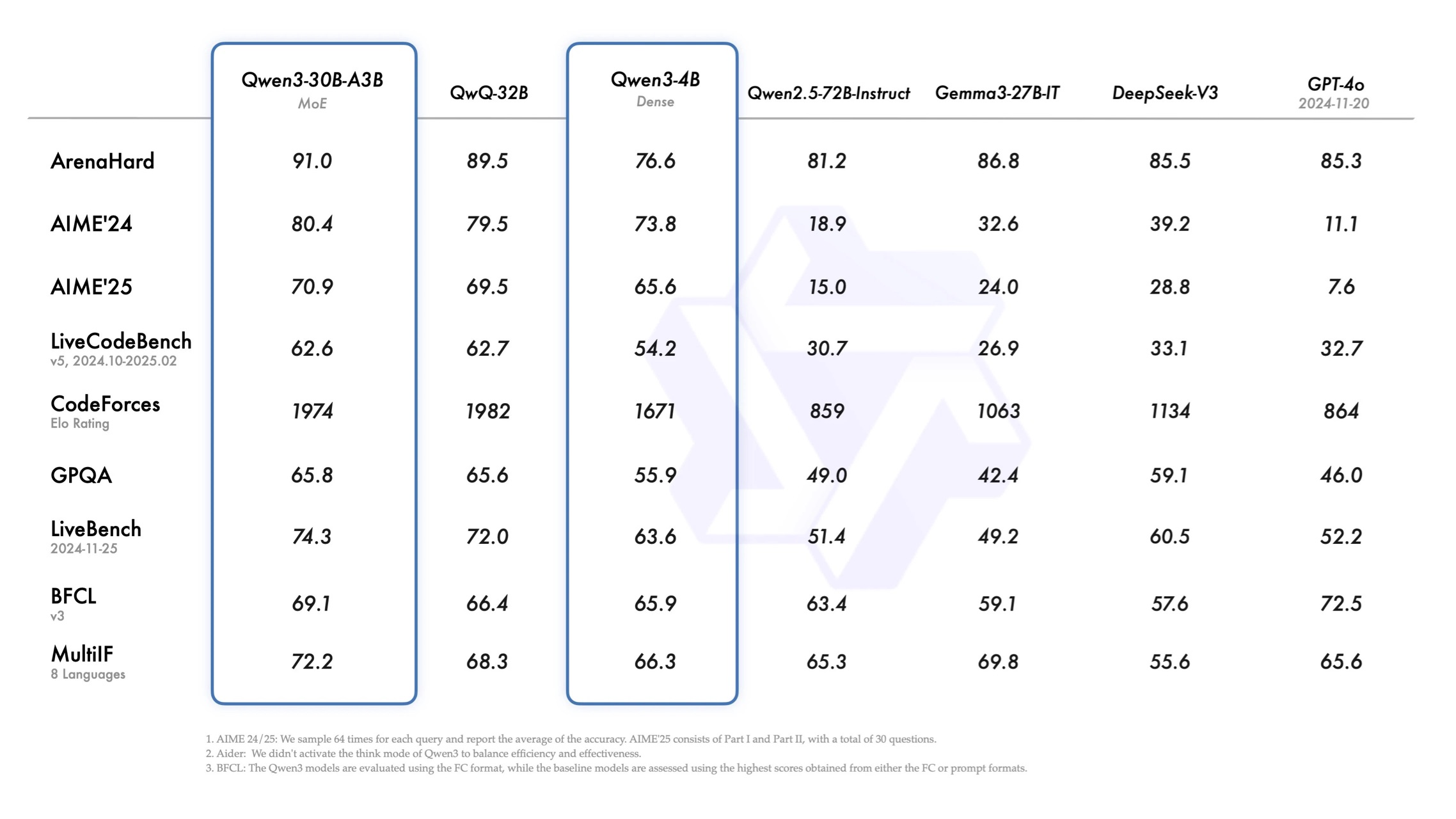
3. 训练规模创纪录,多语言能力登顶
- 数据量:预训练数据达36万亿token(覆盖119种语言),是前代Qwen2.5的2倍;
- 多语言支持:中文表现尤为突出,在弱智吧Benchmark等测试中碾压Llama 3(英文数据占比95%),成为全球开发者中文任务的首选;

- 长文本处理:默认支持32K上下文,用户可自定义扩展至百万级token,性能对标GPT-3.5-turbo-16k。
二、性能表现:全面碾压闭源与开源竞品
1. 基准测试横扫SOTA
Qwen3-235B在权威评测中展现统治级表现:
- 编程:HumanEval得分89.7,超越DeepSeek-R1(88.2)与GPT-4o(87.5);
- 数学:GSM8K准确率95.3%,接近Claude-3.5-Sonnet(96.1%);
- 综合能力:MMLU-Pro、LiveBench等评测中全面领先Llama-3.1-405B。
2. 小模型的逆袭
Qwen3-4B等小型模型性能直逼前代72B版本,企业端侧部署成本降低80%以上。
三、应用场景:从春晚到矿山,AI赋能千行百业
1. 技术落地标杆案例
- 春晚黑科技:2025年春晚中,Qwen3驱动“子弹时间”特效,实现360度环绕视角与3D模型实时渲染,助力《笔走龙蛇》武术表演震撼出圈;
- 行业应用:阿里云联合西安塔力科技推出矿山风险识别系统,在陕煤建新煤矿等场景落地,首次实现大模型在采矿领域的规模化应用。
2. 开发者生态爆发
- 开源工具链:Qwen-Agent框架简化工具调用,支持自定义插件与MCP配置文件,降低开发门槛;
- 社区响应:模型上线24小时内,Ollama等平台火速适配,HuggingFace下载量突破百万。
四、行业影响:开源大模型的鲶鱼效应
1. 技术竞争格局重构
Qwen3以“开源+高性能”策略挑战闭源垄断,推动行业转向低成本、高可控的技术路线。图灵奖得主Yann LeCun评价:“开源模型正超越专有模型”。
2. 商业逻辑颠覆
- 企业服务:阿里云通过开源绑定云服务,开发者使用Qwen3后自然选择阿里云部署,形成生态闭环;
- 硬件市场:DeepSeek等开源模型的成功已引发英伟达股价震荡,Qwen3或进一步冲击AI芯片需求。
3. 未来方向
- 多模态融合:Qwen3-VL视觉模型在13项评测中超越GPT-4o,预示多模态AGI加速到来;
- 长上下文突破:计划扩展至百万级token,解决金融、医疗等领域的超长文档分析需求。
结语:中国AI的“开源革命”
Qwen3的发布不仅是技术突破,更是一场开源生态的胜利。正如阿里CEO吴泳铭所言:“开源是AI普惠的基石。” 从春晚舞台到矿山深处,从开发者社区到全球市场,Qwen3正在重新定义AI的未来。
立即体验Qwen3开源模型
👉 GitHub地址:https://github.com/Qwen
👉 技术文档:https://help.aliyun.com/qwen3
关注我们,获取更多AI前沿洞察!
#AI大模型 #通义千问 #开源革命 #技术突破
参考文献:综合自阿里云官方公告及行业权威报道。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









