








用 GpuGeek 玩转大模型推理与微调实战:高性价比平台打造极致效率体验
🌟嗨,我是LucianaiB!
🌍 总有人间一两风,填我十万八千梦。
🚀 路漫漫其修远兮,吾将上下而求索。
随着大模型技术的持续火热,越来越多开发者和研究者开始涉足大模型推理、微调与部署的实践探索。无论是 LLaMA、Baichuan、ChatGLM 这样的本地化语言模型,还是像 ControlNet、SDXL 这样的图像生成模型,都对 GPU 资源、镜像配置和部署效率提出了极高要求。
我在实际项目中选择使用了 GpuGeek 平台,从模型部署、推理测试到定制化微调,整个流程丝滑高效,大大节省了时间和资源投入。本文将围绕一次基于 LLaMA2-7B 的微调与推理实战,分享具体实践经验,并结合体验总结出 GpuGeek 的两大核心优势。
注册链接:https://gpugeek.com/login?invitedUserId=753279959&source=invited
一、项目背景:LLaMA2-7B 微调与推理部署
项目目标是对 LLaMA2-7B 模型进行指令微调(LoRA)以适配某垂直领域(教育问答),并完成推理部署及API集成。
核心技术路线包括:
- 使用 HuggingFace Transformers + PEFT 进行 LoRA 微调
- 使用 bitsandbytes 进行低比特量化,提升推理效率
- 基于 FastAPI 提供在线接口
- 在 GpuGeek 上完成训练部署全过程
二、为什么选择 GpuGeek?
在挑选云GPU平台时,我对比过多家平台,最终选定 GpuGeek,原因如下:
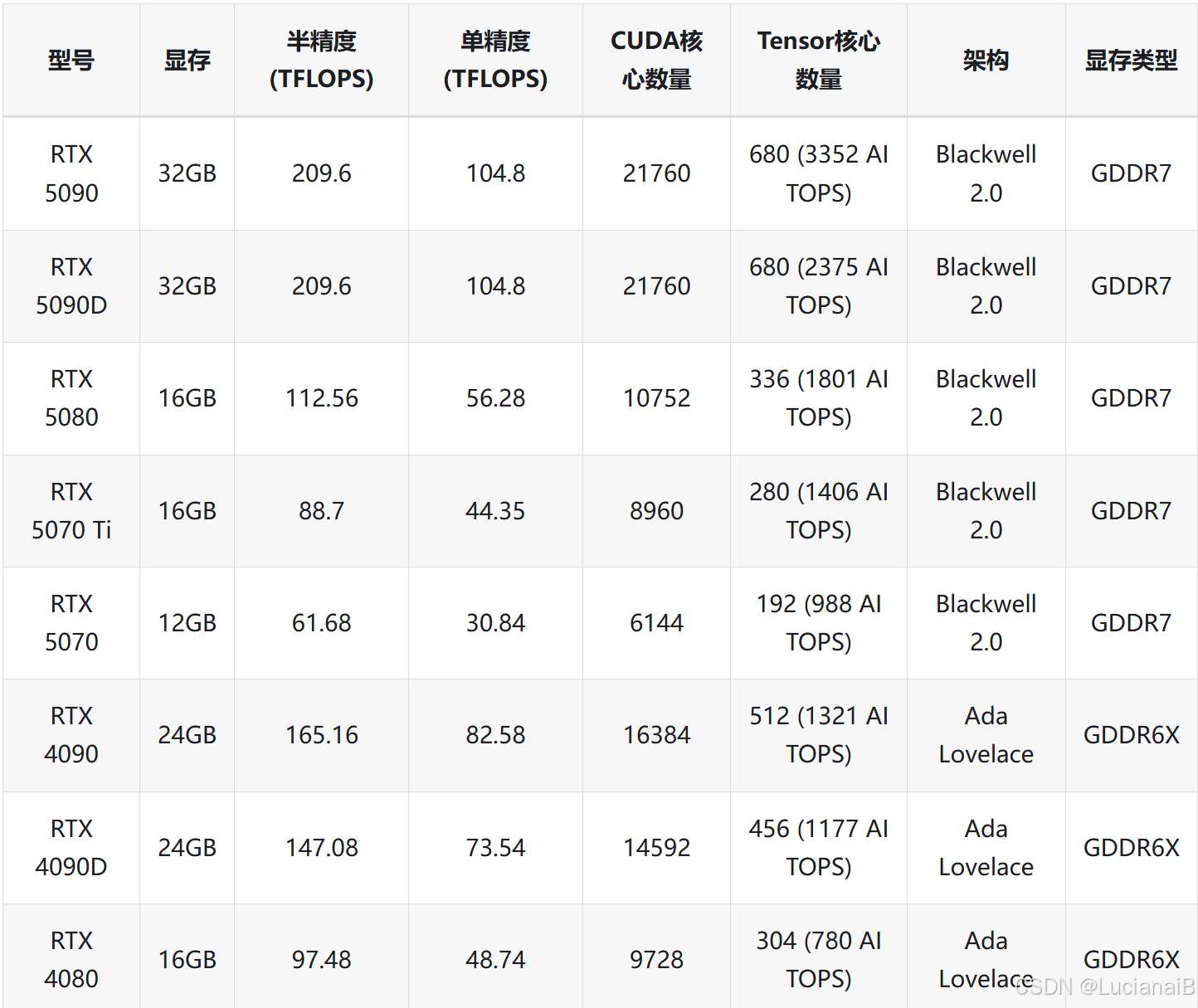
优势一:显卡资源充足,节点种类丰富
在微调阶段,我需要 A100 40GB 以上显存的显卡,GpuGeek 上不仅提供了 A100、H100、3090、4090 等多种节点,而且资源不抢、不排队,几乎随开随用,避免了因排队导致的调度延迟。
此外,平台支持按需选择不同地区节点,适配不同网络环境,极大提升了训练与部署的灵活性。
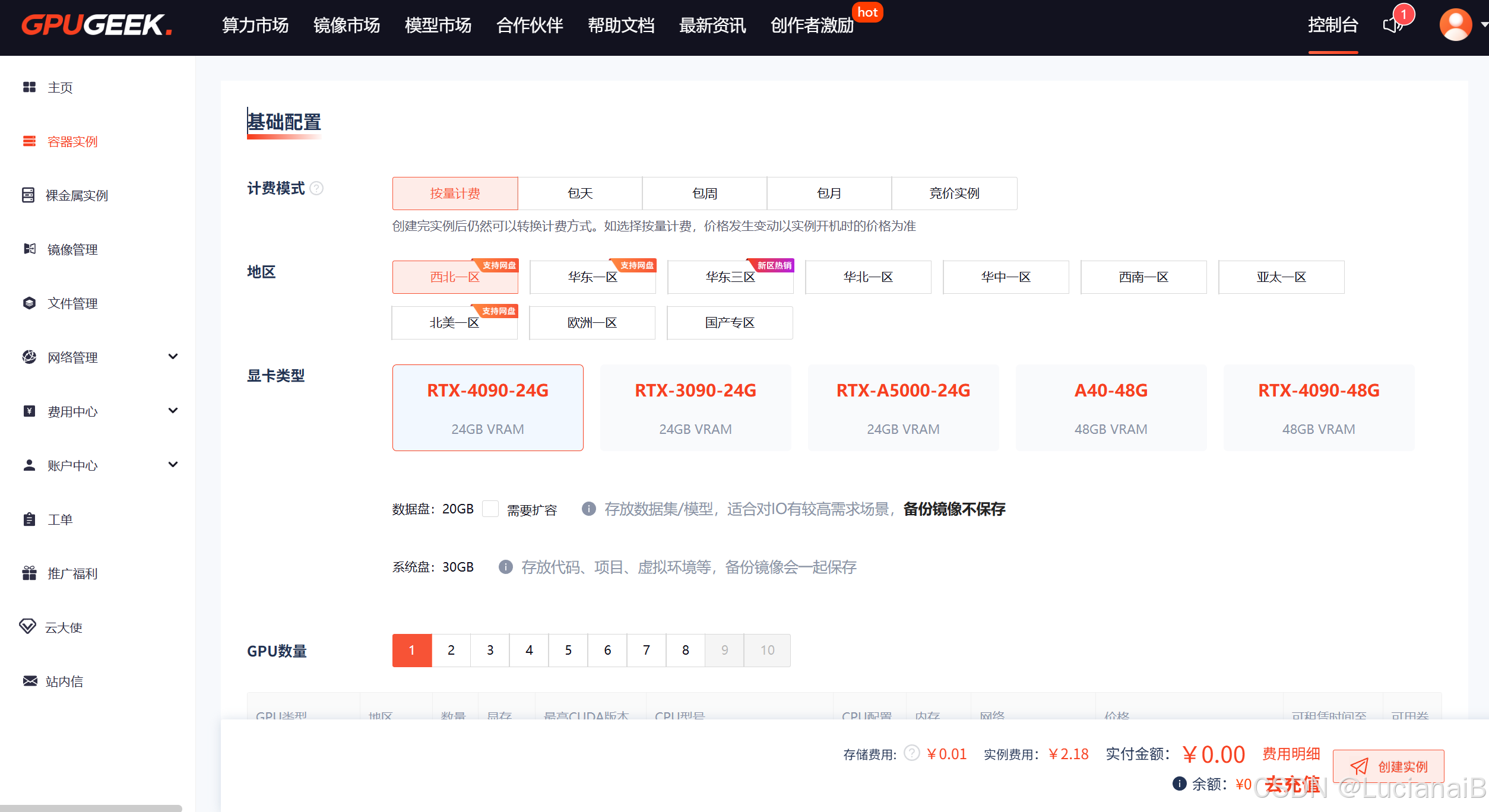
优势二:镜像丰富,实例创建极快
GpuGeek 提供了大量预置镜像(如 HuggingFace + CUDA + bitsandbytes 环境),对于微调大模型的开发者来说,省去了繁琐的环境搭建过程。我从点击“创建实例”到可以运行训练脚本,不到2分钟。
自定义镜像和持久磁盘功能也十分方便,便于多次训练与复用。
三、实战流程详解
1. 环境配置(使用 GpuGeek 镜像)
选择官方提供的 Transformers-LoRA-Ready 镜像,即包含:
- Python 3.10
- CUDA 11.8 + cuDNN
- Transformers / PEFT / bitsandbytes 等常用库

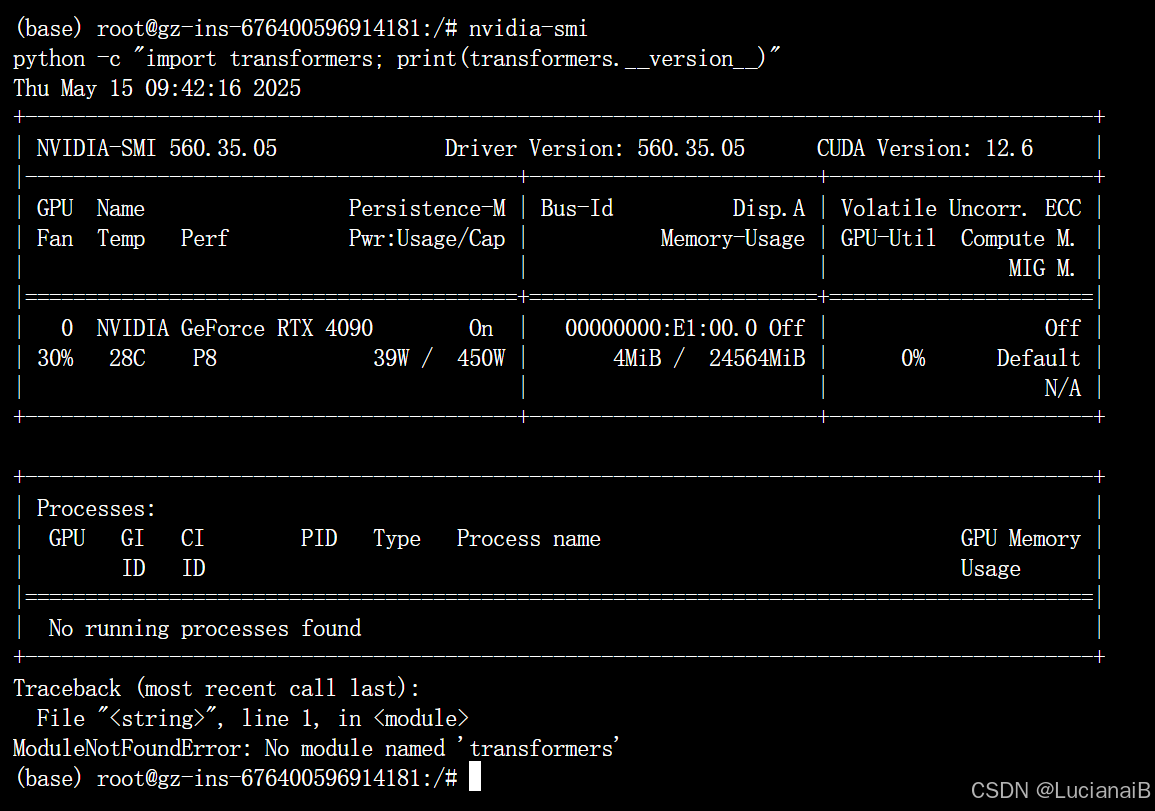
实例创建后即可直接运行以下命令验证环境:
nvidia-smi
python -c "import transformers; print(transformers.__version__)"
2. 加载模型并启动微调
使用 QLoRA 技术进行低成本微调,脚本示例:
!pip install transformers
!pip install peft
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
from peft import LoraConfig, get_peft_model
# 加载模型
model_name = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 应用 LoRA
lora_config = LoraConfig(r=8, lora_alpha=16, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
在 GpuGeek 平台上,该训练任务在 A100 上运行速度非常理想,每 step 时间控制在 2s 内,显存利用率近乎饱和,训练效率极高。
3. 模型推理部署
训练完成后直接保存模型至磁盘,并启动推理服务:
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
print(pipe("学生如何提高英语成绩?", max_new_tokens=50))
通过端口转发,或集成至 FastAPI 形成 API 服务,对外提供实时问答能力。
四、总结与建议
在本次大模型推理与微调的实战中,我选择了GpuGeek平台,并对其性能和便捷性感到非常满意。项目目标是对LLaMA2-7B模型进行指令微调(LoRA),以适配教育问答领域,并完成推理部署及API集成。整个过程从环境配置、模型微调到推理部署都非常顺利,GpuGeek平台的高效性和灵活性为项目提供了强大的支持。
首先,GpuGeek的显卡资源丰富,提供了多种高性能显卡(如A100、H100、3090、4090等),并且资源随开随用,无需排队等待,这大大节省了时间。其次,平台的镜像资源也非常丰富,预置的镜像环境(如HuggingFace + CUDA + bitsandbytes)让我省去了繁琐的环境搭建过程,从创建实例到运行训练脚本仅需不到2分钟。此外,GpuGeek的高性价比也让我印象深刻,相比传统云平台,价格更加亲民,同时还能提供学术加速功能,如自带GitHub代理和HuggingFace镜像同步。
在实际操作中,我使用QLoRA技术对LLaMA2-7B模型进行了低成本微调,整个训练过程在A100显卡上运行流畅,每step时间控制在2秒内,显存利用率近乎饱和,训练效率极高。最终,我通过FastAPI将模型部署为在线接口,成功实现了推理服务的对外提供。
通过这次实战,我深刻体会到GpuGeek平台在深度学习模型开发、训练与部署方面的强大优势。它不仅提供了丰富的显卡资源和预置镜像,还具备高性价比、灵活计费等特点,非常适合开发者和研究者进行大模型的推理与微调实践。
平台亮点小结:
| 亮点 | 说明 |
|---|---|
| 显卡资源足 | A100、H100、3090、4090 等常年可用 |
| 实例启动快 | 2分钟以内启动,镜像选择丰富 |
| 高性价比 | 比传统云平台便宜 30%+ |
| 学术加速 | 自带 GitHub 代理和 HuggingFace 镜像同步 |
| 灵活计费 | 按时计费/包月任选,控制预算更灵活 |
如果你正在寻找一个高效、低成本、配置灵活的深度学习平台,GpuGeek 值得一试!
嗨,我是LucianaiB。如果你觉得我的分享有价值,不妨通过以下方式表达你的支持:👍 点赞来表达你的喜爱,📁 关注以获取我的最新消息,💬 评论与我交流你的见解。我会继续努力,为你带来更多精彩和实用的内容。
点击这里👉LucianaiB ,获取最新动态,⚡️ 让信息传递更加迅速。



















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











