







前言
搜了不少答案,大多是在避免Bank Conflict,很难找到一个关于Bank Conflict的详细定义,这里找了些资料来尝试解释下;
一、基础概念
先简单复习下相关概念
GPU调度执行流程:
- SM调度单位为一个warp(一个warp内32个Thread)
Shared Memory到Bank映射:
先来段NVProfGuide原文:
Shared memory has 32 banks that are organized such that successive 32-bit words map to successive banks that can be accessed
simultaneously. Any 32-bit memory read or write request made of 32 addresses that fall in 32 distinct memory banks can therefore be serviced simultaneously, yielding an overall bandwidth that is 32 times as high as the bandwidth of a single request. However, if two addresses of a memory request fall in the same memory bank, there is a bank conflict and the access has to be serialized.
- shared_memory 可以 被一个warp中的所有(32个)线程进行访问
- shared_memory 映射到大小相等的32个Bank上,Bank上的数据读取带宽为32bit / cycle;
Shared Memory到Bank的映射方式:
- 可配4Byte或者8Byte对齐,可以通过cudaDeviceSetSharedMemConfig 配置(cudaSharedMemBankSizeFourByte 或者 cudaSharedMemBankSizeEightByte ),也可以通过cudaDeviceGetSharedMemConfig 返回当前配置
PS:这里BankSize并不是指某个Bank的实际大小,指的是连续BankSize数据映射到同一个Bank上
举例:对shared memory访问addr的逻辑地址,映射到BankIndex为:
B
a
n
k
I
n
d
e
x
=
(
a
d
d
r
/
B
a
n
k
S
i
z
e
)
%
B
a
n
k
N
u
m
(
32
)
Bank Index = (addr / BankSize)\% BankNum(32)
BankIndex=(addr/BankSize)%BankNum(32)
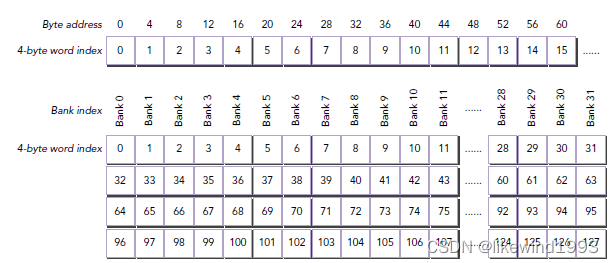
所以,Bank中的数据应该是分层组织的(即原文的 successive 32-bit words map to successive banks),借用CUDA SHARED MEMORY这篇博客中的图来做个示意(图中BankSize = 4Byte),在这种情况下,Bank0的实际大小是
4
B
y
t
e
∗
层数
4Byte * 层数
4Byte∗层数
关于shared memory的介绍,《Using Shared Memory in CUDA C/C++》里还有一段:
To achieve high memory bandwidth for concurrent accesses, shared memory is divided into equally sized memory modules (banks) that can be accessed simultaneously. Therefore, any memory load or store of n addresses that spans b distinct memory banks can be serviced simultaneously, yielding an effective bandwidth that is b times as high as the bandwidth of a single bank.
— 《Using Shared Memory in CUDA C/C++》
有了上述的背景概念后,我们可以对读写过程先算下理论时间复杂度:
假设读写shared memory次数为 N, 一次读写的时间复杂度为 O ( 1 ) O(1) O(1),那么读写 N N N次所需时间复杂度为 O ( N ) O(N) O(N)
假设shared_memory被分成 B B B块Bank,并且可以被进行同时访问,那么理想情况下,读取 N N N次所需的时间复杂度为 O ( N / B ) O(N/B) O(N/B),
二、Bank Conflict
这里先贴张图,来自cuda-c-programming-guide,下图中左边没有Bank Conflict | 中间存在Bank Conflict,称为2-way Bank Conflict | 右边没有Bank Conflict
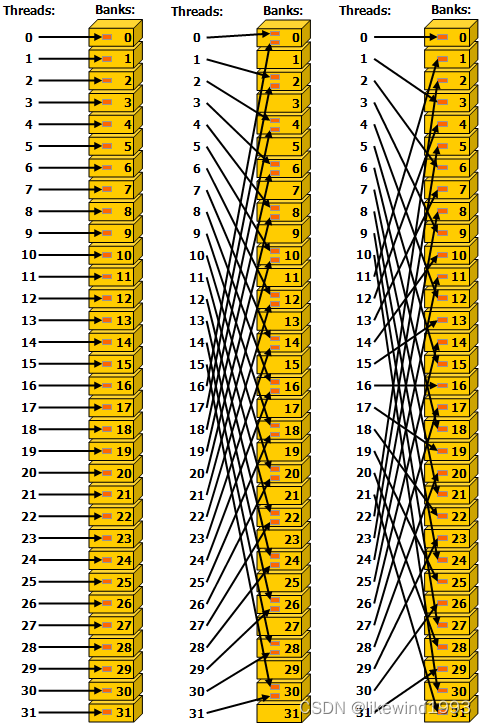
这里有个问题,当不同线程读写同一个Bank中的数据时,会发生什么?
回到《Using Shared Memory in CUDA C/C++》:
However, if multiple threads’ requested addresses map to the same memory bank, the accesses are serialized. The hardware splits a conflicting memory request into as many separate conflict-free requests as necessary, decreasing the effective bandwidth by a factor equal to the number of colliding memory requests. An exception is the case where all threads in a warp address the same shared memory address, resulting in a broadcast. Devices of compute capability 2.0 and higher have the additional ability to multicast shared memory accesses, meaning that multiple accesses to the same location by any number of threads within a warp are served simultaneously.
— 《Using Shared Memory in CUDA C/C++》
上面主要有两点:
- 当多个线程读写同一个Bank中数据时,会由硬件把内存 读写请求,拆分成 conflict-free requests,进行顺序读写
- 特别地,当一个warp中的所有线程读写同一个地址时,会触发broadcast机制,此时不会退化成顺序读写
注:上面提到触发broadcast机制的条件是all threads acess same address,但在翻阅cuda-c-programming-guide以及NVProfGuide时,发现只要是多个thread 读写就会触发broadcast(不需要All)
另外关于读写同一地址时的行为,在最新版本的NVProfGuide里,给出了更明确的流程:
When multiple threads make the same read access, one thread receives the data and then broadcasts it to the other threads. When multiple threads write to the same location, only one thread succeeds in the write; which thread that succeeds is undefined.
即,
- 多个线程读同一个数据时,仅有一个线程读,然后broadcast到其他线程
- 多个线程写同一个数据时,仅有一个线程写,具体是哪个线程写入 是 未定义的
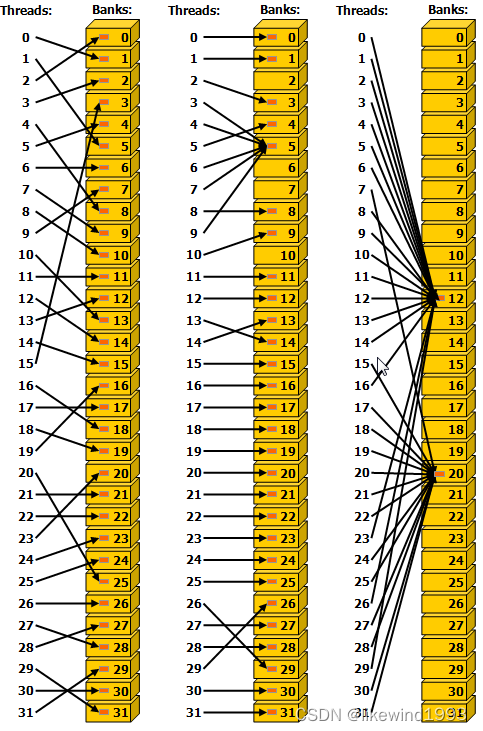
如cuda-c-programming-guide 中给了示意图:左边模拟随机访问 | 中间Thread 3,4,6,7,9访问Bank5中同一个地址 | 右边多个Thread访问 Bank12, Bank20 触发广播机制
依据Bank Conflict 的定义以及广播条件的触发条件 来看,该图中的左/中/右三种访问形式,均没有“Bank Conflict”情况
所以,这里用一句话解释什么是Bank Conflict:
在访问shared memory时,因多个线程读写同一个Bank中的不同数据地址时,导致shared memory 并发读写 退化 成顺序读写的现象叫做Bank Conflict;
特别地,当同一个Bank的内存访问请求数为 M M M时,叫做M-way Bank Conflict;
回到开始读写 N N N次的理论时间复杂度 O ( N / B ) O(N/B) O(N/B), 我们可以看到,当存在M-way Bank Conflict时,时间复杂度变成 O ( M ∗ N / B ) O(M * N/B ) O(M∗N/B)(退化了M倍);
三、如何发现存在Bank Conflict?
关于检测 Bank Conflict , 目前NVProf工具已经可以检测出某段Kernel函数存在Bank Conflict)
Updates in 2023.2
…
Added support for rules to highlight individual source lines. Lines with global/local memory access with high excessive sector counts and shared accesses with many bank conflicts are automatically detected and highlighted.
…
另关于如何避免Bank Conflict的解法(如在CUDA Best Practices里提到的增加Padding等)
参考资料
感兴趣的读者,可以参考下其他人对bank conflict的定义
- stackoverflow:什么是bank conflict?:https://stackoverflow.com/questions/3841877/what-is-a-bank-conflict-doing-cuda-opencl-programming
- :















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









