







一 功能介绍
功能:获取基金历史净值数据
数据来源:
https://fundf10.eastmoney.com/F10DataApi.aspx?type=lsjz&code={}&page=1&sdate=19950101&edate={}&per=40
编程语言:Python
数据处理工具:Pandas
输出结果文件格式:CSV
二 关键代码
2.1 数据来源截图
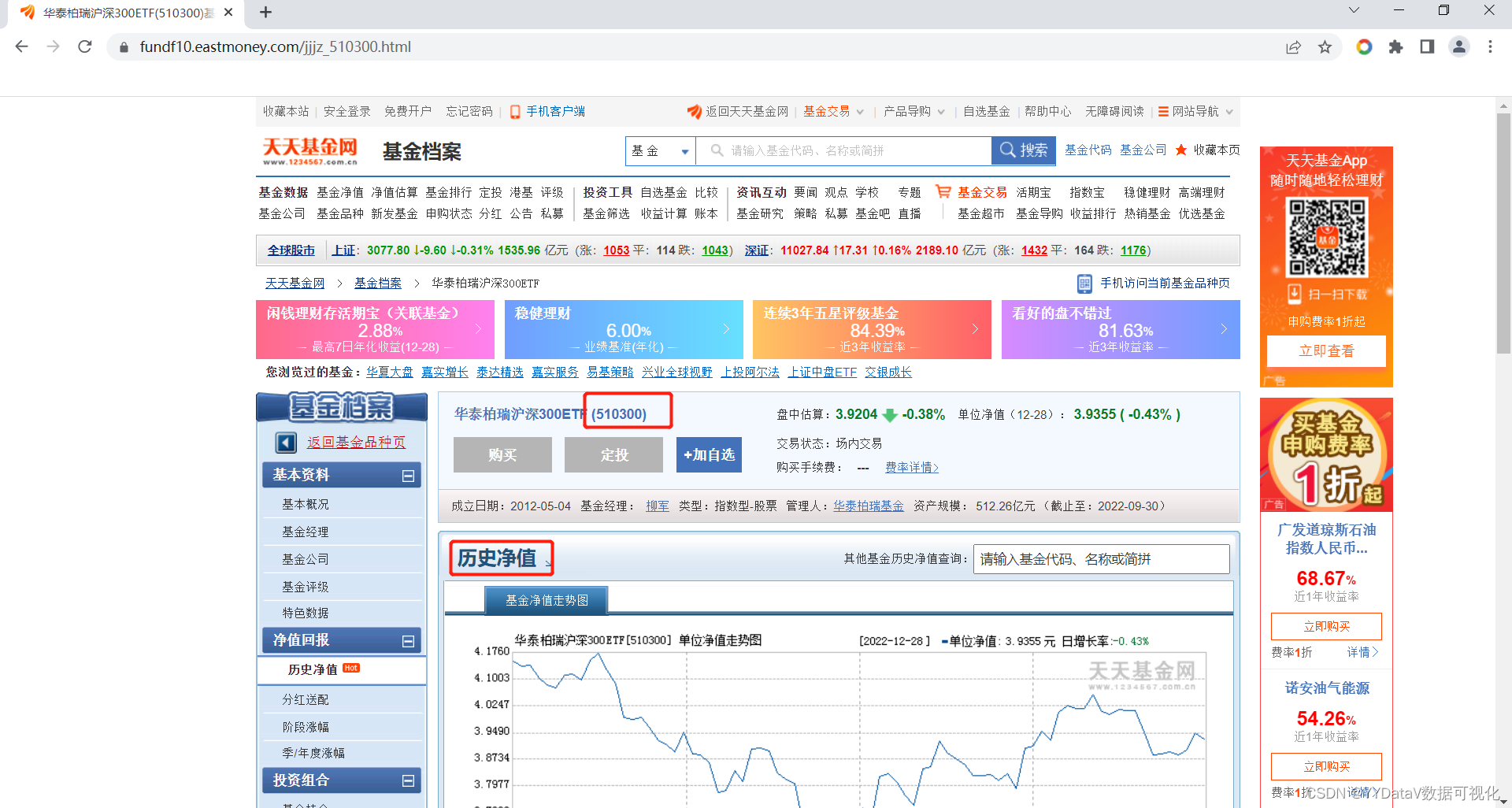
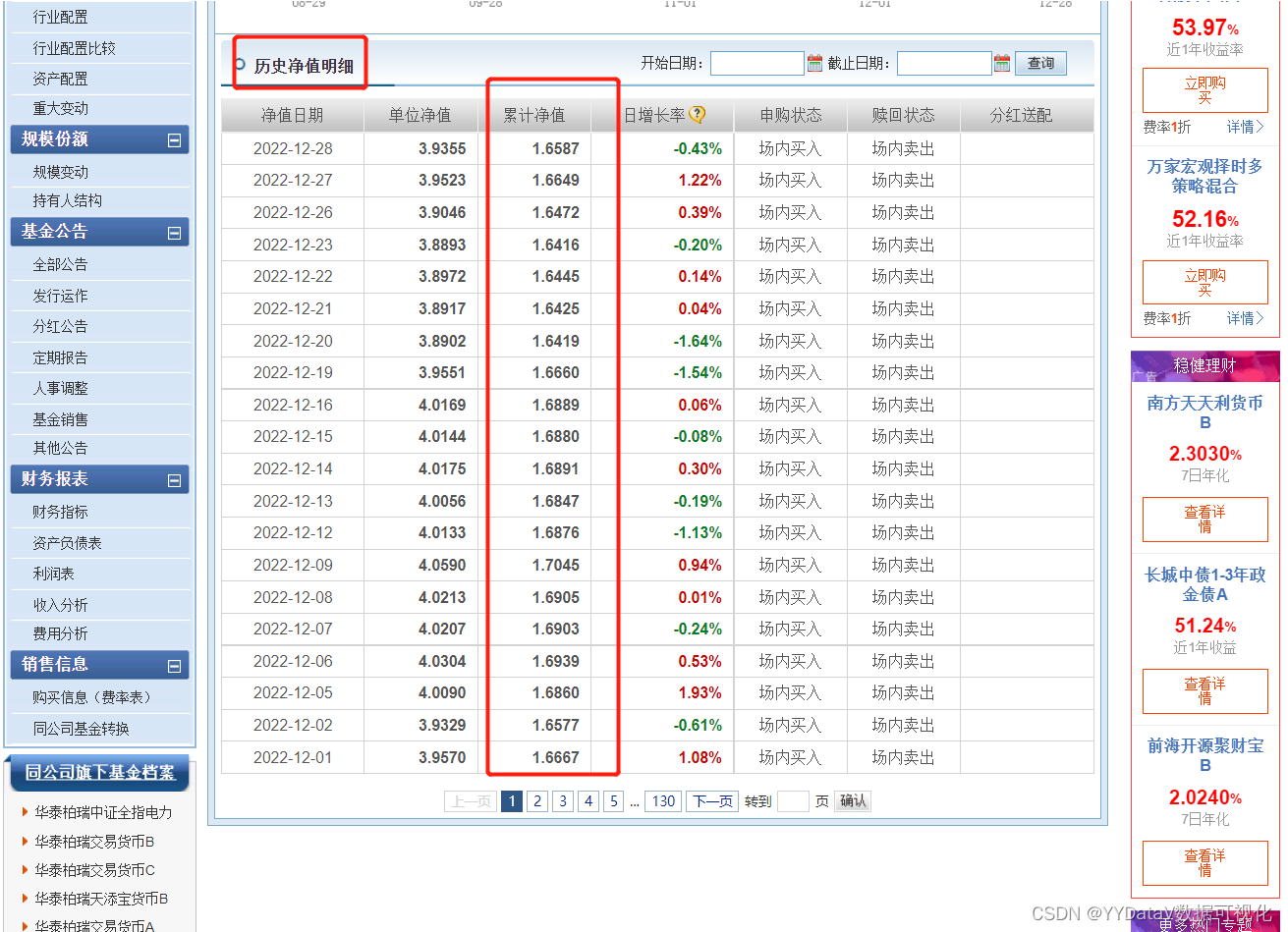
2.2 关键代码
import requests
import pandas as pd
import time
import datetime
import re
from lxml import etree
#基金
def download_fund_history_data(fund_code):
url = "https://fundf10.eastmoney.com/F10DataApi.aspx?type=lsjz&code={}&page=1&sdate=19950101&edate={}&per=40".format(fund_code,
datetime.datetime.strftime(datetime.datetime.now(), "%Y%m%d"))
print(url)
response = requests.get(url)
print(response.text)
pages = re.findall('pages:(.*),', response.text)
int_pages = 0
if len(pages)>0:
int_pages = int(pages[0])
print("总共{}页".format(int_pages))
td_all = []
for i in range(int_pages):
url = "https://fundf10.eastmoney.com/F10DataApi.aspx?type=lsjz&code={}&page={}&sdate=19950101&edate={}&per=40".format(fund_code,
i+1,
datetime.datetime.strftime(datetime.datetime.now(), "%Y%m%d"))
print(url)
response = requests.get(url)
print(response.text)
tables = re.findall('"(.*)"', response.text)
if len(tables)>0:
table = tables[0]
print(table)
tree = etree.HTML(table)
td_list = tree.xpath('//tr/td')
#print(td_list)
for t in td_list:
#print(t.text)
if t.text == None:
td_all = td_all + [""]
else:
td_all.append(t.text)
#print(td_all)
columns = {
"date": "净值日期", "a": "单位净值", "b": "累计净值", "c": "日增长率", "d": "申购状态", "e": "赎回状态"
}
net_date = []
net_a = []
net_b = []
net_c = []
net_d = []
net_e = []
for k,v in enumerate(td_all):
i = k%7
if i == 0:
net_date.append(v)
if i == 1:
net_a.append(v)
if i == 2:
net_b.append(v)
if i == 3:
net_c.append(v)
if i == 4:
net_d.append(v)
if i == 5:
net_e.append(v)
df = pd.DataFrame({'净值日期':net_date,
'单位净值':net_a,
'累计净值':net_b,
'日增长率':net_c,
'申购状态':net_d,
'赎回状态':net_e})
df.to_csv("基金{}历史数据.csv".format(fund_code), index=False, encoding="utf-8")
if __name__ == '__main__':
#510300沪深300ETF
download_fund_history_data("510300")2.3 输出结果
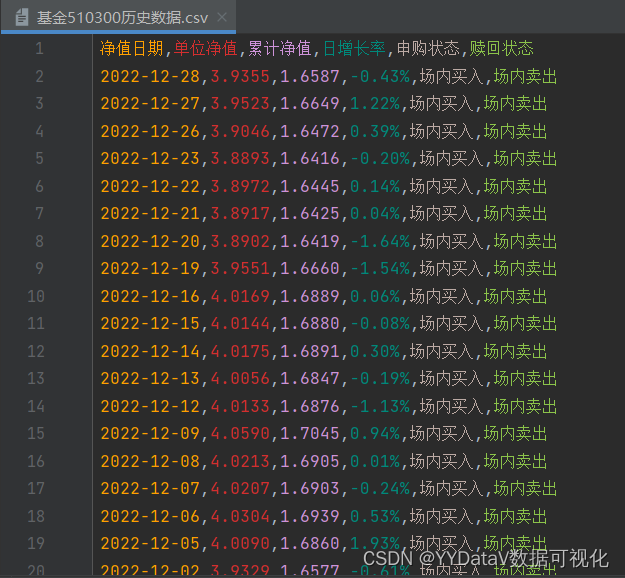


















 2198
2198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











