






目录
3.4 将特征值按照从大到小的顺序排序,选择其中最大的k个,及其对应特征向量
一、PCA相关概念
1. 什么是PCA?
1.1 概念阐释
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法(非监督的机器学习方法)。
其最主要的用途在于“降维”,通过析取主成分显出的最大的个别差异,发现更便于人类理解的特征。也可以用来削减回归分析和聚类分析中变量的数目。
1.2 为什么要做PCA
在数据集提供丰富信息的同时,数据之间也存在大量相关性从而会增加问题分析的复杂性。所以需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。
由于各变量之间存在一定的相关关系,因此可以考虑进行特征维度约减,即将关系紧密的变量变成尽可能少的新变量(即降维),使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息,以便找到需要的主成分特征。主成分分析(PCA)与因子分析就属于这类降维算法。
也就是说,在很多场景中需要对多变量数据进行观测,在一定程度上增加了数据采集的工作量。更重要的是:多变量之间可能存在相关性,从而增加了问题分析的复杂性。
如果对每个指标进行单独分析,其分析结果往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析与因子分析就属于这类降维算法。
主成分分析(PCA)是一种常用的数据降维方法,可以将高维数据转换为低维空间,同时保留原始数据中最具代表性的信息。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
2. 特征维度约减的概念与目的
特征维度约减——将给定的n个样本(每个样本维度为p维)通过特征变换和映射矩阵高维空间映射到低维子空间
原始数据:
进行线性变化(与求内积)得到约减后的数据:
目的:
- 使机器学习算法在高位空间中表现更具鲁棒性,筛选出有价值的维度(有价值点位有限)
- 可视化、高效存储和检索、噪声消除
3. 主成分分析的主要步骤
3.1 求出所有值的均值,然后将所有案例都减去该均值
中心化后均值都为0
3.2求样本的协方差矩阵
原数据的协方差为:
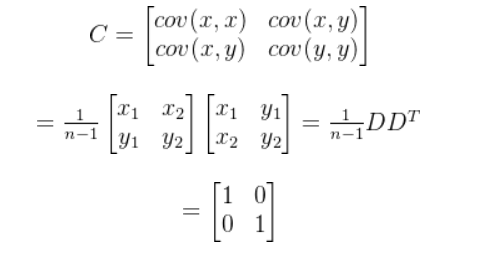
D——data(数据)
左上右下对角线上为方差,求最大值
左下右上对角线为协方差,求最小值

(即对原数据进行中心化)
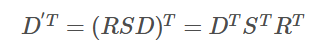
代入上述公式:
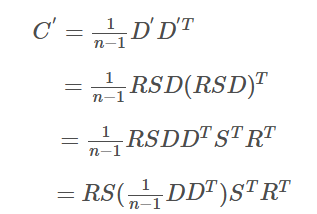
即其中有原数据的协方差,即最终结果为:
![]()
因为
拉伸情况 ![]()
旋转情况![]()
令 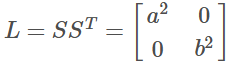
![]()
3.3 求得特征值和特征向量
协方差矩阵的特征值即为L:
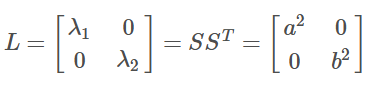
和
是两个轴方向的方差,同时也是协方差矩阵的特征值
特征向量为新向量下的横纵坐标,即为R:
![]()
3.4 将特征值按照从大到小的顺序排序,选择其中最大的k个,及其对应特征向量
3.5 将原始数据投影到选取的特征向量上
3.6 输出投影后的数据集
二、PCA的简单实现
1. 导入库
import numpy as np
import matplotlib.pyplot as plt2. 选取一个二维数据

3. 查看数据分布情况
data = np.genfromtxt("xxhg/1.csv", delimiter=",")
x_data = data[:,0]
y_data = data[:,1]
plt.scatter(x_data,y_data)
plt.show()
4. 中心化数据
def zeroMean(dataMat):
# 按列求平均,即各个特征的平均
meanVal = np.mean(dataMat, axis=0)
newData = dataMat - meanVal
return newData, meanVal5. 求协方差矩阵
#求协方差矩阵
newData,meanVal=zeroMean(data)
# np.cov用于求协方差矩阵,参数rowvar=0说明数据一行代表一个样本
covMat = np.cov(newData, rowvar=0)6. 求特征值及特征向量
#求特征值和特征向量
eigVals,eigVects = np.linalg.eig(np.mat(covMat))7. 对特征值进行从大到小排序并取最大的n个特征值下标
#特征值排序
eigValPaixu=np.argsort(eigVals)
#取最大的n个特征值下标
n_eigValPaixu=eigValPaixu[-1:-(1+1):-1]#从末尾开始取每隔一个元素取一次直到倒数第二个元素8. 最大的n个值对应的特征向量及低维数据的重构
#对应特征向量
n_eigVect=eigVects[:,n_eigValPaixu]
#低维特征数据及重构
lowDD=newData*n_eigVect
reconMat=(lowDD*n_eigVect.T)+meanVal9. 输出原数据投影到选取的特征向量的值
data = np.genfromtxt("xxhg/1.csv", delimiter=",")
x_data = data[:,0]
y_data = data[:,1]
plt.scatter(x_data,y_data)
x_data=np.array(reconMat)[:,0]
y_data = np.array(reconMat)[:,1]
plt.scatter(x_data,y_data,c='r')
plt.show()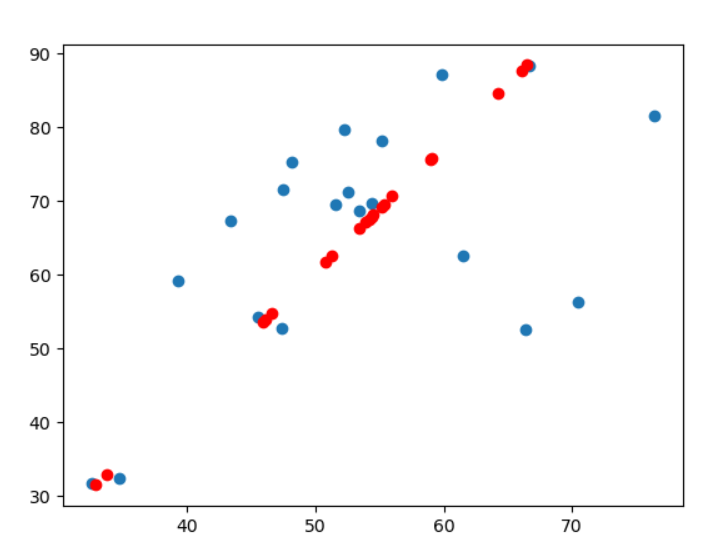
三、总结
对PCA有了一个大概的了解。















 5505
5505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









