







流水线Pipeline技术是提高CPU处理速率的一种方式,它主要针对RISC体系。该体系把数据和指令分开存储,减少了冲突的发生(下文中流水线之间的相关或冲突问题),从而对流水线结构中第一个步骤:取指令来说就比较方便了。非流水线结构是指一个指令周期完成以后再接受下一条处理数据的指令;而流水线结构,每个时钟脉冲都接受下一条处理数据的指令,只是不同的部件做不同的事情
在RISC中,若指令不是关联的或发生指令跳转,通常在当前指令执行完成之前,就可以知道下一条指令的地址。
51单片机属于CISC架构。这种架构的特点是追求用最少的指令来完成所需的任务,因此它有数目庞大的指令集以提高编程效率;但每条指令的长度和执行所占用的机器周期均不相同。
51单片机的1个指令周期包括大约1-4个机器周期,1个机器周期包括12个时钟周期,时钟周期具体是多少,根据晶振频率来定.而机器周期的定义:百科中的
| 计算机中,为了便于管理,常把一条指令的执行过程划分为若干个阶段,每一阶段完成一项工作。例如,取指令、存储器读、存储器写等,这每一项工作称为一个基本操作。完成一个基本操作所需要的时间称为机器周期。一般情况下,一个机器周期由若干个S周期(状态周期)组成。通常用内存中读取一个指令字的最短时间来规定CPU周期,(也就是 计算机通过内部或外部总线进行一次信息传输从而完成一个或几个微操作所需要的时间)),它一般由12个时钟周期(震荡周期)组成,也是由6个状态周期组成。而震荡周期=1秒/晶振频率,因此单片机的机器周期=12秒/晶振频率 。 |
三级流水线指令序列为:
ADD r1 r2
SUB r3 r2
CMP r1 r3
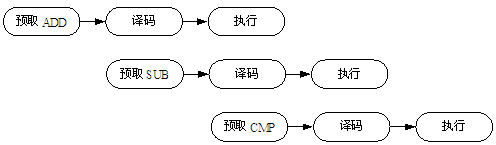
水平为指令周期。。
在第一个周期,内核从存储器取出指令ADD;在第二个周期,内核取出指令SUB,同时对ADD译码;在第三个周期,指令SUB和ADD都沿流水线移动,ADD被执行,而SUB被译码,同时又取出CMP指令。可以看出,流水线使得每个时钟周期都可以执行一条指令。
————————————————————————————————————————————————————
流水线有两个非常大的问题:相关和转移。可以看P59ARM9嵌入式系统设计
在流水线系统中,若第二条指令需要用到第一条指令的结果(只要在需要数据时,这个数据由之前的流水线产生,但没有得到结果),这种情况叫做相关。以上面哪个5级流水线为例,当第二条指令需要取操作数时,第一条指令的运算还没有完成,如果这时第二条指令就去取操作数,就会得到错误的结果。所以,这时整条流水线不得不停顿下来,等待第一条指令的完成。这是很讨厌的问题,特别是对于比较长的流水线,比如20级,这种停顿通常要损失十几个时钟周期。
目前解决这个问题的方法是乱序执行。乱序执行的原理是在两条相关指令中插入不相关的指令,使整条流水线顺畅。比如上面的例子中,开始执行第一条指令后直接开始执行第三条指令(假设第三条指令不相关),然后才开始执行第二条指令,这样当第二条指令需要取操作数时第一条指令刚好完成,而且第三条指令也快要完成了,整条流水线不会停顿。当然,流水线的阻塞现象还是不能完全避免的,尤其是当相关指令非常多的时候。由于 ARM 是硬件 flush 流水设计的,当发生冒险时,会暂停取指,然后清流水, (MIPS 解决冒险通常依赖于编译器,比如插入一条 NOP 指令及重新排列指令序列 )
个人觉得阻塞情况不要清空流水线,而只有在中断,或跳转指令时才要清空流水线。
另一个大问题是条件转移。在上面的例子中,如果第一条指令是一个条件转移指令,那么系统就会不清楚下面应该执行那一条指令?这时就必须等第一条指令的判断结果出来才能执行第二条指令。条件转移所造成的流水线停顿甚至比相关还要严重的多。所以,现在采用分支预测技术来处理转移问题。虽然我们的程序中充满着分支,而且哪一条分支都是有可能的,但大多数情况下总是选择某一分支。比如一个循环的末尾是一个分支,除了最后一次我们需要跳出循环外,其他的时候我们总是选择继续循环这条分支。根据这些原理,分支预测技术可以在没有得到结果之前预测下一条指令是什么,并执行它。现在的分支预测技术能够达到90%以上的正确率,但是,一旦预测错误,CPU仍然不得不清理整条流水线并回到分支点。这将损失大量的时钟周期。所以,进一步提高分支预测的准确率也是正在研究的一个课题。
越是长的流水线,相关和转移两大问题也越严重,所以,流水线并不是越长越好,超标量也不是越多越好,找到一个速度与效率的平衡点才是最重要的。
————————————————————————————PC的概念,百科程序计数器PC(program counter)是用于存放下一条指令所在单元的地址的地方。 为了保证程序能够连续地执行下去,CPU必须具有某些手段来确定下一条指令的地址。而程序计数器正是起到这种作用,所以通常又称为指令计数器。在程序开始执行前,必须将它的起始地址,即程序的一条指令所在的内存单元地址送入PC,因此程序计数器(PC)的内容即是从内存提取的第一条指令的地址。当执行指令时,CPU将自动修改PC的内容,即每执行一条指令PC增加一个量,这个量等于指令所含的字节数,以便使其保持的总是将要执行的下一条指令的地址。由于大多数指令都是按顺序来执行的,所以修改的过程通常只是简单的对PC加1。PC的维数一般和存储器地址寄存器MAR的维数一样。当程序转移时,转移指令执行的最终结果就是要改变PC的值,此PC值就是转去的地址,以此实现转移。有些机器中也称PC为指令指针IP(Instruction Pointer)。 |
ARM7的三级流水线在执行单元完成了大量的工作,包括与操作数相关的寄存器和存储器读写操作、ALU操作以及相关器件之间的数据传输。执行单元的工作往往占用多个时钟周期,从而成为系统性能的瓶颈。ARM9采用了更为高效的五级流水线设计,增加了2个功能部件分别访问存储器并写回结果,且将读寄存器的操作转移到译码部件上,使流水线各部件在功能上更平衡;同时其哈佛架构避免了数据访问和取指的总线冲突。
——————————————————————————————————————P78ARM指令是字对齐的,它的一个字是4字节。R15()PC)ARM7三级流水线:取指令,指令译码,执行
ARM9五级流水线:取指令,指令译码,执行,数据缓存,写回。
可以看到前三级是相同的。在三级或五级流水线下,通过R15访问PC(程序计数器)时会出现取指位置和执行位置不同的现象。
周期1 周期2 | 周期3 周期4 周期5 周期6
PC-8 取指 译码 | 执行
PC-4 取指 |译码 执行
PC |取指 译码 执行
参数点
而PC指向“正在取指”的指令,而不是指向“正在执行”的指令或正在“译码”的指令。一般来说,人们习惯性约定将“正在执行的指令作为参考点”,称之为当前第一条指令,因此PC总是指向第三条指令。当ARM状态时,每条指令为4字节长,所以PC始终指向该指令地址加8字节的地址,即:PC值=当前程序执行位置+8;——
从而正在执行的指令为PC-8; 这须结合流水线的执行情况考虑,取指部件根据PC取指,取指完成后PC+4送到PC,并把取到的指令传递给译码部件,然后取指部件根据新的PC取指。因为每条指令4字节,故PC值等于当前程序执行位置+8。
只有当指令执行时才能发现该指令是否为跳转指令,从而有流水线结构使跳转时要保存的PC值要小心处理。发生跳转时,后面的指令就不执行了,PC值为当前程序执行位置+8,如果执行完这——从而若保存它,跳转回来的地址就不是下一条指令的地址了。 可以直接把PC存储到LR中,而在返回时把LR-4加载到PC中;也可以把PC-4直接存储到LR中,返回时直接把LR加载到PC中————————————————————————若在执行指令 S1时 发生中断,假设当处理器从 S1 取指阶段时就发生了 IRQ 中断,但此时不会去响应 IRQ 中断,因为此时还不能确定中断入口向量表的地址,准确的说,此时 PC 的值还不是中断入口的地址,要确定中断入口的地址,必须等到执行阶段,处理器检测到有一个中断,并通过 ALU 计算而得到中断的入口地址,然后再写入 PC 中,实现跳转到中断入口处,也就是在写入这个值到 PC 并进行跳转之前,硬件自动保存了原来的那个 PC 值到 lr 中。因为中断的检测和中断入口的地址是在执行阶段时确定的,所以此时 PC 的值是 S1+8 的地址,或者是 S3 的地址。
另外还要注意的就是,如果 S1 不是像 ADD R0 R1,R2 这样的指令而是访存指令的时候,处理器必须等到执行完访存之后,才会进入中断,而此时,流水线暂停取指并清空 S1 之后的所有位于流水线中的指令序列,这里是S2 、 S3 。
其它的像分支和跳转等冒险情况,也正是因为分支和跳转的地址是在执行阶段时确定的,所以 PC 的值也为处于执行阶段的指令地址加 8 的地址。
ARM流水线关键技术分析与代码优化
“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“”“‘’” 流水线设计的概念:流水线实际上是把规模较大、层次较多的组合逻辑电路分为几个级,在每一级插入寄存器组并暂存中间数据。K级的流水线就是从组合逻辑的输入到输出恰好有K个寄存器组(分为K级,每一级都有一个寄存器组),上一级的输出是下一级的输入而又无反馈的电路。、
流水线性能的提高是以消耗较多寄存器资源为代价的。同时也增加了延时。

图表示了如何把组合逻辑设计转换为相同组合逻辑功能的流水线设计。这个组合逻辑包括两级:第一级的延迟是T1和T3两个延迟中的最大值;第二级的延迟等于T2延迟。为了通过这个组合逻辑得到稳定的计算结果输出,需要等待的传播延迟为[max(T1,T3)+T2]个时间单位。在从输入到输出的每一级插入寄存器后,流水线设计的第一级寄存器所具有的中的延迟为T1与T3时延中的最大值加上寄存器的Tco(触发时间)。同样,第二级寄存器延迟为T2的时延加上Tco。采用流水线设计为取得稳定的输出总体计算周期为:
max(max(T1,T3)+Tco,(T2+Tco))
流水线设计需要两个时钟周期来获取第一个计算结果,而只需要一个时钟周期来获取随后的计算结果。开始时用来获取第一个计算结果的两个时钟周期被称为流水线设计的首次延迟(latency),对于CPLD来说,器件的延迟如T1,T2和T3相对于触发器的Tco要长得多,并且寄存器的建立时间 Tsu 也要比器件的延迟快得多。只有在上述关于硬件时延的假设为真的情况下,流水线设计才能获得比同功能的组合逻辑设计更高的性能。理解不深
采用流水线设计的优势在于它能提高吞吐量(throughput)。假设T1.T2和T3具有同样的传递时延Tpd,对于组合逻辑设计而言,总的延迟为2*Tpd;对于流水线设计来说,计算周期为(Tpd+Tco)。前面提及的首次延迟(latency)的概念实际上就是将(从输入到输出)最长的路径进行初始化所需要的时间总量;吞吐延迟则是执行一次重复性操作说需要的时间总量。在组合逻辑设计中,首次延迟恶化吞吐延迟同为2*Tpd。与之相比,在流水线设计中,首次延迟是2*(Tpd+Tco),而吞吐延迟是Tpd+Tco。如果CPLD硬件提供快速的Tco,则流水线设计相对于同样功能的组合逻辑设计能提供更大的吞吐量。典型的富含寄存器资源的CPLD器件(如Lattice的ispLSI8840)的Tpd为8.5ns,Tco为6ns。
流水线设计在性能上的提高是以消耗较多的寄存器资源为代价的。对于非常简单的用于数据传输的组合逻辑设计,例如上述例子,可将它们转换成流水线设计且可能只需要增加很少的寄存器单元。随着组合逻辑变得复杂,为了保证中间的计算结果都在同一时钟周期内得到,必须在各级之间加入更多的寄存器。如果需要在CPLD中实现复杂的流水线设计,以获得更优良的性能,如具有丰富寄存器资源的CPLD结构即可预测的延迟两大特点的FPGA,是一个很有吸引力的选择。
下面对流水线加法器(或乘法器)与组合逻辑加法器(或乘法器)作一比较:
流水线加法器与组合逻辑加法器的比较:采用流水线技术可以在相同的半导体工艺的前提下通过电路结构的改进来大幅度地提高重复多次使用的复杂组合逻辑计算电路的吞吐量。下面是一个n位全加器的例子。为实现该加法功能需要3机电路:加法器输入的数据产生器和传送器;数据产生器和传送器的超前进位部分;数据产生、传送功能和超前进位三者就和电路。

在n位组合逻辑全加器中插入三层寄存器或寄存器组,将它转变为n位流水线全加器,如图,由于进位C-1既是第一级逻辑的输入,又是第二级逻辑输入,因此将C-1进位改为流水线结构时需要使用两级寄存器。同样地,发生器输出在作为求和单元的输入之前,也要多次插入寄存器。作为求和单元的输出,进位Cout要达到同一流水线的级别也需要插入两层寄存器。


http://hi.baidu.com/syjfd/item/7423200f55b5e7cb915718e2
基本运算逻辑和它们的Verilog HDL模型















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









