







通过借助“设计计算器”这个例子,我们讲了整型int、浮点型float、以及scanf_s函数和printf函数对整数和小数的格式化输入输出,还有一些函数的封装和定义。
int表示的数据范围
所有的数据都是用int来定义变量然后输入吗?其实不仅仅是数据类型上要做区分,就连数据大小上也是要的,“感觉一个数是不是很大”这件事对人类来说可能是一件很简单的事情,但是换做是硬件和机器就变得很难了。前面我们说过包含头文件可以使用输入输出函数,类似地,包含某些头文件我们也可以看看整型类型int到底是表示多大范围的数据。这个头文件就是<limits.h>(即一个数据的极限)结合输出函数,我们在VS2022上输入以下代码:
#include <stdio.h>
#include <limits.h>
int main()
{
printf("The range of int is from %d to %d\n", INT_MIN, INT_MAX);
return 0;
}编译运行结果:
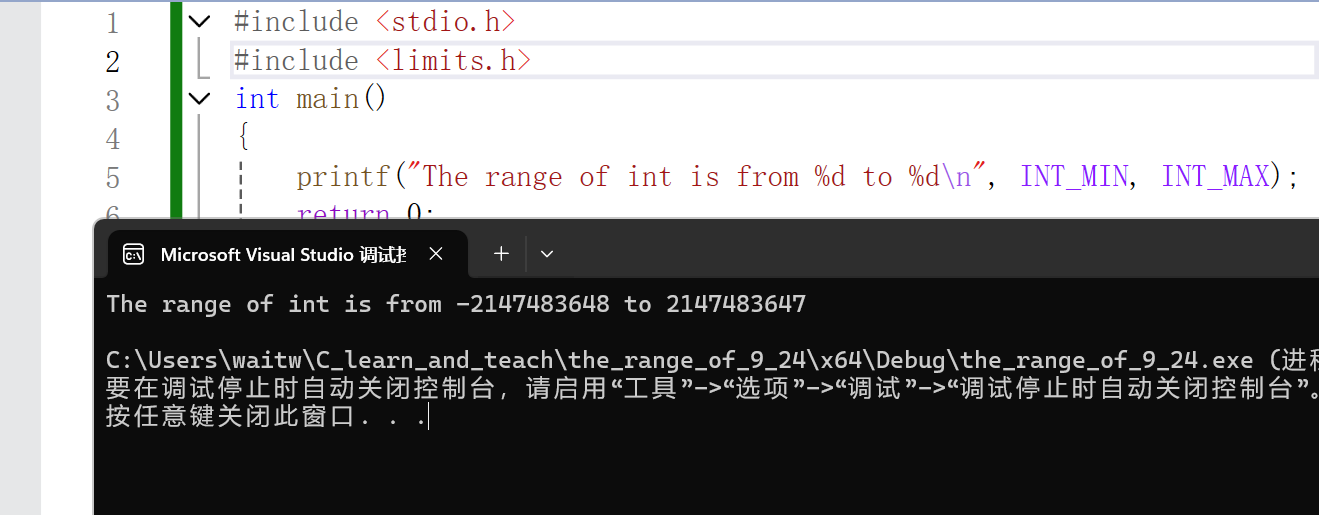
这个范围还蛮大,足以满足现实中很多的需求了,需要注意的是:在不同的编译器上可能会输出不一样的范围,但基本上都是这个范围。
库函数和宏定义
说到打印int的数据范围,应该会联想到之前讲的:打印a+b的值
printf("a+b的值是:%d",c);那这里的c和上面的INT_MIN以及INT_MAX一样都是变量名吗?其实不是。我们有说到printf和scnaf_s两个函数是在头文件中<stdio.h>定义的,由于一些代码使用的频率很高,所以干脆就把它们都预先编写好,等到要用的时候直接包含头文件,输入输出函数就属于这一类型,它们都属于库函数。那INT_MIN以及INT_MAX呢?它们也是库函数吗?其实不是。还记得函数的功能吗?一段代码可以完成特定的任务,实现特定的功能才叫做函数。如果它们都是库函数的话,那么应该采取像输入输出函数的写法:在名字后面加个括号,表示调用此函数,而这里并不是这样使用的,所以它们并不是库函数,它们是宏定义。因为INT_MIN以及INT_MAX所代表的值总是被用到,所以就像库函数那样被预先编写好。当然库函数和宏定义除了可以进行代码复用之外,还有其他的作用之后涉及到的话会讲的。
那接下来,我们就来看它们是如何被预先写好的:在头文件所在行右键一下,然后点击“转到文档(G)<limits.h>”
下滑滑到如下界面:
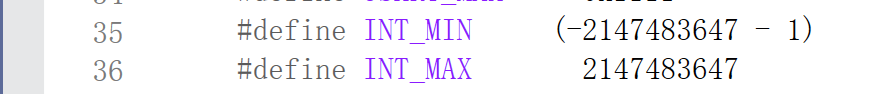
会发现,它们各自前面都带有#define,翻译过来就是定义,定义 INT_MIN 为(-2147483647-1)即-2的31次方,以及定义INT_MAX为2147483647即2的31次方-1。
无符号整型 unsigned int
在int所表示的范围里包含负数,所以它叫有符号整型,与之对应的是无符号整型。无符号顾名思义就是非负数。前者需要在int前面加上signed,而后者需要加上unsigned。但是我们在之前并没有把int写成signed int ,这是因为在编译器的默认情况下int就是表示signed int。那我们来看一下无符号整型又能表示多大的范围:
#include <stdio.h>
#include <limits.h>
int main()
{
printf("The maximum value of an unsigned int is: %u\n", UINT_MAX);
return 0;
}编译并且运行结果:
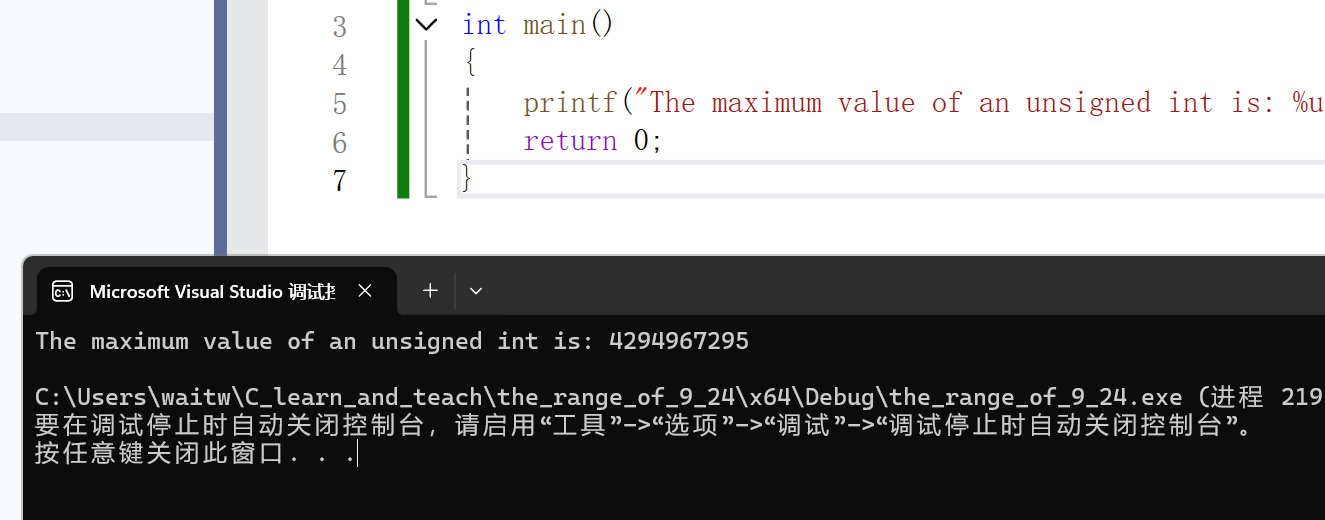
头文件同样是<limits.h>,而宏定义变成了:

看到37行,这里写的UINT_MAX是0xffffffff,以0x为前缀是十六进制的表示方法,f对应到十进制是15。十六进制是0~15总共十六个数,到15之后加一就需要进一位。
而我们会发现占位符从%d变成了%u,之前我们说%d是表示整型的占位符,换一种说法:是表示有符号的十进制整数(十进制就是我们日常用的,到9加一后就进一位,0~9总共十个数)。那同样地,其实%u就是表示无符号的十进制整数。而且我们可以看到无符号整型所表示的范围是2的32次方-1,远比int的最大值大。当要输入比INT_MAX还要大的正数时,就需要用无符号整型:unsigned int,例如:
unsigned int a;
scanf_s("%u",&a);
printf("%u",a);长整型long和长长整型long long
那比unsigned int范围还大的数据用什么表示?用long,默认是有符号长整型,如果不省略,后面可以加一个int,前面加个signed。一样,无符号长整型是unsigned long。比long更大的是long long ,这名字其实取得很直白;一样,无符号长长整型是unsigned long long。
下面来查看long 和long long的范围
include <stdio.h>
#include <limits.h>
int main()
{
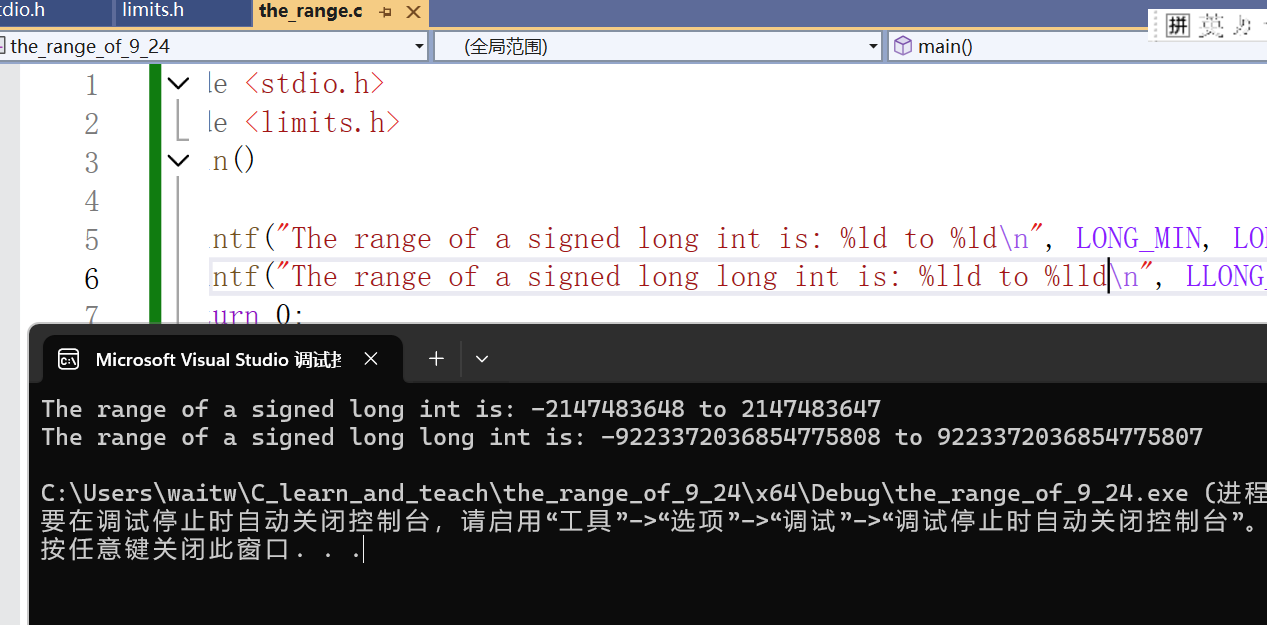
printf("The range of a signed long int is: %ld to %ld\n", LONG_MIN, LONG_MAX);
printf("The range of a signed long long int is: %lld to %lld\n", LLONG_MIN,LLONG_MAX);
return 0;
}我们能明显看到此处的占位符从int的%d变成了%ld和%lld,所以占位符和数据类型基本上是一一对应的,如果没有对应准,那么就会使得输出的数据是有误的,不是预期想要的。看下面的运行:
会发现long表示的范围竟然和int是一样的,这个取决于VS2022编译器的实现,它规定了long的范围和int是一样的。
同样地,咱们来看无符号:
#include <stdio.h>
#include <limits.h>
int main() {
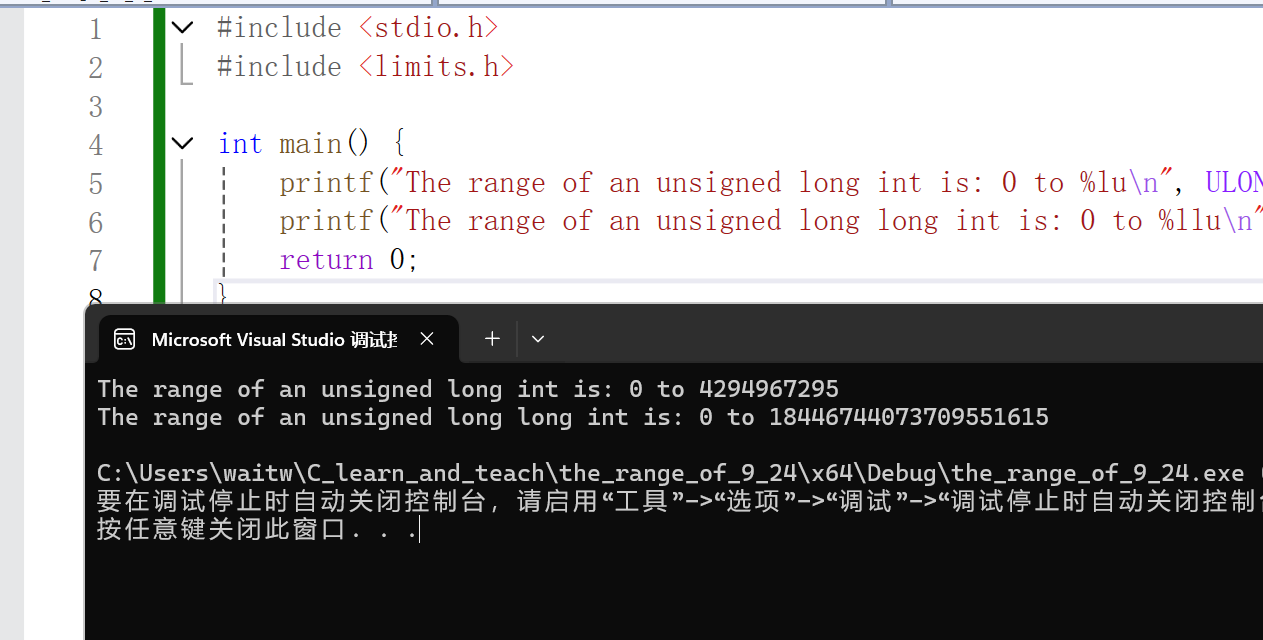
printf("The range of an unsigned long int is: 0 to %lu\n", ULONG_MAX);
printf("The range of an unsigned long long int is: 0 to %llu\n", ULLONG_MAX);
return 0;
}我们也能明显看到占位符从%u变成了%lu和%llu。
此处:unsigned long 和unsigned int的范围是一样的。
短整型short
那会有比int范围还小的整型类型嘛?C语言告诉你是有的!它就是short(即signed short int)那既然int可以表示比short更大的范围,而且最大的是long longe诶,直接用最大的范围不就行了嘛?但是实际上当我们对一个变量进行定义时,我们使用不同的数据类型来定义它,就会使得变量拥有不同的内存,比如int类型的变量所占内存空间是4个字节,而short仅占2个字节。
这里需要补充一下字节的意思:
在计算机系统和计算机硬件中通常用二进制来表示和存储数据,因为二进制只有0和1两个数字,也就是只有两种状态,与电子设备的开关两种状态相对应。而且数据表示的最小单位是比特(Bit),它可以代表0或者1其中一个,而比比特大的就是字节了,它由8个比特位组成,也是由0或者1组成,每一个比特位都有两种可能,所以总共有2的8次方256种可能,这意味着一个字节可以存储0~255,也就是256种数,那4个字节呢?就是32个比特位,即2的32次方,所以有2的32次方种可能,即能表示0~(2的32次方-1)细心的小伙伴肯定会发现这是unsigned int所能表示的范围啊!是的,数据类型所占的字节大小直接决定了它所能表示的数据范围。
回到short,既然short仅占两个字节,那么也就是16个比特位,2的16次方种可能,如果是无符号短整型,那就是0~(2的16次方-1),用代码验证一下:
#include <stdio.h>
#include <limits.h>
int main() {
printf("The range of an unsigned short is: 0 to %hu\n", USHRT_MAX);
return 0;
}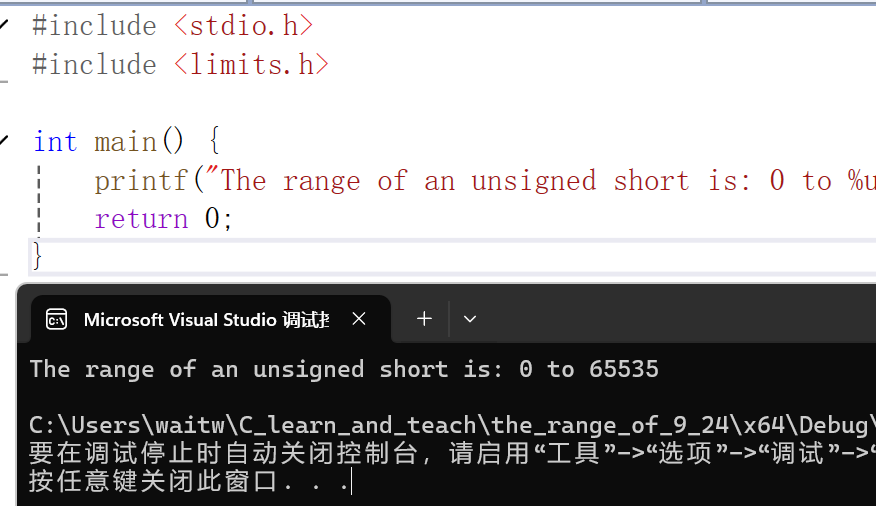
会发现的确是的!那来看一下short(即signed short)
#include <stdio.h>
#include <limits.h>
int main() {
printf("The range of a signed short is: %hd to %hd\n", SHRT_MIN, SHRT_MAX);
return 0;
}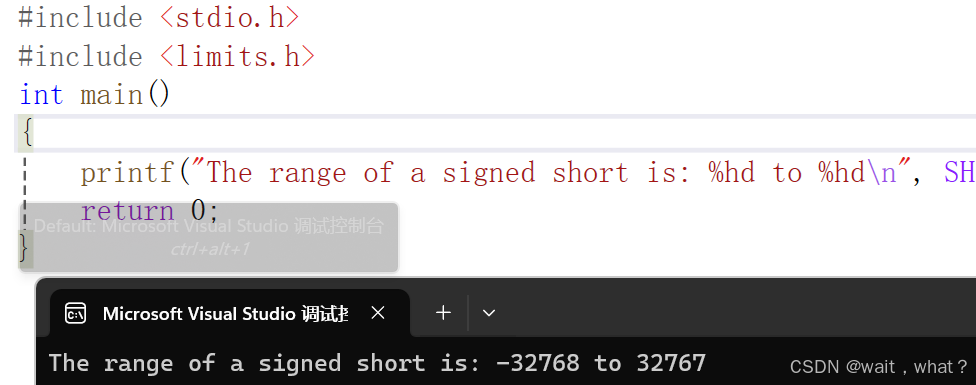 看上面的输出结果,也是总共2的16次方种可能的数。
看上面的输出结果,也是总共2的16次方种可能的数。
各种整型类型所占字节数
那我们就来看看上面列举出的各个数据类型所占字节数吧!要用到下面的代码:
#include <stdio.h>
#include <limits.h>
int main() {
printf("Size of short: %zu bytes\n", sizeof(short));
printf("Size of unsigned short: %zu bytes\n", sizeof(unsigned short));
printf("Size of int: %zu bytes\n", sizeof(int));
printf("Size of unsigned int: %zu bytes\n", sizeof(unsigned int));
printf("Size of long: %zu bytes\n", sizeof(long));
printf("Size of unsigned long: %zu bytes\n", sizeof(unsigned long));
printf("Size of long long: %zu bytes\n", sizeof(long long));
printf("Size of unsigned long long: %zu bytes\n", sizeof(unsigned long long));
return 0;
}控制台结果:
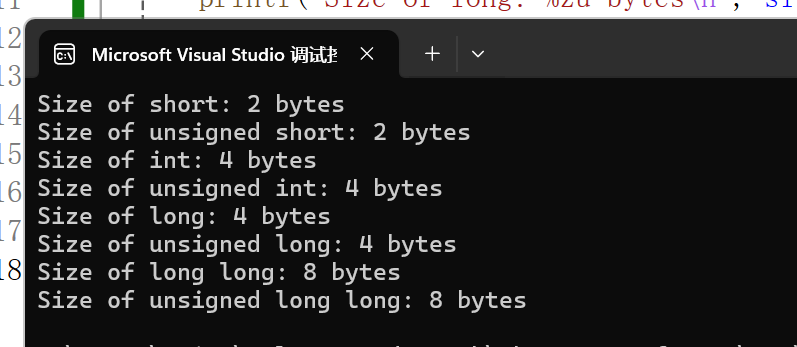
跟我们上面说的是可以呼应上的。补充:不同大小的数据用不同的数据类型是为了更高效地规划我们的内存使用。
总结和预告
今天主要讲的是整型的各种类型以及它们各占的内存大小,明天会讲浮点数的类型,应该浮点型不只有float吧?

















 5565
5565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









