







文章目录
- 基础
- 简单应用
- 批量生成VHDLのcomponent
- 遍历文件夹获得某格式的所有文件
- 十进制转换成二进制/十六进制
- 获得操作系统环境
- 批量移动B站的m4s文件
- 移动迅雷未下载完成的文件到另一文件夹下(文件夹内层级不变)
- 转换文件的编码类型
- 从文件尾部逆序读数据
- 将ascii数字转换为16进制的bin文件
- 合并VHDL/Verilog文件
- 实现UCF到XDC的转换
- 产生tcl脚本来定制VIO
- 整理ISE工程中ipcore_dir下的文件
- 定时备份vivado工程中的hw文件夹
- 解析7系列FPGA的BIT文件
- 解析vhd生成tcl,自动添加观测信号
- 辅助编辑CPJ文件
- 生成BlackBox的配置文件
- 移除文件中的注释
- 使用Inline模块
- 使用here文档格式输出多行文本
- 调用cmd/exe
- 其他
基础
Perl最佳实践_阅读记录
命名惯例
标识符
namespace -> Noun::Adjective::Adjective
| Noun::Adjective
| Noun
package Disk;
package Disk::Audio;
package Disk::DVD::Rewritable;
variable -> [adjective_]* noun
my $next_client;
my $root_node;
my $final_total;
look-variable -> [adjective_]* noun preposition
my %title_of;
my @sales_from;
routine -> imperative_verb [_adjective]? _ noun _ preposition
| imperative_verb [_adjective]? _ noun _ participle
| imperative_verb [_adjective]? _ noun
sub get_record
sub get_record_for
布尔值
sub is_valid
sub has_end_tag
my $has_found_bad_record;
引用变量
把存储引用的变量标上_ref后缀
my @books;
my $books_ref = \@books;
数组/散列
数组以复数命名,而散列以单数命名
my %option;
my %title_of;
my @events;
my @handlers;
控制结构
后缀if保留给流程控制语句,如next、last、redo等;
其他情况尽量使用if块;
不要使用unless、until等后缀
子程序
不要把子程序的名称取得和内置函数相同;
标量返回值一定要用return scalar;
让返回列表的子程序在标量上下文返回“明显的”值;
通过显示的return来返回
正则表达式
一定要使用/x标记;
一定要使用/m标记;
以\A和\z作为字符串边界锚点;
总是使用/s标记;
考虑强制使用Regexp::Autoflags模块;
优先使用m{…},少在多行正则表达式中用/…/;
考虑使用Regexp::Common,不要自己写正则表达式;
perl面向对象_原生
文章目录
- 基础
- 简单应用
- 批量生成VHDLのcomponent
- 遍历文件夹获得某格式的所有文件
- 十进制转换成二进制/十六进制
- 获得操作系统环境
- 批量移动B站的m4s文件
- 移动迅雷未下载完成的文件到另一文件夹下(文件夹内层级不变)
- 转换文件的编码类型
- 从文件尾部逆序读数据
- 将ascii数字转换为16进制的bin文件
- 合并VHDL/Verilog文件
- 实现UCF到XDC的转换
- 产生tcl脚本来定制VIO
- 整理ISE工程中ipcore_dir下的文件
- 定时备份vivado工程中的hw文件夹
- 解析7系列FPGA的BIT文件
- 解析vhd生成tcl,自动添加观测信号
- 辅助编辑CPJ文件
- 生成BlackBox的配置文件
- 移除文件中的注释
- 使用Inline模块
- 使用here文档格式输出多行文本
- 调用cmd/exe
- 其他
创建类
package Cat; #声明类->猫
use strict;
use warnings;
# 构造函数
sub new
{
my $invocant = shift;
my $class = ref($invocant) || $invocant; # 对象或者类名
my $self = {
color => "white",
name => "mimi",
@_, # 覆盖之前的属性
};
return bless($self,$class); # 绑定对象
}
# 方法
sub setColor
{
my ($self,$color) = @_;
$self->{"color"} = $color;
}
sub getColor
{
my ($self,$color) = @_;
return $self->{"color"};
}
sub setName
{
my ($self,$name) = @_;
$self->{"name"} = $name;
}
sub getName
{
my ($self,$name) = @_;
return $self->{"name"};
}
1;
继承类
#----------------------------------------------------------
# 一个包的@ISA数组里的每个元素都保存另外一个包的名字,当缺失方法的
# 时候就搜索这些包.
#----------------------------------------------------------
package PersianCat; #声明类->波斯猫;继承类->猫
our @ISA = "Cat"; #注意此处用our声明
use strict;
use warnings;
sub setSound
{
my ($self,$sound) = @_;
$self->{"sound"} = $sound;
}
sub getSound
{
my ($self,$sound) = @_;
return $self->{"sound"};
}
1;
测试
use FindBin;
use lib "$FindBin::RealBin/.";
use Cat;
use PersianCat;
use strict;
use warnings;
my $aa = Cat->new;
my $bb = PersianCat->new(color=>"black");
$bb->setSound("miaomiao"); #设置波斯猫的叫声
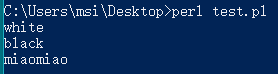
print $aa->getColor(),"\n";
print $bb->getColor(),"\n";
print $bb->getSound(),"\n";
perl面向对象_Moose
Example
package Person;
use Moose; # automatically turns on strict and warnings
has 'name' =>(
is => 'rw',
isa => 'Str'
);
has 'age' =>(
is => 'rw',
isa => 'Int'
);
before 'name' => sub{
print "about to call name","\n";
};
after 'name' => sub{
print "just called name","\n";
};
around 'name' => sub{
my $orig = shift; # CODERef
my $self = shift; # HASHRef
print "around name","\n";
my $name = $self->$orig(@_);
print "still around name","\n";
return $name; # 如果没有此句,则无法正常输出实例的name
};
1;
package User;
use Moose;
extends 'Person';
has 'password' => (
is => 'rw',
isa => 'Str'
);
1;
use FindBin;
use lib "$FindBin::RealBin/.";
use 5.024;
use Person;
use User;
# my $Person_1 = Person->new('age'=>18,'name'=>'Tom'); #OK
my $Person_1 = Person->new(age=>18,name=>'Tom'); #OK
my $Person_2 = Person->new('age'=>10,'name'=>'Jerry');
my $User_1 = User->new(age=>99,name=>'John');
$User_1->password("123456789-a"); #right
# $User_1->password = "123456789-a"; #wrong
say $Person_1->name; #right
# say $Person_1->'name'; #wrong
say $Person_1->age;
say $Person_2->name;
say $Person_2->age;
say $User_1->name;
say $User_1->age;
say $User_1->password;
运行结果

Manual
Moose

Types

MethodModifiers

Roles

Perl命令行选项处理
概述
进行命令行选项处理时,通常使用Getopt::Std模块与Getopt::Long 模块,两个模块之间的主要区别在于 Getopt::Long 接受双减号前缀的长选项命名风格。

Getopt::Long模块
Getopt::Long 模块实现了许多可选功能,例如缩写、区分大小写和严格或松散选项匹配;常用的选项如下,


- GetOptions函数用来解析 @ARGV 的内容。如果 GetOptions函数能正常解析命令选项时,则会返回true;否则会返回undef,并返回一个警告信息
- 如果我们不提供引用的话,那么GetOptions 将定义一个名为 $opt_ 的全局标量;GetOptions 还接受哈希引用作为其第一个参数,并将在其中存储已解析的参数
例子
例1(直接使用选项名称)
use strict;
use warnings;
use Getopt::Long;
#----------------------------------------------------------
# 函数声明
#----------------------------------------------------------
sub subUsage();
#----------------------------------------------------------
# main
#----------------------------------------------------------
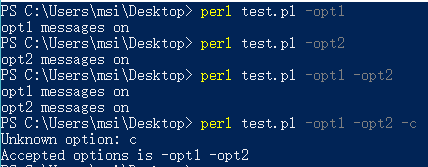
my ($opt1, $opt2);
if(GetOptions(opt1 => \$opt1, opt2 => \$opt2))
{
print "opt1 messages on \n" if $opt1;
print "opt2 messages on \n" if $opt2;
}
else #当未正常解析命令选项时,调用subUsage函数来输出帮助信息
{
subUsage();
exit;
}
#----------------------------------------------------------
# 函数定义
#----------------------------------------------------------
sub subUsage()
{
print "Accepted options is -opt1 -opt2","\n";
}
运行效果如下,
例2(使用hash存储选项名称)
...
my %opts;
if(GetOptions(\%opts,'opt1','opt2'))
{
print "opt1 messages on \n" if $opts{opt1};
print "opt2 messages on \n" if $opts{opt2};
}
else #当未正常解析命令选项时,调用subUsage函数来输出帮助信息
{
subUsage();
exit;
}
....
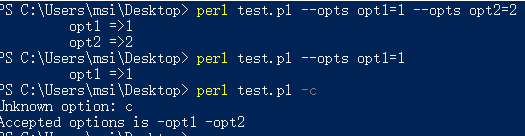
例3(使用hash;设置选项输入值为字符串)
....
my %opts;
if(GetOptions("opts=s" => \%opts))
{
foreach(keys %opts)
{
print "\t $_ =>$opts{$_} \n";
}
}
else #当未正常解析命令选项时,调用subUsage函数来输出帮助信息
{
subUsage();
exit;
}
....
例4(使用bundling、配置选项为大小写敏感)
use strict;
use warnings;
use Getopt::Long;
#Getopt::Long::Configure("ignore_case"); # default behavior
Getopt::Long::Configure("no_ignore_case"); # '--Option' case sensitive
Getopt::Long::Configure("bundling");
#----------------------------------------------------------
# 函数声明
#----------------------------------------------------------
sub subUsage();
#----------------------------------------------------------
# main
#----------------------------------------------------------
my $help;
my $debug;
my $optResult = GetOptions(
'help|h' => \$help,
'debug|d' => \$debug
);
if($optResult)
{
print "help message is on\n" if $help;
print "debug message is on\n" if $debug;
}
else #当未正常解析命令选项时,调用subUsage函数来输出帮助信息
{
subUsage();
exit;
}
#----------------------------------------------------------
# 函数定义
#----------------------------------------------------------
sub subUsage()
{
print "Accepted options is xxxx","\n";
}

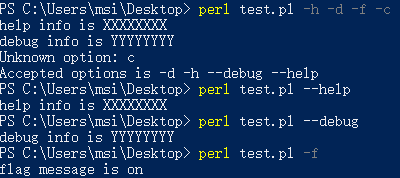
例5(为选项添加函数引用)
use strict;
use warnings;
use Getopt::Long;
#Getopt::Long::Configure("ignore_case"); # default behavior
Getopt::Long::Configure("no_ignore_case"); # '--Option' case sensitive
Getopt::Long::Configure("bundling");
#----------------------------------------------------------
# 函数声明
#----------------------------------------------------------
sub subUsage();
#----------------------------------------------------------
# main
#----------------------------------------------------------
my $help;
my $debug;
my $flag;
my $optResult = GetOptions(
'help|h' => sub { subHelpInfo () },
'debug|d' => sub { subDebugInfo() },
'flag|f' => \$flag
);
if($optResult)
{
print "flag message is on\n" if $flag;
}
else #当未正常解析命令选项时,调用subUsage函数来输出帮助信息
{
subUsage();
exit;
}
#----------------------------------------------------------
# 函数定义
#----------------------------------------------------------
sub subUsage()
{
print "Accepted options is -d -h --debug --help","\n";
}
sub subHelpInfo()
{
print "help info is XXXXXXXX","\n";
}
sub subDebugInfo()
{
print "debug info is YYYYYYYY","\n";
}
Perl脚本编译
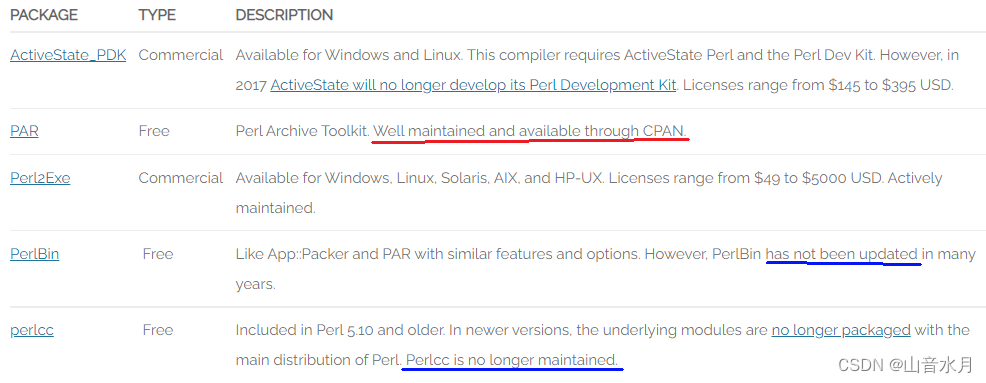
编译perl脚本的理由
- 运行 perl 脚本需要电脑上安装有perl interpreter和相应的模块
- 任何人都可以看到这些脚本的源代码
- 对于用户而言,二进制可执行文件可能更简单
编译perl脚本的方法
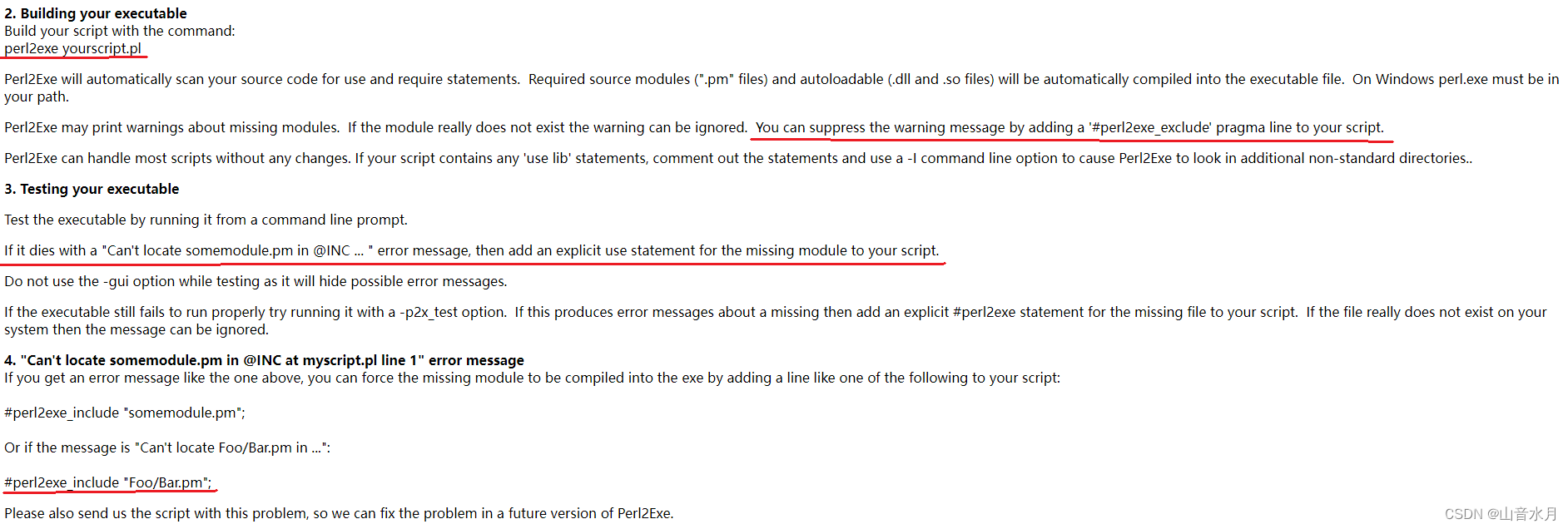
使用perl2exe
官网上下载的是试用版,生成的exe文件在执行之后,会显示试用信息。并且,当使用Encode模块时,也会有一些问题;此时,可以通过perl2exe_include的方式来解决。
在perl中打印出来看一看支持什么编码
use Encode;
print "$_\n" for Encode->encodings(":all");
使用PAR
pp命令行的使用方式
pp -M PAR -M Data::Dumper -x -o test.exe test.pl

加密源码
pp -f Bleach -F Bleach -M PAR -M Data::Dumper -x -o test.exe test.pl
初尝试
在perl的命令行中使用pp命令,生成exe文件
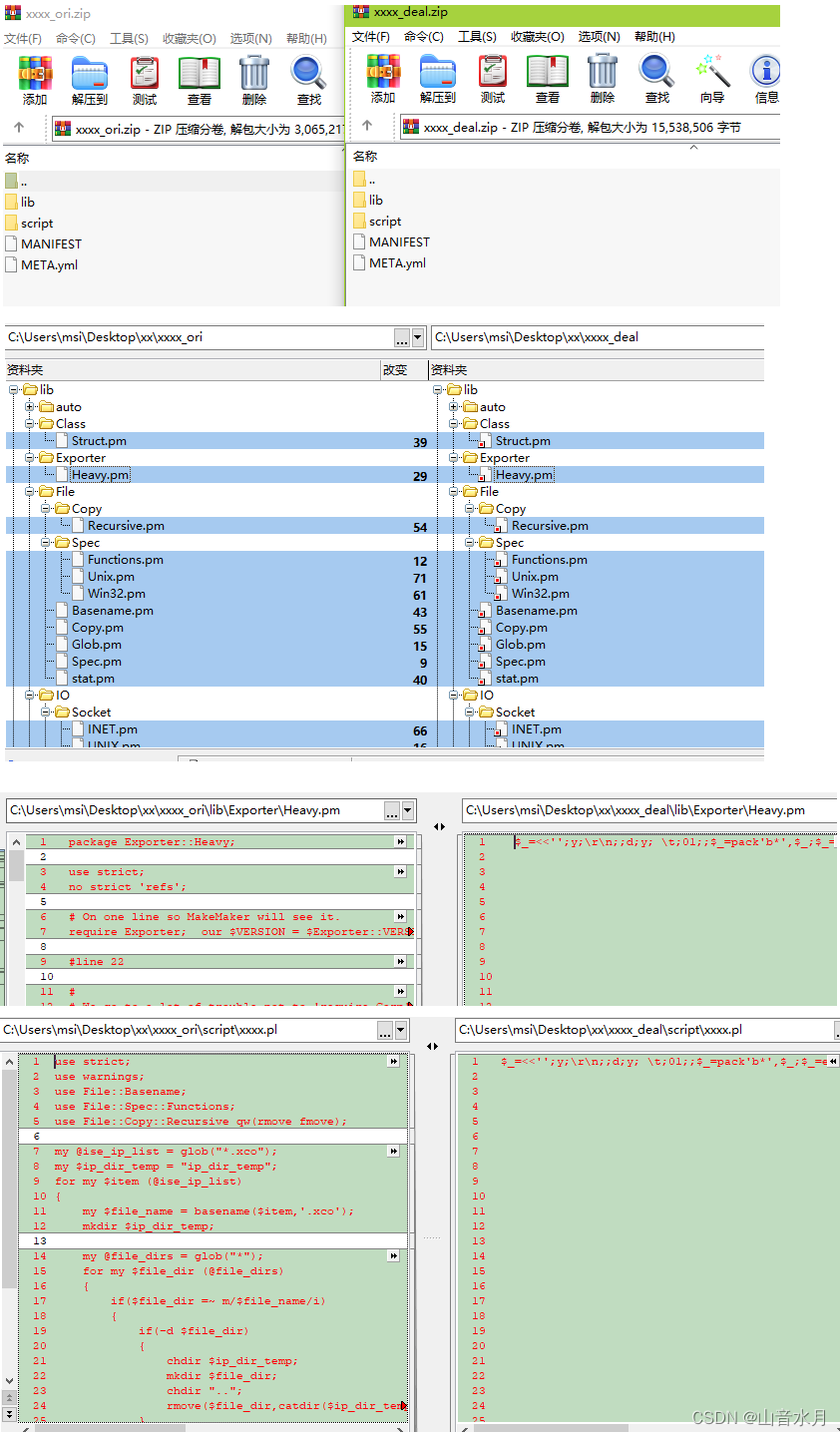
将生成的exe改成zip后缀,可以看到生成的其实是一个压缩包,里面包含lib模块及相应的脚本,可以看到,加密之前,源码其实还是可以看到的,加密之后,源码不可见
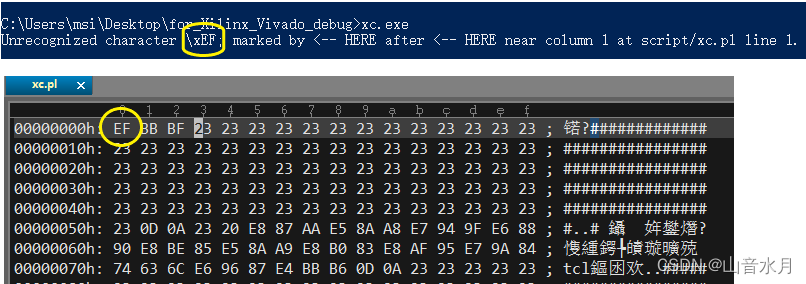
遇到的错误
在调用生成的exe文件时,出现了下述错误,使用十六进制显示pl文件的内容,发现首数据的确是0xEF;于是,新建一个文件,复制粘贴,再重新生成exe,调用成功。
博文链接
A Beginner’s Guide to Compiling Perl Scripts
创建/使用Perl模块
在Perl中,可以通过创建模块实现对代码的封装、复用。创建模块有两种方式:面向对象模块、传统函数模块。Perl中究竟如何面向对象,现在还只是有个大概印象,在本文中,仅以传统函数模块为例。
创建模块
TestModule.pm
#!/usr/bin/perl
package TestModule 1.000;
use parent qw(Exporter);
@EXPORT = qw(subA subB); #默认导出
@EXPORT_OK = qw(subC); #根据请求导出
sub subA { print "This subA\n"}
sub subB { print "This subB\n"}
sub subC { print "This subC\n"}
1;
使用模块
创建模块之后,如果想在脚本中使用模块,需要注意模块的路径(默认lib文件夹)。
如果直接如下脚本使用,会提示找不到模块,
test.pl
#!/usr/bin/perl
use TestModule;
subA();
subB();

此时,可以修改@INC的值,也可以在脚本之中指定模块的路径,如下
test.pl
#!/usr/bin/perl
use FindBin; #获得脚本位置
use lib "$FindBin::RealBin/.";
use TestModule;
#use TestModule qw(subC);
#print "$FindBin::RealBin \n"; # 测试使用
subA();
subB();
博文链接
Perl之安装卸载CPAN模块
在线安装模块
使用 CPAN 安装 Perl 模块
安装某模块
需要在离线情况下为Strawberry Perl安装cpan上的模块,折腾了一会,简要记录一下,
1-务必将待安装模块的依赖模块也准备一下
2-使用Makefile.PL文件安装的时候,make命令要替换成gmake命令
perl Makefile.PL
gmake
gmake test
gmake install
3-使用Build.PL文件安装时,
perl Build.PL
Build
Build test
Build install
卸载某模块
如果需要卸载的话,Strawberry Perl已安装了App::cpanminus模块,可以使用如下命令
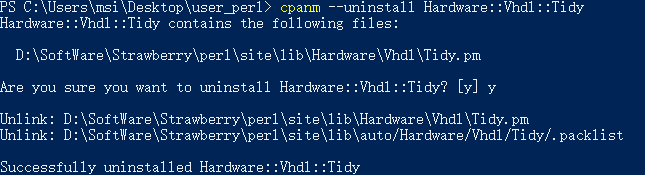
如果未安装cpanm,也可以在安装模块的源代码目录下,使用gmake uninstall命令,弹出的信息会提示应当手动删除哪些文件
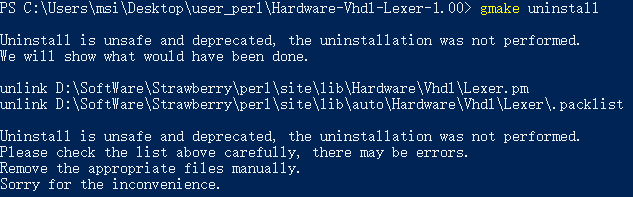
查询已安装模块

不过,似乎有的时候,卸载模块后,perllocal信息不会及时更新,这时可以人工维护一下perllocal.pod文件(内含模块安装信息)
正则表达式相关
贪婪匹配 & 非贪婪匹配

模式匹配修饰符

不捕获模式 & 命名捕获

Split函数的用法

perldsc代码范例(官方文档里的)
Presented with little comment (these will get their own manpages someday) here are short code examples illustrating access of various types of data structures.
ARRAYS OF ARRAYS
Declaration of an ARRAY OF ARRAYS
@AoA = (
[ "fred", "barney" ],
[ "george", "jane", "elroy" ],
[ "homer", "marge", "bart" ],
);
Generation of an ARRAY OF ARRAYS
# reading from file
while ( <> ) {
push @AoA, [ split ];
}
# calling a function
for $i ( 1 .. 10 ) {
$AoA[$i] = [ somefunc($i) ];
}
# using temp vars
for $i ( 1 .. 10 ) {
@tmp = somefunc($i);
$AoA[$i] = [ @tmp ];
}
# add to an existing row
push @{ $AoA[0] }, "wilma", "betty";
Access and Printing of an ARRAY OF ARRAYS
# one element
$AoA[0][0] = "Fred";
# another element
$AoA[1][1] =~ s/(\w)/\u$1/;
# print the whole thing with refs
for $aref ( @AoA ) {
print "\t [ @$aref ],\n";
}
# print the whole thing with indices
for $i ( 0 .. $#AoA ) {
print "\t [ @{$AoA[$i]} ],\n";
}
# print the whole thing one at a time
for $i ( 0 .. $#AoA ) {
for $j ( 0 .. $#{ $AoA[$i] } ) {
print "elt $i $j is $AoA[$i][$j]\n";
}
}
HASHES OF ARRAYS
Declaration of a HASH OF ARRAYS
%HoA = (
flintstones => [ "fred", "barney" ],
jetsons => [ "george", "jane", "elroy" ],
simpsons => [ "homer", "marge", "bart" ],
);
Generation of a HASH OF ARRAYS
# reading from file
# flintstones: fred barney wilma dino
while ( <> ) {
next unless s/^(.*?):\s*//;
$HoA{$1} = [ split ];
}
# reading from file; more temps
# flintstones: fred barney wilma dino
while ( $line = <> ) {
($who, $rest) = split /:\s*/, $line, 2;
@fields = split ' ', $rest;
$HoA{$who} = [ @fields ];
}
# calling a function that returns a list
for $group ( "simpsons", "jetsons", "flintstones" ) {
$HoA{$group} = [ get_family($group) ];
}
# likewise, but using temps
for $group ( "simpsons", "jetsons", "flintstones" ) {
@members = get_family($group);
$HoA{$group} = [ @members ];
}
# append new members to an existing family
push @{ $HoA{"flintstones"} }, "wilma", "betty";
Access and Printing of a HASH OF ARRAYS
# one element
$HoA{flintstones}[0] = "Fred";
# another element
$HoA{simpsons}[1] =~ s/(\w)/\u$1/;
# print the whole thing
foreach $family ( keys %HoA ) {
print "$family: @{ $HoA{$family} }\n"
}
# print the whole thing with indices
foreach $family ( keys %HoA ) {
print "family: ";
foreach $i ( 0 .. $#{ $HoA{$family} } ) {
print " $i = $HoA{$family}[$i]";
}
print "\n";
}
# print the whole thing sorted by number of members
foreach $family ( sort { @{$HoA{$b}} <=> @{$HoA{$a}} } keys %HoA ) {
print "$family: @{ $HoA{$family} }\n"
}
# print the whole thing sorted by number of members and name
foreach $family ( sort {
@{$HoA{$b}} <=> @{$HoA{$a}}
||
$a cmp $b
} keys %HoA )
{
print "$family: ", join(", ", sort @{ $HoA{$family} }), "\n";
}
ARRAYS OF HASHES
Declaration of an ARRAY OF HASHES
@AoH = (
{
Lead => "fred",
Friend => "barney",
},
{
Lead => "george",
Wife => "jane",
Son => "elroy",
},
{
Lead => "homer",
Wife => "marge",
Son => "bart",
}
);
Generation of an ARRAY OF HASHES
# reading from file
# format: LEAD=fred FRIEND=barney
while ( <> ) {
$rec = {};
for $field ( split ) {
($key, $value) = split /=/, $field;
$rec->{$key} = $value;
}
push @AoH, $rec;
}
# reading from file
# format: LEAD=fred FRIEND=barney
# no temp
while ( <> ) {
push @AoH, { split /[\s+=]/ };
}
# calling a function that returns a key/value pair list, like
# "lead","fred","daughter","pebbles"
while ( %fields = getnextpairset() ) {
push @AoH, { %fields };
}
# likewise, but using no temp vars
while (<>) {
push @AoH, { parsepairs($_) };
}
# add key/value to an element
$AoH[0]{pet} = "dino";
$AoH[2]{pet} = "santa's little helper";
Access and Printing of an ARRAY OF HASHES
# one element
$AoH[0]{lead} = "fred";
# another element
$AoH[1]{lead} =~ s/(\w)/\u$1/;
# print the whole thing with refs
for $href ( @AoH ) {
print "{ ";
for $role ( keys %$href ) {
print "$role=$href->{$role} ";
}
print "}\n";
}
# print the whole thing with indices
for $i ( 0 .. $#AoH ) {
print "$i is { ";
for $role ( keys %{ $AoH[$i] } ) {
print "$role=$AoH[$i]{$role} ";
}
print "}\n";
}
# print the whole thing one at a time
for $i ( 0 .. $#AoH ) {
for $role ( keys %{ $AoH[$i] } ) {
print "elt $i $role is $AoH[$i]{$role}\n";
}
}
HASHES OF HASHES
Declaration of a HASH OF HASHES
%HoH = (
flintstones => {
lead => "fred",
pal => "barney",
},
jetsons => {
lead => "george",
wife => "jane",
"his boy" => "elroy",
},
simpsons => {
lead => "homer",
wife => "marge",
kid => "bart",
},
);
Generation of a HASH OF HASHES
# reading from file
# flintstones: lead=fred pal=barney wife=wilma pet=dino
while ( <> ) {
next unless s/^(.*?):\s*//;
$who = $1;
for $field ( split ) {
($key, $value) = split /=/, $field;
$HoH{$who}{$key} = $value;
}
# reading from file; more temps
while ( <> ) {
next unless s/^(.*?):\s*//;
$who = $1;
$rec = {};
$HoH{$who} = $rec;
for $field ( split ) {
($key, $value) = split /=/, $field;
$rec->{$key} = $value;
}
}
# calling a function that returns a key,value hash
for $group ( "simpsons", "jetsons", "flintstones" ) {
$HoH{$group} = { get_family($group) };
}
# likewise, but using temps
for $group ( "simpsons", "jetsons", "flintstones" ) {
%members = get_family($group);
$HoH{$group} = { %members };
}
# append new members to an existing family
%new_folks = (
wife => "wilma",
pet => "dino",
);
for $what (keys %new_folks) {
$HoH{flintstones}{$what} = $new_folks{$what};
}
Access and Printing of a HASH OF HASHES
# one element
$HoH{flintstones}{wife} = "wilma";
# another element
$HoH{simpsons}{lead} =~ s/(\w)/\u$1/;
# print the whole thing
foreach $family ( keys %HoH ) {
print "$family: { ";
for $role ( keys %{ $HoH{$family} } ) {
print "$role=$HoH{$family}{$role} ";
}
print "}\n";
}
# print the whole thing somewhat sorted
foreach $family ( sort keys %HoH ) {
print "$family: { ";
for $role ( sort keys %{ $HoH{$family} } ) {
print "$role=$HoH{$family}{$role} ";
}
print "}\n";
}
# print the whole thing sorted by number of members
foreach $family ( sort { keys %{$HoH{$b}} <=> keys %{$HoH{$a}} }
keys %HoH )
{
print "$family: { ";
for $role ( sort keys %{ $HoH{$family} } ) {
print "$role=$HoH{$family}{$role} ";
}
print "}\n";
}
# establish a sort order (rank) for each role
$i = 0;
for ( qw(lead wife son daughter pal pet) ) { $rank{$_} = ++$i }
# now print the whole thing sorted by number of members
foreach $family ( sort { keys %{ $HoH{$b} } <=> keys %{ $HoH{$a} } }
keys %HoH )
{
print "$family: { ";
# and print these according to rank order
for $role ( sort { $rank{$a} <=> $rank{$b} }
keys %{ $HoH{$family} } )
{
print "$role=$HoH{$family}{$role} ";
}
print "}\n";
}
MORE ELABORATE RECORDS
Declaration of MORE ELABORATE RECORDS
Here’s a sample showing how to create and use a record whose fields are of many different sorts:
$rec = {
TEXT => $string,
SEQUENCE => [ @old_values ],
LOOKUP => { %some_table },
THATCODE => \&some_function,
THISCODE => sub { $_[0] ** $_[1] },
HANDLE => \*STDOUT,
};
print $rec->{TEXT};
print $rec->{SEQUENCE}[0];
$last = pop @ { $rec->{SEQUENCE} };
print $rec->{LOOKUP}{"key"};
($first_k, $first_v) = each %{ $rec->{LOOKUP} };
$answer = $rec->{THATCODE}->($arg);
$answer = $rec->{THISCODE}->($arg1, $arg2);
# careful of extra block braces on fh ref
print { $rec->{HANDLE} } "a string\n";
use FileHandle;
$rec->{HANDLE}->autoflush(1);
$rec->{HANDLE}->print(" a string\n");
Declaration of a HASH OF COMPLEX RECORDS
%TV = (
flintstones => {
series => "flintstones",
nights => [ qw(monday thursday friday) ],
members => [
{ name => "fred", role => "lead", age => 36, },
{ name => "wilma", role => "wife", age => 31, },
{ name => "pebbles", role => "kid", age => 4, },
],
},
jetsons => {
series => "jetsons",
nights => [ qw(wednesday saturday) ],
members => [
{ name => "george", role => "lead", age => 41, },
{ name => "jane", role => "wife", age => 39, },
{ name => "elroy", role => "kid", age => 9, },
],
},
simpsons => {
series => "simpsons",
nights => [ qw(monday) ],
members => [
{ name => "homer", role => "lead", age => 34, },
{ name => "marge", role => "wife", age => 37, },
{ name => "bart", role => "kid", age => 11, },
],
},
);
Generation of a HASH OF COMPLEX RECORDS
# reading from file
# this is most easily done by having the file itself be
# in the raw data format as shown above. perl is happy
# to parse complex data structures if declared as data, so
# sometimes it's easiest to do that
# here's a piece by piece build up
$rec = {};
$rec->{series} = "flintstones";
$rec->{nights} = [ find_days() ];
@members = ();
# assume this file in field=value syntax
while (<>) {
%fields = split /[\s=]+/;
push @members, { %fields };
}
$rec->{members} = [ @members ];
# now remember the whole thing
$TV{ $rec->{series} } = $rec;
###########################################################
# now, you might want to make interesting extra fields that
# include pointers back into the same data structure so if
# change one piece, it changes everywhere, like for example
# if you wanted a {kids} field that was a reference
# to an array of the kids' records without having duplicate
# records and thus update problems.
###########################################################
foreach $family (keys %TV) {
$rec = $TV{$family}; # temp pointer
@kids = ();
for $person ( @{ $rec->{members} } ) {
if ($person->{role} =~ /kid|son|daughter/) {
push @kids, $person;
}
}
# REMEMBER: $rec and $TV{$family} point to same data!!
$rec->{kids} = [ @kids ];
}
# you copied the array, but the array itself contains pointers
# to uncopied objects. this means that if you make bart get
# older via
$TV{simpsons}{kids}[0]{age}++;
# then this would also change in
print $TV{simpsons}{members}[2]{age};
# because $TV{simpsons}{kids}[0] and $TV{simpsons}{members}[2]
# both point to the same underlying anonymous hash table
# print the whole thing
foreach $family ( keys %TV ) {
print "the $family";
print " is on during @{ $TV{$family}{nights} }\n";
print "its members are:\n";
for $who ( @{ $TV{$family}{members} } ) {
print " $who->{name} ($who->{role}), age $who->{age}\n";
}
print "it turns out that $TV{$family}{lead} has ";
print scalar ( @{ $TV{$family}{kids} } ), " kids named ";
print join (", ", map { $_->{name} } @{ $TV{$family}{kids} } );
print "\n";
}
简单应用
批量生成VHDLのcomponent
use strict;
use warnings;
use diagnostics;
use constant WANT_LIBRARY => 0;
use constant WANT_ENTITY => 1;
use constant WANT_GENERIC_PORT => 2;
use constant WANT_PORT => 3;
use constant WANT_ARCHITECTURE => 4;
#获得VHDL模块的component声明
sub get_component_strs{
my $file_path = shift;
my $state = WANT_LIBRARY;
my @component_strs = qw();
open my $fh,'<',$file_path;
while(<$fh>){
my $line = $_;
next if $line =~ m{[\s]*--}xmi; #匹配到纯注释行语句后,continue
if($line =~ m{[\s]*\blibrary}xmi) { #匹配到library行后,将寻找entity行
$state = WANT_ENTITY;
}
if($line =~ m{[\s]*\bentity[\s]+([\w]+)[\s]+is}xmi) { #匹配到entity行后,将寻找各个参数的名称、类型、值
$state = WANT_GENERIC_PORT;
push @component_strs,"component $1\n";
next;
}
if($state == WANT_GENERIC_PORT){
if($line =~ m{[\s]*\bend[\s]+}xmi){ #匹配到entity的end后,将寻找architecture行
$state = WANT_ARCHITECTURE;
push @component_strs,"end component;\n";
push @component_strs,"\n";
next;
}
push @component_strs,$line;
}
last if $line =~ m{\barchitecture}xmi; #匹配到architecture行后,则跳出
}
close $fh;
return @component_strs;
}
open my $fh,'>',"components_all.vhd";
my @files = glob("*.vhd");
for(@files){
my @component_strs_0 = get_component_strs($_);
for(@component_strs_0){
print $fh $_;
}
}
遍历文件夹获得某格式的所有文件
use strict;
use warnings;
use diagnostics;
use File::Find;
use 5.024;
sub get_specific_files{
my ($dir,$file_desc) = @_;
my @all_files;
my @spec_files;
# Use $File::Find::name instead of $_ to get the paths.
find(sub { push @all_files, $_ }, $dir);
for my $file_item (@all_files){
if($file_item =~ m{$file_desc}xmi){
push @spec_files,$file_item;
}
}
return @spec_files;
}
my @files = qw();
@files = get_specific_files('./','\.v$');
for(@files){
say;
}
@files = get_specific_files('./','\.vhd$');
for(@files){
say;
}
十进制转换成二进制/十六进制
use strict;
use warnings;
use diagnostics;
use 5.024;
sub dec_to_bin{
my ($data,$width,$is_signed) = @_;
my $bin_format = "%0"."$width"."b";
my $bin_str;
if($is_signed){
if( abs($data) > (2**($width-1)) ){
die("Data $data is invalid!")
}
$bin_str = sprintf($bin_format,$data);
if($data>0){
return $bin_str;
}
else{
return substr($bin_str,length($bin_str)-$width,length($bin_str));
}
}
else{
if( abs($data) > (2**$width) ){
die("Data $data is invalid!");
}
$bin_str = sprintf($bin_format,$data);
return $bin_str;
}
}
sub dec_to_hex{
my ($data,$width,$is_signed) = @_;
my $bin_format = "%0"."$width"."x";
my $bin_str;
if($is_signed){
if( abs($data) > (2**(4*$width-1)) ){
die("Data $data is invalid!")
}
$bin_str = sprintf($bin_format,$data);
if($data>0){
return $bin_str;
}
else{
return substr($bin_str,length($bin_str)-$width,length($bin_str));
}
}
else{
if( abs($data) > (2**(4*$width)) ){
die("Data $data is invalid!");
}
$bin_str = sprintf($bin_format,$data);
return $bin_str;
}
}
say dec_to_bin(10,8,1);
say dec_to_bin(-10,8,1);
say dec_to_bin(100,8,0);
say dec_to_hex(10,2,1);
say dec_to_hex(-10,2,1);
say dec_to_hex(100,2,0);
# Hex values
$hexval{"0000"} = "0";
$hexval{"0001"} = "1";
$hexval{"0010"} = "2";
$hexval{"0011"} = "3";
$hexval{"0100"} = "4";
$hexval{"0101"} = "5";
$hexval{"0110"} = "6";
$hexval{"0111"} = "7";
$hexval{"1000"} = "8";
$hexval{"1001"} = "9";
$hexval{"1010"} = "A";
$hexval{"1011"} = "B";
$hexval{"1100"} = "C";
$hexval{"1101"} = "D";
$hexval{"1110"} = "E";
$hexval{"1111"} = "F";
# Binary values
$binval{"0"} = "0000";
$binval{"1"} = "0001";
$binval{"2"} = "0010";
$binval{"3"} = "0011";
$binval{"4"} = "0100";
$binval{"5"} = "0101";
$binval{"6"} = "0110";
$binval{"7"} = "0111";
$binval{"8"} = "1000";
$binval{"9"} = "1001";
$binval{"A"} = "1010";
$binval{"B"} = "1011";
$binval{"C"} = "1100";
$binval{"D"} = "1101";
$binval{"E"} = "1110";
$binval{"F"} = "1111";
$binval{"a"} = "1010";
$binval{"b"} = "1011";
$binval{"c"} = "1100";
$binval{"d"} = "1101";
$binval{"e"} = "1110";
$binval{"f"} = "1111";
sub subHexToBin
{
my $hex = shift(@_);
my $len = shift(@_);
if (!$len)
{
die "ERROR: Illegal subHexToBin length - $len\n";
}
$bin = "";
while (length($hex))
{
$hexchar = substr($hex,0,1);
$binset = $binval{$hexchar};
if (!length($binset))
{
die "ERROR: Illegal hex character = $hexchar\n";
}
$bin .= $binset;
$hex = substr($hex,1);
}
while (length($bin)<$len)
{
$bin = "0" . $bin;
}
while (length($bin)>$len)
{
$bin = substr($bin,1);
}
return $bin;
}
sub subBinToHex
{
my $bin = shift(@_);
$hex = "";
while (length($bin)%4)
{
$bin = "0" . $bin;
}
while (length($bin))
{
$hex .= $hexval{substr($bin,0,4)};
$bin = substr($bin,4);
}
return $hex;
}
获得操作系统环境
sub find_operating_system
{
if ($^O =~ /MSWin/){
$l = "\\";
$remove = "del";
$force = "/S /Q";
$move = "move";
print "\n\nINFO: Windows Operating System found\n\n";
}
elsif ($^O =~ /linux/) {
$l= "/";
$remove = "rm";
$force = "-rf";
$move = "mv";
print "\nINFO: Linux Operating System found\n\n";
}
else {
print "\n\nCRIT_ERR: Operating System not supported";
exit;
}
} #end find_operating_system
批量移动B站的m4s文件
从B站下载某个系列视频后,发现各集视频分放在多个独立的文件夹下,因此编个小脚本批量移动、重命名文件。
use strict;
use warnings;
use File::Copy;
use File::Find;
use File::Basename;
my $dir_deal = 'C:\Users\msi\Desktop\for_bilibili';
my @dirs = ".";
my $findfile;
my $path;
my $leaf;
sub wanted {
$findfile = $File::Find::name;
if ($findfile =~/audio.m4s/) {
$path = dirname($findfile);
$leaf = basename($findfile);
if($path=~ /\.\/(\d+)\//)
{
print $1,'---->',$leaf,"\n";
# 复制文件,重命名文件,拷贝到指定的文件夹
copy($leaf,$1.'.mp3');
copy($1.'.mp3',$dir_deal);
unlink $1.'.mp3';
}
}
}
find(\&wanted, @dirs);
移动迅雷未下载完成的文件到另一文件夹下(文件夹内层级不变)
use strict;
use warnings;
use File::Copy;
use File::Find;
use File::Basename;
use File::Path qw(make_path);
my $dir_deal = 'E:/xxx';
my @dirs = 'F:/其他';
my $new_path;
my $findfile;
my $path;
my $leaf;
sub wanted {
$findfile = $File::Find::name;
if ($findfile =~/xltd/) {
$path = dirname($findfile);
$leaf = basename($findfile);
my $path_deal = $path;
$path_deal =~ s{F:/其他}{}gi;
$new_path = $dir_deal.$path_deal;
make_path($new_path);
$new_path = $dir_deal.$path_deal."/".$leaf;
print "-----------------------\n";
# print $path,"\n";
# print $leaf,"\n";
# print $new_path,"\n";
copy $leaf,$new_path;
print "move done!\n";
}
}
find(\&wanted, @dirs);
转换文件的编码类型
有时会有对文件进行编码类型转换的需求,虽然目前的文本编辑软件大都提供了转换的功能,但批量转换还是不太方便。写了个小函数,能进行utf8->gbk或gbk->utf8的转换,如下
use strict;
use warnings;
use utf8;
use Encode;
sub convert_utf8_to_gbk;
sub convert_gbk_to_utf8;
#----------------------------------------------------------
# 主函数
#----------------------------------------------------------
my $dir_name = "deal_dir";
unless (-e $dir_name)
{
mkdir $dir_name;
}
my $file_path = "test.m";
convert_utf8_to_gbk($file_path,$dir_name);
#convert_gbk_to_utf8($file_path,$dir_name);
#----------------------------------------------------------
# 子函数
#----------------------------------------------------------
sub convert_utf8_to_gbk
{
my $utf8_file = shift;
my $dir_name = shift;
my $gbk_file = $dir_name."/".$utf8_file;
open my $file_rd,'<:encoding(utf8)',$utf8_file;
open my $file_wr,'>:encoding(gbk)',$gbk_file;
while(<$file_rd>)
{
chomp;
print $file_wr $_,"\n";
}
close $file_rd;
close $file_wr;
}
sub convert_gbk_to_utf8
{
my $gbk_file = shift;
my $dir_name = shift;
my $utf8_file = $dir_name."/".$gbk_file;
open my $file_rd,'<:encoding(gbk)',$gbk_file;
open my $file_wr,'>:encoding(utf8)',$utf8_file;
while(<$file_rd>)
{
chomp;
print $file_wr $_,"\n";
}
close $file_rd;
close $file_wr;
}
从文件尾部逆序读数据
use strict;
use warnings;
use Fcntl qw(SEEK_SET SEEK_CUR SEEK_END);
my $fid;
my $byte_offsets;
my $data;
my $hex_data;
open $fid,'<','data.txt';
$byte_offsets = -1;
seek $fid,$byte_offsets,SEEK_END; #移动到文件末尾的前一个字节
read $fid,$data,1; #读取一个字节
$hex_data = unpack("H*",$data);
print $hex_data,"\n";
while($hex_data eq "30")
{
$byte_offsets--;
seek $fid,$byte_offsets,SEEK_END; #始终以文件末尾为基准,向前读取文件
read $fid,$data,1;
$hex_data = unpack("H*",$data);
print $hex_data,"\n";
}
print "----------------------------------\n";
print -($byte_offsets+1),"\n";

将ascii数字转换为16进制的bin文件
注意,下面的代码,没有将文件句柄设为二进制,就导致0a转换为二进制文件时变成了0d 0a
open my $fid_w,">","xx.bin";
$xx = '0A';
my $bytes = pack 'H*','xx';
print $fid_w $bytes;
当加上binmode的设置后,正常了
open my $fid_w,">","xx.bin";
binmode $$fid_w;
$xx = '0A';
my $bytes = pack 'H*','xx';
print $fid_w $bytes;
完整代码如下,能将文件中的0x01,0xaa等转换为16进制的bin文件,
use strict;
use warnings;
open my $fid_r,"<","xx.txt";
open my $fid_w,">","xx.bin";
binmode $$fid_w;
while(my $line=<$fid_r>)
{
chomp $line;
$line =~ s/\s+//sgi;
$line =~ s/,//sgi;
$line =~ s/0x//sgi;
my $bytes = pack 'H*',$line;
print $fid_w $bytes;
}
close $fid_r;
close $fid_w;
合并VHDL/Verilog文件
use strict;
use warnings;
#----------------------------------------------------------
# main
#----------------------------------------------------------
my $fid_w;
my $fid_r;
my $file_nums;
my @vhd_files;
my @ver_files;
if(-e "merge_vhd_files.vhd")
{
unlink "merge_vhd_files.vhd";
print "delete merge_vhd_files.vhd","\n";
}
if(-e "merge_ver_files.v")
{
unlink "merge_ver_files.v";
print "delete merge_v_files.v","\n";
}
@vhd_files = glob("*.vhd");
my $file_nums = @vhd_files;
if ($file_nums>0)
{
open $fid_w,">","merge_vhd_files.vhd";
for my $vhd_file (@vhd_files)
{
print $vhd_file,"\n";
open $fid_r,"<",$vhd_file;
while(<$fid_r>)
{
print $fid_w $_;
}
close $fid_r;
}
close $fid_w;
}
@ver_files = glob("*.v");
$file_nums = @ver_files;
if ($file_nums>0)
{
open $fid_w,">","merge_ver_files.v";
for my $ver_file (@ver_files)
{
print $ver_file,"\n";
open $fid_r,"<",$ver_file;
while(<$fid_r>)
{
print $fid_w $_;
}
close $fid_r;
}
close $fid_w;
}
实现UCF到XDC的转换
自实现版本
use strict;
use warnings;
my $fid;
my @ucfFileAy = glob("*.ucf");
for my $ucfFile (@ucfFileAy)
{
open $fid,'<',$ucfFile;
my @pinAy;
#获取引脚名称
while(<$fid>)
{
chomp;
next if /^\s*$/; # 空白行跳过
next if /^\s*\#/; # 注释行跳过
if(/LOC/)
{
if(/\s*NET\s*"([\w<>]+)"/gi)
{
my $href = {"pin_name",$1,"pin_loc","","pin_iostandard",""};
push @pinAy,$href;
}
}
}
close($fid);
#获取引脚属性
open $fid,'<',$ucfFile;
while(<$fid>)
{
chomp;
next if /^\s*$/; # 空白行跳过
next if /^\s*\#/; # 注释行跳过
for my $href (@pinAy)
{
if(/$href->{"pin_name"}/)
{
if(/LOC\s*=\s*"(\w+)"/gi)
{
$href->{"pin_loc"} = $1;
}
if(/IOSTANDARD\s*=\s*(\w+)/gi)
{
$href->{"pin_iostandard"} = $1;
}
}
}
}
close($fid);
# 输出XDC内容
my $line;
my $pin_name;
for my $href (@pinAy)
{
$pin_name = $href->{"pin_name"};
$pin_name =~ s/</[/;
$pin_name =~ s/>/]/;
$line = sprintf "set_property -dict {PACKAGE_PIN %-4s IOSTANDARD %-8s} [get_ports %-20s]",$href->{"pin_loc"},$href->{"pin_iostandard"},$pin_name;
print $line,"\n";
}
}
ISE路径下的版本
文件是位于Xilinx\ISE\14.7\ISE_DS\EDK\data\xps\scripts路径下的ucf_xdc_convert.pl
#!/usr/bin/perl
#
use strict;
#use warnings;
use Data::Dumper;
my $ucf_file = "$ARGV[0]";
my $line;
my @split_lines;
my $netline;
my $port;
my %port_hash;
my $clock_name;
my $freq;
my $xdcfile = "$ARGV[1]";
open FILEO, ">> $xdcfile" or die "Cannot open $xdcfile for writing : $! \n";
open FILE, $ucf_file or die "Cannot open $ucf_file $! \n";
while(defined($line = <FILE>)) {
chomp $line;
my $port_values;
if($line =~ /^NET\s+\"CLK\"\s+(.*)\s+=\s+(.*);$/) {
$clock_name = $2;
}
if($line =~ /^TIMESPEC\s+TS_(.*)\s+=\s+PERIOD\s+(.*)\s+(\d+.*);$/) {
$freq = $3;
}
next if ($line !~ /^NET/);
next if ($line =~ /^#.*$/);
if ($line =~ /^NET\s+(.*);$/) {
$netline = $1;
chomp($netline);
my $port_name = (split(/\s+/, $netline))[0];
chomp($port_name);
if($netline =~ /^(\w+(\[\d+\])?)?\s+(.*\s+=.*)*$/) {
$port_values = $3;
my @split_pipe = split(/\|/, $port_values);
$port_hash{$port_name} = [ @split_pipe ];
}
}
}
#print Dumper(\%port_hash);
close(FILE);
$freq =~ s/(\d+).*/$1/g;
my $nanosec = 10**6 / $freq ;
foreach my $port_keys (keys %port_hash) {
for my $i ( 0 .. $#{ $port_hash{$port_keys} } ) {
my $each_value = $port_hash{$port_keys}[$i];
(my $var, my $value) = (split/=/, $each_value)[0,1];
$var =~ s/^\s+//;
$var =~ s/\s+$//;
$value =~ s/^\s+//;
$value =~ s/\s+$//;
$value =~ s/"//g;
print FILEO "set_property $var $value [ get_ports $port_keys] \n";
}
}
print FILEO "create_clock -name $clock_name -period $nanosec [get_ports CLK]";
close(FILEO);
产生tcl脚本来定制VIO
缘起
在生成VIO时,需要的VIO端口较多,界面提示需要使用tcl生成该VIO,尝试了一下,果然能够生成
步骤
考虑到我在使用VIO时,多使用固定位宽的输入输出端口,因此写了个脚本,在脚本中能够设置各个不同位宽的输入输出的数目,
use strict;
use warnings;
my $vio_ip_name = "Vivado_VIO";
my $vio_in_num = 8;
my $vio_slv01_out_num = 8;
my $vio_slv04_out_num = 16;
my $vio_slv08_out_num = 64;
my $vio_slv16_out_num = 48;
my $vio_slv32_out_num = 32;
my $vio_out_num = $vio_slv01_out_num + $vio_slv04_out_num + $vio_slv08_out_num + $vio_slv16_out_num + $vio_slv32_out_num;
my $line = "create_ip -name vio -vendor xilinx.com -library ip -module_name $vio_ip_name\n";
$line .= "set_property -dict [list CONFIG.Component_Name {$vio_ip_name} CONFIG.C_NUM_PROBE_IN {$vio_in_num} CONFIG.C_NUM_PROBE_OUT {$vio_out_num} \\\n";
for my $index (0..$vio_in_num-1)
{
$line .= sprintf "CONFIG.C_PROBE_IN%d_WIDTH {1} \\\n",$index;
}
for my $index (0..$vio_out_num-1)
{
if($index<$vio_slv01_out_num)
{
$line .= sprintf "CONFIG.C_PROBE_OUT%d_WIDTH {1} \\\n",$index;
}
elsif($index<($vio_slv01_out_num+$vio_slv04_out_num))
{
$line .= sprintf "CONFIG.C_PROBE_OUT%d_WIDTH {4} \\\n",$index;
}
elsif($index<($vio_slv01_out_num+$vio_slv04_out_num+$vio_slv08_out_num))
{
$line .= sprintf "CONFIG.C_PROBE_OUT%d_WIDTH {8} \\\n",$index;
}
elsif($index<($vio_slv01_out_num+$vio_slv04_out_num+$vio_slv08_out_num+$vio_slv16_out_num))
{
$line .= sprintf "CONFIG.C_PROBE_OUT%d_WIDTH {16} \\\n",$index;
}
elsif($index<($vio_slv01_out_num+$vio_slv04_out_num+$vio_slv08_out_num+$vio_slv16_out_num+$vio_slv32_out_num))
{
$line .= sprintf "CONFIG.C_PROBE_OUT%d_WIDTH {32} \\\n",$index;
}
}
$line .= "] [get_ips $vio_ip_name]";
open my $fid,'>',"gen_vio.tcl";
print $fid $line;
运行效果如下,

整理ISE工程中ipcore_dir下的文件
use strict;
use warnings;
use File::Basename;
use File::Spec::Functions;
use File::Copy::Recursive qw(rmove fmove);
my @ise_ip_list = glob("*.xco"); #获得当前目录下的所有的IP文件名,不含后缀
my $ip_dir_temp = 'ip_dir_temp';
for my $ip_item (@ise_ip_list)
{
my $file_name = basename($ip_item,'.xco'); #获得IP文件的文件名,不含后缀
mkdir $ip_dir_temp; #创建临时文件夹
my @files_dirs = glob("*");
for my $file_dir (@files_dirs)
{
if($file_dir =~ m/$file_name/i)
{
if(-d $file_dir) #如果$file_dir是一个文件夹,则拷贝该文件夹到临时文件夹下的同名文件夹中
{
chdir $ip_dir_temp;
mkdir $file_dir;
chdir "..";
my $ip_sub_dir = catdir($ip_dir_temp,$file_dir);
rmove($file_dir, $ip_sub_dir);
}
else
{
fmove($file_dir,$ip_dir_temp);
}
}
}
rename($ip_dir_temp,$file_name); #重命名临时文件夹
}
整理前后

定时备份vivado工程中的hw文件夹
use strict;
use warnings;
use File::Basename;
use File::Path;
use File::Copy::Recursive qw(dircopy);
use Cwd;
my ($scripts_dir,$vivado_pri_dir,$vivado_pri_path,$vivado_pri_name,$vivado_hw_dir,$vivado_hw_bak_dir);
my ($bak_interval_time,$bak_times);
#进入Vivado工程路径,获取Vivado工程名称
chdir("..");
$vivado_pri_dir = getcwd;
($vivado_pri_path) = glob("*.xpr");
$vivado_pri_name = fileparse($vivado_pri_path,".xpr");
#设置备份的文件夹,设置备份的间隔时间
$vivado_hw_dir = $vivado_pri_name . ".hw";
$vivado_hw_bak_dir = $vivado_pri_name . ".hw.bak";
$bak_interval_time = 5*60;
$bak_times = 0;
#进行周期备份
while(1)
{
if( -e $vivado_hw_bak_dir)
{
rmtree($vivado_hw_bak_dir);
}
dircopy($vivado_hw_dir,$vivado_hw_bak_dir) or die $!;
$bak_times += 1;
print "The perl script has bak the dir $bak_times times \n";
sleep($bak_interval_time);
}
解析7系列FPGA的BIT文件
#usr/bin/perl
use strict;
use warnings;
#====================================================================
# 子程序
#====================================================================
sub subDealBitCfgData
{
my $cfgData = shift;
my ($cfgPacketType,$cfgOpCode,$cfgRegAddr,$cfgWordCount);
my $strLine;
#--------------------------------------------------
my %opcode_hashs = (
0 => "NOP ",
1 => "Read ",
2 => "Write ",
3 => "Reserved",
);
my %regaddr_hashs = (
0 => "Reg_CRC ",
1 => "Reg_FAR ",
2 => "Reg_FDRI ",
3 => "Reg_FDRO ",
4 => "Reg_CMD ",
5 => "Reg_CTL0 ",
6 => "Reg_MASK ",
7 => "Reg_STAT ",
8 => "Reg_LOUT ",
9 => "Reg_COR0 ",
10 => "Reg_MFWR ",
11 => "Reg_CBC ",
12 => "Reg_IDCODE ",
13 => "Reg_AXSS ",
14 => "Reg_COR1 ",
15 => "-----------",
16 => "Reg_WBSTAR ",
17 => "Reg_TIMER ",
18 => "-----------",
19 => "-----------",
20 => "-----------",
21 => "-----------",
22 => "Reg_BOOTSTS",
23 => "-----------",
24 => "Reg_CTL1 ",
25 => "-----------",
26 => "-----------",
27 => "-----------",
28 => "-----------",
29 => "-----------",
30 => "-----------",
31 => "-----------",
);
#--------------------------------------------------
$strLine = "";
$cfgWordCount = 0;
$cfgPacketType = ($cfgData & 0x60000000)>>29;
if($cfgPacketType == 1) #配置类型包1
{
$cfgOpCode = ($cfgData & 0x18000000)>>27;
$cfgRegAddr = ($cfgData & 0x3E000)>>13;
$cfgWordCount = ($cfgData & 0x7FF);
if($cfgOpCode == 0)
{
$strLine = "TYPE1 $opcode_hashs{$cfgOpCode}";
}
else
{
$strLine = "TYPE1 $opcode_hashs{$cfgOpCode} $regaddr_hashs{$cfgRegAddr} $cfgWordCount";
}
}
elsif($cfgPacketType == 2) #配置类型包2
{
$cfgWordCount = ($cfgData & 0x7FFFFFF);
$strLine = "TYPE2 $cfgWordCount";
}
return ($cfgPacketType,$cfgWordCount,$strLine);
}
sub subDealBitFile
{
my $bitFilePath = shift;
my $parserFilePath = shift;
my ($readNum,$buf,$hexStr,$decData);
my ($findSyncWord,$cfgPacketType,$cfgWordCount,$strLine);
my ($headInfoNum,$state,$cfgWordCountGet);
my @headinfo_ay;
open my $BIT_FILE,'<',$bitFilePath;
binmode($BIT_FILE);
open my $PARSER_FILE,'>',$parserFilePath;
$findSyncWord = 0;
$headInfoNum = 0;
$state = 0;
$cfgWordCountGet = 0;
while(1)
{
if($findSyncWord == 0)
{
$readNum = read($BIT_FILE,$buf,1);;
$hexStr = uc(unpack("H*",$buf));
push @headinfo_ay,$hexStr;
$headInfoNum += 1;
if(($headInfoNum>4) &&
($headinfo_ay[-4] eq "AA") && ($headinfo_ay[-3] eq "99") &&
($headinfo_ay[-2] eq "55") && ($headinfo_ay[-1] eq "66"))
{
$findSyncWord = 1; #查找到同步控制字
}
}
else
{
$readNum = read($BIT_FILE,$buf,4);
if($readNum>0)
{
$hexStr = uc(unpack("H*",$buf));
$decData = hex($hexStr);
if($state==0) #获取配置命令
{
($cfgPacketType,$cfgWordCount,$strLine) = subDealBitCfgData($decData);
if($cfgWordCount == 0)
{
$state = 0;
}
else
{
$state = 1;
}
print $PARSER_FILE $hexStr,'---->',$decData,'---->',$strLine,"\n";
}
else #获取配置数据
{
print $PARSER_FILE $hexStr,'---->',$decData,"\n";
$cfgWordCountGet += 1;
if($cfgWordCountGet == $cfgWordCount)
{
$cfgWordCountGet = 0;
$state = 0;
}
else
{
$state = 1;
}
}
}
else
{
last;
}
}
}
}
#====================================================================
# 主函数
#====================================================================
subDealBitFile("xxx.bit","xxx.txt");

解析vhd生成tcl,自动添加观测信号
最近在调试时,觉得在hw的ila观测界面中,根据观测信号的位宽手动添加virtual bus有点麻烦。想到了vivado支持tcl命令,遂尝试一下,使用perl解析vhd文件中的观测信号,自动生成tcl文件。
待解析的VHD文件
测试时,该文件中的待观测信号使用了常用的vhdl转换函数
test ( 15 downto 0) <= sig_0;
test ( 30 downto 16) <= sig_1( 14 downto 1);
test (46 downto 31) <= unsigned(sig_3);
test (75 downto 60) <= CONV_STD_LOGIC_VECTOR(sig6,16);
test (95 downto 80) <= SXT(sig4,16);
test (175 downto 160) <= EXT(sig5,16);
test (205 downto 190) <= STD_LOGIC_VECTOR(sig89);
test (90) <= sig_7;
生成tcl
#!usr/bin/perl
use strict;
use warnings;
#----------------------------------------------------------
#从VHDL文件中获得调试信号的信息
#----------------------------------------------------------
sub subGetDebugSigInfo
{
my $vhd_file = shift;
my @vhd_convfun_A_lists = (
"sxt",
"ext",
"conv_std_logic_vector",
);
my @vhd_convfun_B_lists = (
"unsigned",
"signed",
"std_logic_vector",
);
my %debugbg_sig_hash = ();
open my $vhd_fid,'<',$vhd_file;
while(my $line = <$vhd_fid>)
{
chomp $line;
next if $line =~ m/^\s*$/; # 空白行跳过
#--------------------------------------------
#预处理
#--------------------------------------------
$line =~ s/\s*downto\s*/`downto`/gi; # 将downto前后有用的空白字符替换为`
$line =~ s/\s+//g; # 移除无用的空白字符
$line =~ s/`/ /g; # 将`替换为空格
foreach my $conv_fun (@vhd_convfun_A_lists) # 移除转换函数字符
{
$line =~ s/$conv_fun[(](.*?),.*?[)]/$1/gi;
}
foreach my $conv_fun (@vhd_convfun_B_lists) # 移除转换函数字符
{
$line =~ s/$conv_fun[(](.*?)[)]/$1/gi;
}
if($line =~ /downto.*?<=/i)
{
if($line =~ /[(](\d+)\sdownto\s(\d+)[)]<=([\w]+)/)
{
$debugbg_sig_hash{$3} = [($1,$2)];
}
}
else
{
if($line =~ /[(]([\d]+)[)].*?<=([\w]+)/)
{
$debugbg_sig_hash{$2} = [($1,$1)];
}
}
}
return %debugbg_sig_hash;
}
#----------------------------------------------------------
# TCL命令封装
#----------------------------------------------------------
#设置当前wcfg
sub subVtclSetCurWcfg
{
my $cur_wcfg = shift;
my $tcl_line = "";
die "Must use wcfg file" unless $cur_wcfg =~ /wcfg/; #wcfg文件后缀检查
$tcl_line = "current_wave_config ".$cur_wcfg."\n";
return $tcl_line;
}
#设置当前ILA
sub subVtclSetCurIla
{
my $cur_ila = shift;
my $tcl_line = "";
$tcl_line = "current_hw_ila ".$cur_ila."\n";
return $tcl_line;
}
#生成虚拟总线
sub subVtclAddVirtualBus
{
my $lia_bus_name = shift;
my $vbus_nmae = shift;
my $high_pos = shift;
my $low_pos = shift;
my $tcl_line = "";
my @index_ay = reverse ($low_pos..$high_pos);
my $index_ay_len = @index_ay;
if($index_ay_len == 1)
{
$tcl_line .= "add_wave -name ".$vbus_nmae." ".$lia_bus_name."[$index_ay[0]]\n";
}
else
{
$tcl_line .= "add_wave_virtual_bus ".$vbus_nmae."\n";
foreach(@index_ay)
{
$tcl_line .= "add_wave -into ".$vbus_nmae." ".$lia_bus_name."[$_]\n";
}
}
return $tcl_line;
}
#----------------------------------------------------------
#生成TCL命令
#----------------------------------------------------------
#生成虚拟总线
my $cur_ila = "hw_ila_1";
my $cur_wcfg = "hw_ila_data_1.wcfg";
my $lia_bus_name = "ila_dbg_bus";
my $vhd_file = "test.vhd";
my $tcl_line = "";
my %debugbg_sig_hash = subGetDebugSigInfo($vhd_file);
$tcl_line .= subVtclSetCurIla($cur_ila);
$tcl_line .= subVtclSetCurWcfg($cur_wcfg);
foreach my $sig_name (keys %debugbg_sig_hash)
{
my $vbus_name = $sig_name;
my $high_pos = $debugbg_sig_hash{$sig_name}[0];
my $low_pos = $debugbg_sig_hash{$sig_name}[1];
$tcl_line .= subVtclAddVirtualBus($lia_bus_name,$vbus_name,$high_pos,$low_pos);
}
print $tcl_line;
部分运行结果如下所示

20200421
VB.NET版本
Imports System.IO
Imports System.Text.RegularExpressions
Module Module1
Sub Main()
Dim cur_ila As String
Dim cur_wcfg As String
Dim lia_bus_name As String
Dim vhd_file As String
Dim tcl_line As String
Dim debugbg_sig_hash As New Hashtable
cur_ila = "hw_ila_1"
cur_wcfg = "hw_ila_data_1.wcfg"
lia_bus_name = "ila_dbg_bus"
vhd_file = "test.vhd"
tcl_line = ""
''获取调试信号的信息
debugbg_sig_hash = GetDebugSigInfo(vhd_file)
''生成tcl语句
tcl_line &= VtclSetCurIla(cur_ila)
tcl_line &= VtclSetCurWcfg(cur_wcfg)
Dim keys As ICollection = debugbg_sig_hash.Keys
Dim key As String
Dim vbus_name As String
Dim high_pos As UShort
Dim low_pos As UShort
For Each key In keys
vbus_name = key
high_pos = debugbg_sig_hash(key)(0)
low_pos = debugbg_sig_hash(key)(1)
tcl_line &= VtclAddVirtualBus(lia_bus_name, vbus_name, high_pos, low_pos)
Next key
''输出
Console.WriteLine(tcl_line)
Console.ReadKey()
End Sub
''获取调试信号的索引信息
Private Function GetDebugSigInfo(ByVal vhd_file As String) As Hashtable
Dim SR As New StreamReader(vhd_file)
Dim lines As String
Dim re As Regex
Dim mc As MatchCollection
Dim debugbg_sig_hash As New Hashtable
lines = SR.ReadLine
While Not (lines Is Nothing)
''替换换行符
lines = lines.Replace(Environment.NewLine, "")
''跳过空白行
re = New Regex("^\s*$", RegexOptions.None)
mc = re.Matches(lines)
If mc.Count > 0 Then
lines = SR.ReadLine
Continue While
End If
''将downto前后有用的空白字符替换为`
re = New Regex("\s*downto\s*", RegexOptions.IgnoreCase)
lines = re.Replace(lines, "`downto`")
''移除无用的空白字符
re = New Regex("\s+", RegexOptions.IgnoreCase)
lines = re.Replace(lines, "")
''将`替换为空格
re = New Regex("`", RegexOptions.IgnoreCase)
lines = re.Replace(lines, " ")
''处理VHDL中的一些转换函数
Dim index As Byte
Dim str As String
Dim vhd_convfun_A_lists As String() = {"sxt", "ext", "conv_std_logic_vector"}
Dim vhd_convfun_B_lists As String() = {"unsigned", "signed", "std_logic_vector"}
For index = 0 To 2
str = vhd_convfun_A_lists(index) & "\(\s*(\w+)\s*,\s*\d+\)"
re = New Regex(str, RegexOptions.IgnoreCase)
mc = re.Matches(lines)
If mc.Count > 0 Then
For Each m As Match In mc
lines = re.Replace(lines, m.Groups.Item(1).Value)
Next
End If
Next
For index = 0 To 2
str = vhd_convfun_B_lists(index) & "\(\s*(\w+)\s*\)"
re = New Regex(str, RegexOptions.IgnoreCase)
mc = re.Matches(lines)
If mc.Count > 0 Then
For Each m As Match In mc
lines = re.Replace(lines, m.Groups.Item(1).Value)
Next
End If
Next
''提取信号名和信号索引号
re = New Regex("\((\w+)\s*downto\s*(\w+)\s*\)<=(\w+)", RegexOptions.IgnoreCase)
mc = re.Matches(lines)
If mc.Count > 0 Then
For Each m As Match In mc
Dim debugbg_sig_index(1) As UShort
debugbg_sig_index(0) = m.Groups.Item(1).Value
debugbg_sig_index(1) = m.Groups.Item(2).Value
debugbg_sig_hash.Add(m.Groups.Item(3).Value, debugbg_sig_index)
Next
End If
re = New Regex("\((\w+)\)<=(\w+)", RegexOptions.IgnoreCase)
mc = re.Matches(lines)
If mc.Count > 0 Then
For Each m As Match In mc
Dim debugbg_sig_index(1) As UShort
debugbg_sig_index(0) = m.Groups.Item(1).Value
debugbg_sig_index(1) = m.Groups.Item(1).Value
debugbg_sig_hash.Add(m.Groups.Item(2).Value, debugbg_sig_index)
Next
End If
''---------------------------------------------
'Console.WriteLine(lines)
lines = SR.ReadLine
End While
''返回
Return debugbg_sig_hash
End Function
''设置当前wcfg
Private Function VtclSetCurWcfg(ByVal cur_wcfg As String) As String
Dim tcl_line As String
tcl_line = ""
If InStr(cur_wcfg, ".wcfg") Then
tcl_line = "current_wave_config " & cur_wcfg & Environment.NewLine
Else
Console.WriteLine("Must use wcfg file")
End If
Return tcl_line
End Function
''设置当前ILA
Private Function VtclSetCurIla(ByVal cur_ila As String) As String
Dim tcl_line As String
tcl_line = ""
tcl_line = "current_hw_ila " & cur_ila & Environment.NewLine
Return tcl_line
End Function
''生成虚拟总线
Private Function VtclAddVirtualBus(ByVal lia_bus_name As String, ByVal vbus_name As String, ByVal high_pos As UShort, ByVal low_pos As UShort) As String
Dim tcl_line As String
Dim m As Short
tcl_line = ""
If (high_pos = low_pos) Then
tcl_line &= "add_wave -name " & vbus_name & " " & lia_bus_name & "[" & high_pos & "]" & Environment.NewLine
ElseIf (high_pos > low_pos) Then
tcl_line &= "add_wave_virtual_bus " & vbus_name & Environment.NewLine
For m = high_pos To low_pos Step -1
tcl_line &= "add_wave -into " & vbus_name & " " & lia_bus_name & "[" & m & "]" & Environment.NewLine
Next
End If
Return tcl_line
End Function
End Module
辅助编辑CPJ文件
#!usr/bin/perl
use strict;
use warnings;
use Encode;
#****************************************************************************
#子程序声明
#****************************************************************************
sub subGetIlaBusCount;
sub subCpjTextGen;
sub subGetDebugSigInfo;
sub subGetDebugBusName;
#****************************************************************************
#主程序:生成TCL命令
#****************************************************************************
#参数设置
my $ila_index = 3;
my $bus_prefix = "02.";
#获取CPJ文件、VHDL文件信息
my @cpj_file_lists = glob("*.cpj");
my $cpj_file_num = @cpj_file_lists;
if($cpj_file_num>1)
{
print '-'x20,"\n";
print encode("gbk",decode("utf-8","当前文件夹下的CPJ文件数目大于1,请只保留需要的CPJ文件!!!\n"));
}
my @vhd_file_lists = glob("*.vhd");
my $vhd_file_num = @vhd_file_lists;
if($vhd_file_num>1)
{
print '-'x20,"\n";
print encode("gbk",decode("utf-8","当前文件夹下的VHDL文件数目大于1,请确保认这些文件对应的观测核是同一个!!!\n"));
}
# 生成CPJ调试文本
for my $cpj_file (@cpj_file_lists)
{
my $port_start = subGetIlaBusCount($cpj_file,$ila_index);
my $cpj_line = "";
for my $vhd_file (@vhd_file_lists)
{
my $dbgBusName = subGetDebugBusName($vhd_file);
my %debug_sig_hash = subGetDebugSigInfo($vhd_file);
my $cur_index = 0;
#生成CPJ文件的部分文本
foreach my $sig_name (keys %debug_sig_hash)
{
my $bus_name = $bus_prefix.$sig_name;
my $high_pos = $debug_sig_hash{$sig_name}[0];
my $low_pos = $debug_sig_hash{$sig_name}[1];
$cpj_line .= subCpjTextGen($ila_index,$port_start + $cur_index,$bus_name,$high_pos,$low_pos);
$cur_index++;
}
my $cpjTextName = $dbgBusName."_UserCpjText.txt";
open my $fid,">",$cpjTextName;
print $fid $cpj_line;
close($fid);
print '-'x20,"\n";
print encode("gbk",decode("utf-8","处理完成文件$vhd_file\n"));
print encode("gbk",decode("utf-8","注意粘贴到CPJ文件中时要修改unit.0.$ila_index.port.-1.buscount\n"));
}
}
print '-'x20,"\n";
##============================================================================
##子程序:从VHDL文件中获得观测信号的总名称
##============================================================================
sub subGetDebugBusName
{
my $vhd_file = shift;
open my $vhd_fid,'<',$vhd_file;
while(my $line = <$vhd_fid>)
{
#------------------------------
#预处理
#------------------------------
chomp $line;
next if $line =~ m/^\s*$/; #跳过空白行
if($line =~ /\s*(\w+)\s*\(/i)
{
return $1;
}
}
}
#============================================================================
#子程序:从VHDL文件中获得调试信号的信息
#============================================================================
sub subGetDebugSigInfo
{
my $vhd_file = shift;
my @vhd_conv_A_lists = (
"sxt",
"ext",
"conv_std_logic_vector",
);
my @vhd_conv_B_lists = (
"unsigned",
"signed",
"std_logic_vector",
);
my %debug_sig_hash = ();
open my $vhd_fid,'<',$vhd_file;
while(my $line = <$vhd_fid>)
{
#------------------------------
#预处理
#------------------------------
chomp $line;
next if $line =~ m/^\s*$/; #跳过空白行
next if $line =~ m/others/; #跳过包含others的行
$line =~ s/\s*downto\s*/`downto`/gi; #将downto前后有用的空白字符用`代替
$line =~ s/\s+//g; #移除无用的空白字符
$line =~ s/`/ /g; #将`替换为空格
$line =~ s/'[01]'//g; #将常量'0'/'1'替换掉
$line =~ s/[x]?"[0-9a-f]+"//gi; #将常量如"00"/X"01"/x"AF"替换掉
foreach my $conv_fun (@vhd_conv_A_lists)
{
$line =~ s/$conv_fun[(](.*?),.*?[)]/$1/gi;
}
foreach my $conv_fun (@vhd_conv_B_lists)
{
$line =~ s/$conv_fun[(](.*?)[)]/$1/gi;
}
# print $line,"\n";
#------------------------------
#提取信号名/信号位宽
#------------------------------
if($line =~ /downto.*?<=/i)
{
if($line =~ /[(](\d+)\sdownto\s(\d+)[)]<=.*?([\w]+)/)
{
$debug_sig_hash{$3} = [($1,$2)];
}
}
else
{
if($line =~ /[(]([\d]+)[)].*?<=.*?([\w]+)/)
{
$debug_sig_hash{$2} = [($1,$1)];
}
}
}
# foreach my $sig_name (keys %debug_sig_hash)
# {
# my $vbus_name = $sig_name;
# my $high_pos = $debug_sig_hash{$sig_name}[0];
# my $low_pos = $debug_sig_hash{$sig_name}[1];
# print $vbus_name,' 'x8,$high_pos,' 'x8,$low_pos."\n";
# }
return %debug_sig_hash;
}
#============================================================================
#子程序:从CPJ文件中获得某个ILA端口已有的bus数目
#============================================================================
sub subGetIlaBusCount
{
my $cpj_file = shift;
my $ila_index = shift;
open my $cpj_fid,'<',$cpj_file;
while(my $line = <$cpj_fid>)
{
#------------------------------
#预处理
#------------------------------
chomp $line;
if($line =~ /unit.0.$ila_index.port.-1.buscount=(\d+)/i)
{
return $1;
}
}
}
#============================================================================
#子程序:生成CPJ文本信息
#============================================================================
sub subCpjTextGen
{
my $ila_index = shift;
my $port_offset = shift;
my $bus_name = shift;
my $high_pos = shift;
my $low_pos = shift;
my $cpj_line = "";
my @index_ay = ($low_pos..$high_pos);
my $index_ay_len = @index_ay;
my $port_info = "unit.0.".$ila_index.".port.-1.b.".$port_offset.".";
$cpj_line .= $port_info."alias=".$bus_name."\n";
$cpj_line .= $port_info."channellist=";
if($index_ay_len == 1)
{
$cpj_line .= "$index_ay[0]";
}
else
{
foreach(@index_ay)
{
$cpj_line .= "$_ ";
}
}
$cpj_line .= "\n";
$cpj_line .= $port_info."color=java.awt.Color[r\=0,g\=0,b\=124]\n";
$cpj_line .= $port_info."name=DataPort\n";
$cpj_line .= $port_info."orderindex=-1\n";
$cpj_line .= $port_info."radix=Signed\n";
$cpj_line .= $port_info."signedOffset=0.0\n";
$cpj_line .= $port_info."signedPrecision=0\n";
$cpj_line .= $port_info."signedScaleFactor=1.0\n";
$cpj_line .= $port_info."tokencount=0\n";
$cpj_line .= $port_info."unsignedOffset=0.0\n";
$cpj_line .= $port_info."unsignedPrecision=0\n";
$cpj_line .= $port_info."unsignedScaleFactor=1.0\n";
$cpj_line .= $port_info."visible=1\n";
return $cpj_line;
}
使用这段脚本时,要将脚本生成的文本贴到cpj文件后,要注意将buscount的值更新一下
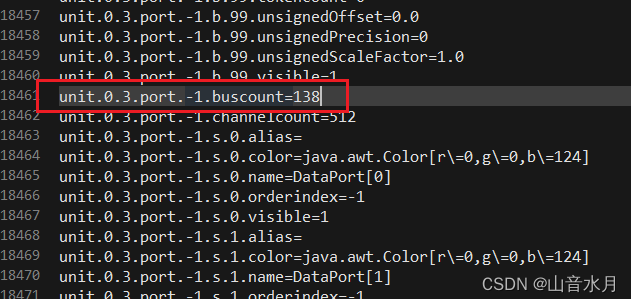
生成BlackBox的配置文件
use strict;
use warnings;
use File::Basename;
#----------------------------------------------------------
# 主程序
#----------------------------------------------------------
my $file = shift @ARGV;;
subGenBlackBoxConfig($file);
subCreateMask($file);
#----------------------------------------------------------
# 解析vhdl文件, 获取参数信息、端口信息
#----------------------------------------------------------
sub subGetVhdlFileInfo
{
my $file_path = shift;
my $debug_en = shift;
my $port_signed = 0;
local $/ = undef; #分隔符默认是\n,此处设置为undef,是想把整个段落作为一行
open my $fid,"<",$file_path;
my $vhd_file_lines = ""; #文件内容清理后的整个段落,赋值进一个标量
while(<$fid>)
{
s/--.*?\n/\n/g; #删除--注释部分
s/\s+/ /g; #替换多个空白符为1个空格
s/\n+\s*\n+/\n/g; #删除多个空行
$vhd_file_lines = $_;
}
close $fid;
#提取出entity声明部分,避免模块中component声明部分引入的generic和port
if($vhd_file_lines =~ m/(.*)architecture/gsi)
{
$vhd_file_lines = $1;
}
# 生成generic参数信息
my @parameterInfoAy = ();
if($vhd_file_lines =~ m/generic\s*\(([\w\s;:=\+\-]+)\)/gsi)
{
my $parameter_line = $1;
if($parameter_line =~ m/;/)
{
for (split(";",$parameter_line))
{
if(m/(\w+)\s*:\s*(\w+)\s*:=\s*([\w\s\+\-]+)/)
{
push @parameterInfoAy, {
parameter_name => $1,
parameter_type => $2,
parameter_value => $3,
};
}
}
}
else
{
if($parameter_line =~ m/(\w+)\s*:\s*(\w+)\s*:=\s*(\w+)/)
{
push @parameterInfoAy, {
parameter_name => $1,
parameter_type => $2,
parameter_value => $3,
};
}
}
}
# 生成port端口信息
my @portInfoAy = ();
if($vhd_file_lines =~ m/port\s*\(([\s\w:;\(\)-]+)\);/gsi)
{
my $port_line = $1;
for (split(";",$port_line))
{
if(m/signed/)
{
$port_signed = 1;
}
else
{
$port_signed = 0;
}
if(m/(\w+)\s*:\s*(\w+)\s+([\w\-+\s]+\({0,1}[\w\-+\s]+\){0,1})/)
{
push @portInfoAy, {
port_name => $1,
port_dir => $2,
port_type => $3,
port_signed => $port_signed
};
}
}
}
if($debug_en==1)
{
for my $item (@parameterInfoAy)
{
print $item->{parameter_name}," ";
print $item->{parameter_type}," ";
print $item->{parameter_value}," ";
print "---\n"
}
for my $item (@portInfoAy)
{
print $item->{port_name}," ";
print $item->{port_dir}," ";
print $item->{port_type}," ";
print $item->{port_signed}," ";
print "***\n"
}
}
return (\@parameterInfoAy,\@portInfoAy);
}
#----------------------------------------------------------
# 解析verilog文件, 获取参数信息、端口信息
#----------------------------------------------------------
sub subGetVerilogFileInfo
{
my $file_path = shift;
my $debug_en = shift;
my $port_signed = 0;
local $/ = undef; #分隔符默认是\n,此处设置为undef,是想把整个段落作为一行
open my $fid,"<",$file_path;
my $verilog_file_lines = ""; #文件内容清理后的整个段落,赋值进一个标量
while(<$fid>)
{
s/\/\/.*?\n/\n/g; #删除//注释部分
s/\s+/ /g; #删除多个空白符
s/\n+\s*\n+/\n/g; #删除多个空行
$verilog_file_lines = $_;
}
$verilog_file_lines =~ s/\/\*.*?\*\///g; #删除/**/注释部分
close $fid;
#提取出module声明部分
if($verilog_file_lines =~ m/(module\s*.*?);/gsi)
{
$verilog_file_lines = $1;
}
# print $verilog_file_lines;
# 生成generic参数信息
my @parameterInfoAy = ();
my @portInfoAy = ();
if($verilog_file_lines =~ m/#\s*\((.*?)\)/gsi) # 模块有parameter参数
{
my $parameter_line = $1;
if($parameter_line =~ m/,/) # 存在多个参数
{
for (split(",",$parameter_line))
{
if(m/parameter\s*(\w+)\s*=\s*([\w\"]+)/)
{
push @parameterInfoAy, {
parameter_name => $1,
parameter_type => "",
parameter_value => $2,
};
}
}
}
else # 仅仅存在一个参数
{
if(m/parameter\s*(\w+)\s*=\s*([\w\"]+)/)
{
push @parameterInfoAy, {
parameter_name => $1,
parameter_type => "",
parameter_value => $2,
};
}
}
# 生成port端口信息
if($verilog_file_lines =~ m/module\s*\w+\s*#\s*\(.*\)\s*\(([\s\w:,[\]-]+)\)/)
{
my $port_line = $1;
for (split(",",$port_line))
{
if(m/signed/)
{
$port_signed = 1;
}
else
{
$port_signed = 0;
}
s/signed//g; #删除signed
s/unsigned//g; #删除unsigned
if(m/\[/) #端口是std_logic_evctor
{
if(m/input\s+\[\s*([\w\-\+]+)\s*:\s*([\w\-\+]+)\s*]\s*(\w+)/)
{
push @portInfoAy, {
port_name => $3,
port_dir => "in",
port_type => "std_logic_vector($1 downto $2)",
port_signed => $port_signed,
};
}
elsif(m/output\s+\[\s*([\w\-\+]+)\s*:\s*([\w\-\+]+)\s*]\s*(\w+)/)
{
push @portInfoAy, {
port_name => $3,
port_dir => "out",
port_type => "std_logic_vector($1 downto $2)",
port_signed => $port_signed,
};
}
}
else #端口是std_logic
{
if(m/input\s*(\w+)/)
{
push @portInfoAy, {
port_name => $1,
port_dir => "in",
port_type => "std_logic",
port_signed => $port_signed,
};
}
elsif(m/output\s*(\w+)/)
{
push @portInfoAy, {
port_name => $1,
port_dir => "out",
port_type => "std_logic",
port_signed => $port_signed,
};
}
}
}
}
}
else # 模块没有parameter参数
{
# 生成port端口信息
if($verilog_file_lines =~ m/module\s+\w+\s*\((.*)\)/)
{
my $port_line = $1;
for (split(",",$port_line))
{
if(m/signed/)
{
$port_signed = 1;
}
else
{
$port_signed = 0;
}
s/signed//g; #删除signed
s/unsigned//g; #删除unsigned
if(m/\[/) #端口是std_logic_evctor
{
if(m/input\s+\[\s*([\w\-\+]+)\s*:\s*([\w\-\+]+)\s*]\s*(\w+)/)
{
push @portInfoAy, {
port_name => $3,
port_dir => "in",
port_type => "std_logic_vector($1 downto $2)",
port_signed => $port_signed,
};
}
elsif(m/output\s+\[\s*([\w\-\+]+)\s*:\s*([\w\-\+]+)\s*]\s*(\w+)/)
{
push @portInfoAy, {
port_name => $3,
port_dir => "out",
port_type => "std_logic_vector($1 downto $2)",
port_signed => $port_signed,
};
}
}
else #端口是std_logic
{
if(m/input\s*(\w+)/)
{
push @portInfoAy, {
port_name => $1,
port_dir => "in",
port_type => "std_logic",
port_signed => $port_signed,
};
}
elsif(m/output\s*(\w+)/)
{
push @portInfoAy, {
port_name => $1,
port_dir => "out",
port_type => "std_logic",
port_signed => $port_signed,
};
}
}
}
}
}
if($debug_en==1)
{
for my $item (@parameterInfoAy)
{
print $item->{parameter_name}," ";
print $item->{parameter_type}," ";
print $item->{parameter_value}," ";
print "---\n"
}
for my $item (@portInfoAy)
{
print $item->{port_name}," ";
print $item->{port_dir}," ";
print $item->{port_type}," ";
print $item->{port_signed}," ";
print "***\n"
}
}
return (\@parameterInfoAy,\@portInfoAy);
}
#----------------------------------------------------------
# 生成HDL黑盒子的配置文件
#----------------------------------------------------------
sub subGenBlackBoxConfig
{
my $file = shift;
my $parameterInfoAy_ref;
my $portInfoAy_ref;
my $debug_en = 0;
my ($fname, $fpath, $fext) = fileparse($file,(".vhd",".vhdl",".v"));
my $file_lines = "";
$file_lines .= "%------------------------------------------------------------------------\n";
$file_lines .= "%该文件由Perl自动生成,必需人工确认后方可使用!\n";
$file_lines .= "%------------------------------------------------------------------------\n";
$file_lines .= "function ${fname}_config(this_block)\n\n";
$file_lines .= " %------------------------------------------------------------------------\n";
$file_lines .= " % 设置模块基本信息\n";
$file_lines .= " %------------------------------------------------------------------------\n";
if($fext =~ m/vhd/)
{
$file_lines .= " this_block.setTopLevelLanguage('VHDL');\n";
($parameterInfoAy_ref,$portInfoAy_ref) = subGetVhdlFileInfo($file,$debug_en);
}
else
{
print "警告:不支持Verilog_1995风格的Verilog文件!\n";
$file_lines .= " this_block.setTopLevelLanguage('Verilog');\n";
($parameterInfoAy_ref,$portInfoAy_ref) = subGetVerilogFileInfo($file,$debug_en);
}
$file_lines .= " this_block.setEntityName('$fname');\n\n";
$file_lines .= " this_block.tagAsCombinational;\n";
$file_lines .= " %------------------------------------------------------------------------\n";
$file_lines .= " % 设置输入输出端口\n";
$file_lines .= " %------------------------------------------------------------------------\n";
for my $item (@$portInfoAy_ref)
{
# 输入端口
if($item->{port_dir} =~ m/in/)
{
next if($item->{port_name} =~ m/clk/i);
next if($item->{port_name} =~ m/ce/i);
$file_lines .= " this_block.addSimulinkInport('$item->{port_name}');\n";
}
elsif($item->{port_dir} =~ m/out/)
{
$file_lines .= " this_block.addSimulinkOutport('$item->{port_name}');\n";
}
}
$file_lines .= "\n";
$file_lines .= " %------------------------------------------------------------------------\n";
$file_lines .= " % 获取generic参数,并根据generic参数设置端口信息\n";
$file_lines .= " %------------------------------------------------------------------------\n";
$file_lines .= " MaskedSubSystemName = get_param(this_block.blockName,'Parent');\n";
for my $item (@$parameterInfoAy_ref)
{
$file_lines .= " $item->{parameter_name} = str2num(get_param(MaskedSubSystemName,'$item->{parameter_name}'));\n";
}
$file_lines .= "\n";
for my $item (@$parameterInfoAy_ref)
{
$file_lines .= " this_block.addGeneric('$item->{parameter_name}', '$item->{parameter_type}', num2str($item->{parameter_name}));\n";
}
$file_lines .= "\n";
$file_lines .= " %端口类型必需人工设置\n";
for my $item (@$portInfoAy_ref)
{
next if($item->{port_name} =~ m/clk/i);
next if($item->{port_name} =~ m/ce/i);
if($item->{port_signed}==1)
{
$file_lines .= " this_block.port('$item->{port_name}').setType(['Fix_' num2str(16) '_0']);\n";
}
else
{
$file_lines .= " this_block.port('$item->{port_name}').setType(['UFix_' num2str(16) '_0']);\n";
}
}
$file_lines .= "\n";
$file_lines .= "
%------------------------------------------------------------------------
% 端口位宽必需人工检查(下面被注释掉的语句供参考修改使用)
% HDL文件路径必需人工设置
%------------------------------------------------------------------------
if (this_block.inputTypesKnown)
%if (this_block.port('real_in').width ~= IDATA_WIDTH)
% this_block.setError('Input data type for port \"real_in\" must have correct width.');
%end
%
%if (this_block.port('bypass_en').width ~= 1)
% this_block.setError('Input data type for port \"bypass_en\" must have width=1.');
%end
%this_block.port('bypass_en').useHDLVector(false);
end % if(inputTypesKnown)
if (this_block.inputRatesKnown)
setup_as_single_rate(this_block,'clk','ce')
end % if(inputRatesKnown)
uniqueInputRates = unique(this_block.getInputRates);
% Add addtional source files as needed.
% |-------------
% | Add files in the order in which they should be compiled.
% | If two files \"a.vhd\" and \"b.vhd\" contain the entities
% | entity_a and entity_b, and entity_a contains a
% | component of type entity_b, the correct sequence of
% | addFile() calls would be:
% | this_block.addFile('b.vhd');
% | this_block.addFile('a.vhd');
% |-------------
this_block.addFile('$fpath$fname$fext');
return;
%------------------------------------------------------------
function setup_as_single_rate(block,clkname,cename)
inputRates = block.inputRates;
uniqueInputRates = unique(inputRates);
if (length(uniqueInputRates)==1 & uniqueInputRates(1)==Inf)
block.addError('The inputs to this block cannot all be constant.');
return;
end
if (uniqueInputRates(end) == Inf)
hasConstantInput = true;
uniqueInputRates = uniqueInputRates(1:end-1);
end
if (length(uniqueInputRates) ~= 1)
block.addError('The inputs to this block must run at a single rate.');
return;
end
theInputRate = uniqueInputRates(1);
for i = 1:block.numSimulinkOutports
block.outport(i).setRate(theInputRate);
end
block.addClkCEPair(clkname,cename,theInputRate);
return;
";
open my $fid,'>',"${fname}_config.m";
print $fid $file_lines;
close $fid;
}
#----------------------------------------------------------
# 生成HDL黑盒子的配置文件
#----------------------------------------------------------
sub subCreateMask
{
my $file = shift;
my $parameterInfoAy_ref;
my $portInfoAy_ref;
my $debug_en = 0;
my ($fname, $fpath, $fext) = fileparse($file,(".vhd",".vhdl",".v"));
if($fext =~ m/vhd/)
{
($parameterInfoAy_ref,$portInfoAy_ref) = subGetVhdlFileInfo($file,$debug_en);
}
else
{
($parameterInfoAy_ref,$portInfoAy_ref) = subGetVerilogFileInfo($file,$debug_en);
}
my $file_lines = "";
$file_lines .= "block_name = 'untitled/Subsystem';\n";
$file_lines .= "p = Simulink.Mask.create(block_name);\n";
for my $item (@$parameterInfoAy_ref)
{
$file_lines .= "p.addParameter('Type','edit', 'Prompt','$item->{parameter_name}','Name','$item->{parameter_name}','Value',num2str($item->{parameter_value}));\n";
}
$file_lines .= "p.addParameter('Type','edit', 'Prompt','模块上显示自定义图标(0-不显示;1-显示)','Name','EN_SHOW_DISP','Value',num2str(0));\n";
open my $fid,'>',"${fname}_create_mask.m";
print $fid $file_lines;
close $fid;
}
clc;clear all;close all;
[filename, pathname, filterindex] = uigetfile({ '*.vhd','VHDL Files(*.vhd)';'*.v','Verilog2001 Files(*.v)'}, ...
'打开HDL文件', ...
'MultiSelect', 'off');
filepath = strcat(pathname,filename);
perl('gen_blackbox.pl',filepath);
移除文件中的注释
use strict;
use warnings;
use Regexp::Common qw /comment/;
#---------------------------------------
# Language comment
#---------------------------------------
# C /**/
# C++ // /**/
# CLU %
# Ada --
# ABC \
#---------------------------------------
my $filepath = "xxx.v";
#my $filepath = "xxx.vhd";
my $lang = "v";
open my $fid,'<',$filepath;
#为了处理多行注释,将文件中的多行合并起来再统一处理
my $line = "";
while (<$fid>)
{
$line.=$_;
}
close $fid;
$line =~ s/$RE{comment}{'C++'}//gs if $lang eq 'v';
$line =~ s/$RE{comment}{Ada}//gs if $lang eq 'vhd';
print $line;
使用Inline模块
use strict;
use warnings;
use Inline 'C';
print "9 + 16 = ", add(9, 16), "\n";
print "9 - 16 = ", subtract(9, 16), "\n";
greet('Ingy');
greet(42);
__END__
__C__
int add(int x, int y) {
return x + y;
}
int subtract(int x, int y) {
return x - y;
}
void greet(SV* sv_name) {
printf("Hello %s!\n", SvPV(sv_name, PL_na));
}
使用here文档格式输出多行文本
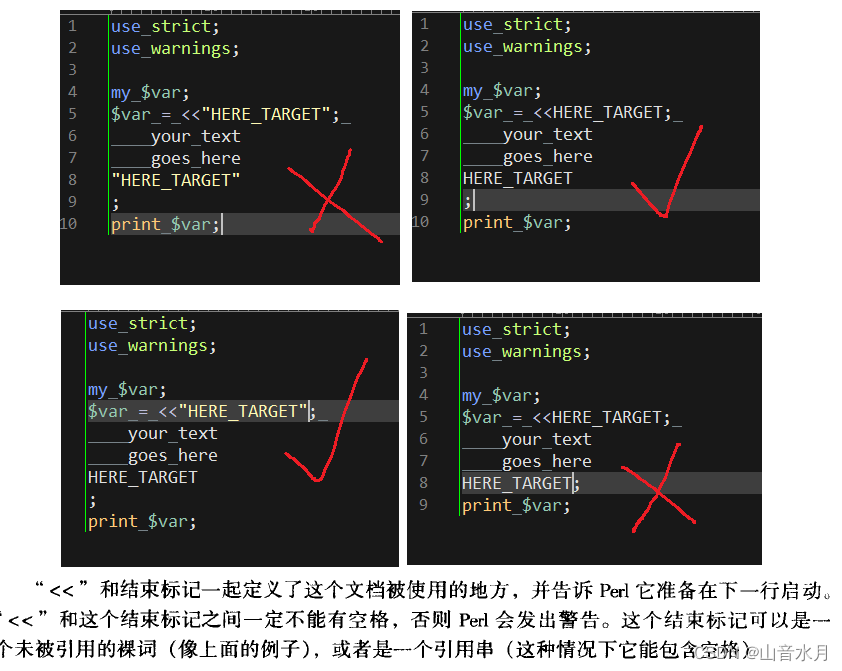
调用cmd/exe
调用cmd命令
注意,system的调用是阻塞的,因此在最后加上了&
use strict;
use warnings;
use File::Path qw(remove_tree);
#----------------------------------------------------------
# 子函数
#----------------------------------------------------------
sub subGenBatFile
{
my $fileLine = "";
my $ise_path = shift;
my $ngc_file = shift;
$fileLine .= "\@echo off\n";
$fileLine .= "cd /d $ise_path\n";
$fileLine .= "call settings32.bat\n";
$fileLine .= "cd /d %~dp0\n";
$fileLine .= "set fileName=$ngc_file\n";
$fileLine .= "netgen -ofmt vhdl -sim ${ngc_file}.ngc -w ${ngc_file}_sim.vhd\n";
$fileLine .= "\@echo on\n";
open my $w_fid,'>',"temp.bat";
print $w_fid $fileLine;
}
#----------------------------------------------------------
# 主函数
#----------------------------------------------------------
my $fid_cfg;
my $ise_path = "";
my $ngc_file = "";
my $line_cnt = 0;
my $cmd_str = "";
open $fid_cfg,'<','cfg_data.txt';
while(<$fid_cfg>)
{
chomp;
next if /^\s+$/;
if (0 == $line_cnt)
{
$ise_path = $_;
$line_cnt++;
}
elsif (1 == $line_cnt)
{
$ngc_file = $_;
$line_cnt++;
}
}
subGenBatFile($ise_path,$ngc_file);
system "temp.bat > temp.log &";
remove_tree('./_xmsgs/');
unlink "temp.bat" if -e "temp.bat";
unlink "temp.log" if -e "temp.log";
unlink "${ngc_file}_sim.nlf" if -e "${ngc_file}_sim.nlf";
运行cmd命令时,捕获输出
use Capture::Tiny 'capture';
my ($output, $error_output, $exit_code) = capture {
system("python 00_tools/get_ver_parameters.py $utf8_path");
};
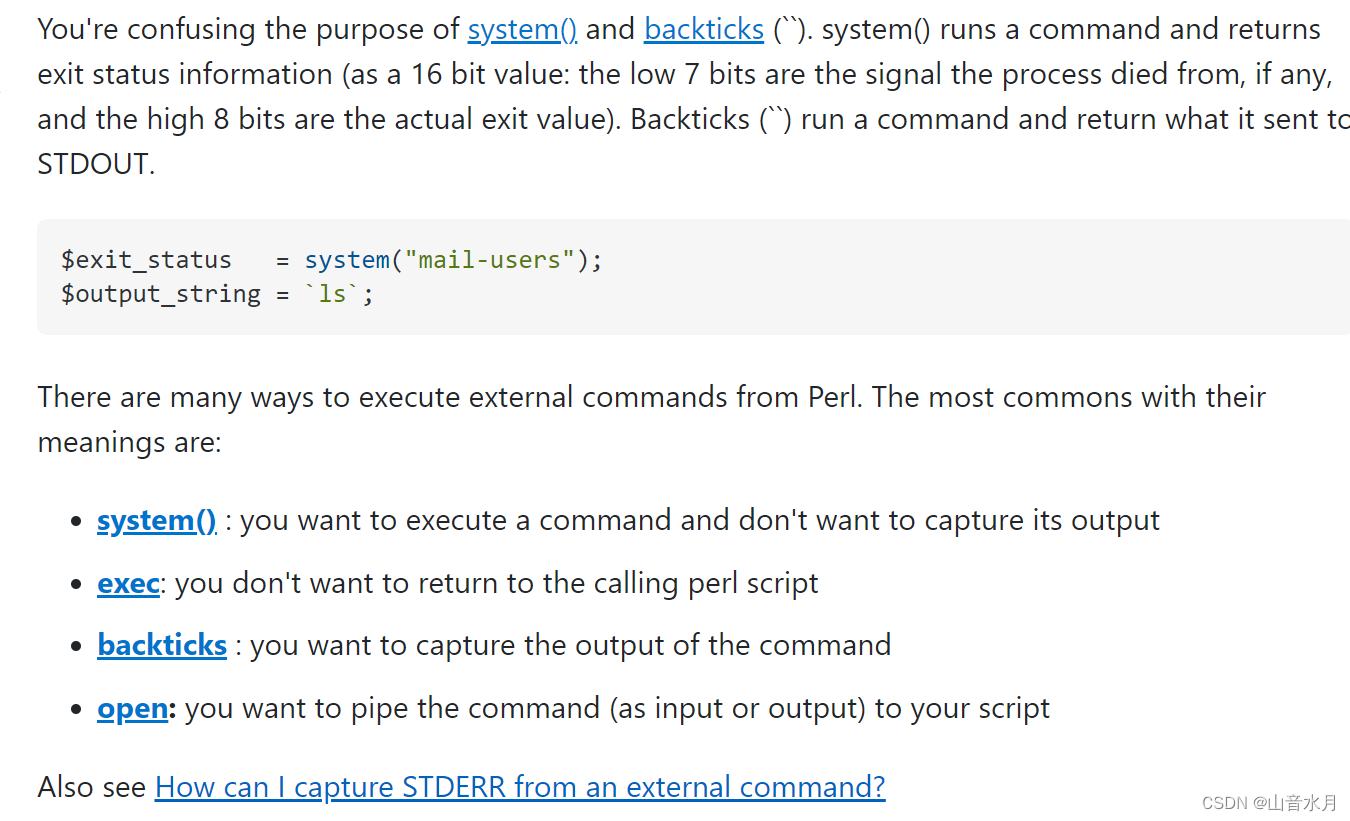
多次调用一个需要"按任意键继续"的exe
情况大致如下,需要读取一个文件夹的某个输入文件,调用exe进行处理,输出到另一个文件夹里,会出现多次调用;此处有点麻烦的是,该exe在执行完成后需要“按任意键继续”才能执行
use strict;
use warnings;
use File::Basename;
use File::Spec;
use File::Path;
use File::Find;
use Capture::Tiny 'capture';
#----------------------------------------------------------
#
#----------------------------------------------------------
sub get_specific_files{
my ($dir,$file_desc) = @_;
my @all_files;
my @spec_files;
# Use $File::Find::name instead of $_ to get the paths.
# find(sub { push @all_files, $_ }, $dir);
find(sub { push @all_files, $File::Find::name }, $dir);
for my $file_item (@all_files){
if($file_item =~ m{$file_desc}xmi){
push @spec_files,$file_item;
}
}
return @spec_files;
}
#----------------------------------------------------------
#
#----------------------------------------------------------
if (-d "output")
{
File::Path::rmtree("output");
}
my @p_files_ay = get_specific_files("input",'\.p$');
for my $p_file (@p_files_ay)
{
my ($in_path, $in_leaf, $suffix) = fileparse($p_file,".p");
my $out_leaf = $in_leaf;
$out_leaf =~ s/input/output/gsi;
# print $in_path,'-->',$in_leaf,'--->',$out_leaf,"\n";
if (!-d $out_leaf)
{
File::Path::make_path($out_leaf);
}
my $p_path = $in_leaf.$in_path.".p";
my $m_path = $out_leaf.$in_path.".m";
my ($output, $error_output, $exit_code) = capture {
#由于调用的exe需要"按任意键继续",才能接着执行,因此使用echo & echo.|
system("echo & echo.|ptom.exe -i $p_path -o $m_path");
};
# print $output,"\n";
}
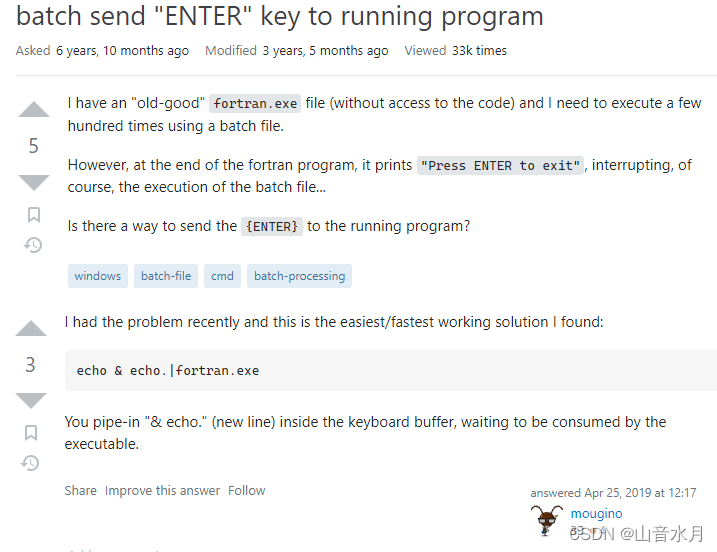
其他
递归创建文件夹
判断文件夹是否存在
使用portable版的perl
使用portable版的perl有一个好处,可以即插即用
cpan和cpanm的区别

不使用临时文件,直接修改原文件
















 2356
2356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









