







关于卷积神经网络CNN,网络和文献中有非常多的资料,我在工作/研究中也用了好一段时间各种常见的model了,就想着简单整理一下,以备查阅之需。
- LeNet5,1994年
- Alexnet,2012年
- VGG,2014年
- Network-in-network
- GoogleNet,2014年
- ZFnet, 2014年
Lenet5
LeNet5 诞生于 1994 年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从 1988 年开始,在许多次成功的迭代后,这项由 Yann LeCun 完成的开拓性成果被命名为 LeNet5(参见:Gradient-Based Learning Applied to Document Recognition)。
就从Lenet说起,可以看下caffe中lenet的配置文件(点我),可以试着理解每一层的大小,和各种参数。由两个卷积层,两个池化层,以及两个全连接层组成。 卷积都是5*5的模板,stride=1,池化都是MAX。下图是一个类似的结构,可以帮助理解层次结构(和caffe不完全一致,不过基本上差不多)
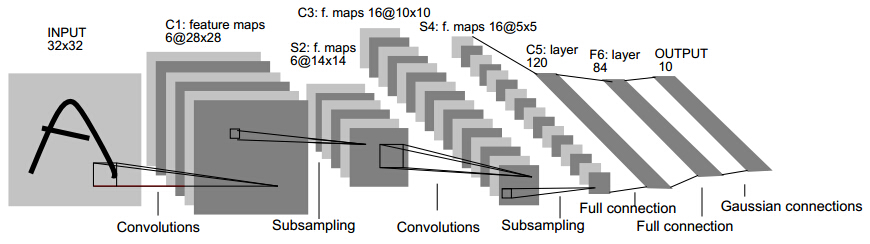
LeNet5 的架构基于这样的观点:(尤其是)图像的特征分布在整张图像上,以及带有可学习参数的卷积是一种用少量参数在多个位置上提取相似特征的有效方式。在那时候,没有 GPU 帮助训练,甚至 CPU 的速度也很慢。因此,能够保存参数以及计算过程是一个关键进展。这和将每个像素用作一个大型多层神经网络的单独输入相反。LeNet5 阐述了那些像素不应该被使用在第一层,因为图像具有很强的空间相关性,而使用图像中独立的像素作为不同的输入特征则利用不到这些相关性。
对于卷积层,其计算公式为
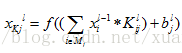
其中K表示由L层到L+1层要产生的feature的数量,表示“卷积核”,表示偏置,也就是bias,令卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,对于卷积层C1,每个像素都与前一层的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。
对于LeNet5,S2这个pooling层是对C1中的2*2区域内的像素求和再加上一个偏置,然后将这个结果再做一次映射(sigmoid等函数),所以相当于对S1做了降维,此处共有6*2=12个参数。S2中的每个像素都与C1中的2*2个像素和1个偏置相连接,所以有6*5*14*14=5880个连接(connection)。
除此外,pooling层还有max-pooling和mean-pooling这两种实现,max-pooling即取2*2区域内最大的像素,而mean-pooling即取2*2区域内像素的均值。
LeNet5最复杂的就是S2到C3层,其连接如下图所示。

前6个feature map与S2层相连的3个feature map相连接,后面6个feature map与S2层相连的4个feature map相连接,后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
S4是pooling层,窗口大小仍然是2*2,共计16个feature map,所以32个参数,16*(25*4+25)=2000个连接。
C5是卷积层,总共120个feature map,每个feature map与S4层所有的feature map相连接,卷积核大小是5*5,而S4层的feature map的大小也是5*5,所以C5的feature map就变成了1个点,共计有120(25*16+1)=48120个参数。
F6相当于MLP中的隐含层,有84个节点,所以有84*(120+1)=10164个参数。F6层采用了正切函数,计算公式为,

输出层采用了RBF函数,即径向欧式距离函数,计算公式为,

以上就是LeNet5的结构。
LeNet5 特征能够总结为如下几点:
卷积神经网络使用 3 个层作为一个序列:卷积、池化、非线性 → 这可能是自从这篇 paper 起图像深度学习的关键特征!
使用卷积提取空间特征;
使用映射到空间均值下采样(subsample);
双曲正切(tanh)或 S 型(sigmoid)形式的非线性;
多层神经网络(MLP)作为最后的分类器;
层与层之间的稀疏连接矩阵避免大的计算成本;
总体来看,这个网络是最近大量架构的起点,并且也给这个领域的许多带来了灵感。
(间隔
从 1998 年到 2010 年神经网络处于孵化阶段。大多数人没有意识到它们不断增长的力量,与此同时其他研究者则进展缓慢。由于手机相机以及便宜的数字相机的出现,越来越多的数据可被利用。并且计算能力也在成长,CPU 变得更快,GPU 变成了多种用途的计算工具。这些趋势使得神经网络有所进展,虽然速度很慢。数据和计算能力使得神经网络能完成的任务越来越有趣。之后一切变得清晰起来......)
Alexnet
2012年,Imagenet比赛冠军的model——Alexnet [2](以第一作者alex命名)。caffe的model文件在这里。说实话,这个model的意义比后面那些model都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,确实让CNN和GPU都大火了一把,顺便推动了有监督DL的发展。
AlexNet 将 LeNet 的思想扩展到了更大的能学习到远远更复杂的对象与对象层次的神经网络上。这项工作的贡献有:
使用修正的线性单元(ReLU)作为非线性;
在训练的时候使用 Dropout 技术有选择地忽视单个神经元,以避免模型过拟合;
覆盖进行最大池化,避免平均池化的平均化效果;
使用 GPU NVIDIA GTX 580 减少训练时间;
在那时,GPU 相比 CPU 可以提供更多数量的核,训练时间可以提升 10 倍,这又反过来允许使用更大的数据集和更大的图像。
AlexNet 的成功掀起了一场小革命。卷积神经网络现在是深度学习的骨干,它已经变成了「现在能解决有用任务的大型神经网络」的代名词。
模型结构见下图,别看只有寥寥八层(不算input层),但是它有60M以上的参数总量,事实上在参数量上比后面的网络都大。
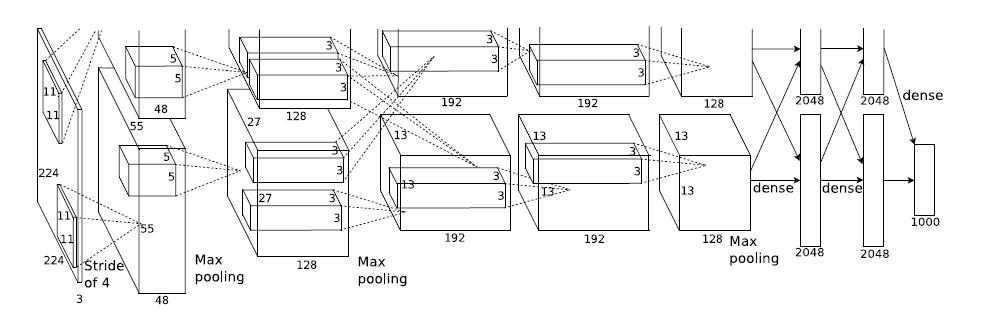
这个图有点点特殊的地方是卷积部分都是画成上下两块,意思是说吧这一层计算出来的feature map分开,但是前一层用到的数据要看连接的虚线,如图中input层之后的第一层第二层之间的虚线是分开的,是说二层上面的128map是由一层上面的48map计算的,下面同理;而第三层前面的虚线是完全交叉的,就是说每一个192map都是由前面的128+128=256map同时计算得到的。
Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理。下面是我画的示意图:
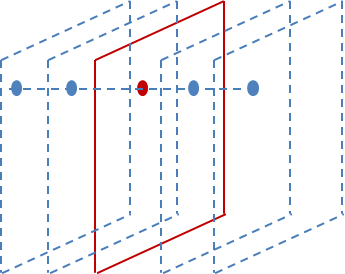
前后几层(对应位置的点)对中间这一层做一下平滑约束,计算方法是:
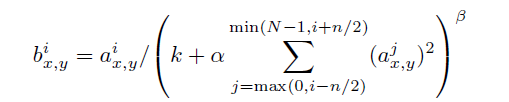
具体打开Alexnet的每一阶段(含一次卷积主要计算)来看[2][3]:
(1)con - relu - pooling - LRN

具体计算都在图里面写了,要注意的是input层是227*227,而不是paper里面的224*224,这里可以算一下,主要是227可以整除后面的conv1计算,224不整除。如果一定要用224可以通过自动补边实现,不过在input就补边感觉没有意义,补得也是0。
(2)conv - relu - pool - LRN
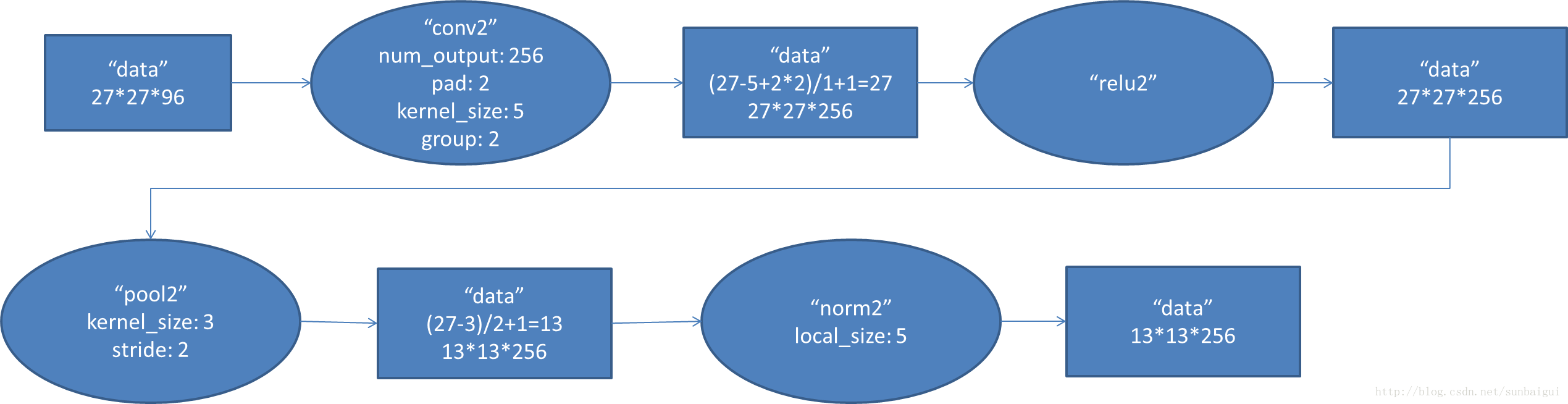
和上面基本一样,唯独需要注意的是group=2,这个属性强行把前面结果的feature map分开,卷积部分分成两部分做。
(3)conv - relu

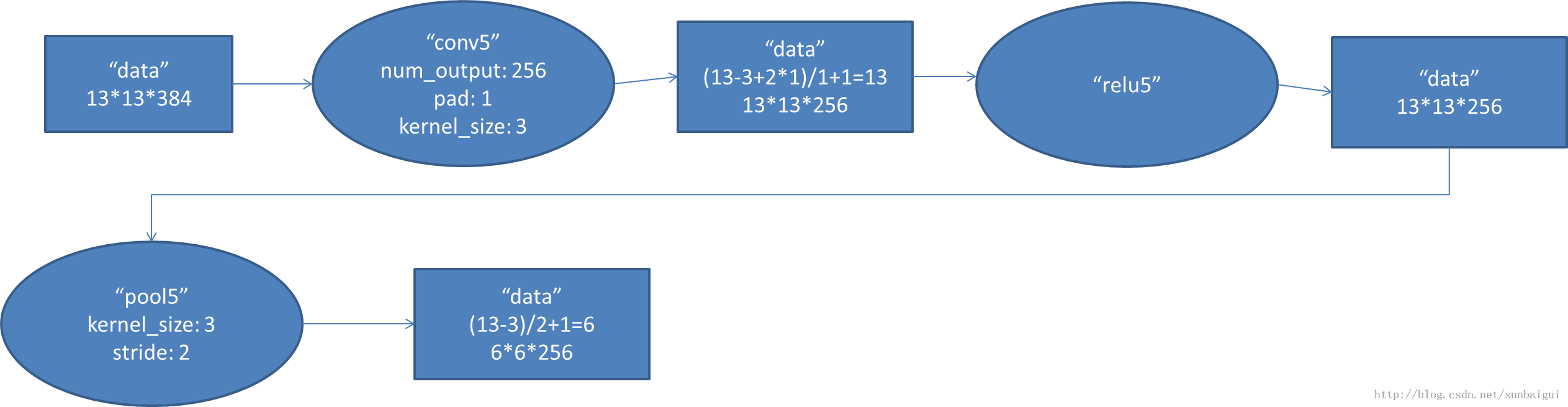
(4)conv-relu

(5)conv - relu - pool
(6)fc - relu - dropout
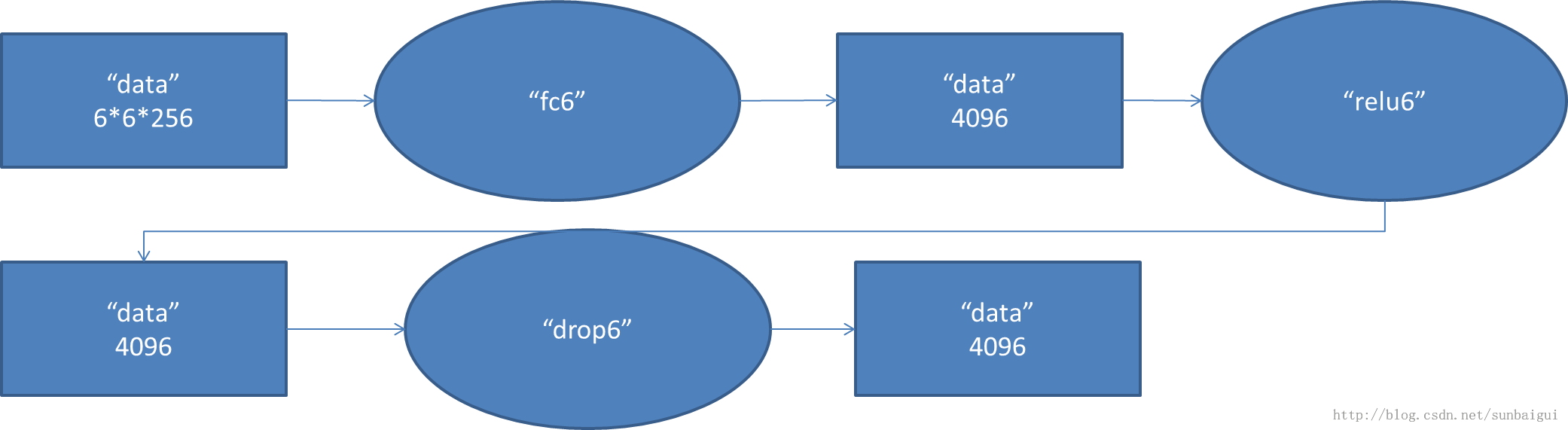
这里有一层特殊的dropout层,在alexnet中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。
(7)
fc - relu - dropout
(8)fc - softmax
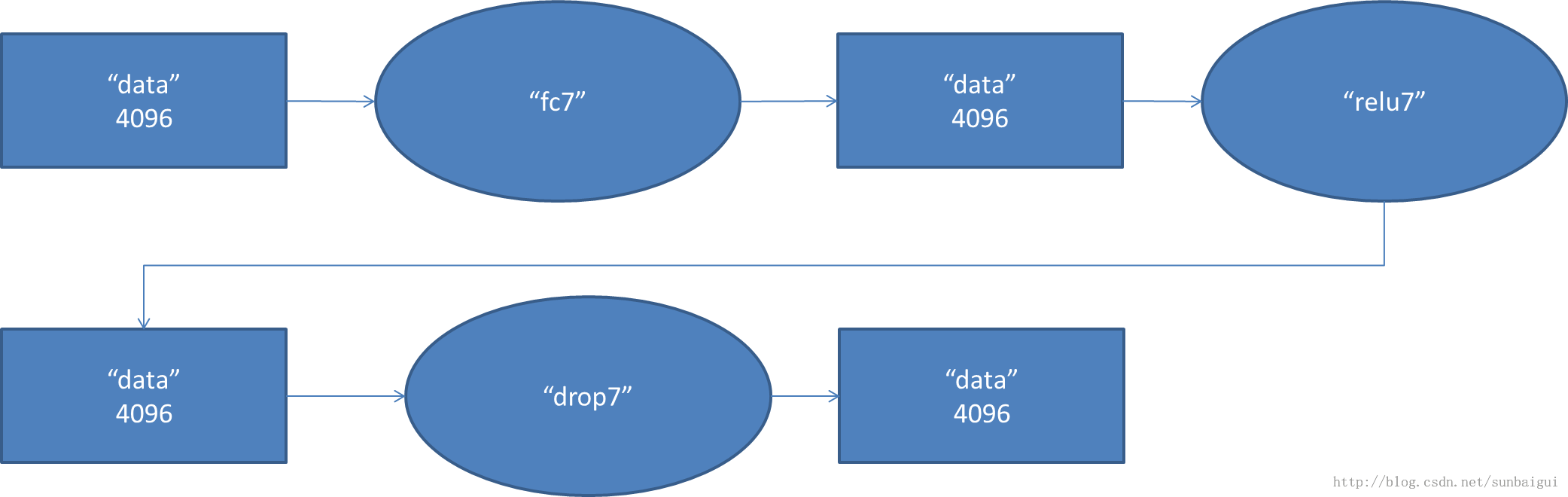

以上图借用[3],感谢。
VGG
来自牛津大学的 VGG 网络(参见:Very Deep Convolutional Networks for Large-Scale Image Recognition)是第一个在各个卷积层使用更小的 3×3 过滤器(filter),并把它们组合作为一个卷积序列进行处理的网络。
这看来和 LeNet 的原理相反,其中是大的卷积被用来获取一张图像中相似特征。和 AlexNet 的 9×9 或 11×11 过滤器不同,过滤器开始变得更小,离 LeNet 竭力所要避免的臭名昭著的 1×1 卷积异常接近——至少在该网络的第一层是这样。但是 VGG 巨大的进展是通过依次采用多个 3×3 卷积,能够模仿出更大的感受野(receptive field)的效果,例如 5×5 与 7×7。这些思想也被用在了最近更多的网络架构中,如 Inception 与 ResNet。
VGG有很多个版本,也算是比较稳定和经典的model。它的特点也是连续conv多,计算量巨大(比前面几个都大很多)。具体的model结构可以参考[6],这里给一个简图。基本上组成构建就是前面alexnet用到的。
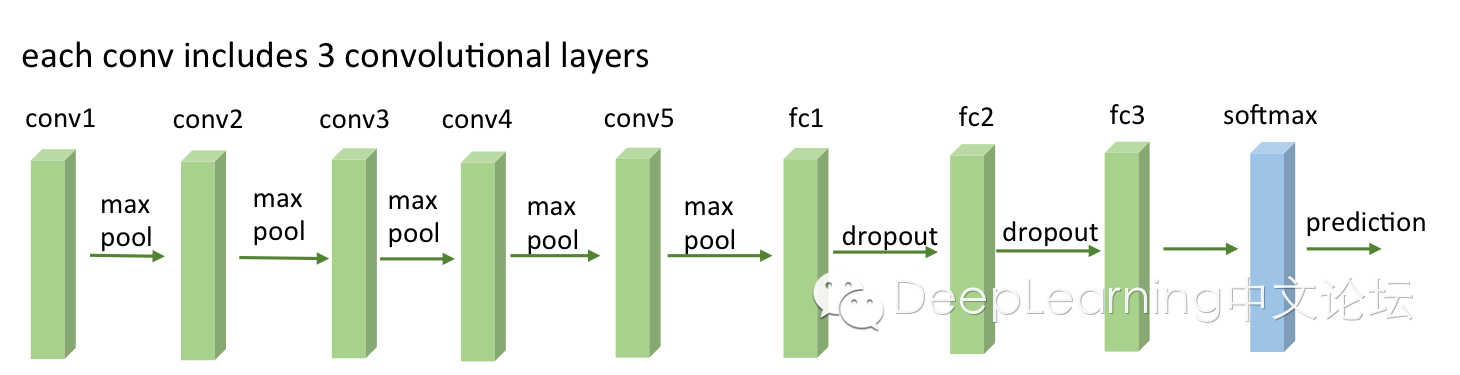
下面是几个model的具体结构,可以查阅,很容易看懂。
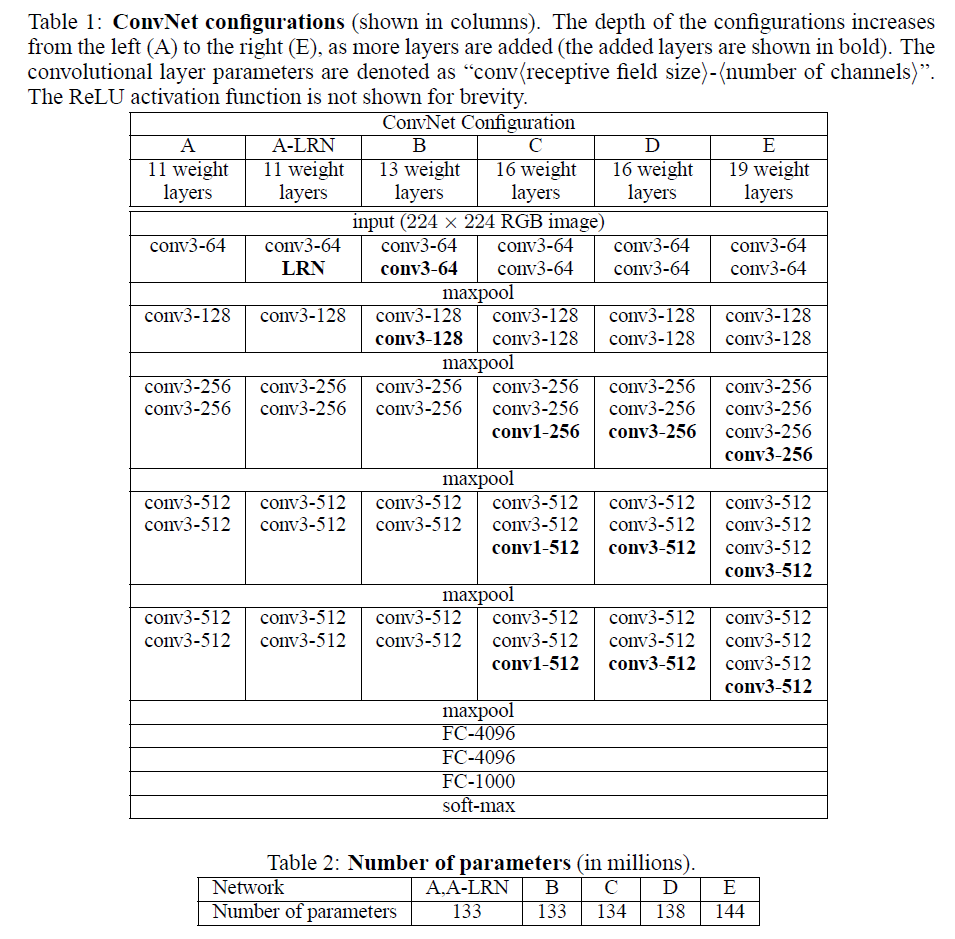
VGG 网络使用多个 3×3 卷积层去表征复杂特征。注意 VGG-E 的第 3、4、5 块(block):256×256 和 512×512 个 3×3 过滤器被依次使用多次以提取更多复杂特征以及这些特征的组合。其效果就等于是一个带有 3 个卷积层的大型的 512×512 大分类器。这显然意味着有大量的参数与学习能力。但是这些网络训练很困难,必须划分到较小的网络,并逐层累加。这是因为缺少强大的方式对模型进行正则化,或者或多或少约束大量由于大量参数增长的搜索空间。
VGG 在许多层中都使用大特征尺寸,因为推断(inference)在运行时是相当耗费时间的。正如 Inception 的瓶颈(bottleneck)那样,减少特征的数量将节省一些计算成本。
Network-in-network
网络中的网络(NiN,参见论文:Network In Network)的思路简单又伟大:使用 1×1 卷积为卷积层的特征提供更组合性的能力。
NiN 架构在各个卷积之后使用空间 MLP 层,以便更好地在其他层之前组合特征。同样,你可以认为 1×1 卷积与 LeNet 最初的原理相悖,但事实上它们可以以一种更好的方式组合卷积特征,而这是不可能通过简单堆叠更多的卷积特征做到的。这和使用原始像素作为下一层输入是有区别的。其中 1×1 卷积常常被用于在卷积之后的特征映射上对特征进行空间组合,所以它们实际上可以使用非常少的参数,并在这些特征的所有像素上共享!

MLP 的能力能通过将卷积特征组合进更复杂的组(group)来极大地增加单个卷积特征的有效性。这个想法之后被用到一些最近的架构中,例如 ResNet、Inception 及其衍生技术。
NiN 也使用了平均池化层作为最后分类器的一部分,这是另一种将会变得常见的实践。这是通过在分类之前对网络对多个输入图像的响应进行平均完成的。
GoogleNet
googlenet[4][5],14年比赛冠军的model,这个model证明了一件事:用更多的卷积,更深的层次可以得到更好的结构。(当然,它并没有证明浅的层次不能达到这样的效果)。来自谷歌的 Christian Szegedy 开始追求减少深度神经网络的计算开销,并设计出 GoogLeNet——第一个 Inception 架构(参见:Going Deeper with Convolutions)
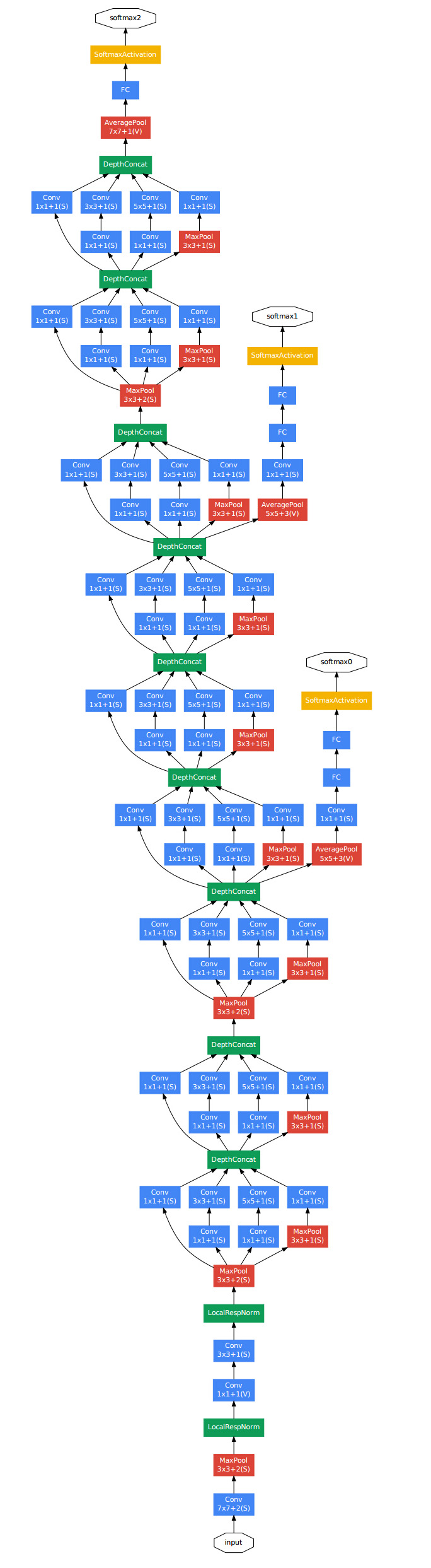
那是在 2014 年秋季,深度学习模型正在变得在图像与视频帧的分类中非常有用。大多数怀疑者已经不再怀疑深度学习与神经网络这一次是真的回来了,而且将一直发展下去。鉴于这些技术的用处,谷歌这样的互联网巨头非常有兴趣在他们的服务器上高效且大规模庞大地部署这些架构。
Christian 考虑了很多关于在深度神经网络达到最高水平的性能(例如在 ImageNet 上)的同时减少其计算开销的方式。或者在能够保证同样的计算开销的前提下对性能有所改进。
他和他的团队提出了 Inception 模块:
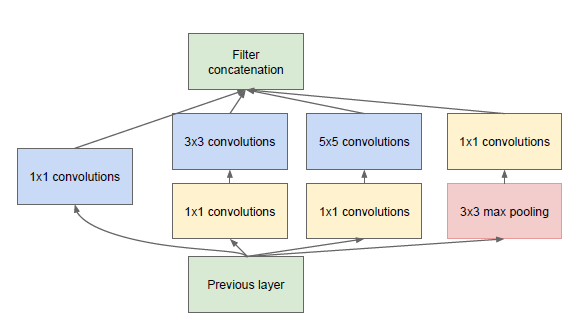
是说一分四,然后做一些不同大小的卷积,之后再堆叠feature map。
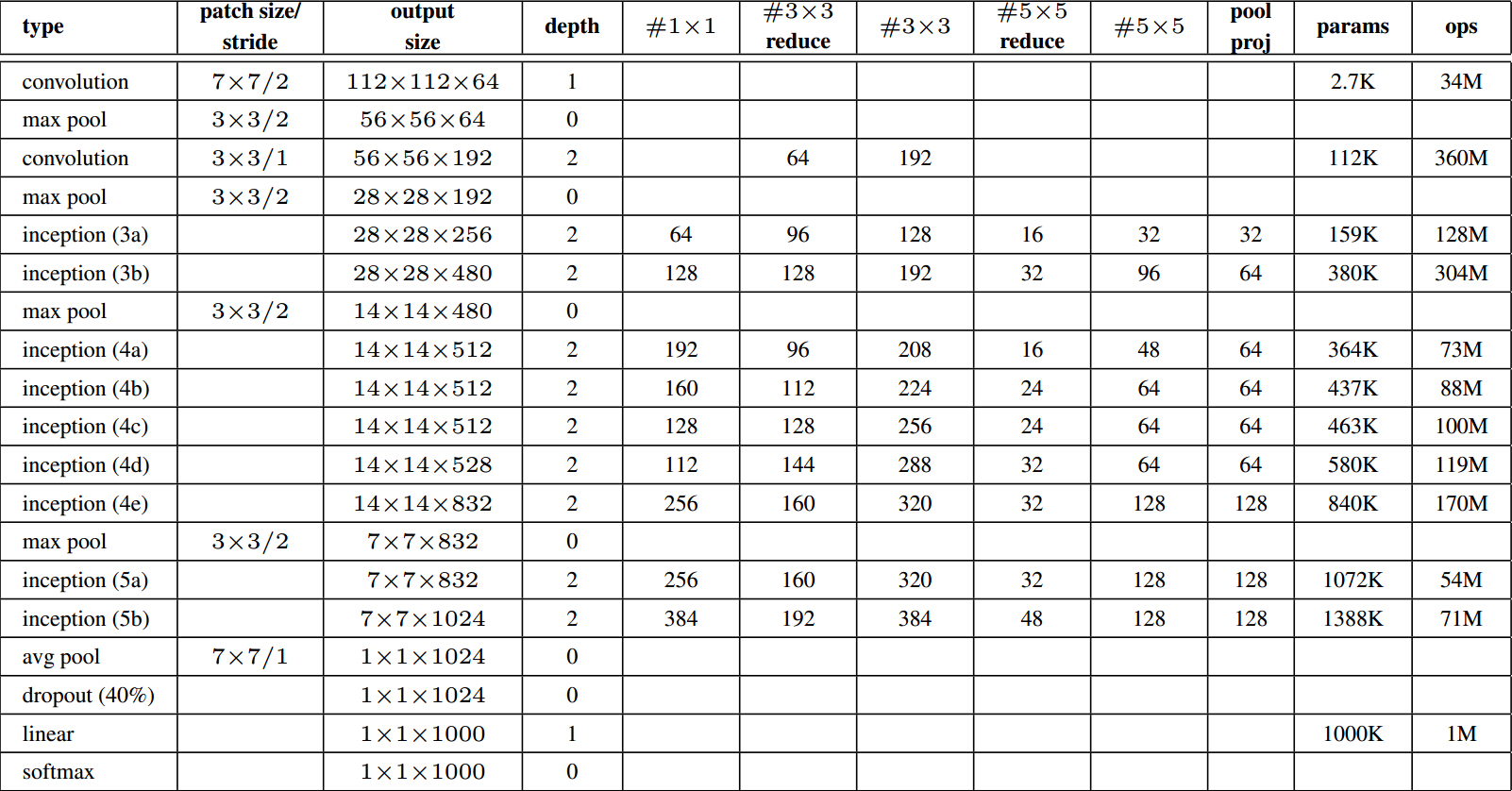
计算量如下图,可以看到参数总量并不大,但是计算次数是非常大的。
初看之下这不过基本上是 1×1、3×3、5×5 卷积过滤器的并行组合。但是 Inception 的伟大思路是用 1×1 的卷积块(NiN)在昂贵的并行模块之前减少特征的数量。这一般被称为「瓶颈(bottleneck)」。这部分内容将在下面的「瓶颈层(bottleneck layer)」部分来解释。
GoogLeNet 使用没有 inception 模块的主干作为初始层,之后是与 NiN 相似的一个平均池化层加 softmax 分类器。这个分类器比 AlexNet 与 VGG 的分类器的运算数量少得多。这也促成一项非常有效的网络设计,参见论文:An Analysis of Deep Neural Network Models for Practical Applications。
瓶颈层(Bottleneck layer)
受到 NiN 的启发,Inception 的瓶颈层减少了每一层的特征的数量,并由此减少了运算的数量;所以可以保持较低的推理时间。在将数据通入昂贵的卷积模块之前,特征的数量会减少 4 倍。在计算成本上这是很大的节约,也是该架构的成功之处。
让我们具体验证一下。现在你有 256 个特征输入,256 个特征输出,假定 Inception 层只能执行 3×3 的卷积,也就是总共要完成 256×256×3×3 的卷积(将近 589,000 次乘积累加(MAC)运算)。这可能超出了我们的计算预算,比如说,在谷歌服务器上要以 0.5 毫秒运行该层。作为替代,我们决定减少需要进行卷积运算的特征的数量,也就是 64(即 256/4)个。在这种情况下,我们首先进行 256 -> 64 1×1 的卷积,然后在所有 Inception 的分支上进行 64 次卷积,接而再使用一个来自 64 -> 256 的特征的 1×1 卷积,现在运算如下:
256×64 × 1×1 = 16,000s
64×64 × 3×3 = 36,000s
64×256 × 1×1 = 16,000s
相比于之前的 60 万,现在共有 7 万的计算量,几乎少了近 10 倍。
而且,尽管我们做了更好的运算,我们在此层也没有损失其通用性(generality)。事实证明瓶颈层在 ImageNet 这样的数据集上已经表现出了顶尖水平,而且它也被用于接下来介绍的 ResNet 这样的架构中。
它之所以成功是因为输入特征是相关联的,因此可通过将它们与 1×1 卷积适当结合来减少冗余。然后,在小数量的特征进行卷积之后,它们能在下一层被再次扩展成有意义的结合。
ZF-Net
 ZF-Net说明
ZF-Net说明
总结
OK,到这里把常见的最新的几个model都介绍完了,可以看到,目前cnn model的设计思路基本上朝着深度的网络以及更多的卷积计算方向发展。虽然有点暴力,但是效果上确实是提升了。当然,我认为以后会出现更优秀的model,方向应该不是更深,而是简化。是时候动一动卷积计算的形式了。
参考资料
[1] http://blog.csdn.net/zouxy09/article/details/8781543/
[2] ImageNet Classification with Deep Convolutional Neural Networks
[3] http://blog.csdn.net/sunbaigui/article/details/39938097
[4] http://blog.csdn.net/csyhhb/article/details/45967291
[5] Going deeper with convolutions
[6] VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









