







文章目录
1、什么是文本匹配?
文本匹配是自然语言处理中一个重要的基础问题,可以应用于大量的NLP任务中,如信息检索、问答系统、复述问题、对话系统、机器翻译等,这些NLP任务在很大程度上可以抽象为文本匹配问题。
例如网页搜索可抽象为网页同用户搜索Query的一个相关性匹配问题,自动问答可抽象为候选答案与问题的满足度匹配问题,文本去重可以抽象为文本与文本的相似度匹配问题。
2、文本匹配方法概述
2-1 传统文本匹配方法
传统的文本匹配技术有BoW、VSM、TF-IDF、 BM25、Jaccord、SimHash等算法,如BM25算法通过网络字段对查询字段的覆盖程度来计算两者间的匹配得分,得分越高的网页与查询的匹配度更好。主要解决词汇层面的匹配问题,或者说词汇层面的相似度问题。而实际上,基于词汇重合度的匹配算法有很大的局限性,原因包括:
- 词义局限:“的士”和“出租车”虽然字面上不相似,但实际为同一种交通工具;“苹果”在不同的语境下表示不同的东西,或为水果或为公司
- 结构局限:“机器学习”和“学习机器”虽然词汇完全重合,但表达的意思不同。
- 知识局限:“秦始皇打Dota”,这句话虽从词法和句法上看均没问题,但结合知识看这句话是不对的。
这表明,对于文本匹配任务,不能只停留在字面匹配层面,更需要语义层面的匹配。而语义层面的匹配,首先面临语义如何表示,如何计算的问题。
2-2 主题模型
属于无监督技术
上世纪90年代逐渐流行起来语义分析技术(Latent Sementic Analysis, LSA),开辟了一个新思路。将语句映射到等长的低维连续空间,可在此隐式的潜在语义空间上进行相似度计算。
此后,又有PLSA(Probabilistic Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)等更高级的概率模型被设计出来,逐渐形成非常火热的 主题模型 技术方向。
这些技术对文本的语义表示形式简洁、运算方便,较好地弥补了传统词汇匹配方法的不足。不过从效果上来看,这些技术都无法替代字面匹配技术,只能作为字面匹配的有效补充。
2-3 深度语义匹配模型
随着深度学习在计算机视觉、语音识别和推荐系统领域中的成功运用,近年来有很多研究致力于将深度神经网络模型应用于自然语言处理任务,以降低特征工程的成本。
基于神经网络训练出的Word Embedding来进行文本匹配计算,训练方式简洁,所得的词语向量表示的语义可计算性进一步加强。但是只利用无标注数据训练得到的Word Embedding在匹配度计算的实用效果上和主题模型技术相差不大。他们本质都是基于共现信息的训练。另外,Word Embedding本身没有解决短语、句子的语义表示问题,也没有解决匹配的非对称性问题。
一般来说,深度文本匹配模型分为两种类型: 表示型和交互型。
表示型
表示型模型更侧重对表示层的构建,会在表示层将文本转换成唯一的一个整体表示向量。
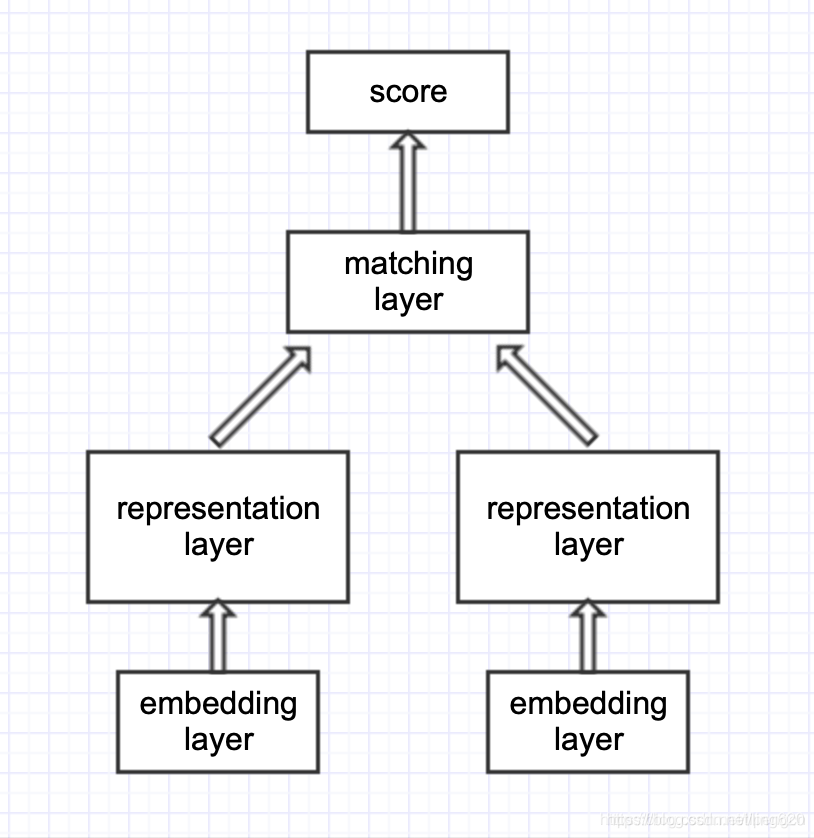
representation-based类模型,思路是基于Siamese网络,提取文本整体语义再进行匹配- 典型的
Siamese结构,双塔共享参数,将两文本映射到统一空间,才具有匹配意义 - 表整层进行编码,使用
MLP, CNN, RNN, Self-attention, Transformer encoder, BERT均可 - 匹配层进行交互计算,采用点积、余弦、高斯距离、MLP、相似度矩阵均可
- 经典模型有:
DSSM, CDSSM, MV-LSTM, ARC-I, CNTN, CA-RNN, MultiGranCNN等 - 优点:可以对文本预处理,构建索引,大幅度降低在线计算耗时
- 缺点:失去语义焦点,易语义漂移,难以衡量词的上下文重要性。
相关算法
DSSM: 2013年由微软Redmond研究院发表,全称DSSM(Deep Structured Semantic Models)CDSSM:2014年由微软提出,弥补了DSSM会丢失上下文的问题,全称Convolutional latent semantic model(又称CLSM)- 主要将
DNN替换成了CNN
- 主要将
MV-DSSM:2016年由微软发表,MV为Multi-View,一般可以理解为多视角的DSSMARC-I:2014年由华为若亚方舟实验室提出
交互型
交互性模型摒弃后匹配的思路,假设全局的匹配度依赖于局部的匹配度,在输入层就进行词语间的先匹配,并将匹配的结果作为灰度图进行后续的建模。
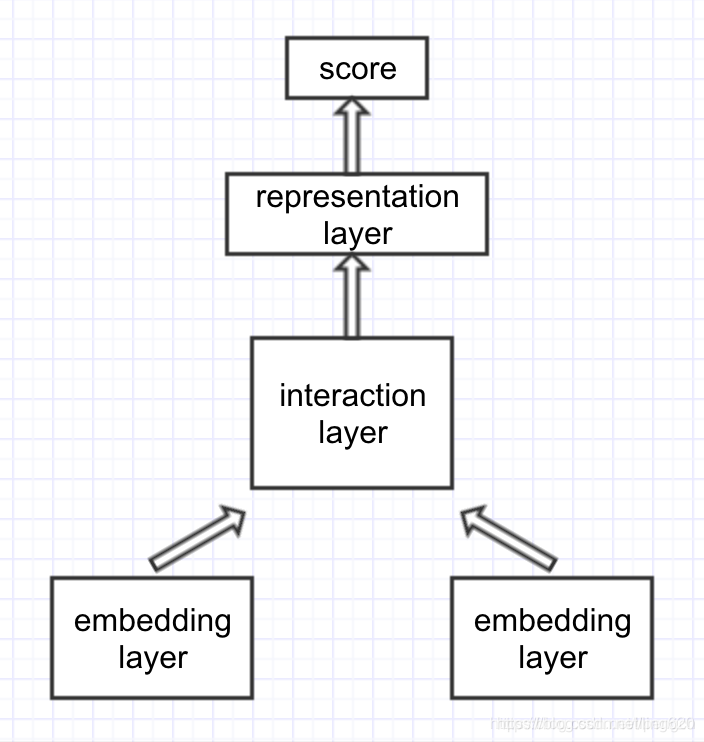
interaction-based类模型,思路是捕捉直接的匹配信号(模式),将词间的匹配信号作为灰度图,再进行后续建模抽象- 交互层,由两文本词与词构成交互矩阵,交互运算类似于
attention,加性乘性都可以 - 表征层,负责对交互矩阵进行抽象表征,
CNN、S-RNN均可 - 经典模型有:
ARC-II、MatchPyramid、Match-SRNN、K-NRM、DRMM、DeepRank、DUET、IR-Transformer、DeepMatch、ESIM、ABCNN、BIMPM等 - 优点:更好地把握了语义焦点,能对上下文重要性进行更好的建模
- 缺点:忽视了句法、句间对照等全局性信息,无法由局部匹配信息刻画全局匹配信息
相关算法
ARC-II:2014年由华为诺亚方舟实验室提出MatchPyramid:2016年由中科院提出ABCNN:2016年由IBM提出ESIM:2017年由朱晓丹提出
3、语义匹配应用介绍
工业界的很多应用都有在语义上衡量文本相似度的需求,我们将这类需求统称为“语义匹配”。
根据文本长度的不同,语义匹配可以细分为三类:
- 短文本-短文本语义匹配
- 短文本-长文本语义匹配
- 长文本-长文本语义匹配
基于主题模型的语义匹配通常作为经典文本匹配技术的补充,而不是取代传统的文本匹配技术(上文有提到)。
3-1 短文本-短文本语义匹配
该类型在工业界的应用场景很广泛。如,
在网页搜索中,需要度量用户查询(Query)和网页标题(web page title)的语义相关性;
在Query查询中,需要度量 Query和其他 Query之间的相似度。
由于主题模型在短文本上的效果不太理想,在短文本-短文本匹配任务中 词向量的应用 比主题模型更为普遍。简单的任务可以使用Word2Vec这种浅层的神经网络模型训练出来的词向量。
如,计算两个Query的相似度, q1 = "推荐好看的电影"与 q2 = “2016年好看的电影”。
- 通过词向量按位累加的方式,计算这两个Query的向量表示
- 利用余弦相似度(Cosine Similarity)计算两个向量的相似度。
对于较难的短文本-短文本匹配任务,考虑引入有监督信号并利用“DSSM”或“CLSM”这些更复杂的神经网络进行语义相关性的计算。
总结:
- 使用词向量按位累加方式获取句向量,使用距离度量获取相似度
- 利用
DSSM等方法进行匹配度计算
3-2 短文本-长文本语义匹配
短文本-长文本语义匹配的应用场景在工业界非常普遍。例如,
在搜索引擎中,需要计算用户 Query 和一个网页正文(content)的语义相关度。由于 Query 通常较短,因此 Query 与 content 的匹配与上文提到的短文本-短文本不同,通常需要使用短文本-长文本语义匹配,以得到更好的匹配效果。
在计算相似度的时候,我们规避对短文本直接进行主题映射,而是根据长文本的 主题分布,计算该分布生成短文本的概率,作为他们之间的相似度。
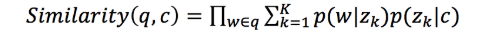
其中,q表示Query,c表示content, w表示q中的词, z k z_k zk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2922
2922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









