







目录
一、序言
一时炒股一时爽,一直炒股一直爽。有人赢麻了,有人亏麻了。也许股市只有秋天红,但韭菜一年四季都绿。等涨停过去了,黄花菜也可以凉拌了。
今天咱不聊怎么炒股,咱聊聊股票的行情系统。国内沪深A股和美股每天都有4、5000股票在交易,港股也有2000多只股票在交易,对于一个行情系统来说,承载的数据读取和写入数量都非常庞大。
同时对于用户来说,股票行情系统的实时性也非常重要,尤其是港美股,用户可以进行T+0交易,行情信息的延迟和错误展示直接会影响用户实时交易和判断。
二、行情系统架构图
一般来说,系统会从行情数据数据源拉取数据,这些数据源有些来自交易所,有些来自第三方。拉取到行情数据后会进行数据的清洗,格式转换、压缩等等。
整体架构如下:
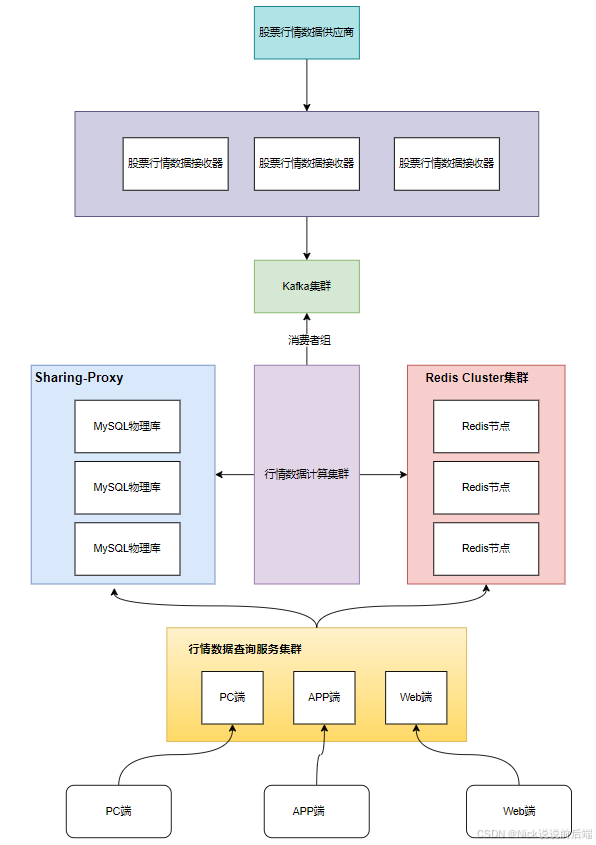
1、为什么选择Kafka
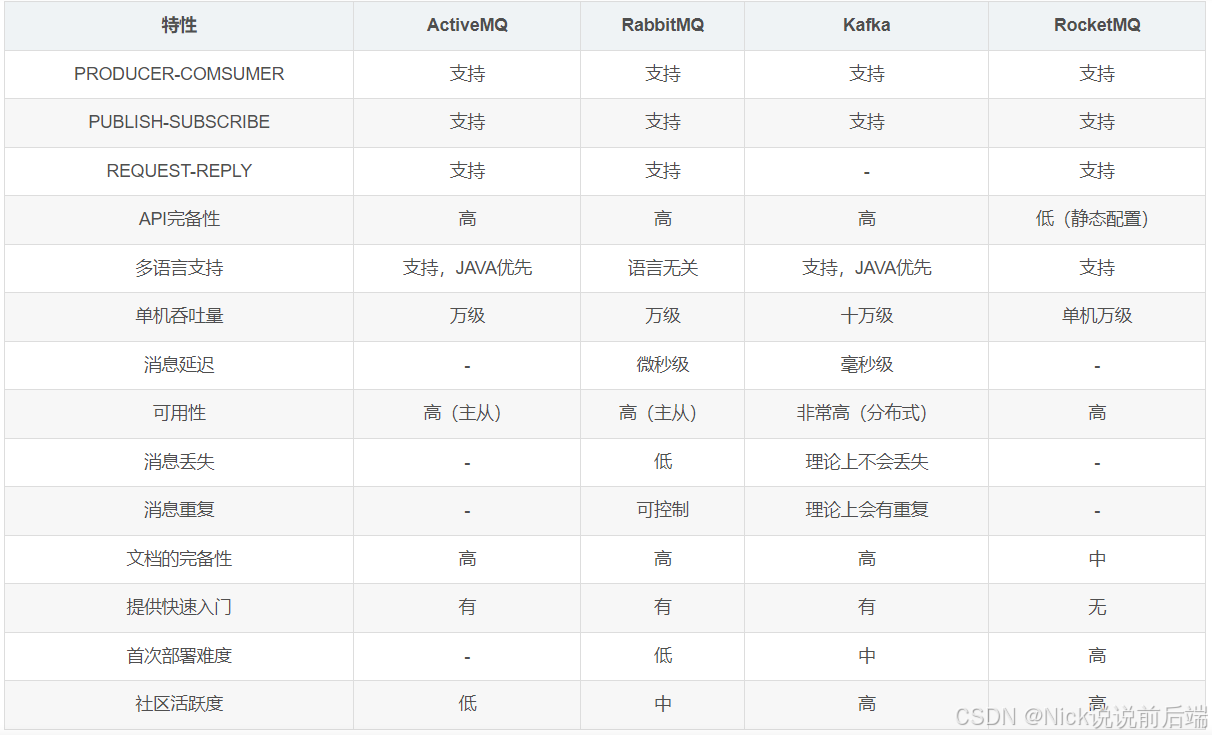
因为行情数据数据量非常大,高峰期每秒甚至可能会产生10几万条交易信息,目前主流的MQ中Kafka的单机吞吐量达到十万级,适合实时数据计算和处理。
下面是各大主流MQ的对比图:
2、行情数据Redis集群分片存储
行情数据清洗后,需要进行计算,比如涨跌幅、振幅、K线(分钟K、日K、月K、周K、年K)等等。
实时行情数据从数据库中查询不现实,我们可以将这些数据先缓存到Redis中,由于几千只个股交易数据非常庞大,单节点Redis的QPS以及内存、磁盘存储都有限。
我们可以采用Redis集群加上读写分离架构,集群可以支持水平扩容,热点和大key也可以实现迁移和分片。
行情数据的写入和查询非常频繁,读写分离架构可以请求分流,将查询请求分发到从节点,增加整体系统的QPS。
备注:博主之前在的一家证券公司主要做港美股行情,Redis集群主节点部署了5台依然有性能瓶颈,最终扩容到了10个主节点。
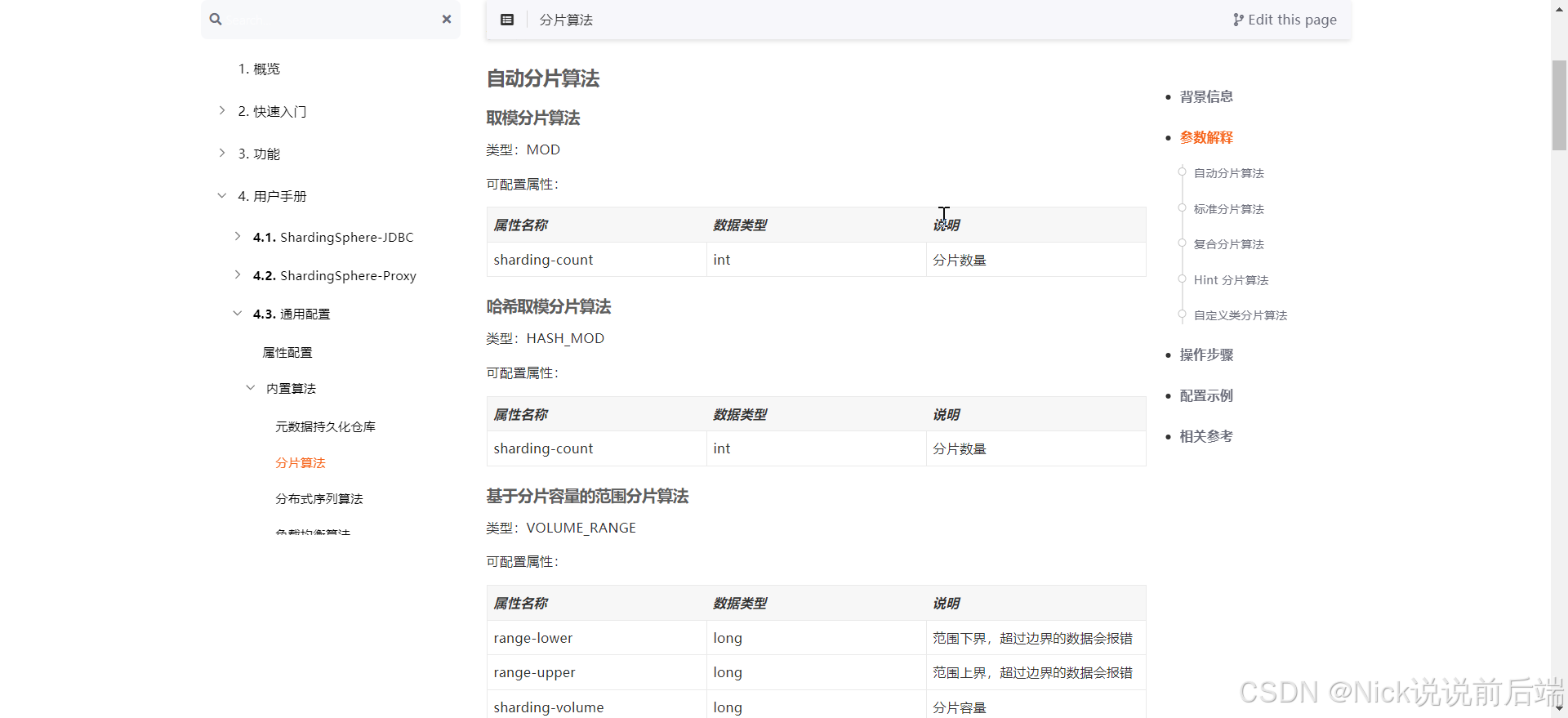
3、数据库通过Sharding Proxy分表
行情数据除了刷新到Redis缓存中,同时需要落地磁盘,我们可以根据个股股票代码进行数据分片,将行情数据存储到不同的数据库表或者库中。
Sharding Proxy可以轻松支持分库和分表,而且支持的分片规则也非常多样。比如对指定字段进行哈希取模,文件范围分片等等。
我们可以通过修改表的分片规则,实现表的水平扩容。
三、需要考虑的问题
1、股票行情需要保证顺序处理
个股的交易信息是顺序产生的,因此我们要保证消息的顺序处理,其中包括消息的顺序投递和顺序消费。
- 消息顺序投递:Kafka支持消息分区,相同个股行情信息根据自定义分区器投递到相同分区就可以保证顺序生产。
- 消息顺序消费:消息从分区消息时,需要保证只被一个消费者组的消费者进行消费,同时拉取完数据后消费者要顺序处理数据(消费者并发度设为1就好)。
2、数据序列化方式
由于股票行情信息界面展示的数据量非常大,这时数据化序列化方式的选择非常重要,像PC端和APP端用户可能会频繁拉取数据,更加紧凑的数据序列化方式可以让传输更快。
PC端和APP端可以采用ProtoBuf实现序列化,Web端访问量相对会比较少,采用JSON序列化也okay。
3、数据推送方式
实时行情可以通过WebSocket或者自定义消息协议进行推送,博主之前所在的证券公司采用的是自定义的消息协议,通过Netty搭建后台推送服务。
4、Redis并发量过高
虽然Redis单节点的QPS能达到10万级,但是实际上由于机器配置、网络等原因并不能实现这么高的并发,而且高峰期对Redis的QPS要求更大。
我们可以将Redis作为一级缓存,从查询服务读取Redis缓存数据时,可以将数据加载到机器内存中,作为二级缓存,这样既可以降低对Redis读的压力,而且可以减少一次从Redis读取数据的请求。
5、行情数据计算线程池
行情数据服务有很多计算逻辑,对于CPU高度密集型服务,线程池的配置建议调整为逻辑CPU的1到2倍。



















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











