






相关文章及代码下载
jieba库
Jieba是优秀的中文分词第三方库中文文本需要通过分词获得单个的词语,jieba是优秀的中文分词第三方库,需要额外安装jieba库提供三种分词模式,最简单只需掌握一个函数
Jieba分词依靠中文词库利用一个中文词库,确定汉字之间的关联概率汉字间概率大的组成词组,形成分词结果除了分词,用户还可以添加自定义的词组
下面对中外小进行文档分析和词云的制作
英文小说分析
1、打开小说文件,我选择了英文小说双城记(A Tale of Two Cities),先对字符串进行处理,去掉各种标点符号,除英文以外的内容。

将处理过程打包为getText()函数,各种标点符号使用.replace()方法替换成空格
2、统计小说中所有英文单词的使用频次,结果保存在一个字典中。
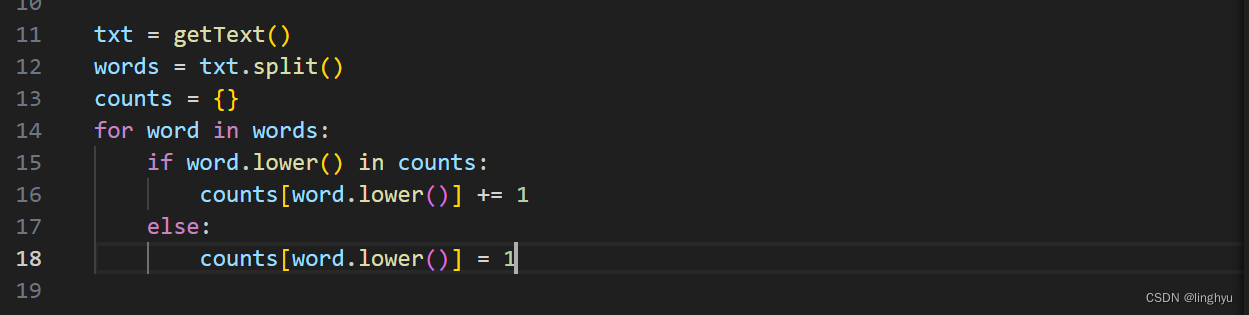
以.split()方法对读取的小说内容txt字符串进行切分,循环以字典形式进行使用频次的记录,如果字典中没有,则新建键,并值为1;如果字典中存在,则对它的值+1。
3、对字典中的数据进行排序,按照使用频次从高到低进行排序,并把统计结果写到一个文本文件中。
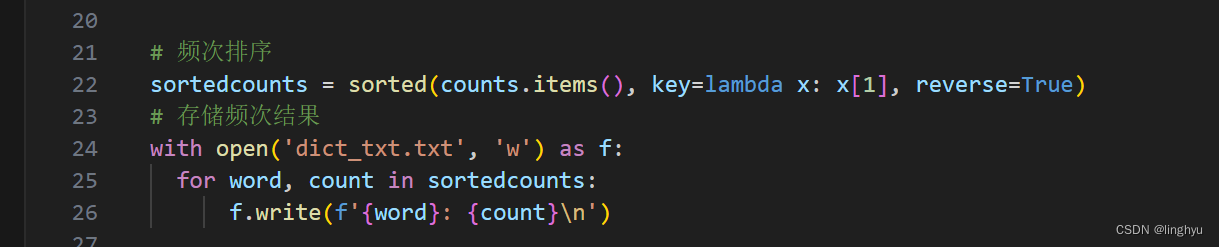
使用sorted()方法,以频次为权重进行递减排序,并以.txt进行存储
4、使用wordcloud模块,把单词的使用频次的信息用词云的方式显示出来。


以下是完整代码:
from wordcloud import WordCloud
def getText():
txt = open("./A Tale of Two Cities.txt", "r").read()
txt = txt.lower()
for ch in "!@#$'%^&*()_+-=`~;:[\\]{|}<,.>/?":
txt = txt.replace(ch, " ")
return txt
txt = getText()
words = txt.split()
counts = {}
for word in words:
if word.lower() in counts:
counts[word.lower()] += 1
else:
counts[word.lower()] = 1
# 频次排序
sortedcounts = sorted(counts.items(), key=lambda x: x[1], reverse=True)
# 存储频次结果
with open('dict_txt.txt', 'w') as f:
for word, count in sortedcounts:
f.write(f'{word}: {count}\n')
# 制作词云,有字典作为频次来源就不再次打开存储结果了
wordcloud = WordCloud(width=800, height=600, background_color='white')
wordcloud.generate_from_frequencies(counts)
wordcloud.to_file('task1_wordcloud.png')
中文小说分析
1、使用中文分词库jieba进行分词。统计使用最多的人名和中文词汇并输出。

引用jieba库,以及词云
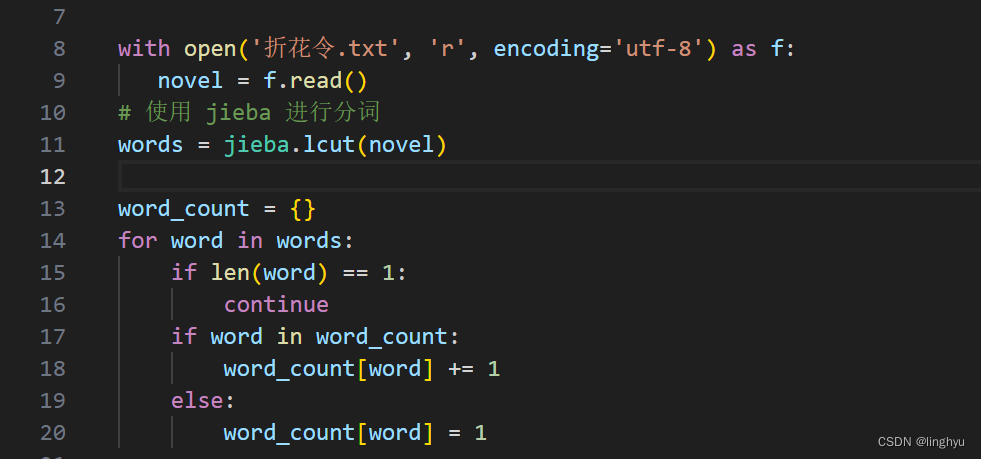
以utf-8打开中文小说,这里使用的是上网搜索的网络小说,进行词频的统计,与任务一的统计方法相同
同样以词频为权重进行排序
![]()
因为词频统计的结果包含许多除了人物的词组,因此在要进行输出出现频次最多的人物和后面列出小说中的主要人物需要对第一次计算词频的结果进行清洗

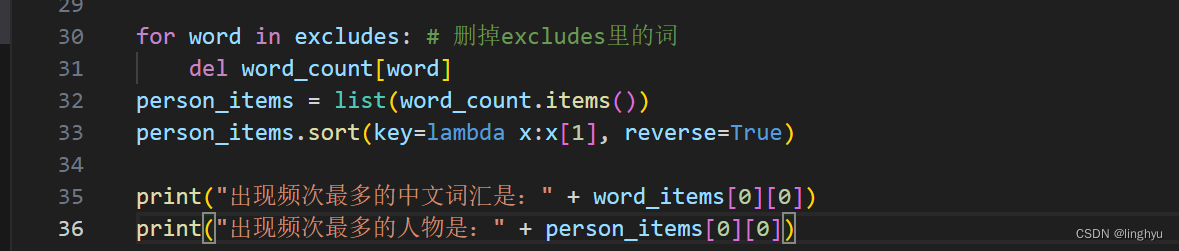
2、列出小说中的主要人物,包括主人公,以及另外相关人物5人或以上。
经过了上文的清洗,可以很容易对处理完的字典找到主要人物

3、把小说分段,分析出小说一共有多少自然段。因为所保存的小说为网络小说,因此使用章节来进行划分,一共18个章节
![]()
表示出上文列出的主要人物在章节中出现的情况,这里我使用了一个二维数组,通过用0、1的方式来表示当前列的章节,五个主要人物是否有出现,并且方便下面亲密度的计算,可以直观的看出人物出现的位置和频率。
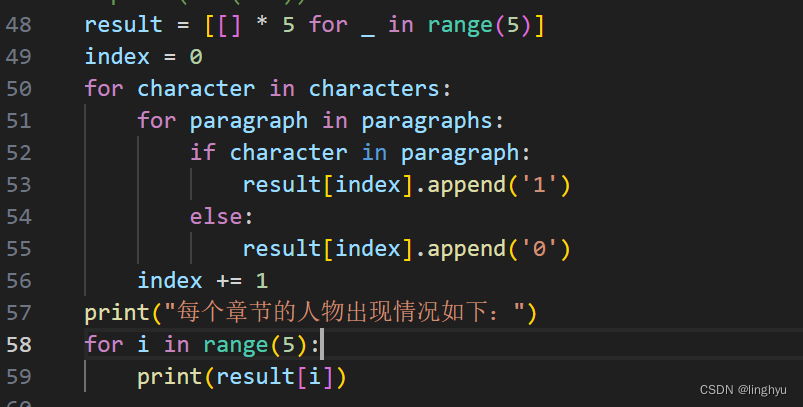
4、分析主人公以及其他相关人物之间的亲密度,两个人在同一个章节同时出现亲密度加1,得到统计结果。
我以上文提到的二维数组的结构进行分析,列表示章节,行表示人物,使用字典及一个嵌套循环进行遍历和记录
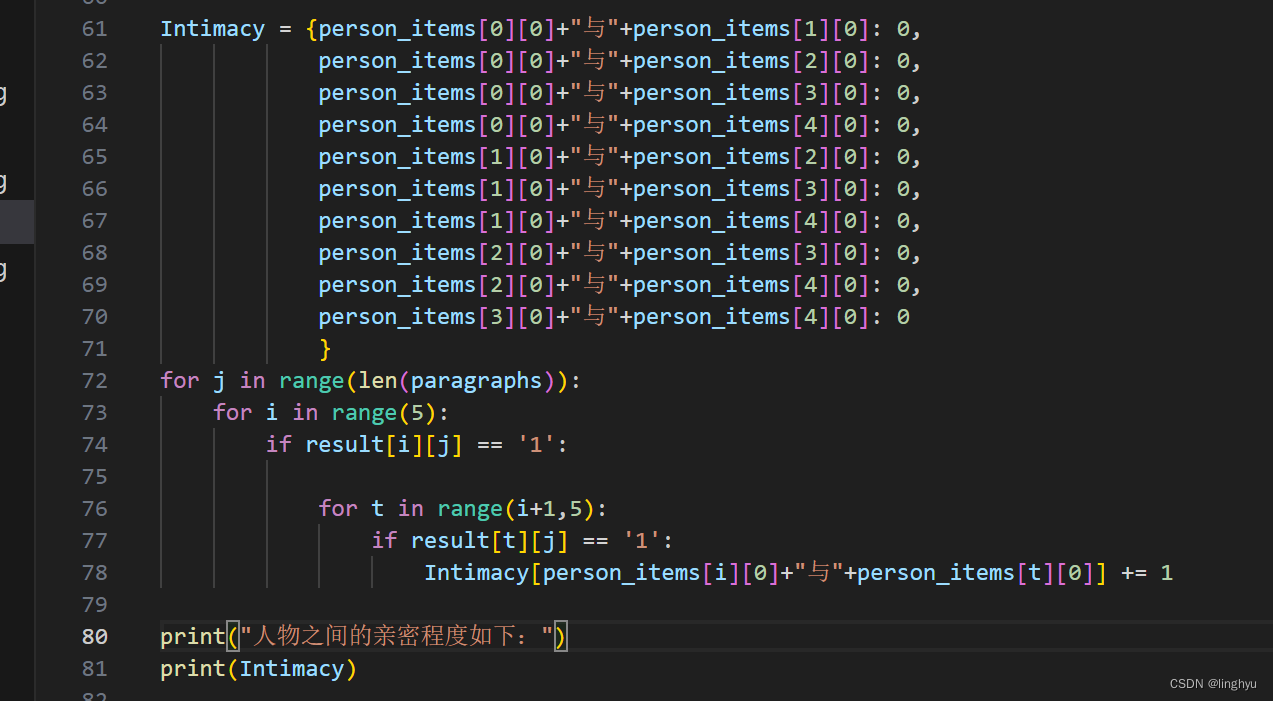
5、使用wordcloud来得到该中文小说的云图。


生成词云我放在了对词频信息清洗之前,生成总的中文词组的词云
以下是完整代码:
import jieba
from wordcloud import WordCloud
excludes = {"小姐","什么","一个","不是","怎么","姑娘","还是","知道","那个","喜欢","侯爷",
"这样","觉得","公主","时候","旌旗","所以","就是","郡主","这个","自己","看着",
"不知","没有","如今"}
with open('折花令.txt', 'r', encoding='utf-8') as f:
novel = f.read()
# 使用 jieba 进行分词
words = jieba.lcut(novel)
word_count = {}
for word in words:
if len(word) == 1:
continue
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
wordcloud = WordCloud(background_color="white", font_path="simsun.ttf", height=300, width = 400)
wordcloud.generate_from_frequencies(word_count)
wordcloud.to_file('task2_wordcloud.png')
word_items = list(word_count.items())
word_items.sort(key=lambda x:x[1], reverse=True)
for word in excludes: # 删掉excludes里的词
del word_count[word]
person_items = list(word_count.items())
person_items.sort(key=lambda x:x[1], reverse=True)
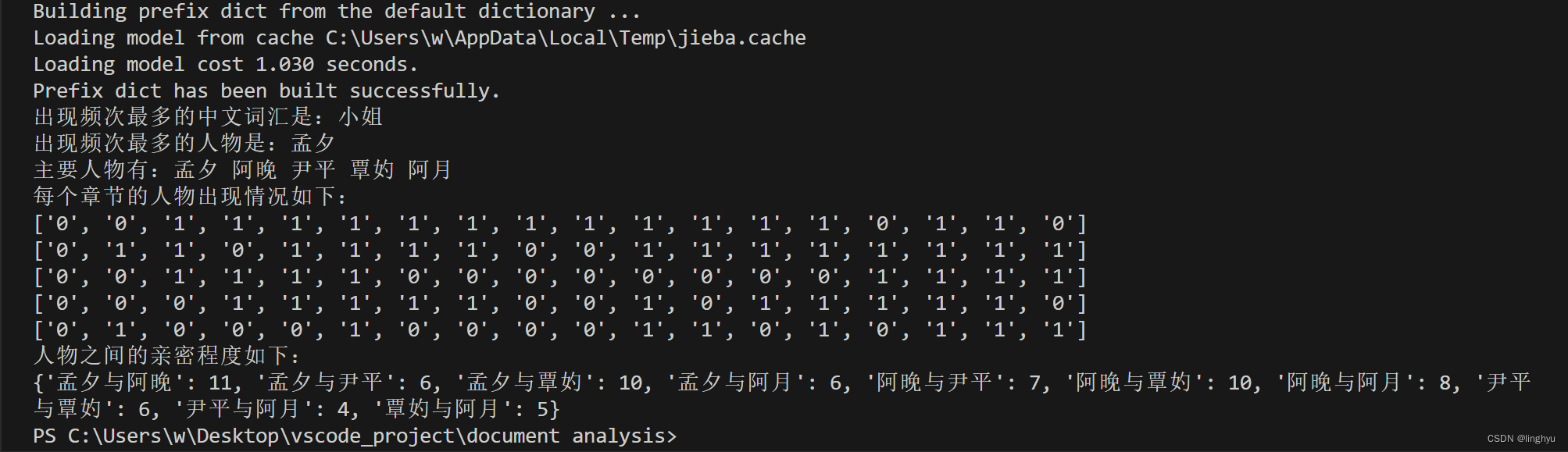
print("出现频次最多的中文词汇是:" + word_items[0][0])
print("出现频次最多的人物是:" + person_items[0][0])
characters = []
arr = ""
for i in range(5):
word, count = person_items[i]
characters.append(word)
arr += word + ' '
print ("主要人物有:" + arr)
# 以章节分割
paragraphs = novel.split("------------")
# print(len(txt))
result = [[] * 5 for _ in range(5)]
index = 0
for character in characters:
for paragraph in paragraphs:
if character in paragraph:
result[index].append('1')
else:
result[index].append('0')
index += 1
print("每个章节的人物出现情况如下:")
for i in range(5):
print(result[i])
Intimacy = {person_items[0][0]+"与"+person_items[1][0]: 0,
person_items[0][0]+"与"+person_items[2][0]: 0,
person_items[0][0]+"与"+person_items[3][0]: 0,
person_items[0][0]+"与"+person_items[4][0]: 0,
person_items[1][0]+"与"+person_items[2][0]: 0,
person_items[1][0]+"与"+person_items[3][0]: 0,
person_items[1][0]+"与"+person_items[4][0]: 0,
person_items[2][0]+"与"+person_items[3][0]: 0,
person_items[2][0]+"与"+person_items[4][0]: 0,
person_items[3][0]+"与"+person_items[4][0]: 0
}
for j in range(len(paragraphs)):
for i in range(5):
if result[i][j] == '1':
for t in range(i+1,5):
if result[t][j] == '1':
Intimacy[person_items[i][0]+"与"+person_items[t][0]] += 1
print("人物之间的亲密程度如下:")
print(Intimacy)
以下是代码执行结果:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









