






你的下一个微博罗伯特何必是罗伯特
这是一篇我在使用开源数据集(Twitter Emotion Dataset (kaggle.com))进行情绪识别的分类模型训练及将模型文件介入对话模型进行应用的过程记录。当通过训练得到了可以输入新样本预测的模型文件后,想到了或许可以使用模型文件对新样本的预测来做一个与微博罗伯特类似的评论机器人应该会很有趣。
在对话模型方面我调用的是国内近期开源的ChatGLM4-9B:THUDM/GLM-4: GLM-4 series: Open Multilingual Multimodal Chat LMs | 开源多语言多模态对话模型 (github.com)
训练分类模型的过程已发布在kaggle:Multi-classification emotion recognition task (kaggle.com)
当然,这个仓库仍有不足:
1、使用的数据集为英文社交媒体评论短文本,其标注质量以及引用在中文对话模型中有些欠佳。
2、模型文件的介入是在提示词工程中进行的,或许有资源进行系统的对话模型微调效果会更佳,目前是与以GLM自身情绪识别一起,进行最终结果的判定。
3、仍是一个需要手动执行的流程,如果加入自动抓取组件,理论上可以完成一个自动化评论机器人的个人账户本地部署。
可以的话,请为我的github点一些小小star,如果大家感兴趣的话,我会尽力补全仓库的这些不足的,谢谢大家。
一、绪论
(1)研究背景
随着互联网和社交媒体的迅速发展,人们在各种平台上发布的情绪表达日益增多。这些情绪表达不仅反映了个人的情感状态,也影响着公众意见的形成和社会舆论的走向。因此,对文本中的情绪进行分析成为了一个重要的研究领域。
文本的情绪分析是自然语言处理(NLP)领域的一个重要分支,旨在通过机器学习及深度学习技术对文本中所表达的情感进行自动分析和识别。随着社交媒体和在线评论的爆炸性增长,它们提供了大量的情感数据,为文本的情绪分析提供了数据基础,以供实现预测、理解用户的文本和行为偏好,对于舆情管控、商业决策、观点搜索等场景具有重要的应用价值[1]。
短文本情绪识别的多分类任务是一个在自然语言处理领域中日益受到关注的研究方向。随着互联网技术的发展,人们通过社交媒体、电子商务平台等渠道发布大量的短文本,这些文本往往包含丰富的情感信息,对于理解公众意见、监控舆情、进行市场分析等具有重要意义。因此,如何准确地从短文本中识别和分类这些情感成为了一个挑战性的问题。
(2)研究现状
文本情绪分析的研究可以追溯到2010年,当时的研究主要集中在情感信息抽取、分类以及检索与归纳等任务上[2]。随后,随着深度学习技术的兴起,基于深度学习的文本情绪分析方法逐渐成为主流,这些方法通过学习文本的深层特征,能够更准确地捕捉到文本的情绪倾向[3][4][5]。近年来,多模态情绪分析也开始受到关注,这种方法不仅考虑文本内容,还结合了图像、声音等其他模态的信息,以期获得更全面的情绪分析结果[6]。
尽管已有大量研究,但文本情绪分析仍面临一些挑战,如数据稀缺性、类别不平衡、领域依赖性和语言不平衡等问题[1]。此外,如何有效融合不同特征以提高情绪分类的准确率和识别复杂情绪的方法,例如(悲喜交加等)也是当前研究的几个热点[3][4][5]。
- 李然,林政,林海伦,等.文本情绪分析综述[J].计算机研究与发展,2018,55(01):30-52.
- 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(08):1834-1848.
- 李文亮,杨秋翔,秦权.多特征混合模型文本情感分析方法[J].计算机工程与应用,2021,57(19):205-213.
- 陶永才,张鑫倩,石磊,等.面向短文本情感分析的多特征融合方法研究[J].小型微型计算机系统,2020,41(06):1126-1132.
- 刘圣洁. 基于深度学习和多特征融合的文本情感分析研究[D].吉林大学,2022.DOI:10.27162/d.cnki.gjlin.2021.005915.
- Poria, S., Majumder, N., Hazarika, D., Cambria, E., Hussain, A., & Gelbukh, A.F. (2018). Multimodal Sentiment Analysis: Addressing Key Issues and Setting up Baselines. ArXiv, abs/1803.07427.
二、数据集
在数据集的构建中,我们需要优质的文本数据样本及准确的标签,文本的内容以及标签的多样性很大程度上影响着最终训练模型的准确性及鲁棒性。本次使用了开源数据集Twitter Emotion Dataset( Twitter Emotion Dataset (kaggle.com) ):在这个数据集中,每个条目都有一段从 Twitter 中提取的文本,并附有相应的标签,表示该消息所传达的主要情绪。这些情绪经过深思熟虑后被分为六个不同的类别:悲伤(0)、喜悦(1)、爱(2)、愤怒(3)、恐惧(4)和惊讶(5)。数据集拥有超过 416809 条 Twitter 消息,涵盖各种主题和用户人口统计。人工标注的标签确保了高质量的情感分类。推文来自不同地域,从全球视角捕捉社交媒体中的情绪。
三、初步数据预处理
(1)导入所需库并读出数据集文件
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
import string
import re
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
import csv
file_path = 'data/dataset.csv'
data = pd.read_csv(file_path)(2)数据查看及清洗
由上图可知,第一列序列为无用项,需要移除,即:
data.head() # 查看数据集头部
data.drop(columns=['Unnamed: 0'], inplace=True)
图1 数据集前五项
接下来检查是否有任何重复的样本
duplicated_texts = data[data.duplicated(subset='text', keep=False)].sort_values(by='text')
duplicated_texts[['text', 'label']] if not duplicated_texts.empty else "未发现重复文本."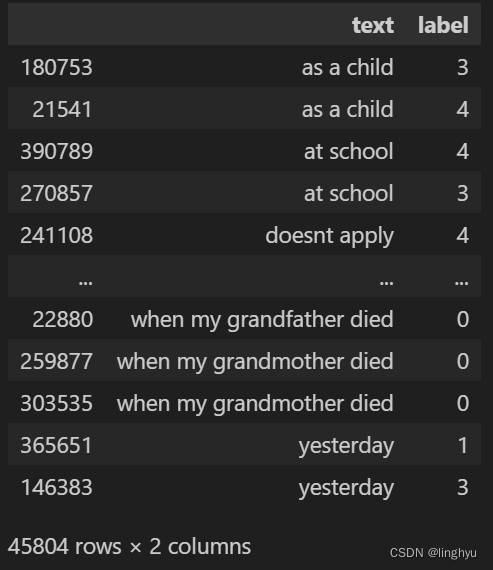
图2 查看重复文本
进行标记文本并展平单词列表,简单清洗并获取常用单词
def get_most_common_words(text_series, top_n=15):
# 标记文本并展平单词列表
words = ' '.join(text_series).lower().split()
# 删除标点符号
words = [''.join(char for char in word if char not in string.punctuation) for word in words]
# 删除空字符串
words = [word for word in words if word]
# 获取最常用的单词
counter = Counter(words)
most_common = counter.most_common(top_n)
return most_common
most_common_words = {}
for label in label_counts.index:
most_common_words[label] = get_most_common_words(data[data['label'] == label]['text'])
most_common_words
根据图3 所示,删除常用单词,可以看到常用单词都是英语文本中的常用介词,清除介词加强算法学习的针对性。
def clean_text(text):
text = re.sub(r'http\S+|www\S+|https\S+', '', text, flags=re.MULTILINE) # 清洗URLs
text = re.sub(r'\W', ' ', text)# 删除标点符号及数字
text = re.sub(r'\s+[a-zA-Z]\s+', ' ', text)# 清除单字符
text = re.sub(r'\s+', ' ', text, flags=re.I)# 清除重复空格
word_remove = ['i','feel','feeling','and','to','the','that','and','of','about','was','in']
for word in word_remove:
text = re.sub(r'\b'+word+r'\b', '', text, flags=re.I)
text = text.lower()# 统一小写
return text
data['cleaned_text'] = data['text'].apply(clean_text)
data[['text', 'cleaned_text']].head()
图4 常用介词清洗前后结果
(3)数据规约
查看各个标签样本的个数
# 每个标签样本的个数
label_counts = data['label'].value_counts()
plt.figure(figsize=(10, 6))
label_counts.plot(kind='bar')
plt.title('Distribution of Emotions in the Dataset')
plt.xlabel('Emotion Label')
plt.ylabel('Number of Occurrences')
plt.xticks(rotation=45)
plt.show()
# 显示每个标签的确切计数
label_counts
图5 标签样本的个数柱状图

图6 每个标签的确切计数
从图三可以看到,最高的标签数量来到了14万条,而最低的标签数量只有1.5万。两极分化的数据量容易使模型训练对某一类具有倾向性。因此我们对其进行删减规约,虽然减少了大部分数据量,但或许能够加速模型对各类标签的学习及分类,让每个标签数量趋于一致。并且保留原始数据量对后续训练算法做对比,比对是否有影响。
clear_label = [1,0,3,4,2]
for i in clear_label:
label_i_data = data[data['label'] == i]
# 如果标签i的行数大于 14972,则随机抽样 14972 行
if len(label_i_data) > 14972:
label_i_data = label_i_data.sample(n=len(label_i_data)-14972)
# 从数据集中删除标签i的其余行
# 将当前标签的数据追加到处理后的数据中
data = data.drop(label_i_data.index)
label_counts = data['label'].value_counts()
label_counts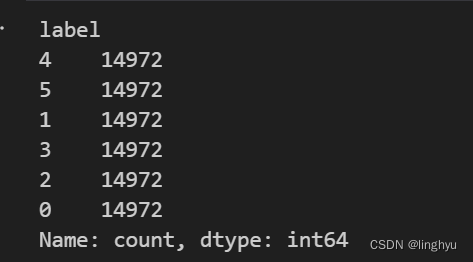
图7 处理后的各类标签数量
接下来查看各类标签中文本字数是否大致相同
# 计算每个文本的字数
data['word_count'] = data['text'].apply(lambda x: len(str(x).split()))
# 绘制每个标签的字数分布
plt.figure(figsize=(10, 6))
for label in label_counts.index:
subset = data[data['label'] == label]
plt.hist(subset['word_count'], bins=30, alpha=0.5, label=f'Emotion {label}')
plt.title('Distribution of Word Counts for Each Emotion')
plt.xlabel('Word Count')
plt.ylabel('Number of Texts')
plt.legend()
plt.show()以下是执行绘制的结果:
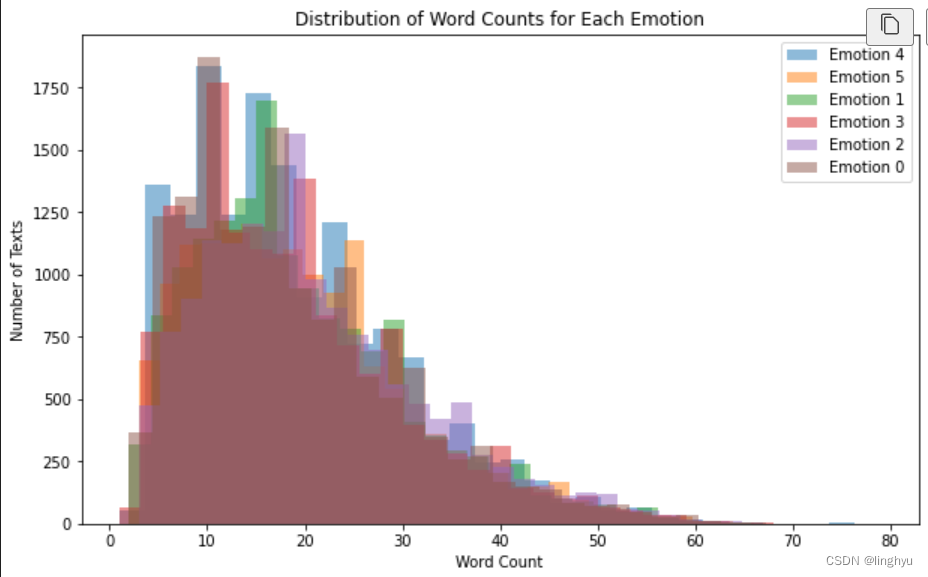
图 8 各类标签中文本字数
(4)数据集成
TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计方法。
TF-IDF假设词语的重要性与它在文本中的频率(TF)有关,但同时会考虑它在整个语料库中的普遍性(IDF)。TF-IDF倾向于过滤掉常见的词语,保留那些在特定文件中频繁出现但在整个语料库中不常见的词语,这些词语往往能够更好地代表该文件的内容。
因此,我们对原数据集进行训练、测试集进行分割,初始化TF-IDF vectorizer,进行拟合和转换为 TF-IDF 向量操作。并且保存训练文本,以便后续初始化预测新样本标签使用。
X_train, X_test, y_train, y_test = train_test_split(data['cleaned_text'],data['label'],test_size=0.2, random_state
=42) # 分割训练、测试集8:2
# 保存 X_train 到 CSV 文件,预测新样本使用
with open('data\X_train.csv', 'w', newline='') as f:
writer = csv.writer(f)
for text in X_train:
writer.writerow([text])
# 初始化 TF-IDF vectorizer
tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
# 对训练数据进行拟合和 Transform 为 TF-IDF 向量
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test) # 对测试数据X_test仅 Transform
X_train_tfidf.shape, X_test_tfidf.shape
图9 训练集及测试集的矩阵形状
四、多层感知器(MLP)模型训练
这里就只以调用MLP接口进行训练为例展示
数据预处理
将训练和测试数据从稀疏矩阵格式转换为NumPy数组,并且将数据和标签转换为PyTorch张量,以便用于模型训练。创建训练和测试数据集对象,以及创建数据加载器,以便在训练过程中按批次加载数据。
代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from joblib import dump
# 将数据转换为 NumPy 数组(如果它们是稀疏矩阵)
X_train_np = X_train_tfidf.toarray() if hasattr(X_train_tfidf, 'toarray') else X_train_tfidf.values
X_test_np = X_test_tfidf.toarray() if hasattr(X_test_tfidf, 'toarray') else X_test_tfidf.values
# 将 NumPy 数组转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train_np, dtype=torch.float32)
# 确保 y_train 也是一个 NumPy 数组
y_train_tensor = torch.tensor(y_train.values, dtype=torch.long)
X_test_tensor = torch.tensor(X_test_np, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.long)
# 创建 TensorDataset
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
# 创建 DataLoader
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)代码实现
定义一个简单的MLP模型,包括一个隐藏层和一个输出层。隐藏层使用ReLU激活函数。
class MLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x初始化模型,确定输入维度、隐藏层维度和输出维度,实例化模型。
input_dim = X_train_tensor.shape[1]
hidden_dim = 128
output_dim = 6
model = MLP(input_dim, hidden_dim, output_dim)移动模型到 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)训练模型
num_epochs = 50
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()在验证集上评估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()打印和保存最佳模型,并输出最佳准确率和对应的epoch
print(f"Epoch {epoch+1}/{num_epochs}, Accuracy: {100 * correct / total}%")
if correct / total > accs:
accs = correct / total
acc_epoch = epoch
model_file_path = 'model/MLP__model.joblib'
dump(model, model_file_path)
print(accs, acc_epoch)(5)算法结果
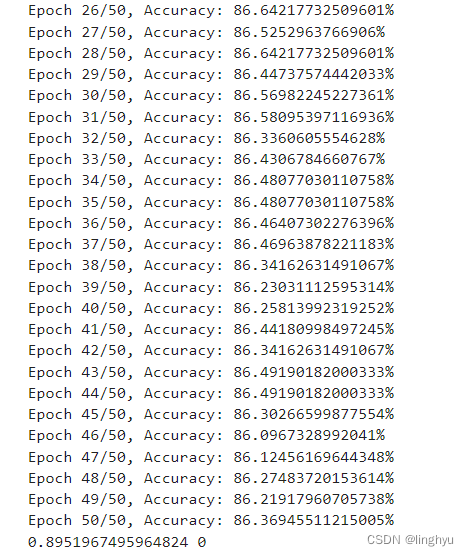
图10 模型训练过程
由上图的分析可知,在50次的迭代过程中,模型最终的最高准确率为89%
五、评论机器人拓展
(1)新样本预测
当使用数据集,经过数据预处理、数据挖掘及模型训练评估后,还能做些什么呢?在模型训练及评估过程中,我们使用 joblib 库的 dump() 保存了我们训练出来的最佳模型文件。

图11 保存的模型文件
利用模型文件,我们即可加载模型文件对自定义或输入的新英文文本样本进行情绪类型的分类。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from joblib import load
def forward_propagation(X, W, b):
Z = X.dot(W) + b
A = softmax(Z)
return A
W, b = load('trained_model11.joblib')
tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
X_tfidf = tfidf_vectorizer.fit_transform(data['cleaned_text'])
text = input("Enter English text: ")
X_text = tfidf_vectorizer.transform([text])
A = forward_propagation(X_text, W, b)
emotion_label = np.argmax(A)
emotion_labels = ['Sadness', 'Joy', 'Love', 'Anger', 'Fear', 'Surprise']
print("Predicted emotion:", emotion_labels[emotion_label])# 保存 X_train 到 CSV 文件,预测新样本使用
图12 新样本预测样例
(2)调用开源对话模型GLM4-9B进行拓展
仅仅是这样就ok了吗?是否能有一些应用呢?
数据集为推特的用户发言文本的情绪分类数据集,或许我们也可以利用开源对话模型,通过我们预测出来的发言文本的情绪分类标签来引导对话模型对发言的内容进行评论回复。当文本表达正面情绪,例如开心、惊喜时,让对话模型给予必要的认可和赞美;在遇到负面情绪时,例如愤怒、惊恐、伤心,让对话模型适当的给予安慰、关心和开导。
对话模型选用了近期开源的GLM4-9B,
在硬件配置方面,GLM4-9B 需要较高的计算能力和存储空间,我在尝试本地部署运行爆显存后,最后使用了openai的接口进行调用。
以下部分代码:
from openai import OpenAI
from utils import *
def init_staus():
client = OpenAI(
api_key="xxxxx",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
messages=[
{"role": "system", "content": "你的名字是Dave,你是一个具有38年心理疏导经验的心理学家,你深知与人对话时根据他人言语表达的情感,与他共情可以更好的进行沟通。当沟通对象表达正面情绪,例如开心、惊喜时,给予必要的认可和赞美;在遇到负面情绪时,例如愤怒、惊恐、伤心,请适当的给予安慰、关心和开导。"},
{"role": "user", "content": "请你作为心理学家,把我当成你的沟通对象,根据我给出的内容以及预测的情绪标签与我进行沟通,并且不需要对我的情绪进行评价,只需要以正常的对话和我沟通。并且需要注意的是,预测的情绪标签不一定准确,仅供参考,并且在对话过程中不要提及情绪标签。你听懂了吗?"},
{"role": "assistant", "content": "听懂了,请告诉我你想说的内容和预测的情绪标签吧。预测的情绪标签我也会自行对内容进行情感分析,不确定时以我的情感分析结果为准,并且对话中我不会提及情绪标签。"},
]
return client, messages
def get_answer(client, messages, inputs, max_length, temperature, top_p, staus):
user_input = inputs
if staus == 0:
example_text = translate(user_input) # Chinese to English
lable = predict(example_text)
# emo_input = user_input
emo_input = "内容:" + user_input +"。情绪标签:" + lable
else:
emo_input = user_input
return answer, messages
通过向 GLM4 进行prompt的设定和引导,让他模仿为一个具有38年心理疏导经验的心理学家,并且根据原文信息及我们使用我们训练的模型文件进行预测的情绪分类标签,加上他自身的对文本情绪分析的能力达到进行稳定输出的结果。
(3)streamlit交互界面的构建
在交互界面上,我选用了streamlit框架进行构建。
Streamlit是一款开源的Python库,旨在帮助数据科学家和机器学习工程师快速创建简单的web应用程序。用户只需编写简单的Python脚本,Streamlit就能自动生成并展示用户界面。此外,Streamlit还支持多种数据可视化库,如Matplotlib、Altair和Plotly等,方便用户展示数据和分析结果。
以下是部分代码:
if 'text_area_content' not in st.session_state:
st.session_state.text_area_content = ""
prompt = st.text_area(' ', st.session_state.text_area_content, help = "Are you happy today?", height = 100)
st.session_state.text_area_content = prompt
send_text = st.button("send to Dave.", key = "send_prompt", help = "say hi to Dave?")
st.sidebar.subheader('Parameters')
max_length = st.sidebar.slider("Max Length", min_value = 1024, max_value = 8192, value = 2048, step = 1024, help = "Prompt Max Length")
temperature = st.sidebar.slider("Temperature", min_value = 0.10, max_value = 1.00, value = 0.95, step = 0.05)
top_p = st.sidebar.slider("Top_p", min_value = 0.1, max_value = 1.0, value = 0.7, step = 0.1)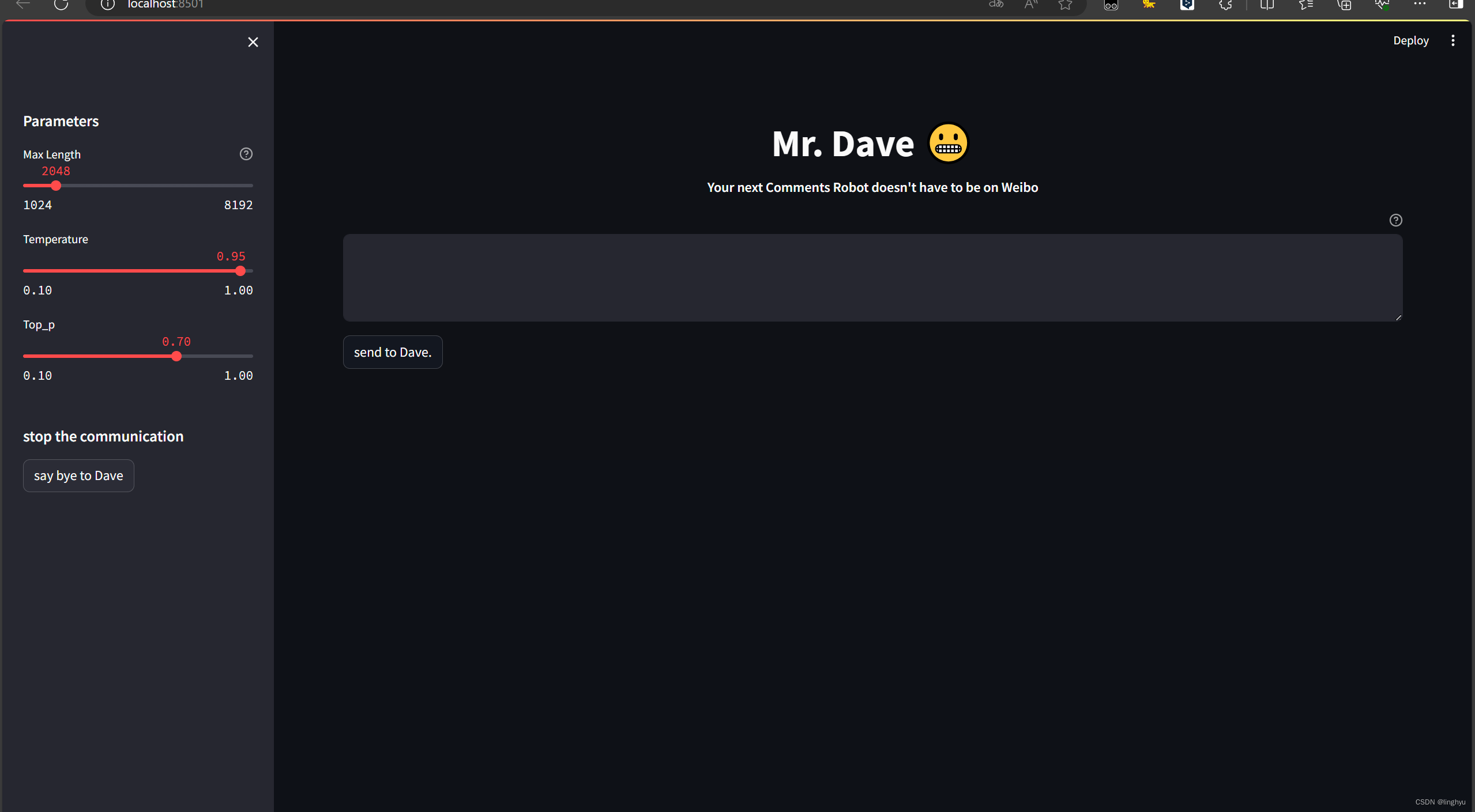
图13 Streamlit交互界面演示
(4)运行结果演示
负面情绪演示:我不太聪明,无法真正感受到我的音乐,对小事没有热情,我不确定我是否会去做。

图14 负面情绪交互界面演示

图15 负面情绪的终端信息
正面情绪演示:今天我真的太开心了,这真是我今年最棒的一天,真的令人感到开心。

图16 正面情绪及多轮对话演示















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









