







2021年9月25日,由“科创中国”未来网络专业科技服务团指导,江苏省未来网络创新研究院、网络通信与安全紫金山实验室联合主办、SDNLAB社区承办的2021中国智能网卡研讨会中,多家机构谈到了智能网卡的网络加速实现,我们对此进行整理,以飨读者。
网络加速的起源
传统数据中心基于冯诺依曼架构,所有的数据都需要送到CPU进行处理。随着数据中心的高速发展,摩尔定律逐渐失效,CPU的增长速度无法满足数据的爆发式增长,CPU的处理速率已经不能满足数据处理的要求。
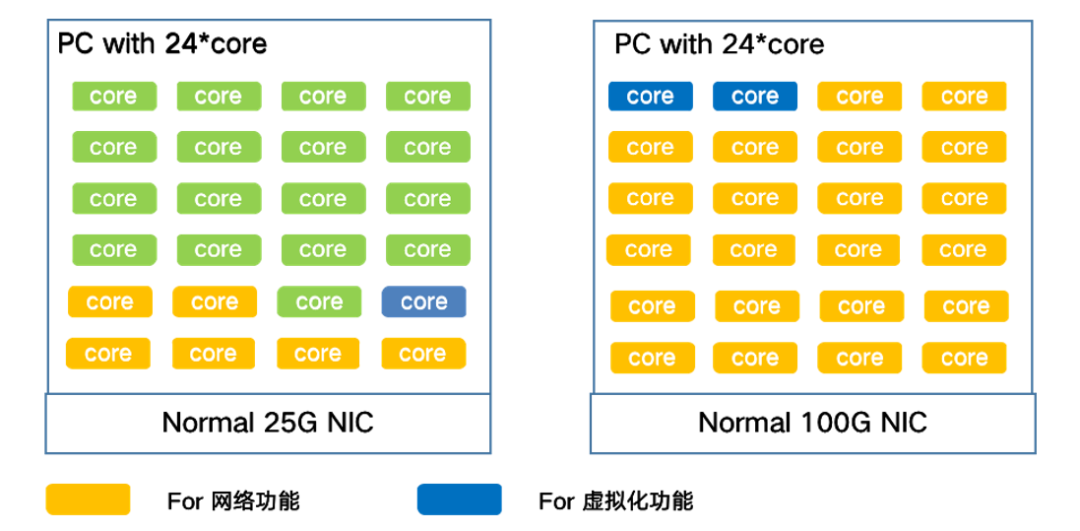
图1:通用服务器处理网络负载的消耗情况
以24核计算型服务器为例,网络功能占用6个core,虚拟化功能占用1个core,可用于VM的core数量为17个,可用CPU资源比例为70%。当网卡升级到100G时,CPU资源基本都被占用,算力资源基本不可用。
计算架构从以CPU为中心的Onload模式,向以数据为中心的Offload模式转变。以数据为中心的计算架构成为了趋势。以数据为中心的模式即数据在哪里,计算就部署在哪里。当数据在存储资源上,对数据的计算就在存储上执行。当数据在网络中流动时,对数据的处理就在网络上执行。通过架构的演进,典型的通信延时可以从30-40微秒,缩短为3-4微秒。网络计算和智能网卡/DPU成为数据中心计算架构的核心。
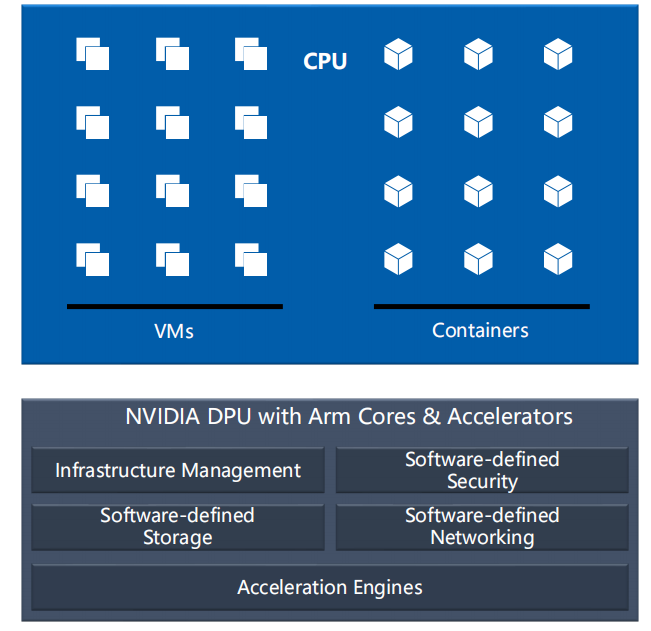
图2:NVIDIA DPU功能框架
智能网卡/DPU通过集成多个面向不同应用的加速引擎,进行数据平面卸载,通过内嵌的ARM处理器或者其他协处理器进行控制平面的卸载。
在网络功能卸载方面,硬件替代CPU完成专业设备NFV后处理逻辑,实现硬件加速。同时,网络功能卸载将观察点从硬件交换机延伸到主机侧,实现网络端到端
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









