







【大模型】(记一面试题)使用Streamlit和Ollama构建PDF文件处理与聊天机器人应用
我在找工作的过程中,遇到一个面试题:搭建一个简易的利用大型 LLM 和 RAG 来实现用户与PDF文件的自然语言交互。
参考链接:https://medium.com/the-ai-forum/rag-on-complex-pdf-using-llamaparse-langchain-and-groq-5b132bd1f9f3
做题准备
在人工智能的学习路上,各种认知是拓宽了不少,但是实际代码编写以及项目落地迟迟没有实施,正好,可以通过这个面试题,考验自己的实操能力。根据题目给予的参考资料,以及通过搜索引擎来搜索资料一步一步进行实现,并在此做一个学习记录。
环境准备
首先,准备了一些核心的开发环境库:
- Streamlit
- Ollama
- LlamaParse
- LlamaIndex
- Python的
dotenv库
pip install streamlit ollama llama-parse llama-index python-dotenv
代码结构
整个应用程序的代码结构如下:
- 导入所需的库
- 加载环境变量
- 定义一个生成器函数来处理用户输入
- 设置Streamlit的页面标题和文件上传器
- 初始化会话状态
- 显示聊天消息
- 处理用户输入并生成响应
- 处理PDF文件并构建向量索引
1. 导入所需的库
首先,需要导入所需的库:
导入必要的库
2. 加载环境变量
使用dotenv库加载环境变量,以便在代码中使用:
加载环境变量
3. 定义生成器函数
我们定义一个生成器函数来处理用户输入,并使用Ollama模型生成响应:
定义生成器函数
初始化Ollama模型
设置查询引擎
迭代生成响应
4. 设置Streamlit的页面标题和文件上传器
使用Streamlit设置页面标题和文件上传器,让用户可以上传PDF文件:
设置Streamlit页面标题
设置文件上传器
5. 初始化会话状态
初始化会话状态,用于存储用户消息:
初始化会话状态
6. 显示聊天消息
遍历并显示存储在会话状态中的消息:
遍历会话状态中的消息
显示每条消息
7. 处理用户输入并生成响应
处理用户输入的消息,生成并显示模型的响应:
如果有新的用户输入
保存用户消息
显示用户消息
生成模型响应
保存并显示模型响应
8. 处理PDF文件并构建向量索引
处理上传的PDF文件,并使用LlamaParse解析内容,构建向量索引:
如果有上传的PDF文件
读取文件内容
使用LlamaParse解析文件
构建向量索引
保存向量索引到会话状态
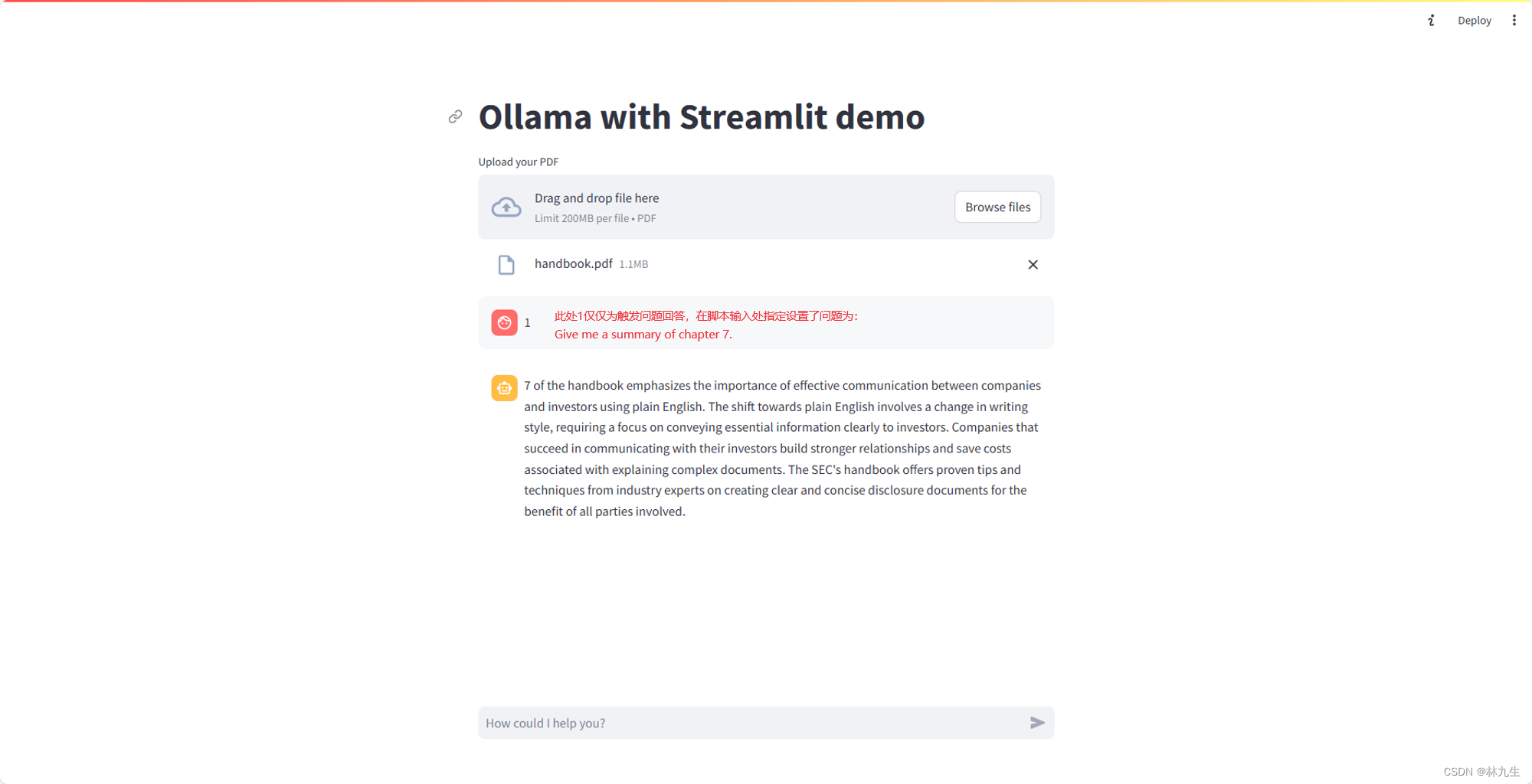
初步实现效果















 6093
6093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









