



 本文详细介绍了Presto查询引擎的工作流程,包括查询生命周期、语法解析和语义校验、逻辑执行计划生成、分布式执行计划的构建以及Stage调度策略。重点讨论了Presto如何将SQL语句转化为执行计划,如何进行Stage划分,以及Stage调度的核心类和策略。此外,还分析了Split的计算、Node选择和Task计算的过程,揭示了Presto在大数据查询中的高效处理机制。
本文详细介绍了Presto查询引擎的工作流程,包括查询生命周期、语法解析和语义校验、逻辑执行计划生成、分布式执行计划的构建以及Stage调度策略。重点讨论了Presto如何将SQL语句转化为执行计划,如何进行Stage划分,以及Stage调度的核心类和策略。此外,还分析了Split的计算、Node选择和Task计算的过程,揭示了Presto在大数据查询中的高效处理机制。
1、Query生命周期
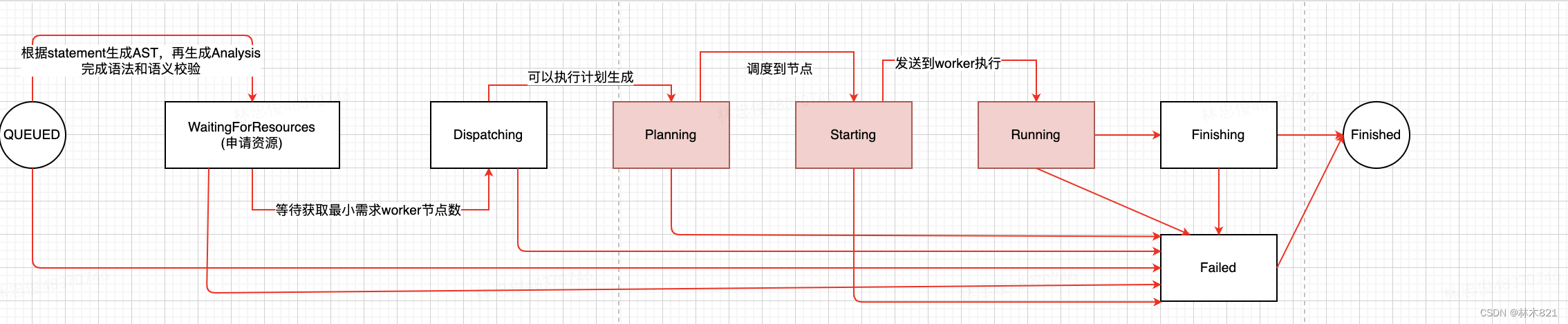
图所示:在QUEUED阶段,会完成Statement的语法解析和语义判断,生成Analysis对象。在Planning阶段,会根据Analysis生成执行计划;让调度到满足的节点后会将任务发送到Worker上进行执行,从而进入到Running阶段。接下来的第二章节会详细的描述Statement是如何生成物理执行在worker上进行执行的。
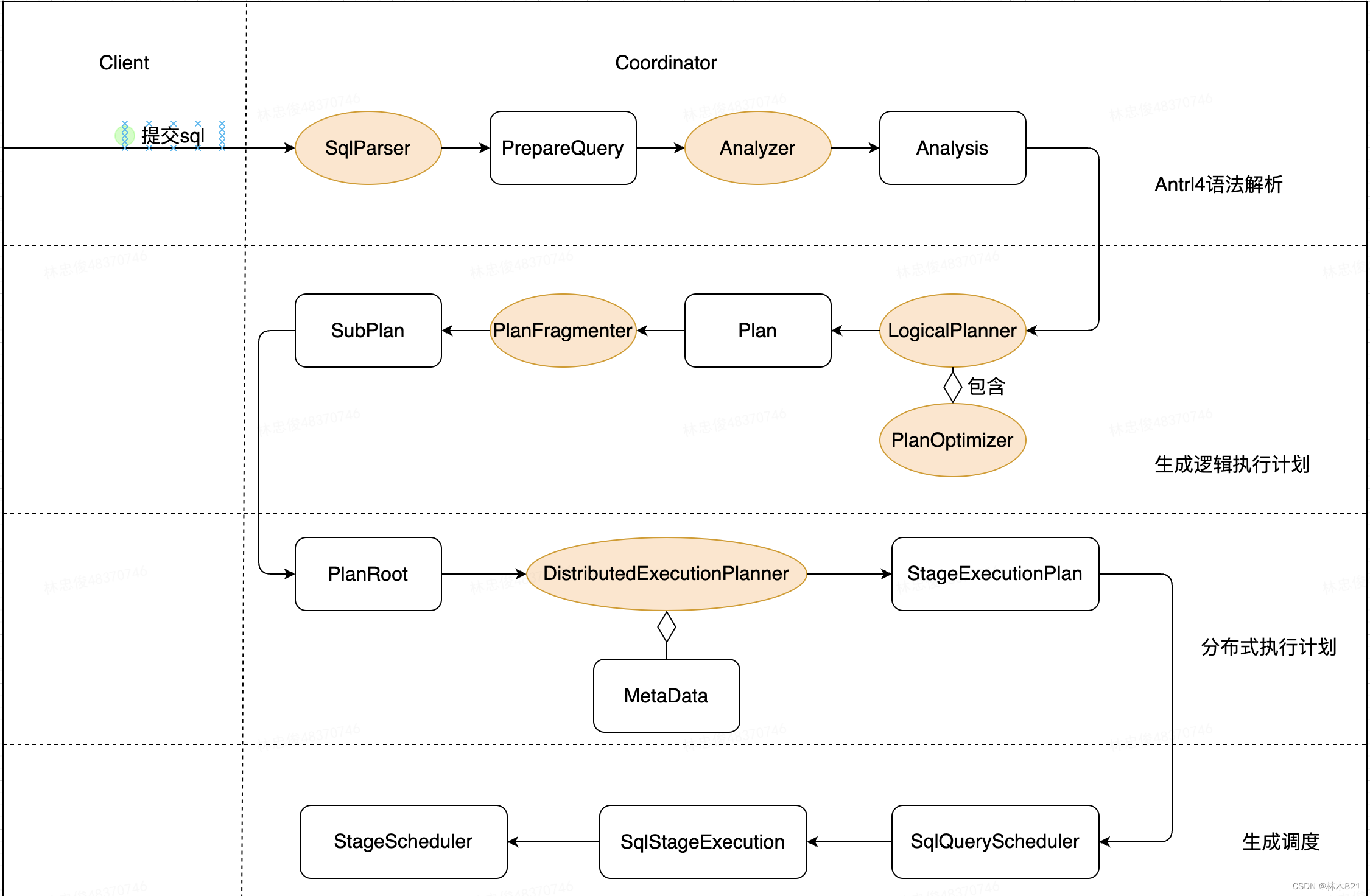
2、语法解析+语义校验
Presto的语法规则使用Antrl4来描述,收到SQL后会按照Antrl4的模式来进行词法解析和语法解析。此阶段发生在Query生命周期的初始化阶段,在经过语法解析和语义校验成功后,才会为Query分配资源。
2.1 时序图
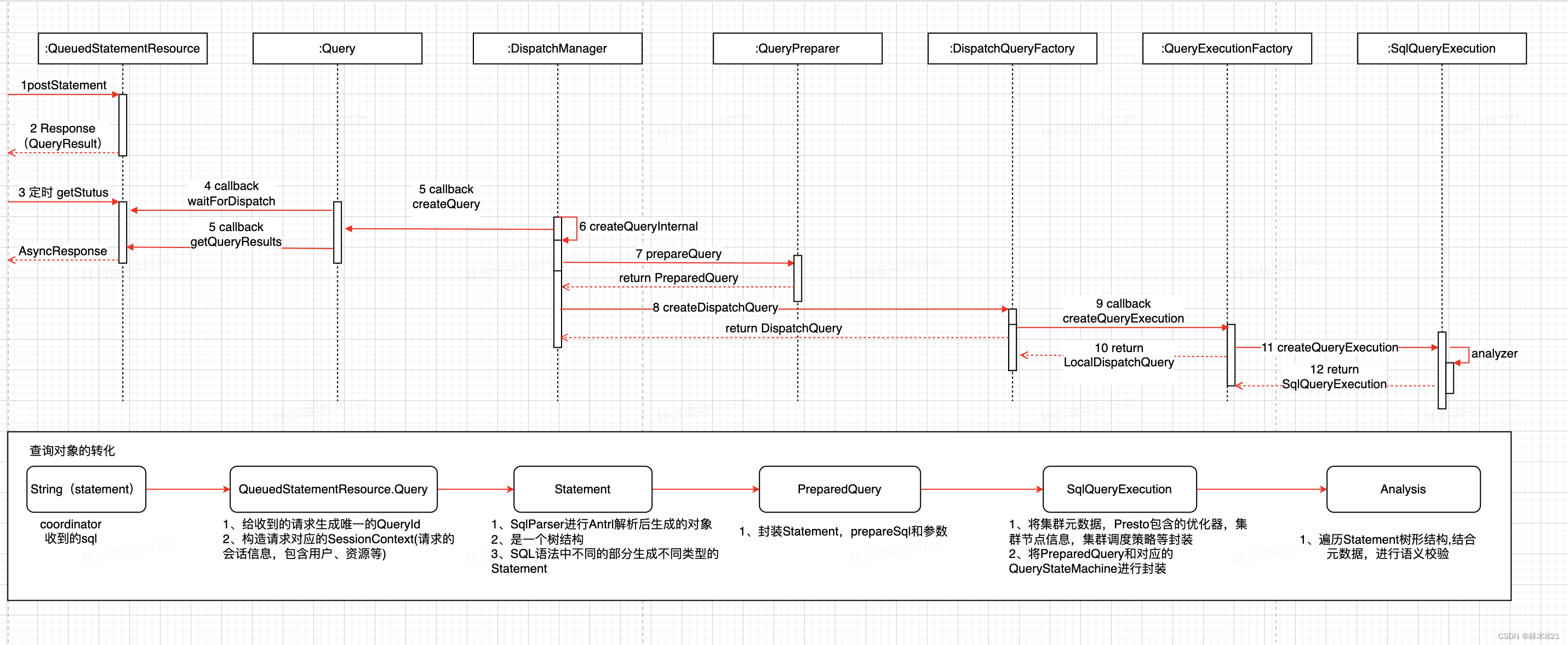
-
sql通过client使用restful协议提交到coordinator。QueuedStatementResource类负责接收请求,并将请求封装成Query对象放入到查询队列中。
-
QueuedStatementResource绑定了DispatchManager对象来调度队列中的Query对象,并将其进行Sql解析转化成PreparQuery对象
-
DisPatchFactory会将PrepareQuery转换成SqlQueryExecution对象放入到待执行的队列中,在构造SqlQueryExecution对象时会调用Analyzer来对其进行语法解析,构造成sql对应的语法树,同时生成Analysis对象。
-
这一步完成后,请求的后续调度会从QueuedStatementResource转移到ExecutionStatementResource中。SqlQueryExecution会维护一个statemachine,描述其当前的状态。
-
ExecutionStatementResource中的SqlQueryManager来负责处理请求的后续操作,它会调用SqlQueryExecution自身的start方法来实现后续的分布式执行计划生成和Stage中(task、split)的调度。
-
具体antlr4语法解析sql的知识这里不进行描述。
2.2 核心功能分析
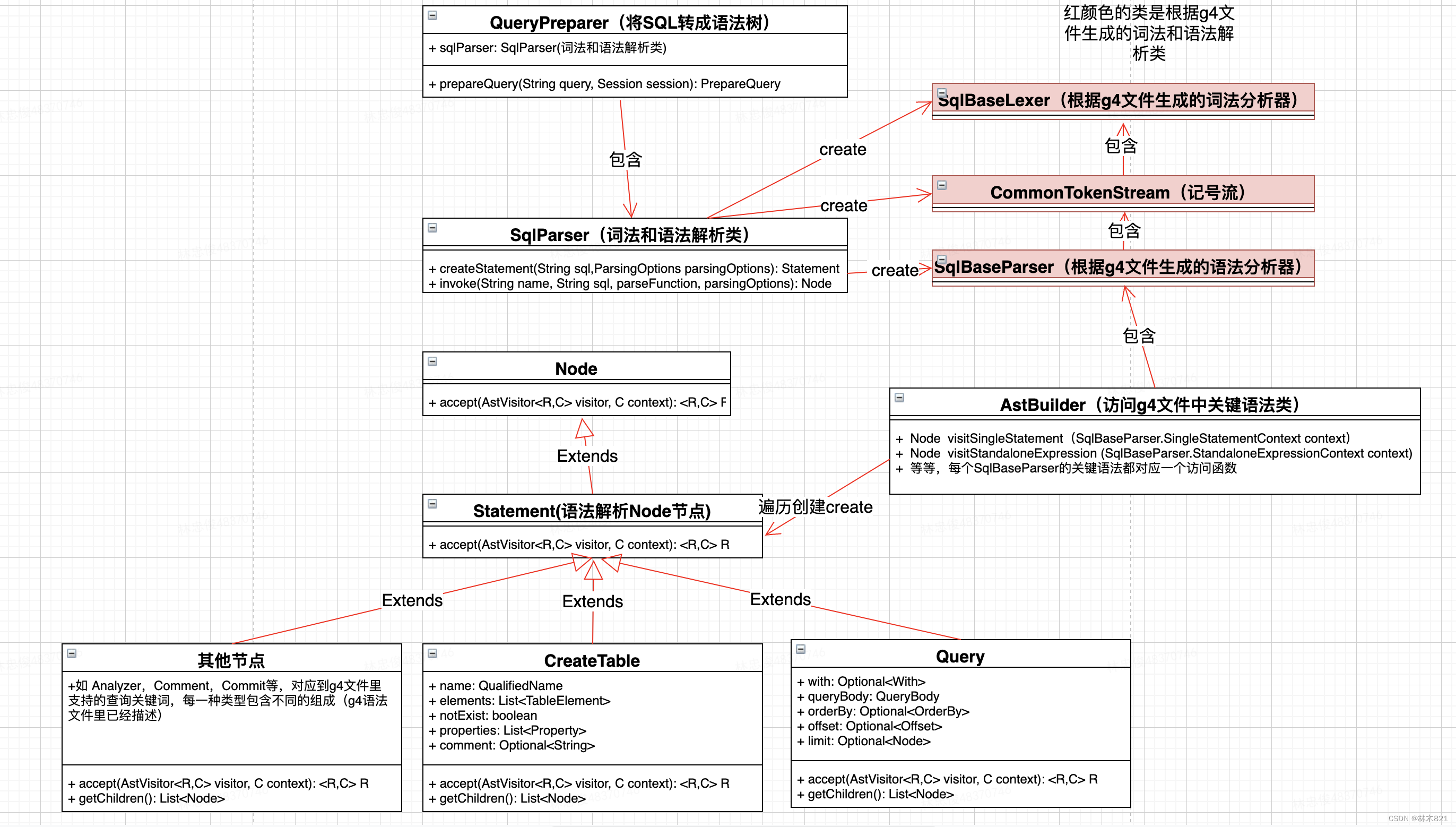
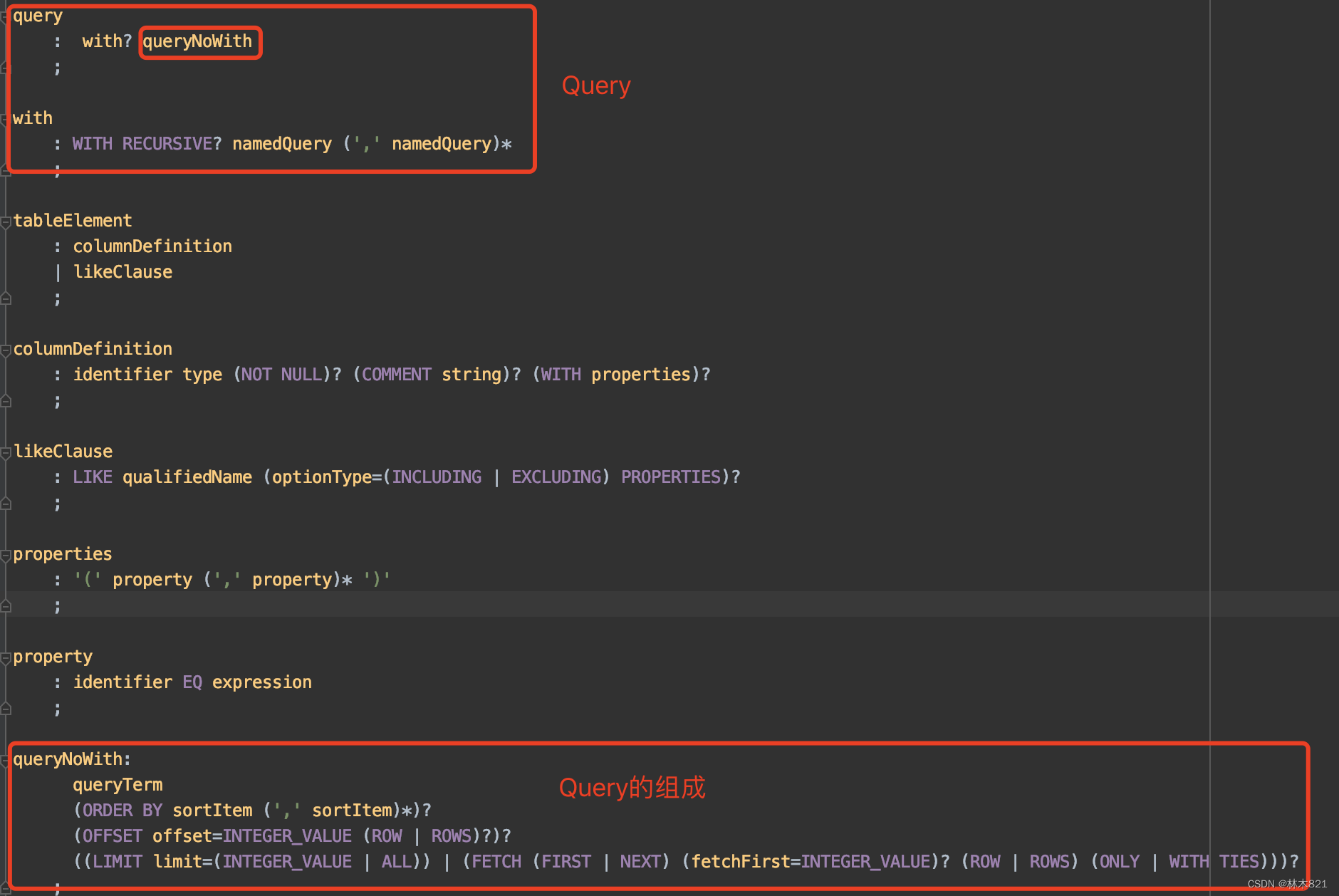
功能: 将输入的查询statement按照Antlr语法树的格式进行解析,将statement字符串先进行分词再按照语法构造出g4文件中描述的各个节点,按照规则构造成一个Node树。此步骤的实现过程要和Antlr的解析原理配合理解。
查询类的Statement是Query,在经过词法分词,语法解析后会生成对应的statement如下:
| Query类型的Statement | g4语法文件 |
|---|---|
| |
|

2.2.2 SqlQueryExecution
Presto中使用SqlQueryExecutionFactory来创建SqlQueryExecution对象。SqlQueryExecution对象主要是构造Sql查询运行的上下文信息,如集群元数据,数据源管理类,集群节点管理类。在构建次对象时Query仍然处于状态机的Queued阶段。
2.2.2.1 类的成员
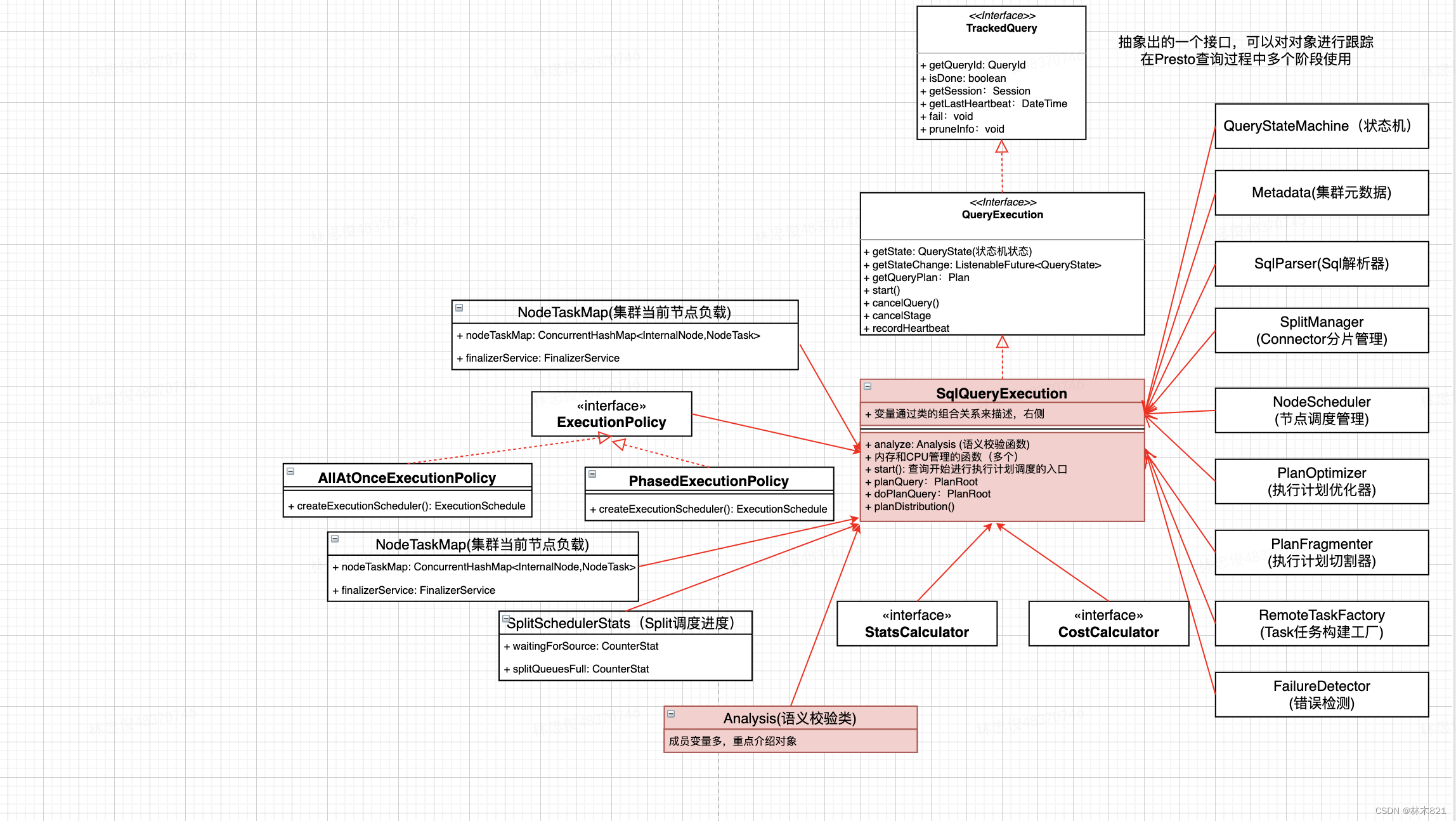
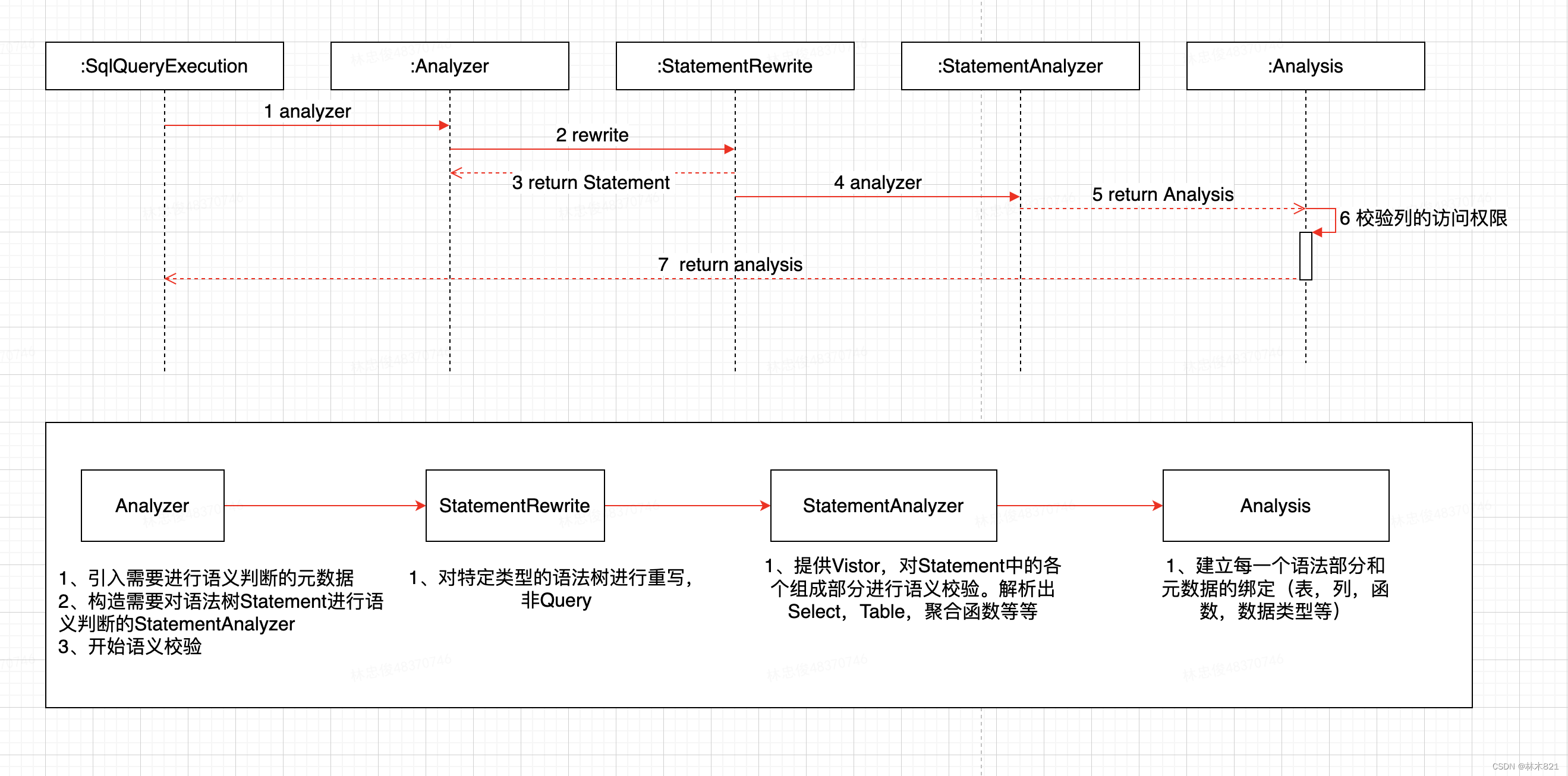
2.2.2.2 功能-sql语义校验(Analysis)
在构造SqlQueryExecution对象时,会对收到的PrepareQuery中的Statement进行语义的校验。具体校验的流程是:
3、逻辑执行计划
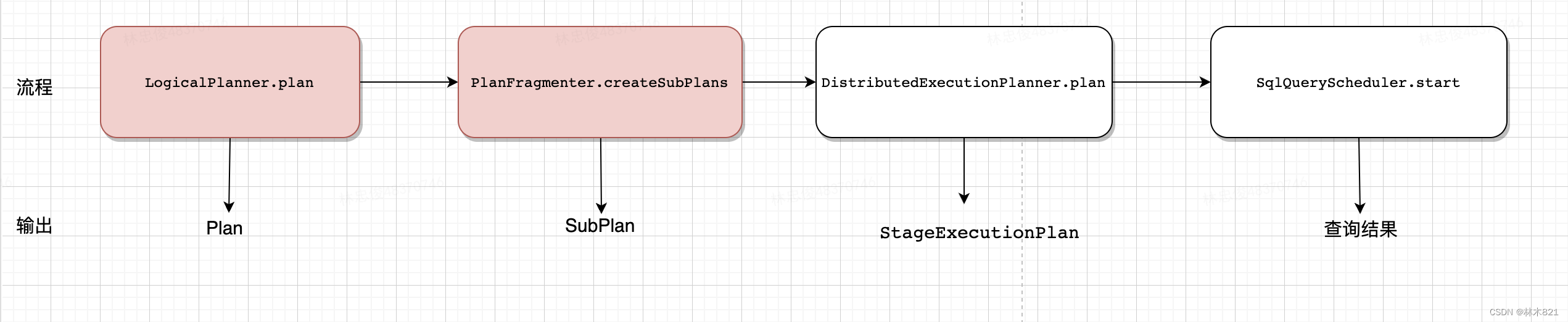
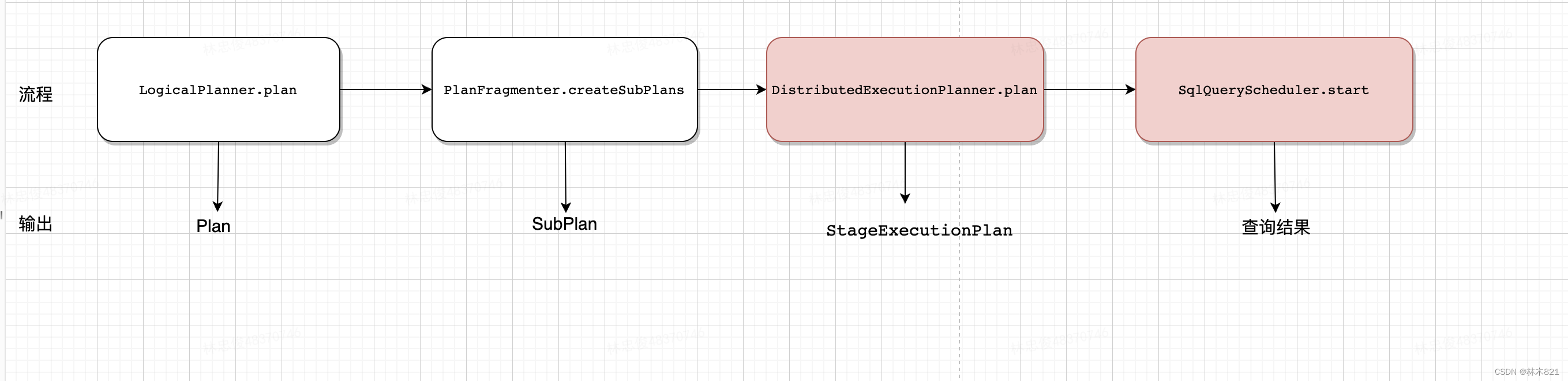
在生成执行计划和和调度时,要依赖 LogicalPlanner,PlanFragmenter,DistributedExecutionPlanner 和 SqlQueryScheduler 这几个类,下面是这几个类的简要介绍:
-
LogicalPlanner:负责生成逻辑执行计划(包含逻辑执行计划优化PlanOptimizers);
-
PlanFragmenter:将 LogicalPlanner 生成的逻辑执行计划,拆分为多个子计划;
-
DistributedExecutionPlanner:将 PlanFragmenter 拆分好的子计划,进一步拆分成可以分配到不同 Worker 节点上运行的 Stage;
-
SqlQueryScheduler:将 Stage 调度到不同的 Worker 节点上运行;
3.1 生成逻辑执行计划Plan的UML
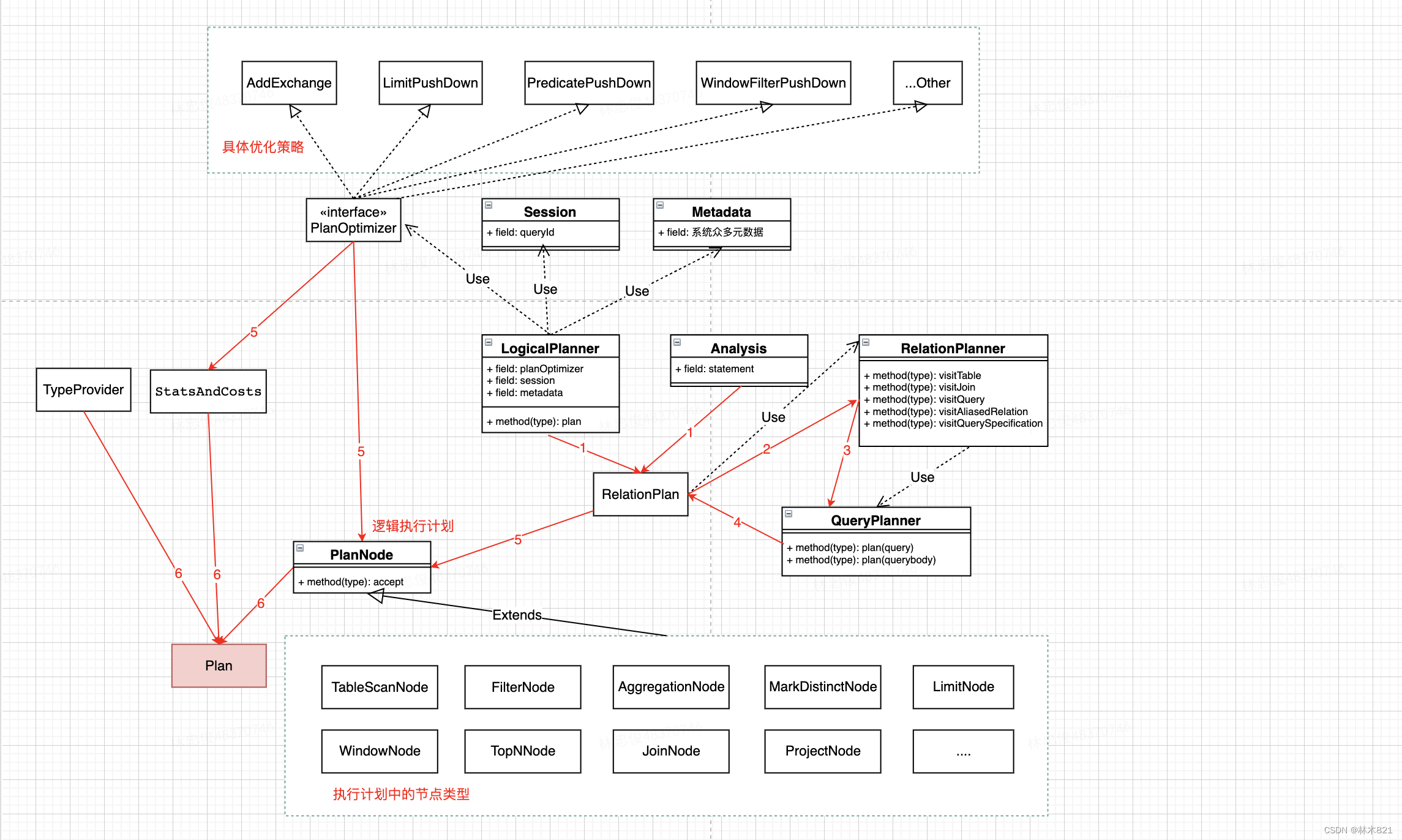
3.2 PlanNode介绍
这个部分的功能是:在语法解析后,将查询转化成逻辑计划。在analysis中,已经将sql中的(select信息,from-table表信息,where信息,聚合函数信息,limit信息,order by, group by等等)解析出来,将sql中的不同部分映射到对应的PlanNode即可(在RelationPlan使用visit模式来生成PlanNode)。在查询中核心的PlanNode枚举如下:
| 节点名称 | 含义 |
|---|---|
| AggregationNode | 聚合操作的节点,有Final、partial、single三种,表示最终聚合、局部聚合和单点聚合,在执行计划优化前,聚合类型都是单点聚合,在优化器中会拆成局部聚合和最终聚合。 |
| ExchangeNode | 逻辑执行计划中,不同Stage之间交换数据的节点 |
| FilterNode | 进行Filter过滤操作的节点 |
| JoinNode | 执行Join操作的节点 |
| LimitNode | 执行limit操作的节点 |
| MarkDistinctNode | 处理count distinct |
| OutputNode | 输出Node |
| RemoteSourceNode | 类似于ExchangeNode,在分布式执行计划中,不同Stage之间交换数据的节点 |
| ProjectNode | 将下层的节点输出列映射成上层节点 例如:select a + 1 from b将TableScanNode的a列 + 1 映射到OutputNode |
| SampleNode | 抽样函数Node |
| RowNumberNode | 处理窗函数RowNumber |
| SortNode | 排序Node |
| TableScanNode | 读取表的数据 |
| TopNNode | order by ... limit 会使用效率更高的TopNNode |
| UnionNode | 处理Union操作 |
| WindowNode | 处理窗口函数 |
| ... |
RelationPlan在构造PlanNode时,其的visit操作如下。其中QueryPlanner负责解析select,order by,limit等部分的PlanNode。
| visit操作 | 作用 | 核心处理 |
|---|---|---|
| visitTable | 生成TableScanNode | 执行计划的核心在RelationPlanner的visitQuerySpecification中----->QueryPlanner的plan(QuerySpecification node)
|
| visitAliasedRelation | 处理有别名的Relation | |
| visitSampledRelation | 添加一个SampleNode,主要处理抽样函数 | |
| visitJoin | 根据不同的join类型,生成不同的节点结构,一般来说是将左右两边生成对应的queryPlan,然后左右各添加一个ProjectNode,中间添加一个JoinNode相连,让上层添加一个FilterNode,FilterNode为join条件 | |
| visitQuery | 使用QueryPlanner处理Query,并返回生成的执行计划。 | |
| visitQuerySpecification | 使用QueryPlanner处理QueryBody,并返回生成的执行计划 | |
| visitUnion | 处理union操作 |
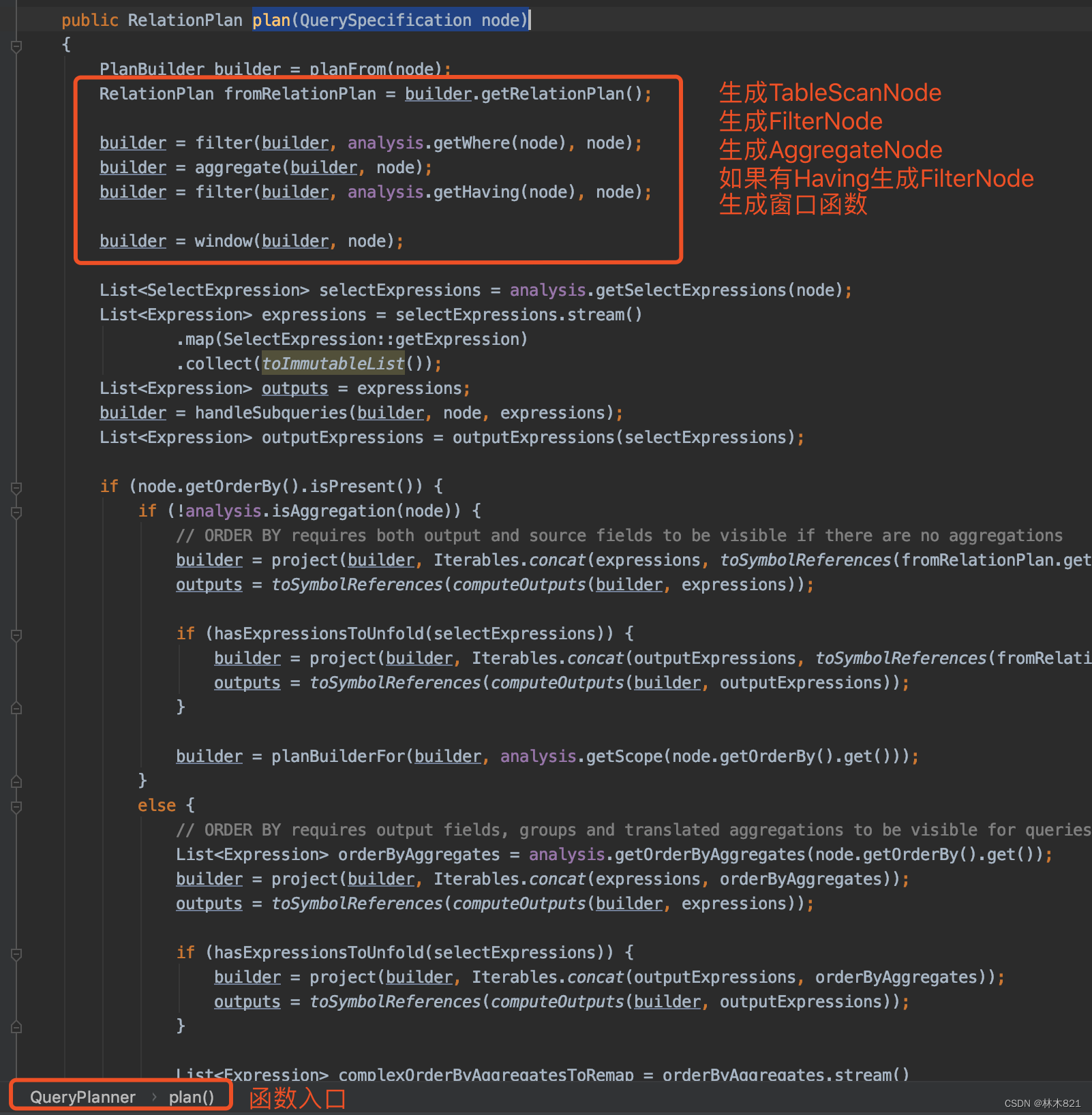
总结这一步骤的流程如下:
-
使用vistor模式遍历完analysis中各个部分后,进行语义判断;如果校验成功则可以生成逻辑执行计划;否则会抛出异常,查询结束。visit的类型和生成的PlanNode类型如上表格枚举。
-
在生成逻辑执行计划后,会依次应用PlanOptimizer中的各个规则(规则有优先级顺序)来优化执行计划。在优化过程中,优化器会在 Plan 中插入 Exchange 结点。之后的 PlanFragmenter 会根据这些 Exchange 结点将 Plan 切分成 SubPlan。
-
优化完成后,最终生成Plan对象。
3.3 PlanOptimizer的规则
| 优化策略 | 作用 |
|---|---|
| AddExchanges | 委托在StatsRecordingPlanOptimizer优化器中进行优化。优化的策略如下:
|
| CanonicalizeExpressions | 将执行计划中的表达式标准化,比如将is not null 改写为not(is null),将if语句改写为case when |
| CountConstantOptimizer | 将count(a)改写为count(*)提高不同数据源的兼容性 |
| HashGenerationOptimizer | 提前进行hash计算 |
| IndexJoinOptimizer | 将Join优化为IndexJoin,获取Join表的索引,提升速度 |
| IterativeOptimizer LimitPushDown | limit条件下推,减小下层节点的数据量 |
| MetadataQueryOptimizer | 将对表的分区字段进行的聚合操作,改写为针对表元数据的查询,减少读取表的操作 |
| PickLayout PredicatePushDown | 谓词(过滤条件)下推,减下下层节点的数据量 |
| ProjectionPushDown | ProjectNode下推,减少Union节点的数据量 |
| PruneUnreferencedOutputs | 去除ProjectNodeP不在最终输出中的列,减小计算量 |
| PruneRedundantProjections | 去除多余的projectNode,如果上下节点全都直接映射,则去掉该层projectNode |
| SetFlatteningOptimizer | 合并能够合并的Union语句 |
| SimplifyExpressions | 对执行计划中涉及到的表达式进行化简和优化 |
| UnaliasSymbolReferences | 去除执行计划中projectNode无意义的映射,如果列直接相对而没有带表达式则直接映射到上层节点 |
| WindowFilterPushDown | 窗口函数过滤条件下推 |
3.3.1 增加Exchangenode的规则
如上图表格中AddExchanges的优化策略的描述,在聚合,窗口函数,聚合等情况下,设计到数据计算的节点会增加ExchangeNode。
举一个样例SQL:select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10。 它对应的逻辑执行计划如下:
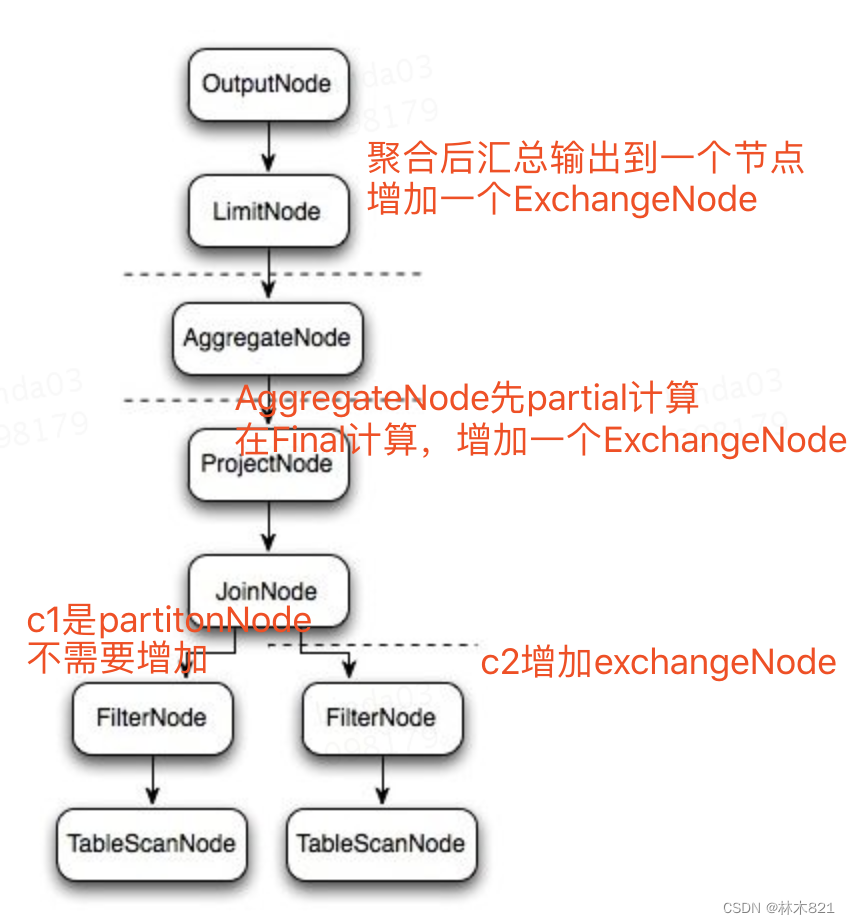
3.4 逻辑执行计划划分SubPlan
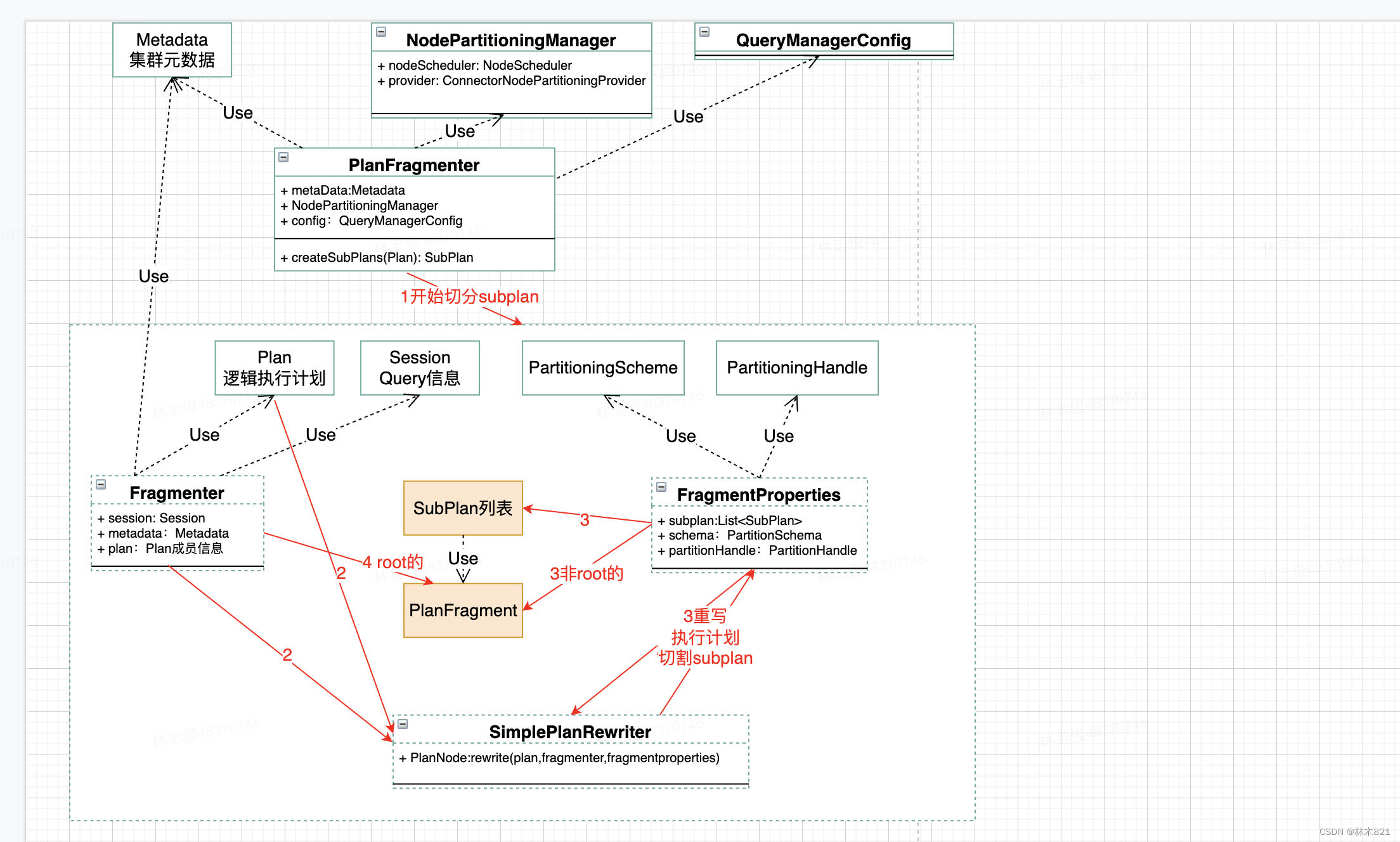
描述一下上图的整体流程:
-
第一步骤:PlanFragmenter调用createSubPlans()来进行SubPlan的切割。依赖MetaData,NodePartitionManager和QueryManagerConfig对象。
-
第二步骤:构造此查询的Fragmenter(切分器)和FragmentProperties。构造的时候需要依赖生成的逻辑执行计划Plan,查询Session和底层数据元的PartitionSchema和PartitionHandler。
-
第三步骤:SimplePlanRewriter对执行计划Plan进行一次节点的访问(根节点往下遍历),当发现ExchangeNode则进行一次Fragment的切割(ExchangeNode保存了其下source的PlanNode节点集合,即根据ExchangeNode首次创建的FragmentID为1,第一个ExchangeNode上还有一个Root Fragment ),一旦访问到最后一个ExchangeNode,整个执行计划已经切割完成。同时自上而下切割时会按照栈的模式存储每一个Fragment的上下文信息。然后遍历这个栈结构,即开始从下往上来进行PlanFragment和SubPlan的构造,构造出来的SubPlan存储到FragmentProperties中。在访问完ExchangeNode时,将ExchangeNode转化成RemoteSourceCode,PlanFragment会存储直接下游RemoteSourceNodes,以便后续根据这个信息生成RemoteSplit信息。一直到访问Root的OutPutNode节点,因为OutPutNode不是ExchangeNode,Root的SubPlan没有被创建。故在SimplePlanRewriter执行完成后,要执行一次buildRootFragment()。
-
第四步骤:完成对Root SubPlan的PlanFragment的构造。
SubPlan: 逻辑执行计划Plan(PlanNodes)会根据ExchangeNode将其拆分成多个SubPlan,一个SubPlan中包含多个节点PlanNode。
Fragment: Presto会将SQL语句拆解为一个一个PlanNodes, 比如join-node, exchange-node, projection-node, filter-node等等. 每个SubPlan会包含其中若干个PlanNodes, 这些PlanNodes封装到一个叫做Fragment的对象中. 也就是说, SubPlan主要负责上下游依赖的其他SubPlan的关系, Fragment负责维护和管理本SubPlan中要执行的PlanNode。
3.4.1 RemoteSourceNode和ExchangeNode
逻辑执行计划中的PlanNode没有RemoteSourceNode这个类型,它时一个虚拟的PlanNode。这个PlanNode是在SimplePlanRewriter对执行计划进行visit时,当遇到ExchangNode节点时才生成的。
这里复用上述的例子来进行阐述
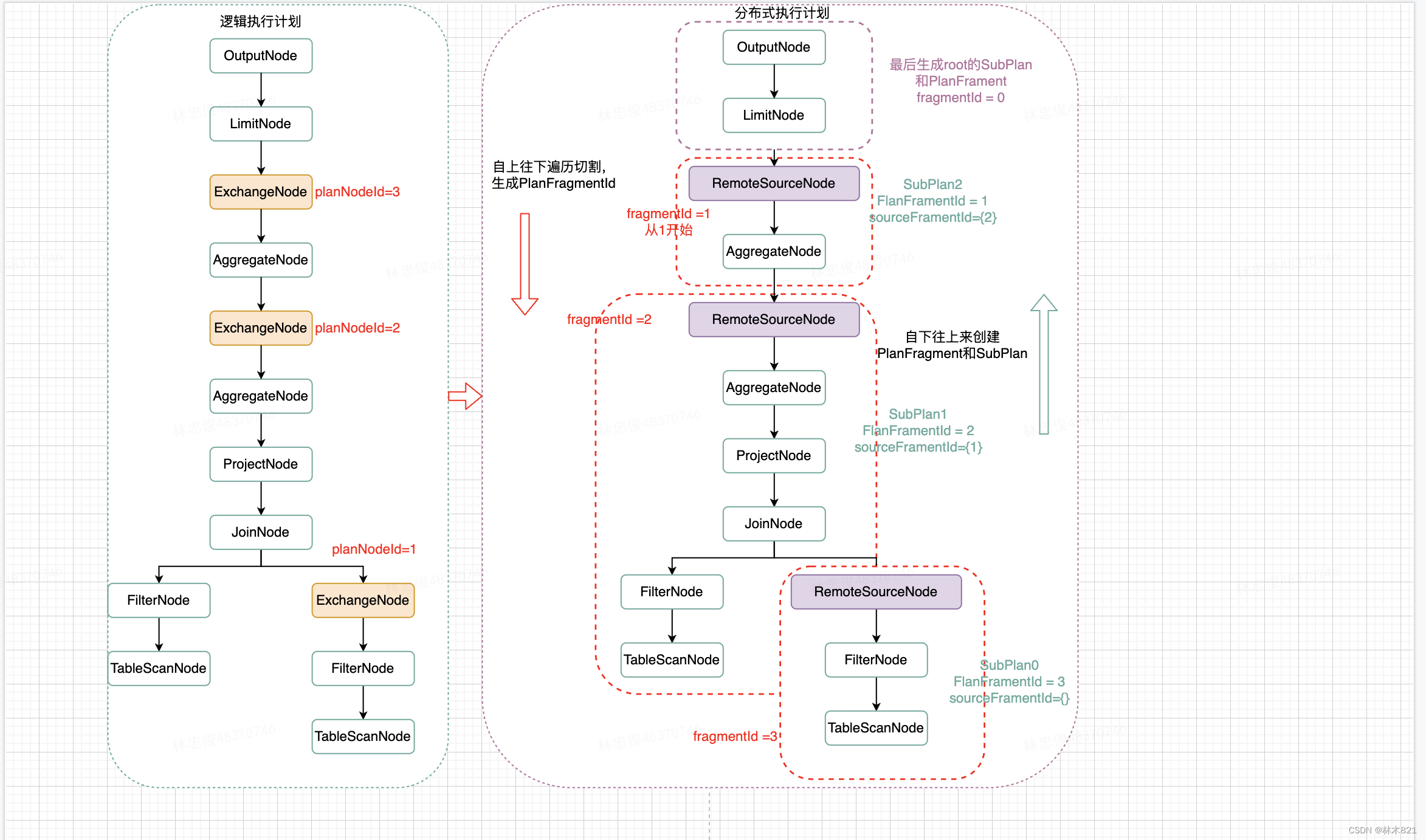
一个SubPlan中绑定一个FlanFragment,每个FlanFragment中要存储直接下游所有的RemoteSourceNode信息。
3.4.2 Fragment对象
这个对象里有两个对象会在后续为SubPlan配置调度时频繁用到:PartitioningHandle和PartitionSchema(这两个属性都维护在MetaData中的TableMeta中)。每个PlanFrament中的PartitioningHandle中的部分属性会在切割执行计划visit每一个PlanNode中进行修改(connectorHandle属性)。PartitioningHandle的类型有source、fixed、single、coordinator_only等。具体每一种PlanNode的设置策略可以阅读PlanFragmenter中的各个visit函数。
| PlanFragment | PartitioningHandle |
|---|---|
|
|
|
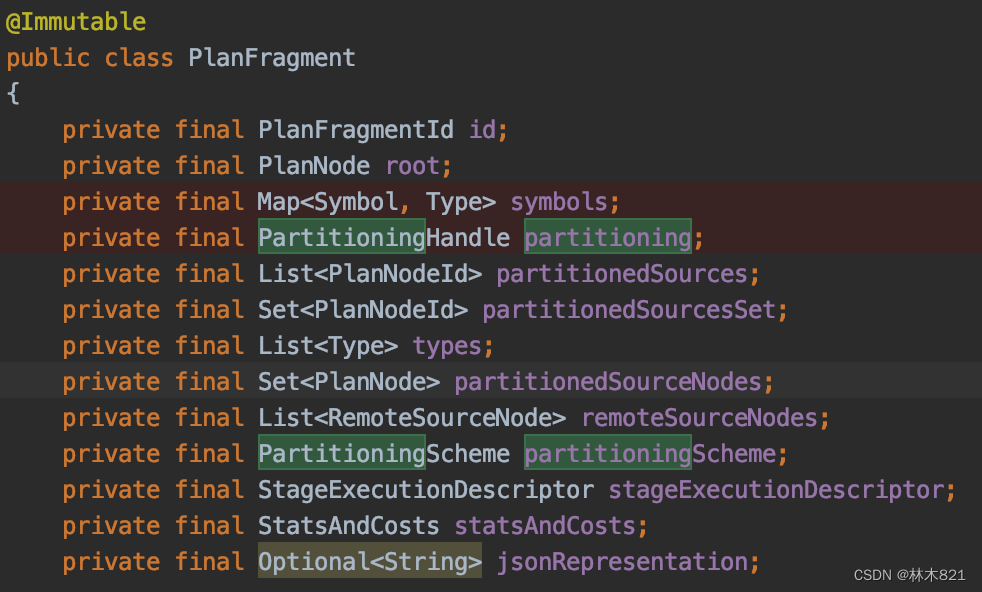

3.4.3 PlanRoot
根据Analysis对象生成执行计划,并根据Presto提供的优化器对其进行优化。同时根据执行计划中的各个PlanNode, 对执行计划进行划分,生成SubPlan,且每一个SubPlan绑定一个PanFragment(子执行计划的上下文)
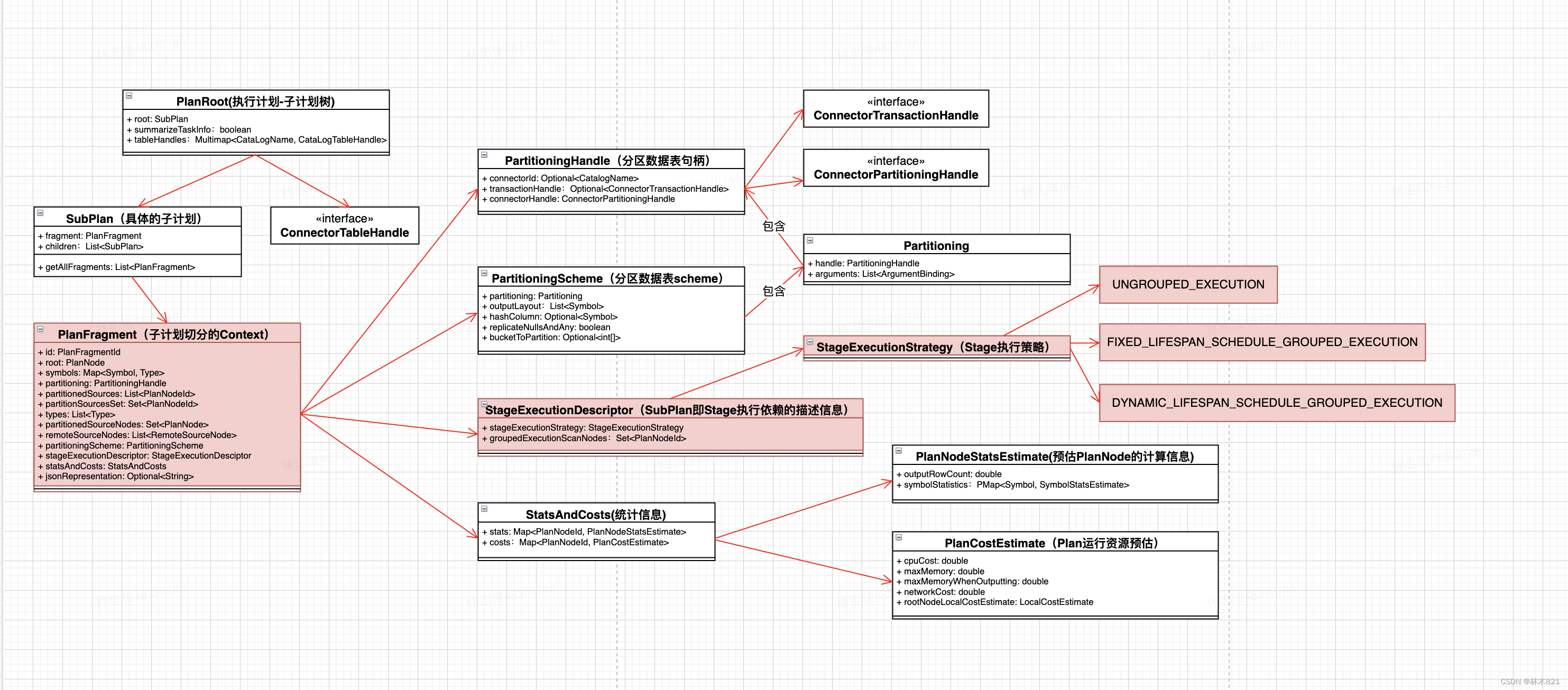
上图中展示了经过执行计划优化后PlanRoot的组成:
-
PlanRoot包括经过PlanFragmenter划分后的一个SubPlan树(一个SubPlan称为一个Stage)
-
PlanRoot包括本次查询需要依赖的CataLogHandle
SubPlan称为一个Stage,她包含其依赖的SubPlan集合。每一个SubPlan绑定一个PlanFragment,PlanFragment维护了一个SubPlan运行时所有依赖的信息。如上图所示PlanFragment是每一个SubPlan的核心。
PlanFragment包含的数据源的信息,Stage运行时描述信息是Stage调度和执行的重要组成,后续会重点每一个类的构造原理和具体取值的含义
4、分布式执行计划(生成调度策略)
4.1 分布式可执行计划时序图
在PlanRoot构造完成后,开始进行分布式执行计划的生成,即将每一个SubPlan转换成可以执行的StageExecutionPlan,同时根据上下文信息构造Stage调度的SqlQueryScheduler来实现Stage的调度。下图展示了分布式执行计划和调度策略生成的时序图。
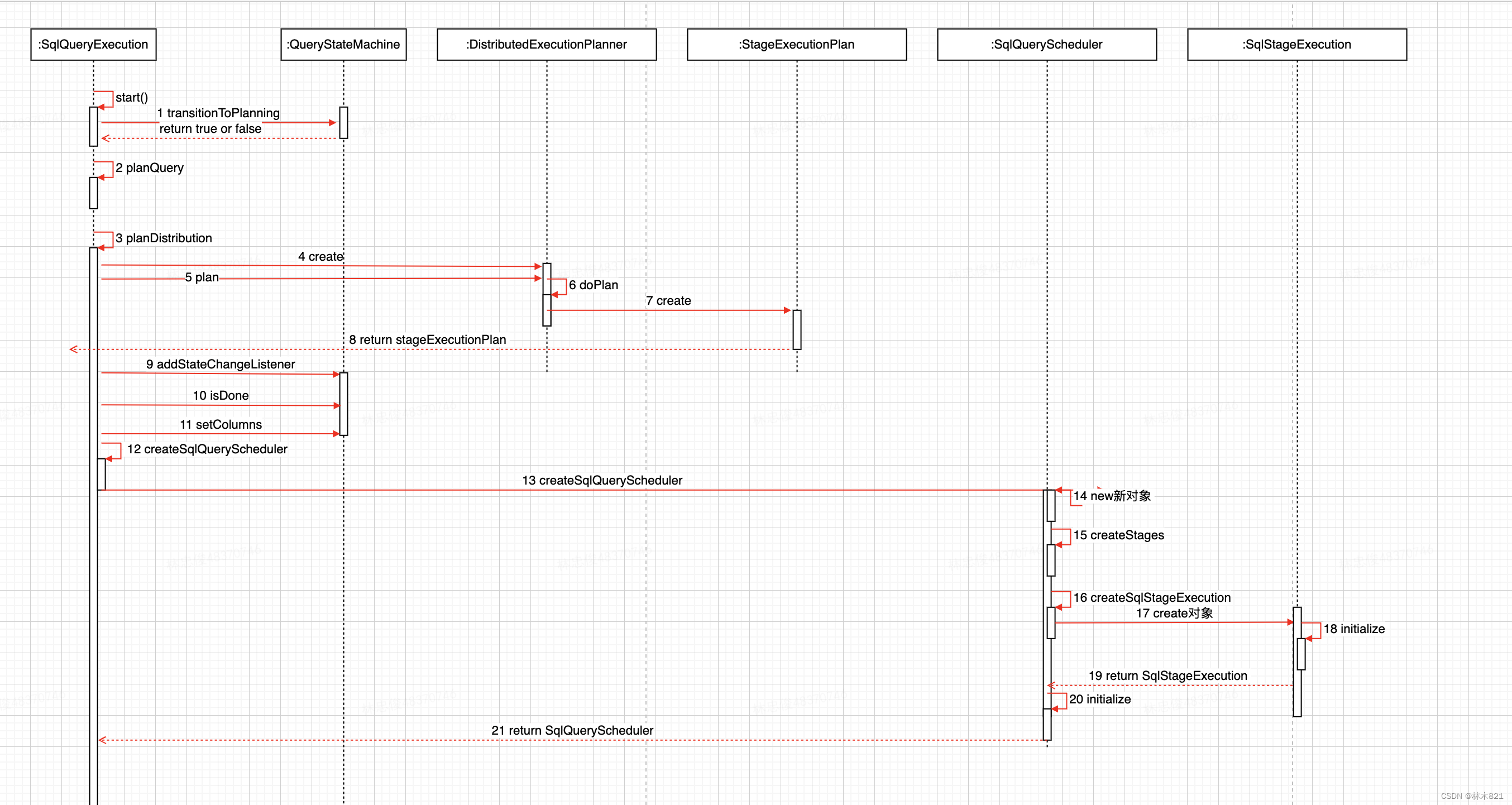
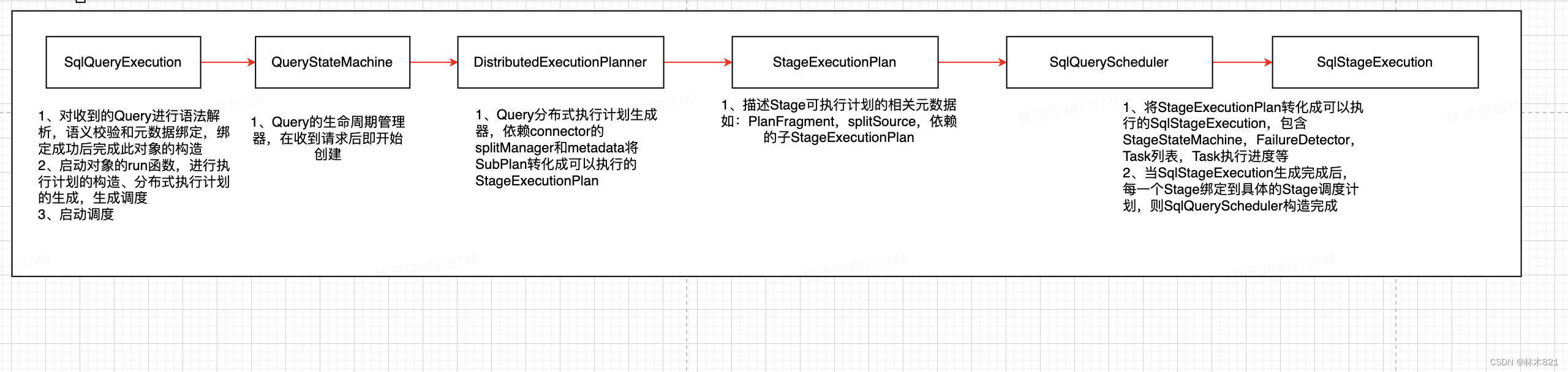
上述时序图中显示的类是分布式执行计划和调度的核心类,需要了解每一个类的成员和函数才能更好的了解一个Query是如何被划分成Stage,以及Stage是如何被调度的。
4.2 分布式可执行计划核心UML类
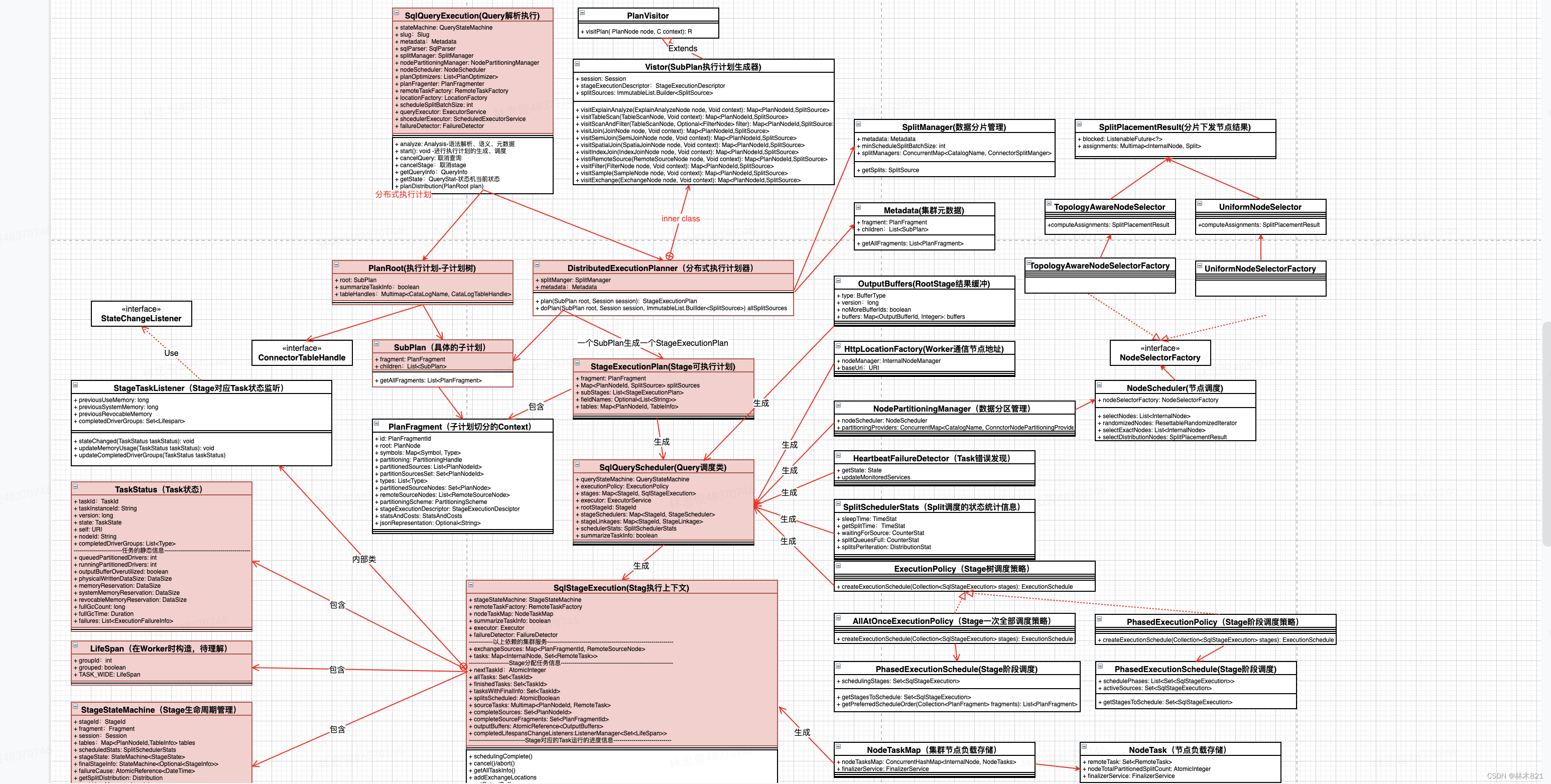
4.3 SqlQueryExecution
Sql进行语法解析、语义,执行计划,调度的入口实现类
4.3.1 类成员变量
| 成员 | 功能描述 |
|---|---|
| preparedQuery | 描述一个查询Statement,以及参数表达式 |
| stateMachine | 管理一次完整Query的状态机 |
| slug | 描述查询当前所在的位置,是Queued还是Executing |
| meteData | 维护Presto集群的元数据,如支持的数据类型,支持的函数,连接的数据源和表、列元数据等 |
| accessControl | 实现类是:AccessControlManager 维护每个CataLog的访问控制权限 |
| sqlParser | 进行Sql语法解析的实现类,将statement按照语法树解析出各个关键字段,并进行语法校验 |
| splitManager | 维护Catalog表数据的分片管理,主要是按照表元数据将其进行分片 |
| nodePartitioningManager | 维护Catalog表数据分布管理,即表的每个partitioning可以通过哪些node节点进行读取 维护当前Presto集群节点的调度策略:
|
| nodeScheduler | 当前Presto集群节点的调度策略:
|
| planOptimizers | Presto提供的逻辑执行计划优化器 |
| planFragmenter | 将一次完成的执行计划划分成多个SubPlan的切割器。划分SubPlan的规则是:存在数据交换的PlanNode之间增加ExchangeNode,按照ExchangeNode进行划分。 |
| remoteTaskFactory | 实现类是:MemoryTrackingRemoteTaskFactory 功能:将每一个stage转化成HttpRemoteTask对象发送到worker上进行执行。 |
| locationFactory | 实现类是:HttpLocationFactory,负责创建具体URI地址。如:
|
| scheduleSplitBatchSize | 此参数是系统级配置参数,每个Query共享同一份配置,这个参数默认是1000。 参数的含义: The size of single data chunk expressed in rows that will be processed as single split. Higher value may be used if system works in reliable environment and there the responsiveness is less important then average answer time. Decreasing this value may have a positive effect if there are lots of nodes in system and calculations are relatively heavy for each of rows. Other scenario may be if there are many nodes with poor stability - lowering this number will allow to react faster and for that reason the lost computation time will be potentially lower. |
| queryExecutor | 此对象是用于构造SqlStageExecution的内部类StageTaskListener,当TaskStatus发生变更时,用此线程来更新内存账本和Stage对应的Task进度信息。 |
| schedulerExecutor | 此对象在SqlQueryScheduler针对Stage的PartitioningHandle是scaled_writer_distribution时,进行ScaledWriterScheduler的构造。 ScaledWriterScheduler类待整理其功能 |
| failureDetector | 实现类:HeartbeatFailureDetector 功能:每隔5秒对当前集群的所有服务进行检测,去除失效的监控任务,禁止失效的节点服务,为新服务增加新的监控任务等。总体是及时发现集群服务变更,保持集群信息的正确性 |
| queryScheduler | AtomicReference类提供了一个可以原子读写的对象引用变量。 原子意味着尝试更改相同AtomicReference的多个线程(例如,使用比较和交换操作)不会使AtomicReference最终达到不一致的状态。 AtomicReference甚至有一个先进的compareAndSet()方法,它可以将引用与预期值(引用)进行比较,如果它们相等,则在AtomicReference对象内设置一个新的引用。 SqlQueryScheduler: 将SqlQueryExecution经过执行计划后生成的SubPlan转化成SqlStageExecution进行调度。
|
| queryPlan | 一个SqlQueryExecution在执行语法解析和语义校验后,经过逻辑计划器之后会生成Plan对象,包含 |
| nodeTaskMap | 存储Presto Worker上每个节点的Task负载,供SqlQueryScheduler在调度Split和Task时进行 |
| executionPolicy | Presto提供两种Stage的调度策略:
|
| schedulerStats | 此对象存储在Split调度时的统计信息 |
| analysis | 一个Statement在经过SqlParser后,再经过语义校验和元数据绑定后生成的对象。此对象是执行计划生成的输入 |
| statsCalculator | 实现类:ComposableStatsCalculator,统计右图中的各个PlanNode的统计信息。 |
| costCalculator | 实现类:CostCalculatorUsingExchanges。预估每个节点的花费信息,TableScan会使用的CPU时间等。具体原理还未细看 |
4.3.2 类函数功能
| 函数名称 | 功能 |
|---|---|
| SqlQueryExecution |
|
| Analysis analyze() |
|
| DataSize getUserMemoryReservation() | |
| DataSize getTotalMemoryReservation() | |
| Duration getTotalCpuTime() | |
| BasicQueryInfo getBasicQueryInfo() | |
| void start() | |
| void addStateChangeListener(StateChangeListener<QueryState> stateChangeListener) | |
| PlanRoot planQuery() | |
| PlanRoot doPlanQuery() | |
| static Multimap<CatalogName, ConnectorTableHandle> extractTableHandles(Analysis analysis) | |
| void planDistribution(PlanRoot plan) | |
| void closeSplitSources(StageExecutionPlan plan) | |
| void cancelQuery() | |
| void cancelStage(StageId stageId) | |
| void fail(Throwable cause) | |
| QueryInfo getQueryInfo() |
4.4 SubPlan
在经过执行计划后,按照ExchangeNode进行拆分的Stage的描述类,即SubPlan。一个Query对应一个SubPlan树。
| 成员 | 类型 | 功能描述 | 备注 |
|---|---|---|---|
| fragment | Fragment | SubPlan包含的PlanNode,依赖的元数据,后续要进行执行和调度的上下文 | |
| children | List<SubPlan> | SubPlan依赖的叶子Subplan |
4.5 StageExecutionPlan
4.5.1 类成员变量
| 成员 | 类型 | 功能描述 |
|---|---|---|
| fragment | Fragment | SubPlan包含的PlanNode,依赖的元数据,后续要进行执行和调度的上下文 |
| splitSources | Map<PlanNodeId, SplitSource> | 描述每一个PlanNode的输入SplitSource。 SplitSource是一个逻辑概念,描述从哪个表读取哪个ConnectorSplitSource。Presto抽象了一个SplitBatch的概念,即通过系统参数将一定大小的Split合成一个SplitBatch来进行调度。 |
| subStages | List<StageExecutionPlan> | StageExecutionPlan下依赖的一组叶子StageExecutionPlan |
| fieldNames | Optional<List<String>> | 每个StageExecution中的RootPlanNode的输出FieldName信息 |
| tables | Map<PlanNodeId,TableInfo> | 存储PlanNode对应的Table信息 |
4.6 SqlQueryScheduler
4.6.1 类成员变量
| 成员 | 类型 | 功能描述 |
|---|---|---|
| queryStateMachine | QueryStateMachine | 查询请求发送到Coordinator后,会给每个查询构造一个sm,来管理其的生命周期。维护一个查询的静态信息和查询中的状态和进度信息 |
| executionPolicy | ExecutionPolicy | Presto提供两种Stage的调度策略:
|
| stages | Map<StageId, SqlStageExecution> | 描述当前一个Query分了几个Stage,每个stage对应的SqlStageExecution |
| rootStageId | StageId | 每个Query的Root Stage |
| stageSchedulers | Map<StageId, StageScheduler> | 每个Stage对应的调度策略 |
| stageLinkages | Map<StageId, StageLinkage> | Stage之间的调度链条 |
| schedulerStats | SplitSchedulerStats | 此对象存储在Split调度时的统计信息 |
| summarizeTaskInfo | boolean | 查询语句如果是(Explain且isAnalyze),则summarizeTaskInfo设置成false。 ?????为什么这么设置? 这个参数只会在后续的TaskInfoFetcher中使用,如果是True,则URI中增加一个summarize的参数 |
| started | AtomicBoolean | 可以进行开始调度的标示 |
4.6.2 类函数功能
| 函数名称 | 功能 | 备注 |
|---|---|---|
| static SqlQueryScheduler createSqlQueryScheduler |
| |
| SqlQueryScheduler |
| |
| initialize |
| |
| updateQueryOutputLocations |
| |
| createStages |
|
|
| getBasicStageStats |
| |
| getStageInfo |
| |
| getUserMemoryReservation | 汇总每个SqlStageExecution的内存信息(user类型) | |
| getTotalMemoryReservation | 汇总每个SqlStageExecution的内存信息(user+system类型 | |
| getTotalCpuTime | 汇总每个SqlStageExecution的cpu时常信息 | |
| start | 使用线程调用SqlQueryScheduler的schedule函数 | |
| schedule |
| 此逻辑会在第六章节调度中完整介绍 |
| cancelStage | 按照StageId取消stage,调用SqlStage的cancel函数 | |
| abort | 遍历SqlStageExecution,一次执行abort | |
| whenAllStages | 针对stages进行监听,监听stages是否已经完成 |
4.7 SqlStageExecution
4.7.1 类成员变量
| 成员 | 类型 | 功能描述 | 备注 |
|---|---|---|---|
| stageStateMachine | StageStateMachine | 查询请求发送到Coordinator后,会给每个查询构造一个sm,来管理其的生命周期。维护一个查询的静态信息和查询中的状态和进度信息 | 这个类后续会重点单独介绍 |
| remoteTaskFactory | RemoteTaskFactory | 实现类是:MemoryTrackingRemoteTaskFactory 功能:将每一个stage转化成HttpRemoteTask对象发送到worker上进行执行。 | |
| nodeTaskMap | NodeTaskMap | 存储Presto Worker上每个节点的Task负载,供SqlQueryScheduler在调度Split和Task时进行 | |
| summarizeTaskInfo | boolean | 查询语句如果是(Explain且isAnalyze),则summarizeTaskInfo设置成false。 ?????为什么这么设置? 这个参数只会在后续的TaskInfoFetcher中使用,如果是True,则URI中增加一个summarize的参数 | |
| executor | Executor | 此对象是用于构造SqlStageExecution的内部类StageTaskListener,当TaskStatus发生变更时,用此线程来更新内存账本和Stage对应的Task进度信息。 | |
| failureDetector | FailureDetector | 实现类:HeartbeatFailureDetector 功能:每隔5秒对当前集群的所有服务进行检测,去除失效的监控任务,禁止失效的节点服务,为新服务增加新的监控任务等。总体是及时发现集群服务变更,保持集群信息的正确性 | |
| exchangeSources | Map<PlanFragmentId, RemoteSourceNode> |
| |
| tasks | Map<InternalNode, Set<RemoteTask>> |
| |
| nextTaskId | 运行时Task的信息,会在调度和Task生命周期管理中描述 AtomicReference<OutputBuffers> Root Stage对应的最终的OutputBuffers | ||
| allTasks | |||
| finishedTasks | |||
| tasksWithFinalInfo | |||
| splitsScheduled | |||
| sourceTasks | |||
| completeSources | |||
| completeSourceFragments | |||
| outputBuffers | |||
| completedLifespansChangeListeners | |||
4.8 StageScheduler
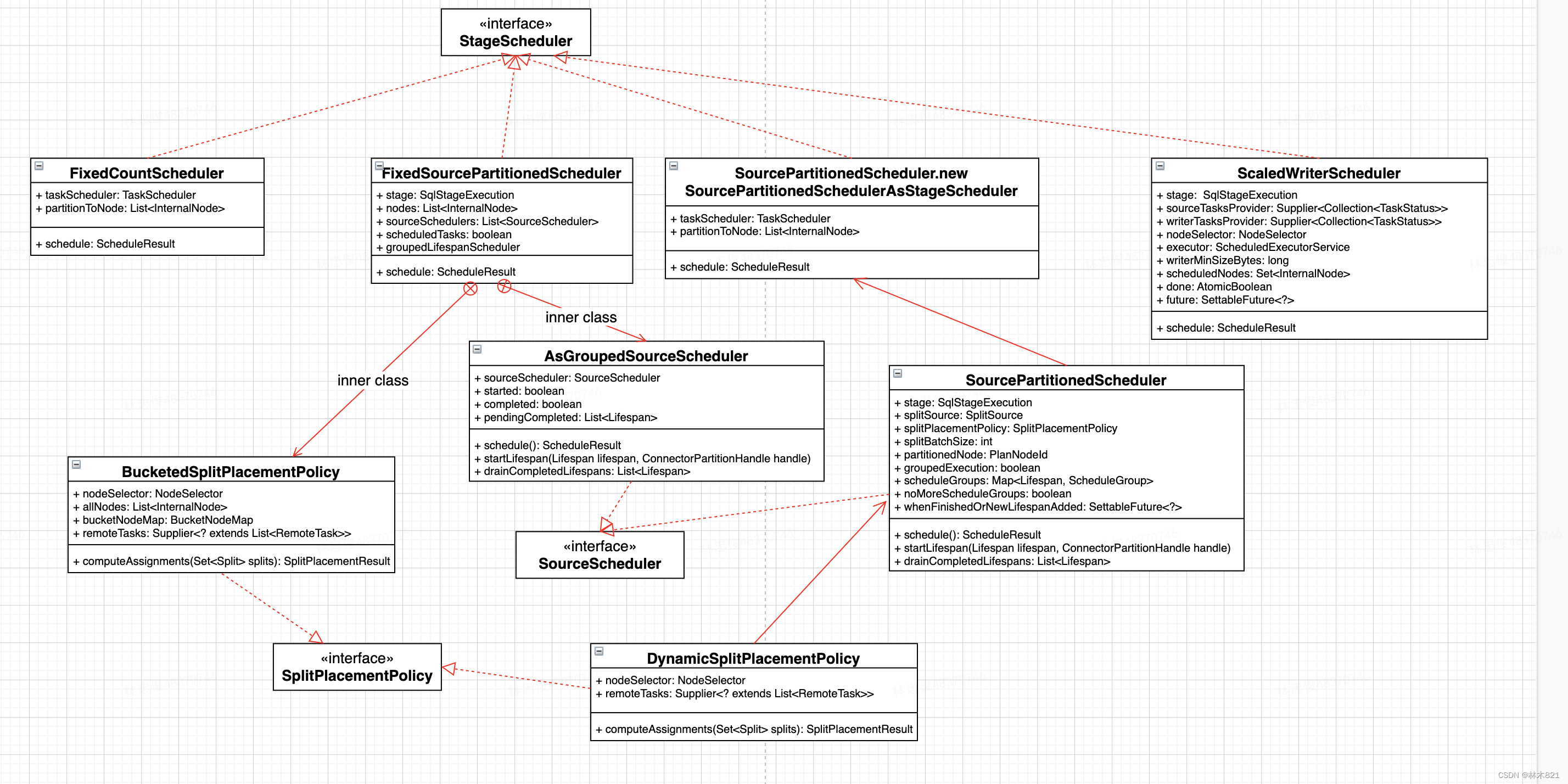
Presto中针对Stage提供了四种类型的StageScheduler,其中对于Source类型的Stage还需要绑定SourceScheduler和SplitPlacementPolicy。Source类型的Stage根据数据源Connector的特性调度策略又分为两种:
-
FixedSourcePartitionedScheduler
-
BucketedSplitPlacementPolicy
-
AsGroupedSourceScheduler
-
-
SourcePartitionedScheduler.newSourcePartitionedSchedulerAsStageScheduler
-
DynamicSplitPlacementPolicy
-
SourcePartitionedScheduler
-
4.8.1 Stage和StageScheduler的映射规则
需要弄清楚PlanFragment中的各个字段的含义,才能清楚的了解映射规则的设计。
SqlExecutionPlan计划的PartitioningHandle和关联的SplitSources信息决定了其的调度策略。Stage是SqlExecutionPlan一次调度执行的描述,后续将使用stage来描述生成调度和执行调度过程。Stage分为四种类型(从PartitioningHandle属性继承而来)在进行执行计划拆分时,会根据ExchangeNode的类型来给SubPlan中的PlanFrament的PartitioningHandle设置类型。所以Stage一定包含一个PartitioningHandle,PartitioningHandle的类型可以表述为Stage的类型。
| 类型 | 描述 | 备注 |
|---|---|---|
| Source | 一般是TableScanNode、ProjectNode、FilterNode,一般是最下游的取数的Stage | 如果splitSource对应的表是unbucket,则为distribution_source。 |
| Fixed | 一般在Source之后,将Source阶段获取的数据分散到多个节点上处理,类似于Map端reduce操作,包括局部聚合、局部Join、局部数据写入 | |
| Single | 一般在Fixed之后,只在一台机器上进行,汇总所有的结果、做最终聚合、全局排序,并将结果传输给Coordinator | |
| Coordinator_only | 只在Coordinator上 |
底层数据表的格式(是否bucket表)会影响直接计划的拆分(如join),即增加ExchangeNode的策略(ExchangeNode同时会维护一个字段Type来描述ExchangeNode下节点的功能)。当根据ExchangeNode将执行计划拆分成分布式执行计划后,会根据ExchangeNode的Type来生成不同的PartitionHandle类型。PartitionHandle的类型和Stage中的SplitSource信息共同决定了配置的调度策略。(Stage and Source Scheduler and Grouped Execution · prestodb/presto Wiki · GitHub)
StageScheduler调度策略和策略分配规则如下:
-
SourcePartitionedScheduler:凡是包含TableScanNode的执行计划都需要使用SourcePartitionedScheduler来完成SplitSource中每个split到执行节点的分配(assignSplits过程)。如果表是unbucketed,在生成执行计划时会把TableScanNode拆分成一个独立的stage(至多加上FilterNode),且type是source_distribution;为其分配的调度策略是SourcePartitionedScheduler,绑定的split分配node的策略是DynamicSplitPlacementPolicy
-
FixedSourcePartitionedScheduler:包含TableScanNode的执行计划(即splitSource至少有一个是source split,可以包含remote split且source split对应的table是bucket表)。这种stage会配置成FixedSourcePartitionedScheduler调度,但是底层核心split到node的分配操作仍然是底层调用SourcePartitionedScheduler来实现。这个时候为split分配node的策略是BucketedSplitPlacementPolicy
-
FixedCountScheduler:非source类型,全部都是remote split,选择节点直接进行(构建task:scheduleTask)
SourcePartitionedScheduler是处理读取数据stage(source)的调度器。有一个额外的操作即对数据Split进行调度,给需要处理的split分配执行节点。在presto中,stage中task和split的调度是解耦的。为Split分配Node的策略有两种:
-
BucketedSplitPlacementPolicy(底层数据表是bucketed表),在生成执行时会使用NodePartitionManager生成split和node的映射关系,在具体调度时使用映射管理来为split分配node
-
DynamicSplitPlacementPolicy: (底层数据表是unbucketed表)在具体调度执行前为split分配node
| source stage对应tableScan表 | 调度策略 | Split分配Node策略 |
|---|---|---|
| bucket | FixedSourcePartitionedScheduler | BucketedSplitPlacementPolicy |
| unbucket | SourcePartitionedScheduler | DynamicSplitPlacementPolicy |
【源Stage-unBucket Split】
| 静态策略 | 计算Split下发的node | 调度具体过程 |
|---|---|---|
| 调度器:SourcePartitionedScheduler split下发策略:DynamicSplitPlacementPolicy Stage中是否已经计算出Node列表:否,无法计算 | 入口:DynamicSplitPlacementPolicy 计算方法:
|
|
【源Stage-Bucket Split or remoteSplit】
| 静态策略 | 计算Split下发的node | 调度具体过程 |
|---|---|---|
| 入口调度策略:FixSourcePartitionedScheduler Source调度策略:SourcePartitionedScheduler Source split下发策略:BucketedSplitPlacementPolicy Stage中是否已经计算出Node列表:已经计算出NodePartitionMap | 入口:BucketedSplitPlacementPolicy 计算方法:
|
|
【非源Stage-all remoteSplit】
| 静态策略 | 调度具体过程 |
|---|---|
| 入口调度策略:FixCountScheduler Source split下发策略:无,全部是RemoteSplit Stage中是否已经计算出Node列表:已经计算出NodePartitionMap |
|
4.9 StageLinkage
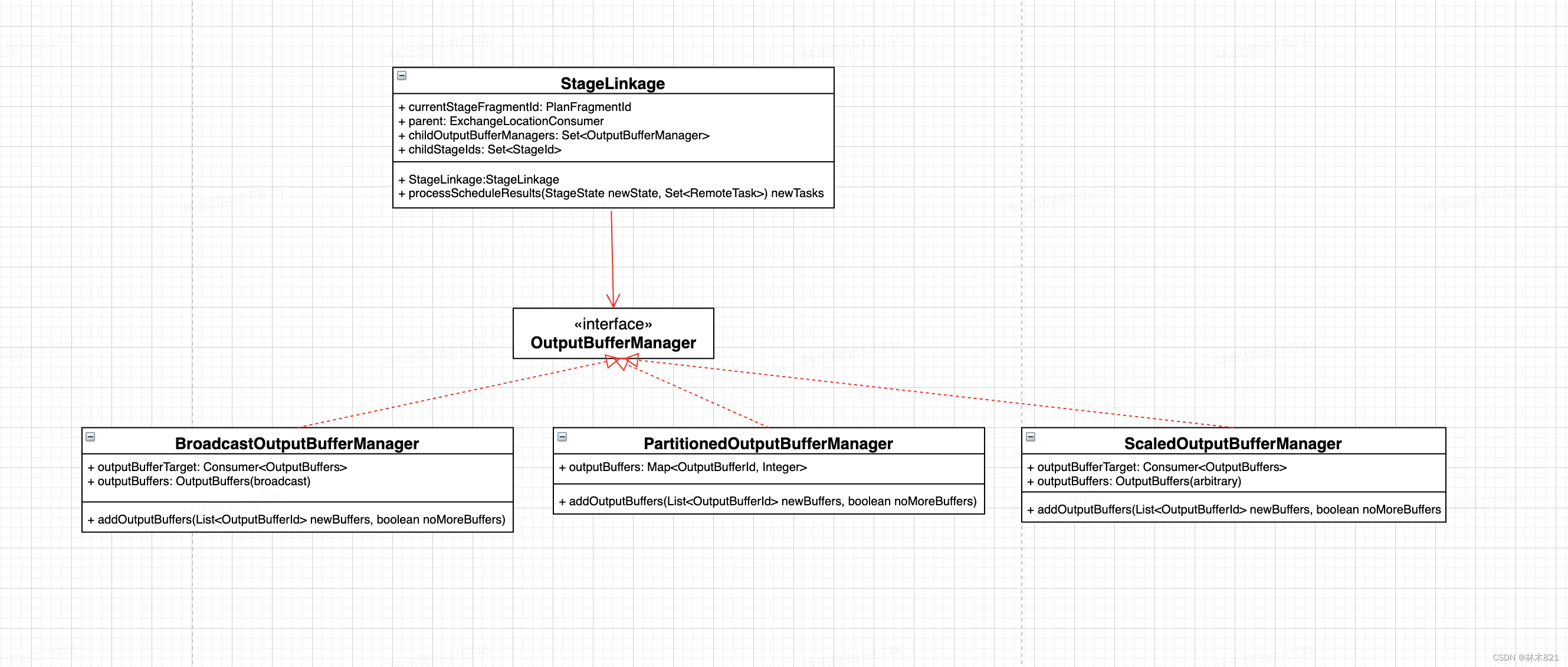
4.9.1 StageLinkage的作用
每个StageLinkage包含对应Stage的PlanFragmentId,父亲Stage需要的ExchangeLocationConsumer,子Stage列表Set<StageId>和每一个子Stage结果的OutputBufferManager。
在进行Stage调度时会调用StageLinkage的processScheduleResults函数。
4.9.2 Stage和OutputBufferManager的映射
| PartitioningHandle | OutputBufferManager | 备注 |
|---|---|---|
| FIXED_BROADCAST_DISTRIBUTION | BroadcastOutputBufferManager | Stage中ExchanNode的类型有关:Replicate |
| SCALED_WRITER_DISTRIBUTION | ScaledOutputBufferManager | |
| 其他 | PartitionedOutputBufferManager | Partition |
4.10 DistributedExecutionPlanner
4.10.1 DistributedExecutionPlanner的作用
将以一个SubPlan转化成StageExecutionPlan(本质给每一个Stage生成其PlanNode需要读取的SplitSource,即需要读取哪些数据)。处理流程如下:
-
从SubPlan的上下文PlanFragment中获取Root PlanNode,根据PlanNode的具体节点类型来执行visit函数
-
visit函数来生成SplitSource
| 节点类型 | visit函数 | 处理逻辑 |
|---|---|---|
| ExplainAnalyzeNode | visitExplainAnalyze(ExplainAnalyzeNode node, Void context) | 遍历Stage PlanNode对应的Source PlanNode,获取<PlanNodeId,SplitSource>信息 |
| TableScanNode | visitTableScan(TableScanNode node, Void context) visitScanAndFilter(TableScanNode node, Optional<FilterNode> filter) | |
| JoinNode | visitJoin(JoinNode node, Void context) | |
| SemiJoinNode | visitSemiJoin(SemiJoinNode node, Void context) | |
| SpatialJoinNode | visitSpatialJoin(SpatialJoinNode node, Void context) | |
| IndexJoinNode | visitIndexJoin(IndexJoinNode node, Void context) | 遍历Stage PlanNode对应的Source PlanNode,获取<PlanNodeId,SplitSource>信息 |
| RemoteSourceNode | visitRemoteSource(RemoteSourceNode node, Void context) | 一个Stage的叶子节点,其读取的数据来源于依赖的子Stage |
| ValuesNode | visitValues(ValuesNode node, Void context) | 常量,nothing |
| FilterNode | visitFilter(FilterNode node, Void context) |
|
| SampleNode | visitSample(SampleNode node, Void context) | |
| 其他 | 对应的visit | 遍历Stage PlanNode对应的Source PlanNode,获取<PlanNodeId,SplitSource>信息 |
4.10.2 包含TableScan的Stage的SplitSource生成
// get dataSource for table
SplitSource splitSource = splitManager.getSplits
(session,node.getTable(),stageExecutionDescriptor.isScanGroupedExecution(node.getId()) ? GROUPED_SCHEDULING : UNGROUPED_SCHEDULING); 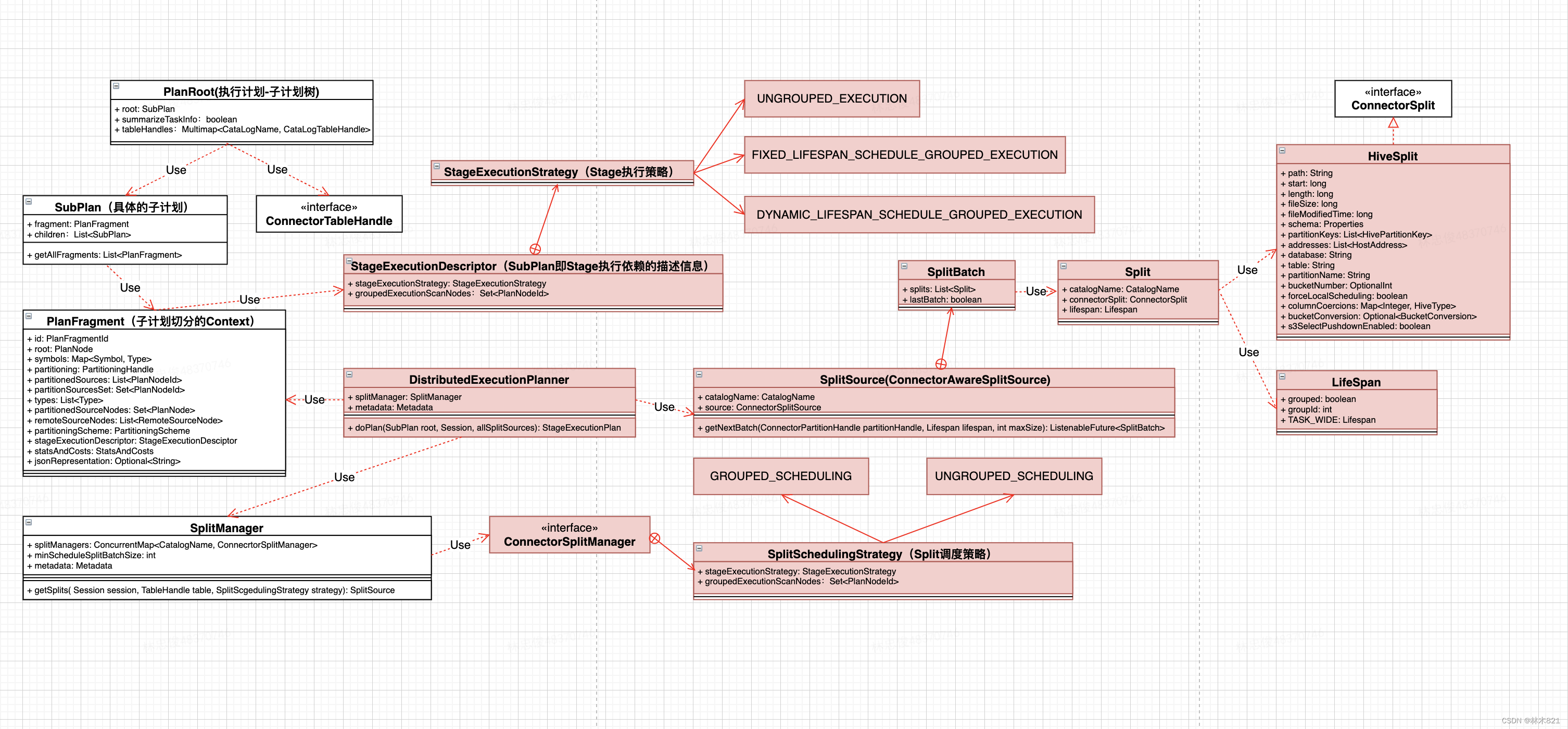
DistributedExecutionPlanner使用SubPlan的信息(PlanFragment),从Root PlanNode节点开始Visit SubPlan中的所有Node,构造出此Stage需要的SplitSource。SplitSource中存储了此Stage需要处理的Split集合,但是此Split是逻辑概念的Split,仅仅是通过对应数据源的ConnectorSplitManager将其进行划分(以Hive为例子,存储path,start,lenght, fileSize等)
在进行Split获取和封装时,有两个变量StageExecutionStrategy和SplitSchedulingStrategy分别描述了Stage的执行策略和Stage中Split调度策略。
4.10.3 StageExecutionDescriptor的作用
在DistributedExecutionPlanner阶段,对于每一个执行计划节点PlanNode会维护其对应的StageExecutionDescriptor信息。
StageExecutionDescriptor的设置和描述如下:
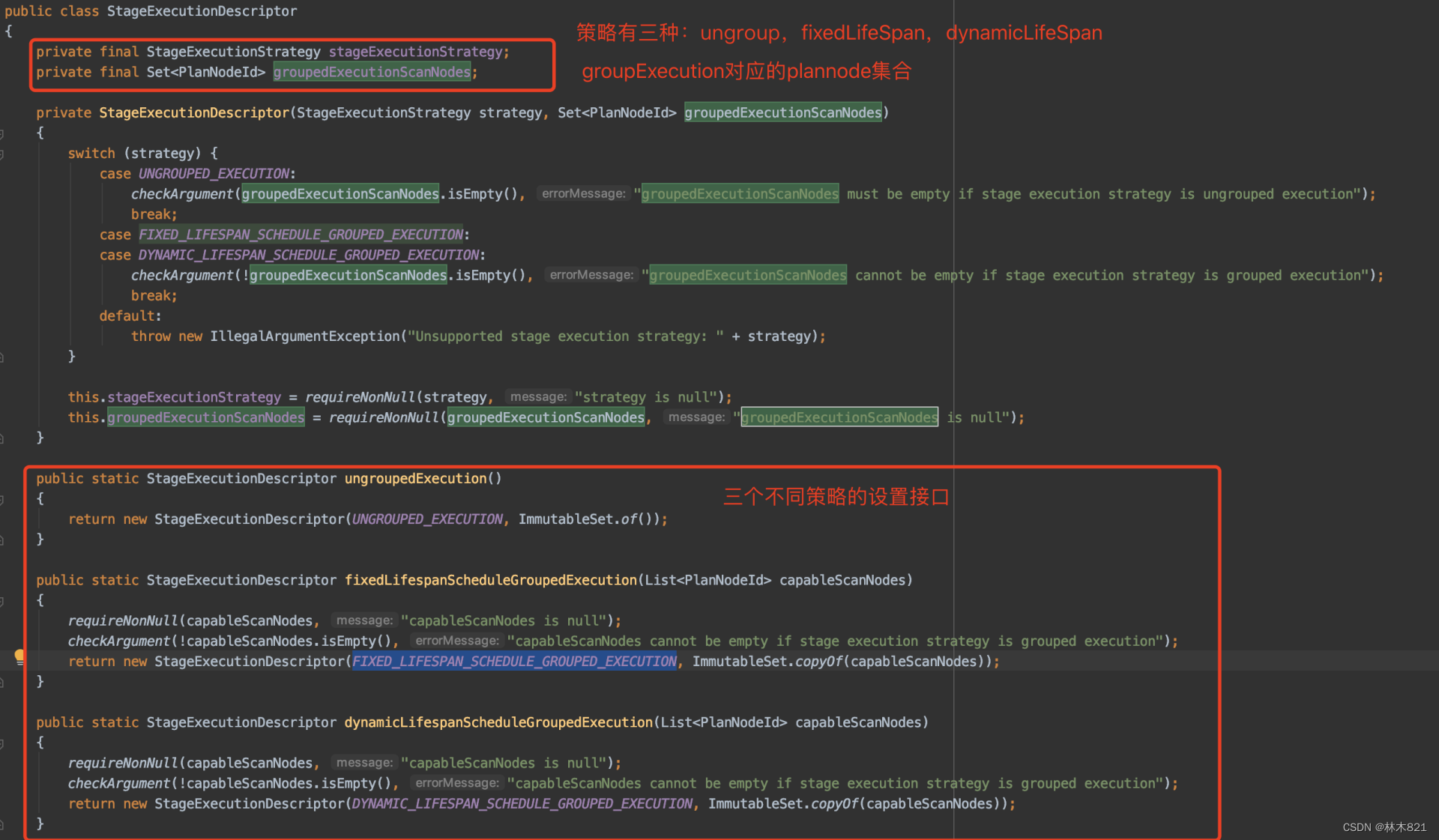
在coordinator的分布式执行计划生成阶段,最重要的就是获取SplitSource信息,从而在stage划分后,能开始进行调度。对于Source stage的调度,要依赖SplitSource中生成的Split的下发策略,即split下发到哪个节点,对应的Task在哪个节点执行。
那么决定Stage是否可以Group执行的因素是什么呢???
大概猜测:数据connector的系统配置参数,是否partition,bucket,等决定了这个参数。GroupExecution参数在coordinator和worker端都被使用,在coordinator端决策了生成splitsource的策略(allatonce?bucket?),在worker端决定了operator是否可以group执行。
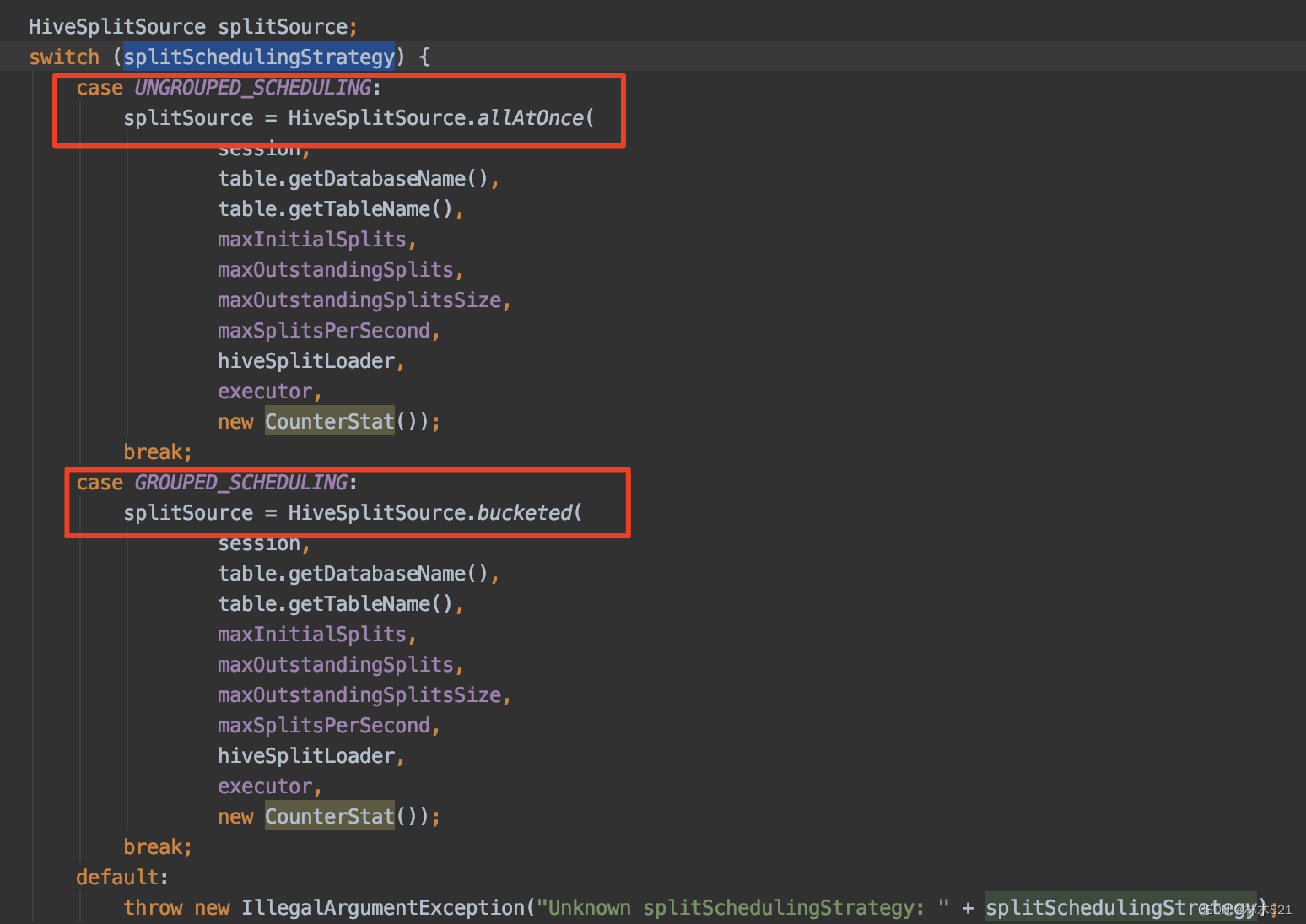
4.10.4 SplitSchedulingStrategy的作用
和StageExecutionDescriptor的设置应该有关?????猜测(group execution的设置策略和依据是什么),之后的LiferSpan,GroupScheduler等等是否都是因此而产生。这个参数在具体的connector的splitManager中会使用,以hive为例代码如下:
5、调度Stage
5.1 Stage生命周期(状态机)
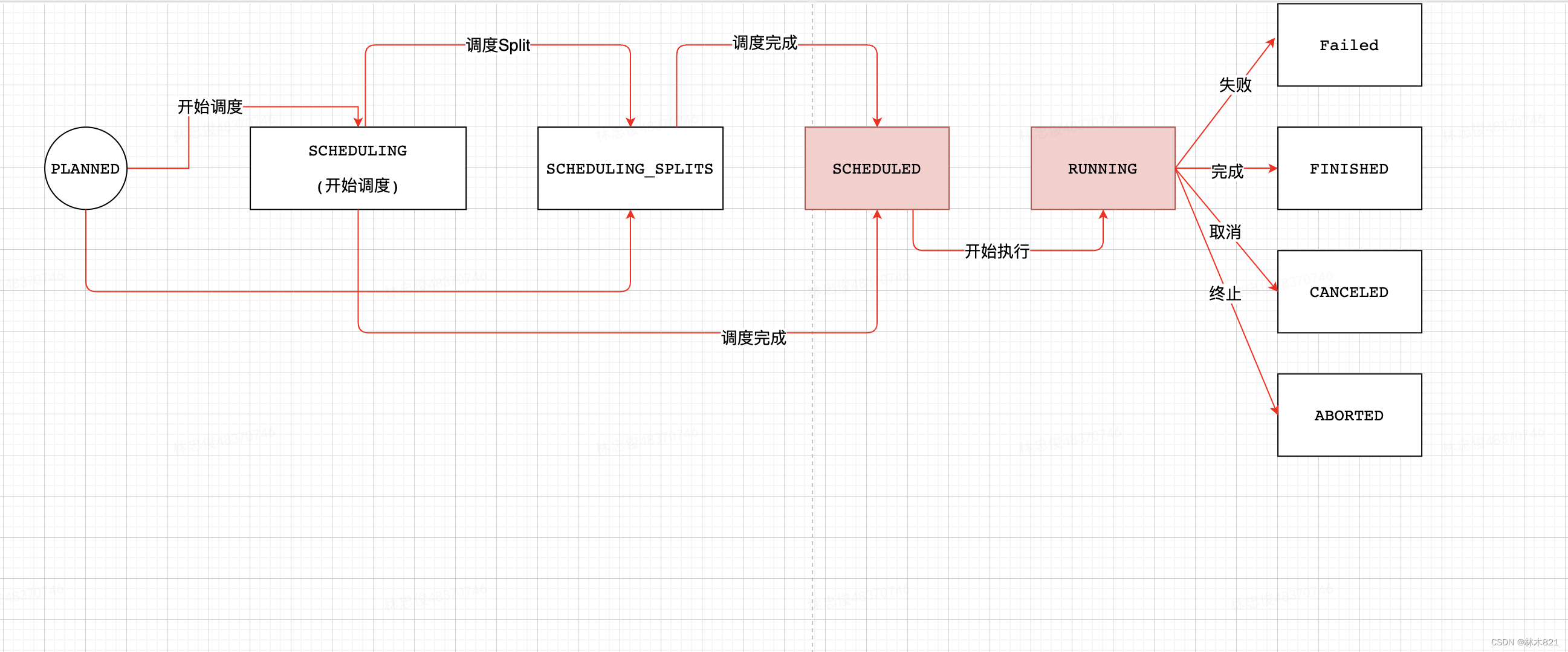
5.2 调度UML类图
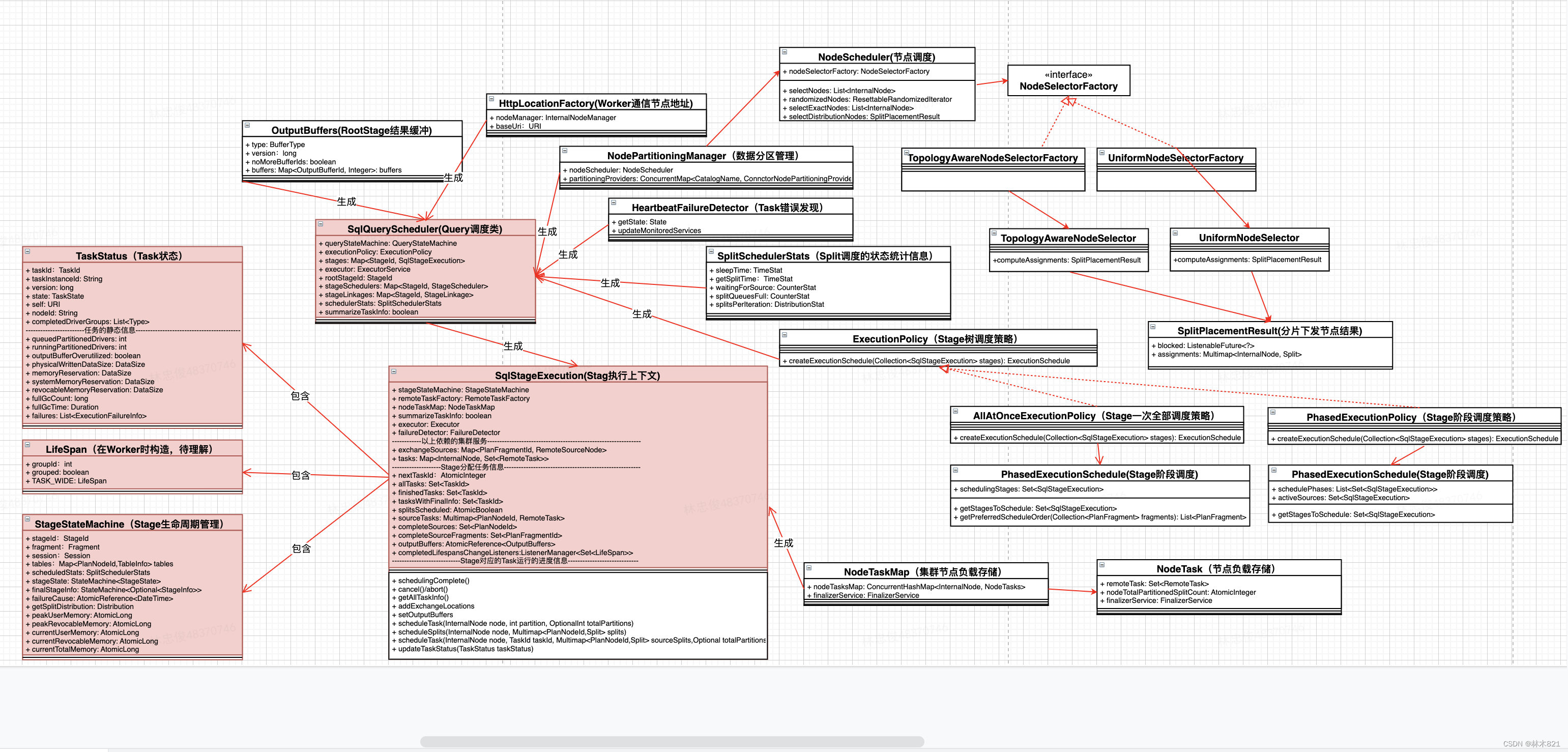
5.3 调度UML时序图
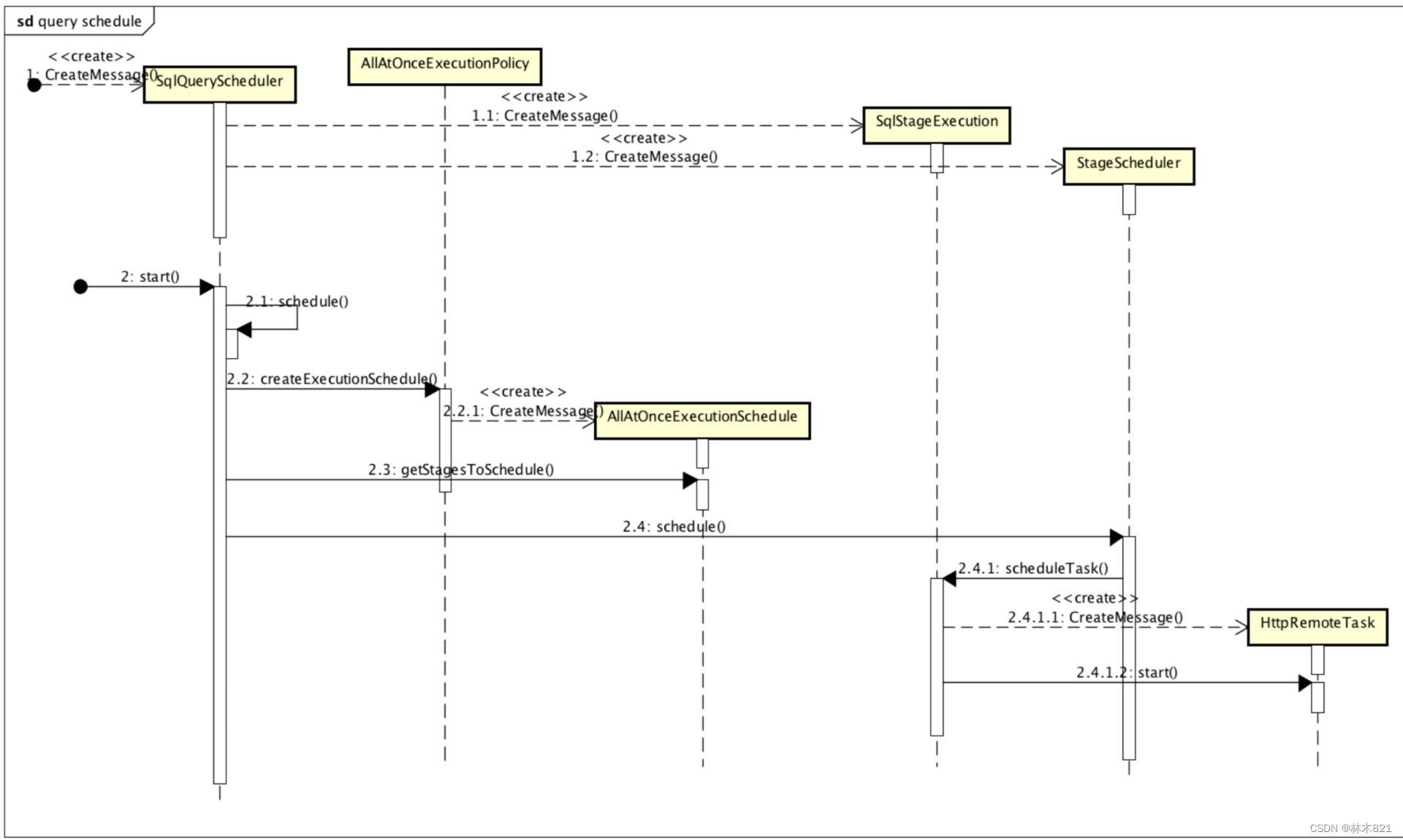
-
第一步骤,根据stage调度策略(AllAtOnceExecutionPolicy和PhasedExecutionPolicy)来将本次查询的系列SqlStageExecution进行排序。即SqlStageExecution(Stage)的调度顺序。
-
按照SqlStageExecution的顺序,遍历依次进行调度。使用SqlStageExecution中绑定的StageStateMachine来描述stage执行的状态。
-
调度SqlStageExecution时,根据SqlStageExecution绑定的StageScheduler执行StageScheduler的scheduler()。
-
如果StageScheduler是SourcePartitionedScheduler或者FixedSourcePartitionedScheduler,底层都会执行SourcePartitionedScheduler的scheduler。这个过程里有两个核心的功能,首先为stage的每一个split source来分配node(即assignSplit);然后将split运行起来,即schedulerSplit(本质是创建Task,task运行在split上)。
-
如果StageScheduler是FixedCountScheduler,即stage的split 都是remote split。即根据NodePartitionMap中维护的本stage可以执行的node列表,来调度task(scheduleTask)。
-
一旦开始scheduleTask机会开始创建RemoteTask(源头的task个数和split的个数一致,非源头的stage会根据相关信息,每个node上创建一个task)。创建RemoteTask时会更新SqlStageExecution的allTask和tasks变量。
-
调度完成返回了ScheduleResult结果。StageLinkage会根据ScheduleResult的结果和状态来跟新sourceTask的信息。如果此stage包含remoteSourceNode,则要根据allTask和sourceTask来为task创建依赖的remoteSplit。如果存在remoteSplit则会更新RemoteTask(远程update)。
-
启动RemoteTask的start()方法。开始轮询获取task的状态,不停的更新SqlStageExecution所有有关task的变量。直到所有task完成。
-
当所有stage都完成,此次查询调度完成
5.4 Stages的执行策略ExecutionPolicy
在经过SqlQueryScheduler的createSqlQueryScheduler函数后,遍历SubPlan将其转换成SqlStageExecaution列表。当开始调用schedule进行调度时,会根据Presto当前的ExecutionSchedule完成对Stage的调度。
Presto提供了两种执行策略(AllAtOnceExecutionPolicy和PhasedExecutionPolicy),具体策略是通过系统参数设置,默认是AllAtOnceExecutionSchedule。
-
AllAtOnceExecutionPolicy:在AllAtOnceExecution策略下,顾名思义, 就是一次调度所有 stage, 虽然是一次性调度, 但各个 stage 之间是有序的, 从整个 sub plan 树的叶子节点开始, 自底向上的去调度其对应 stage, 最先调度源头 stage, 最后调度到 root stage。
-
PhasedExecution:PhasedExecution模式下,coordinator会根据Stage之间的依赖关系,分批对这些Stage进行调度。
-
Task是Stage在某个Presto Worker上的一个instance,而Stage在被调度的过程中,如何决策往哪些Presto Worker上下发Task,发送多少个Task呢? 首先对于源头Stage(包含TableScanNode),coordinator会尝试从connector获取对应TableScanNode的splits,split包含isRemotelyAccessible属性。当remotelyAccessible=false时,该split只能被下发至addresses包含的Presto Worker上;而当remotelyAccessible=true时,该split可能被调度至集群内的任意一个Presto Worker上。当该stage的split为第一次被调度至Presto Worker上时,coordinator就会往该Presto Worker下发Task。 对于非源头Stage,coordinator会从Presto Worker中选择min(hashPartitionCount, aliveWokers)个worker,每个worker下发一个task。
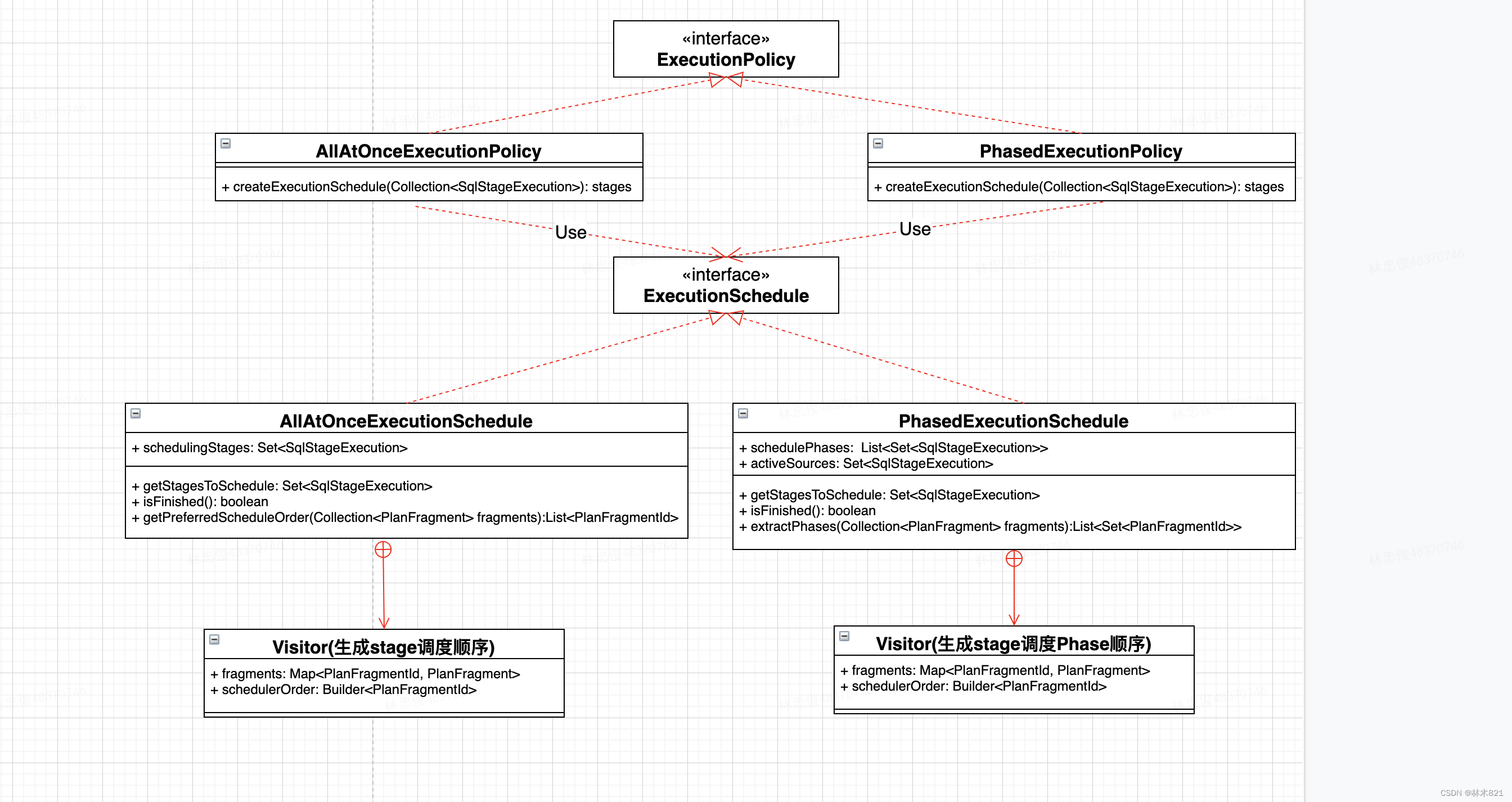
5.5 Stage调度流程(Split计算,Node选择,Task计算)
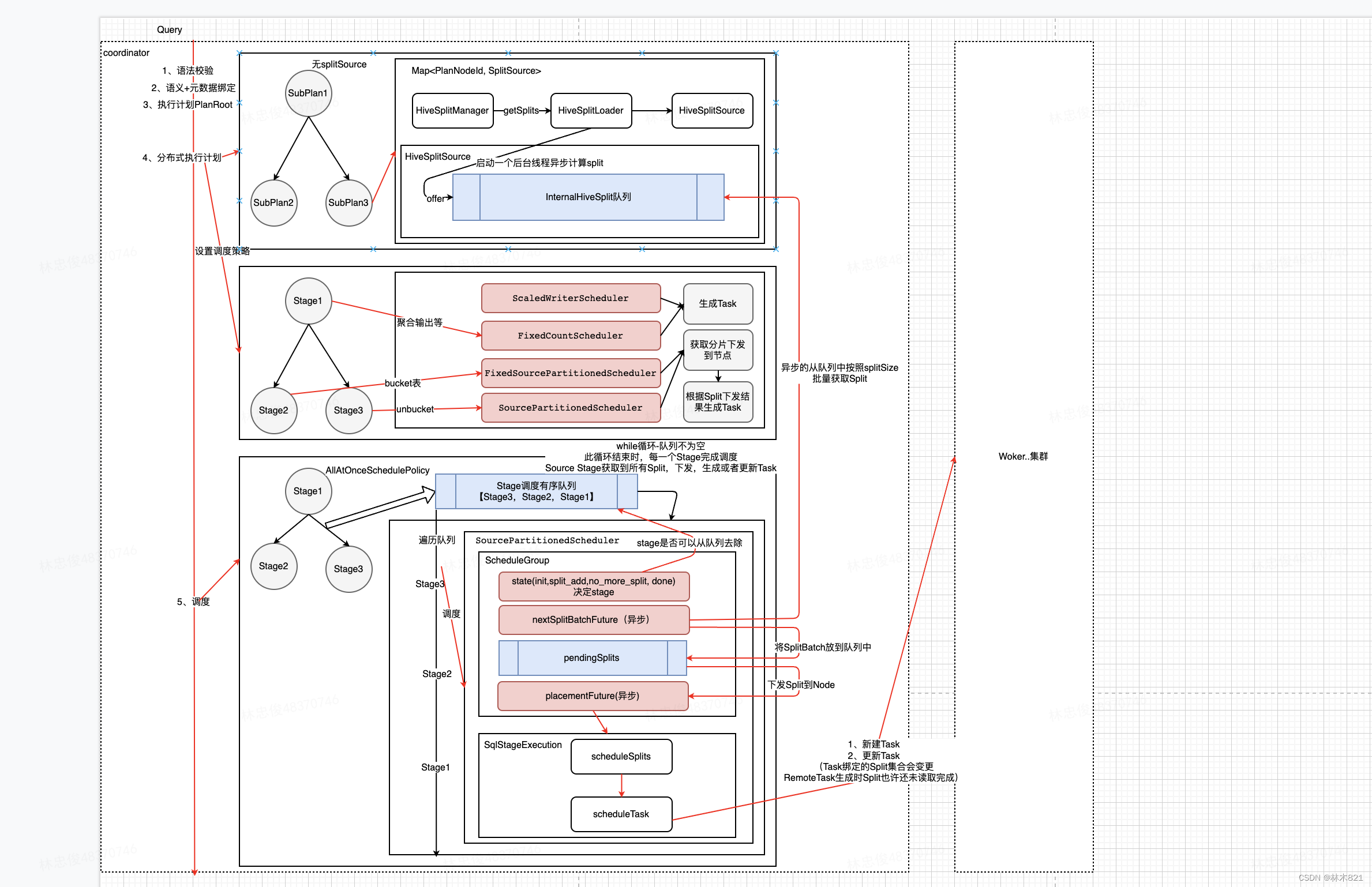
1、分布式执行计划函数planDistribution有两个功能:
-
给每个Stage生成<PlanNode,SplitSource>,即给有TableScanNode的Stage绑定SplitSource,值得注意的是SplitSource只是一个ListenerFuture,真实的Split信息刚开始计算,是启动一个额外的线程在后台进行计算
-
按照每个Stage的特性(是否是Source,PartitionningHandle的特性(表是否是Bucket表)等来给每个Stage分配StageScheduler,同时按照Stage的依赖关系构造StageLinkage的关系)
2、Split的拆分计算是异步的,在开始调度的时Split的计算进度未知,故使用一个While循环来一直判断Split是否计算完成,Split的下发是否计算完成等。调度完成的条件是每个Stage被调度完成(Split计算完成,Split下发完成,Task发送到Woker完成)
3、Split的计算,Split的下发都有可能阻塞,所以采用异步调用的方式
4、每次while执行时,如果只获取到部分Split,也会进行Split下发和Task的生成发送到woker,在后续再读取到Split时会根据Split和Node的信息来选择是新建还是更新Task,一旦处于no_more_split时则说明Stage对应的Split已经完全获取完成
5、对于非Source类型的Stage,不存在获取Split和下发Split的过程,其读取的Split为下游Stage的产出,会使用StageLinkage来维护,调度时只需要根据节点负载信息来调度task即可
5.5.1 调度策略StageScheduler-SourcePartitionedScheduler
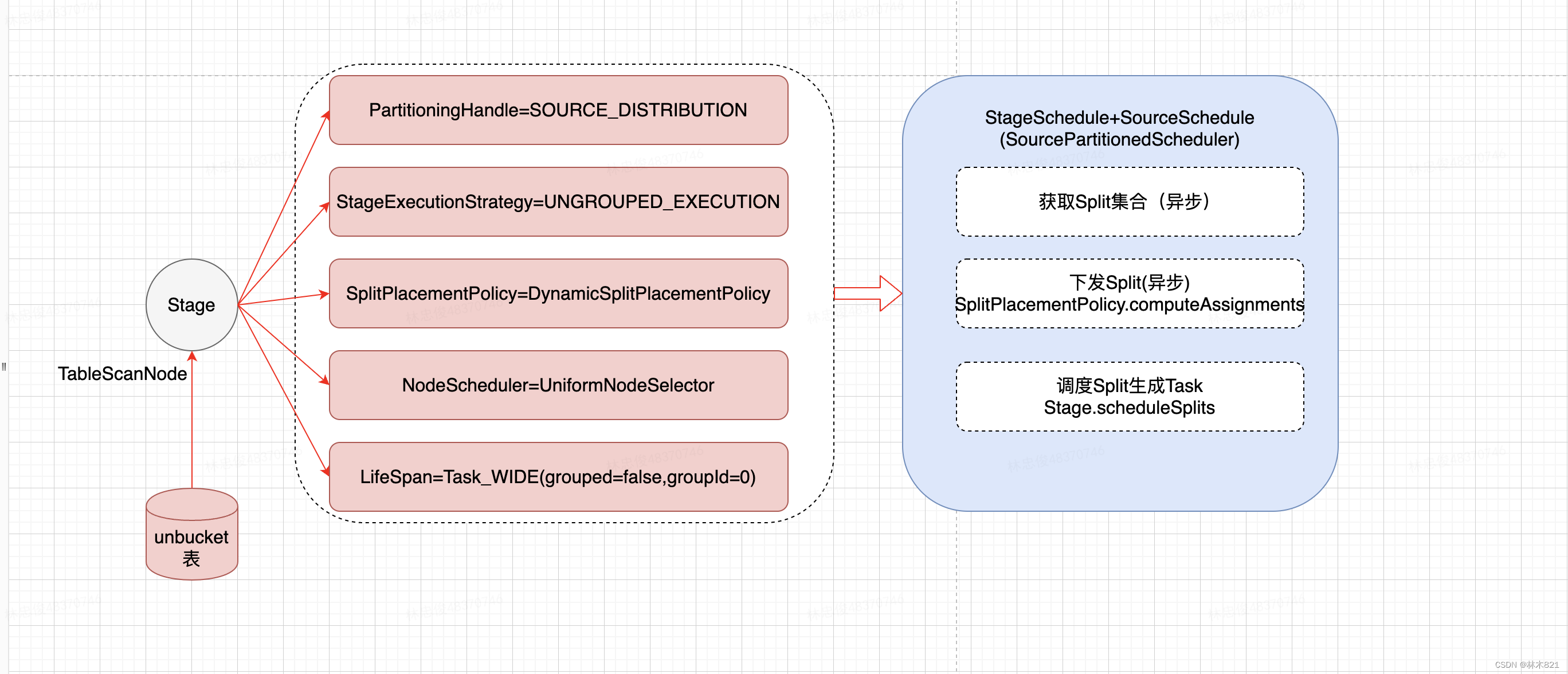
调度函数主要包括了三个部分的功能:
-
根据Stage绑定的SplitSource(CompletableFuture<ConnectorSplitBatch>)来获取SplitBatch集合,然后一直通过splitSource.getNextBatch来获取Split集合。SplitBatch包含的Split的个数和min-schedule-split-batch-size、schedule-split-batch-size参数有关
-
使用SplitPlacementPolicy来进行下发Split,即Split分配到哪个节点上,SplitPlacementResult维护下发结果
-
根据SplitPlacementResult中的split和node映射关系来生成Task,函数入口是assignSplits,结果是Set<RemoteTask>
5.5.1.1 DynamicSplitPlacementPolicy下发Split
uniform.computeAssignments
5.5.1.2 调度Split和生成Task逻辑
sourcepartitionedSchduler.assignSplits到SqlStageExecution.scheduleSplits到SqlStageExecution.scheduleTask到remoteTaskFactory.createRemoteTask
5.5.2 调度策略
StageScheduler-FixedSourcePartitionedScheduler
5.5.2.1 含有remote split的source stage(join查询)
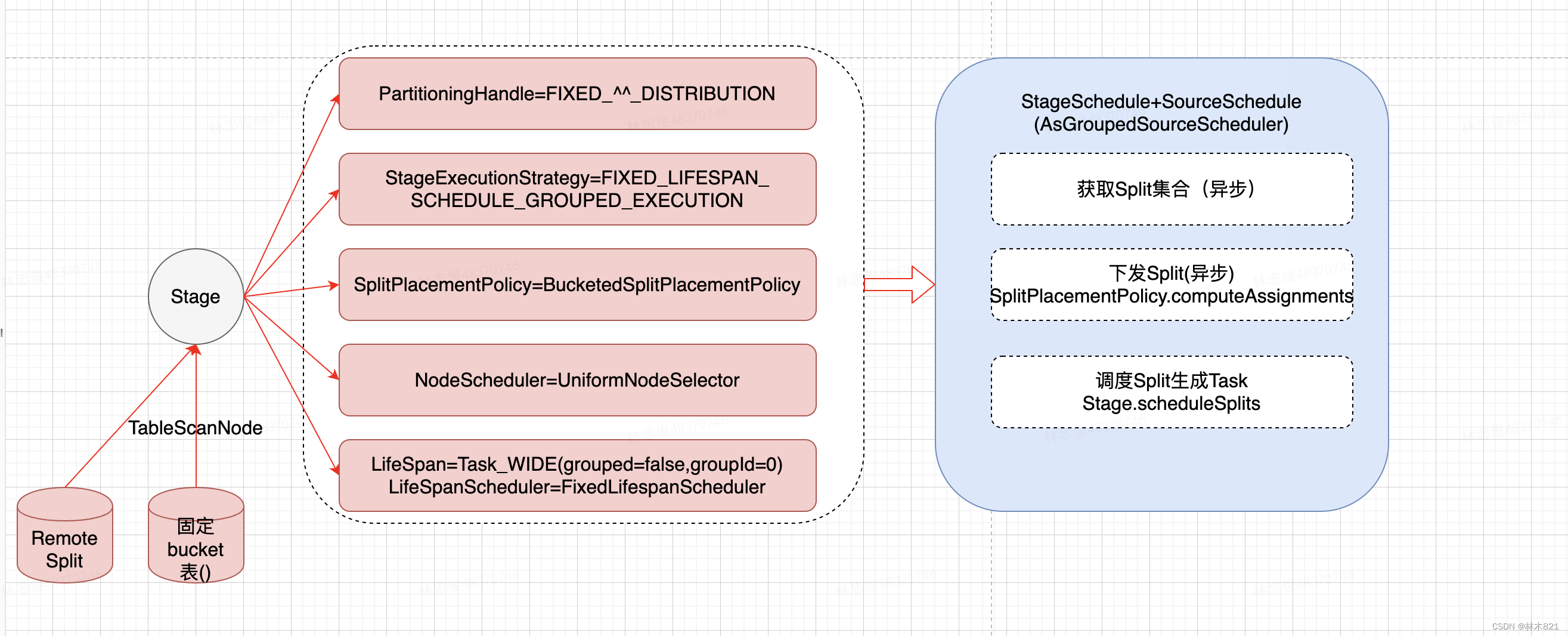


















 1835
1835





 到【灌水乐园】发言
到【灌水乐园】发言







