







进程池&&线程池
在面向对象程序编程中,对象的创建与析构都是一个较为复杂的过程,较费时间,所以为了提高程序的运行效率尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁。
所以我们可以创建一个进程池(线程池),预先放一些进程(线程)进去,要用的时候就直接调用,用完之后再把进程归还给进程池,省下创建删除进程的时间,不过当然就需要额外的开销了。
利用线程池与进程池可以使管理进程与线程的工作交给系统管理,不需要程序员对里面的线程、进程进行管理。
以进程池为例
进程池是由服务器预先创建的一组子进程,这些子进程的数目在 3~10 个之间(当然这只是典型情况)。线程池中的线程数量应该和CPU数量差不多。
进程池中的所有子进程都运行着相同的代码,并具有相同的属性,比如优先级、 PGID 等。
当有新的任务来到时,主进程将通过某种方式选择进程池中的某一个子进程来为之服务。相比于动态创建子进程,选择一个已经存在的子进程的代价显得小得多。至于主进程选择哪个子进程来为新任务服务,则有两种方法:
主进程使用某种算法来主动选择子进程。最简单、最常用的算法是随机算法和Round Robin(轮流算法)。
主进程和所有子进程通过一个共享的工作队列来同步,子进程都睡眠在该工作队列上。当有新的任务到来时,主进程将任务添加到工作队列中。这将唤醒正在等待任务的子进程,不过只有一个子进程将获得新任务的“接管权”,它可以从工作队列中取出任务并执行之,而其他子进程将继续睡眠在工作队列上。
当选择好子进程后,主进程还需要使用某种通知机制来告诉目标子进程有新任务需要处理,并传递必要的数据。最简单的方式是,在父进程和子进程之间预先建立好一条管道,然后通过管道来实现所有的进程间通信。在父线程和子线程之间传递数据就要简单得多,因为我们可以把这些数据定义为全局,那么它们本身就是被所有线程共享的。
---------------------
作者:sayhello_world
来源:CSDN
原文:https://blog.csdn.net/sayhello_world/article/details/72829329
版权声明:本文为博主原创文章,转载请附上博文链接!
池
由于服务器的硬件资源“充裕”,那么提高服务器性能的一个很直接的方法就是以空间换时间,即“浪费”服务器的硬件资源,以换取其运行效率。这就是池的概念。
池是一组资源的集合,这组资源在服务器启动之初就被创建并初始化,这称为静态资源分配。
当服务器进入正式运行阶段,即开始处理客户请求的时候,如果它需要相关的资源,就可以直接从池中获取,无需动态分配。很显然,直接从池中取得所需资源比动态分配资源的速度要快得多,因为分配系统资源的系统调用都是很耗时的。
当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用来释放资源。从最终效果来看,池相当于服务器管理系统资源的应用设施,它避免了服务器对内核的频繁访问。提高了效率。
池可以分为很多种,常见的有进程池,线城池,内存池。
---------------------
原文:https://blog.csdn.net/sayhello_world/article/details/72829329
@https://blog.csdn.net/sayhello_world/article/details/72829329
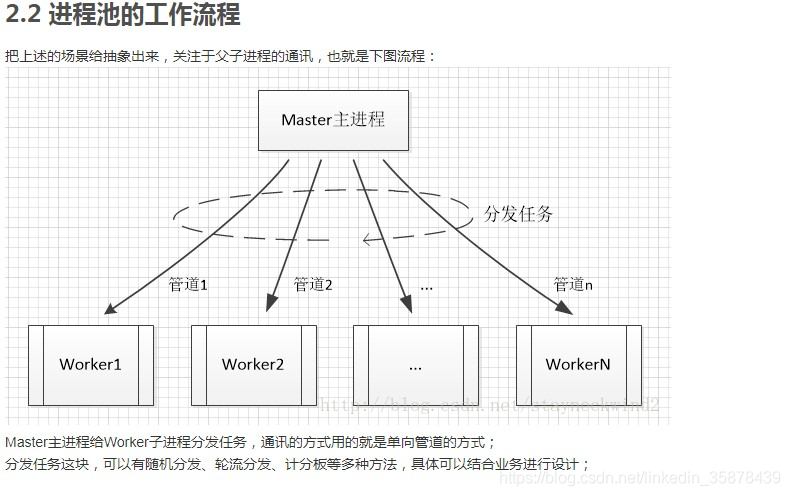
/***
*根据上述流程图进行一个简单的实现,假设分别有A、B、C三种任务,主进程使用轮流分发(Round-robin)把任务均匀地分配给子进程们;
*在结构体process上得考虑一下,Master进程需要保存所有子进程的进程号、管道号;
*
*/
#include<stdio.h>
#include <string.h>
#include<stdlib.h>
#include <errno.h>
#include <signal.h>
#include <unistd.h>
#include <sys/types.h>
#define FAILURE -1
#define u8 unsigned char
#define u16 unsigned short
#define SIZE_NAME_NORMAL 48
#define SIZE_NAME_LONG 48
#define SUCCESS 0
#define CLOSE_FD(x) (close(x))
#define FREE_POINTER(x) (free(x))
#define __offset(pinst) ((pinst)->proc[(pinst)->process_idx])
/* 写管道*/
#define __round_robin(pinst, roll) \
((pinst)->proc[((roll) % (pinst)->process_num) + 1].pipefd[1])
/***
*本节根据上述流程图进行一个简单的实现,假设分别有A、B、C三种任务,主进程使用轮流分发(Round-robin)把任务均匀地分配给子进程们;
*在结构体process上得考虑一下,Master进程需要保存所有子进程的进程号、管道号;
*
*/
/* Process struct */
typedef struct process
{
char name[SIZE_NAME_NORMAL]; /* Process name */
pid_t pid; /* Process id */
int pipefd[2]; /* Connection between master/slave */
size_t score; /* Score record */
} process_t;
/* Program instance */
typedef struct instance
{
char prg_name[SIZE_NAME_LONG]; /* Program name with path */
char cfg_name[SIZE_NAME_LONG]; /* Configure name with path */
u16 process_num; /* Sub process number */
u16 process_idx; /* Current process index */
struct process *proc; /* Process struct */
} instance_t;
static u8 g_enable; /* Running flag */
static void __sig_quit(int sig)
{
g_enable = 0;
}
static int __master(instance_t *pinst)
{
int ret = 0;
int fd = 0;
int ix = 0;
int roll = 0;
char c = 0;
printf("Master#%u setup\n", pinst->process_idx);
for ( g_enable = 1; g_enable; ) {
/* Get pipe fd by round-robin */
fd = __round_robin(pinst, ++roll);
c = 'A' + roll % 3; // 'A'/'B'/'C'
ret = write(fd, &c, 1);
if ( ret <= 0 ) {
return FAILURE;
}
sleep(1);
}
/* Tell all workers to quit */
for ( ix = 1; ix <= pinst->process_num; ix++ ) {
c = 'Q';
write(__round_robin(pinst, ++roll), &c, 1);
}
printf("Master#%u shutdown\n", pinst->process_idx);
return SUCCESS;
}
static int __worker(instance_t *pinst)
{
int fd = __offset(pinst).pipefd[0];
int ix = 0;
ssize_t read_byte = FAILURE;
char buffer[1024] = {0};
printf("Worker#%u setup\n", pinst->process_idx);
for ( g_enable = 1; g_enable; ) {
printf("work read front......\n");
read_byte = read(fd, buffer, sizeof(buffer)); /* 读管道会阻塞*/
printf("work read after......\n");
if ( read_byte <= 0 ) {
if ( errno == EAGAIN || errno == EINTR ) {
continue;
}
return FAILURE;
}
for ( ix = 0; ix < read_byte; ix++ ) {
switch ( buffer[ix] ) {
case 'A':
case 'B':
case 'C':
__offset(pinst).score += buffer[ix];
printf("Worker#%u Recv command: %c, score: %llu\n",
pinst->process_idx,
buffer[ix], __offset(pinst).score);
break;
case 'Q':
printf("Quit\n");
g_enable = 0;
break;
default:
break;
}
}
}
printf("Worker#%u shutdown\n", pinst->process_idx);
return SUCCESS;
}
int process_pool(instance_t *pinst, u16 process_num)
{
int ret = FAILURE;
int ix = 0;
int status = 0;
if ( !pinst || !process_num ) {
printf("NULL\n");
goto _E1;
}
/**
* SIGINT ctrl+c 终止进程
*/
signal(SIGINT, __sig_quit);
/** SIGTERM 程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和
*处理. 通常用来要求程序自己正常退出. shell命令kill缺省产生这
*个信号. */
signal(SIGTERM, __sig_quit);
pinst->process_idx = 0;
pinst->process_num = process_num;
pinst->proc = (process_t *)calloc(process_num + 1, sizeof(process_t));
if ( !pinst->proc ) {
printf("Alloc process pool struct failed\n");
goto _E1;
}
for ( ix = 1; ix <= process_num; ix++ ) {
int bufsize = 1;
/*fd[0]:读管道,fd[1]:写管道*/
ret = pipe(pinst->proc[ix].pipefd);
if ( SUCCESS != ret ) {
printf("socketpair\n");
goto _E2;
}
printf("Setup worker#%u\n", ix);
pinst->proc[ix].pid = fork();
if ( pinst->proc[ix].pid < 0 ) {
printf("fork\n");
goto _E2;
}
else if ( pinst->proc[ix].pid > 0 ) {
/* Father process close read fd pipe */
CLOSE_FD(pinst->proc[ix].pipefd[0]);
printf(".......\n");
continue;
}
else {
/* Child process close write fd pipe */
CLOSE_FD(pinst->proc[ix].pipefd[1]);
printf("xxxxxxxx\n");
pinst->process_idx = ix;
ret = __worker(pinst);
goto _E2;
}
}
ret = __master(pinst);
/* Waiting workers */
for ( ix = 1; ix <= pinst->process_num; ix++ ) {
waitpid(pinst->proc[ix].pid, &status, WNOHANG);
}
_E2:
for ( ix = 1; ix <= pinst->process_num; ix++ ) {
CLOSE_FD(pinst->proc[ix].pipefd[1]);
CLOSE_FD(pinst->proc[ix].pipefd[0]);
}
FREE_POINTER(pinst->proc);
_E1:
return ret;
}
int main(int argc, char *argv[])
{
instance_t inst = {0}; /*实例结构体*/
if ( argc < 2 ) {
printf("Usage: \n\t%s < process number >\n", argv[0]);
return EXIT_FAILURE;
}
return process_pool(&inst, atoi(argv[1]));
}














 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









