







目录
1.进程调度基本概念
1.1调度策略
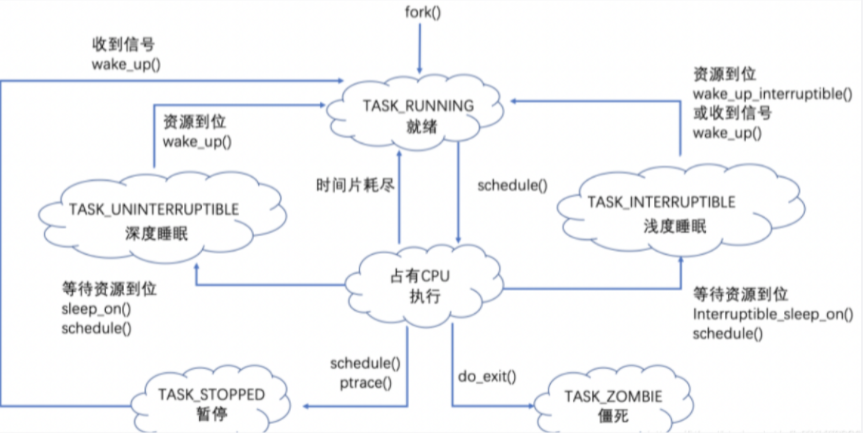
进程调度的概念比较简单,我们假设在一个单核处理器的系统中,同一时刻只有一个进程可以拥有处理器资源,那么其他的进程只能在就绪队列中等待,等到处理器空闲之后才有计划获得处理器资源来运行。在这种场景下,操作系统就需要从众多的就绪进程中选择一个最合适的进程来运行,这个就是调度器需要做的事情。linux内核管理过程中是按照线程完成调度工作,与线程所属进程基本上没有什么关系。
调度策略:传统Uniⅸx操作系统的调度算法必须实现几个互相冲突的目标:进程响应时间尽可能快,后台作业的吞吐量尽可能高,尽可能避免进程的饥饿现象,低优先级和高优先级进程的需要尽可能调和等等。决定什么时候以怎样的方式选择一个新进程运行的这组规则就是所谓的调度策略( scheduling policy)。
1.2进程分类与调度
在 Linux中,进程的优先级是动态的。调度程序跟踪进程正在做什么,并周期性地调整它们的优先级。在这种方式下,在较长的时间间隔内没有使用CPU的进程,通过动态地增加它们的优先级来提升它们。相应地,对于已经在CPU上运行了较长时间的进程,通过减少它们的优先级来处罚它们。站在CPU的角度来看进程,有些进程一直占用处理器,有些进程只需要一部分处理器资源即可。所以进程按照这个特性可以分为两类:
(1)CPU消耗型:把大部分的时间用在运行代码上,并且会一直占用CPU。一个常见的例子就是while循环的运行,如运行大量计算的程序等。
(2)IO消耗型:IO消耗性的进程会把大部分的时间用在提交I/O请求或等待I/O请求,所以这类的进程通常只需要很少的处理器计算资源即可,如需要键盘的输入进程或等待网路I/O的进程。
另一种分类方法:
(1)交互式进程:经常需要与用户进行交互;
(2)批处理进程:不需要与用户交互,经常在后台运行,会受到调度程序的慢待,如编译程序等;
(3)实时进程:不会被第优先级的进程阻塞,应该有一个很短的响应时间;
Linux2.6调度程序实现了基于进程过去行为的启发式算法,以确定进程应该被当做交互式进程还是批处理进程。
存在调度的基本情况如下:
(1)在创建子进程以后,父进程与子进程执行顺序需要调度;
(2)一个进程退出时需要确定调度;
(3)当一个进程阻塞在I/O和信号量上时,需要调度其他进程进入执行;
(4)当I/O中断发生时,必须做出调度决策;
1.3交互式系统中的调度
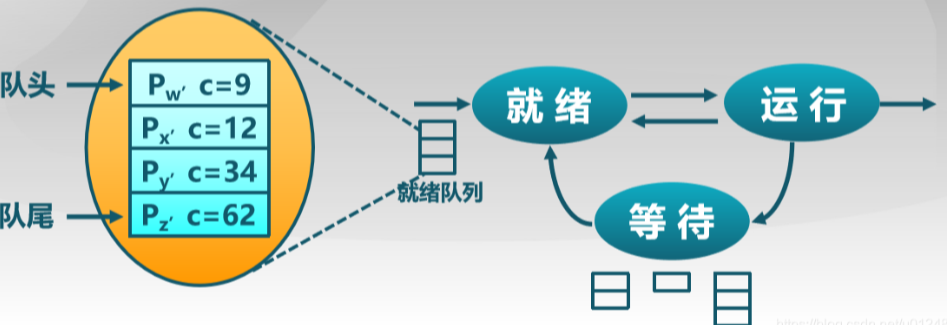
1.3.1先来先服务算法(FCFS)
每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择第一个进程接着运行。

优点:算法简单;
缺点:平均等待时间波动较大,短进程可能会排到长进程后面;IO资源和CPU资源利用率较低;
1.3.2短进程优先算法(SPN)
选择就绪队列中执行时间最短进程占用CPU进入运行状态,就绪队列按预期的执行时间来排序;
优点:平均周转时间较短;
缺点:不公平,可能导致出现饥饿,连续的短进程流会使得长进程长时间无法获得CPU资源;平均响应时间过长;需要预知未来,需要解决预估下一个CPU计算的持续时间;
1.3.3时间片轮转算法(RR)
每个进程被分配一个时间段,称为时间片(*Quantum*),即允许该进程在该时间段中运行。如果时间片用完,进程还在运行,那么将会把此进程从 CPU 释放出来,并把 CPU 分配另外一个进程;如果该进程在时间片结束前阻塞或结束,则 CPU 立即进行切换;
1.4调度优先级
对于操作系统中的任务是不同的,例如,系统进程和用户进程、前台进程和后台进程,如果不加以区分,那么系统中关键的任务无法及时处理,后台运算导致视频播放卡顿,所以基于此,重要的任务需要被优先调度,就产生了优先级的概念。
1.4.1多队列调度算法(MQ)
对于该调度算法,就绪队列被划分成多个独立的子队列,如前台(交互)、后台(批处理),每个队列拥有自己的调度策略,如前台-RR,后台-FCFS,队列间的调度。
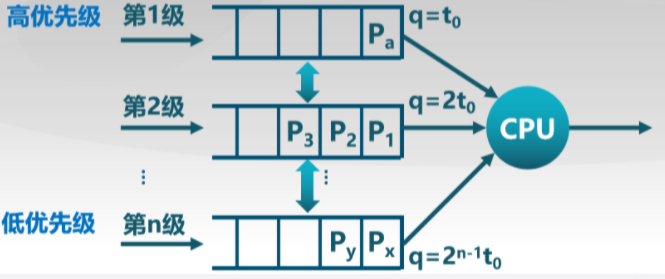
算法特点:维护多个优先级队列;高优先级的任务优先执行;同优先级内使用RR调度;
2.进程调度
每个普通进程都有它自己的静态优先级,调度程序使用静态优先级来估价系统中这个进程与其他普通进程之间调度的程度。内核用从100(最高优先级)到139(最低优先级)的数表示普通进程的静态优先级。注意,值越大静态优先级越低。
struct task_struct {
//prio是动态调度优先级,static_prio静态优先级进程启动时分配,内核不使用nice值使用静态优先级。normal_prio是基于static_prio和调度策略计算出来的优先级
int prio, static_prio, normal_prio;
unsigned int rt_priority; //实时进程优先级
}内核使用0-139数值表示进程优先级,数值越小,优先级越高。优先级0-99给实时进程使用,100-139给普通进程使用。另外,在用户空间中有一个传统的变量nice,用于映射普通进程的优先级,即100~139。
2.1基本时间片
静态优先级本质上决定了进程的基本时间片,即进程用完了以前的时间片时,系统分配给进程的时间片长度。静态优先级和基本时间片的关系用下列公式确定:

普通进程除了静态优先级,还有动态优先级,其值的范围是100(最高优先级)~139(最低优先级)。动态优先级是调度程序在选择新进程来运行的时候使用的数。它与静态优先级的关系用下面的经验公式表示。
![]()
bonus是范围从0~10的值,值小于5表示降低动态优先级以示惩罚,值大于5表示增加动态优先级以示奖赏。 bonus的值依赖于进程过去的情况,说得更准确一些,是与进程的平均睡眠时间相关。除了使用优先级来表示进程的轻重缓急之外,在实际调度器中还是用了权值来表示进程的优先级,为了计算方便,内核约定nice值为0的进程权重为1024,其他的nice值对应的进程权重值可以通过查表的方式来获取,内核预先计算好了一个表prio_to_weight,表的下标对应Nice值为[-20 ~ 19]。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};2.2调度时机及调度策略
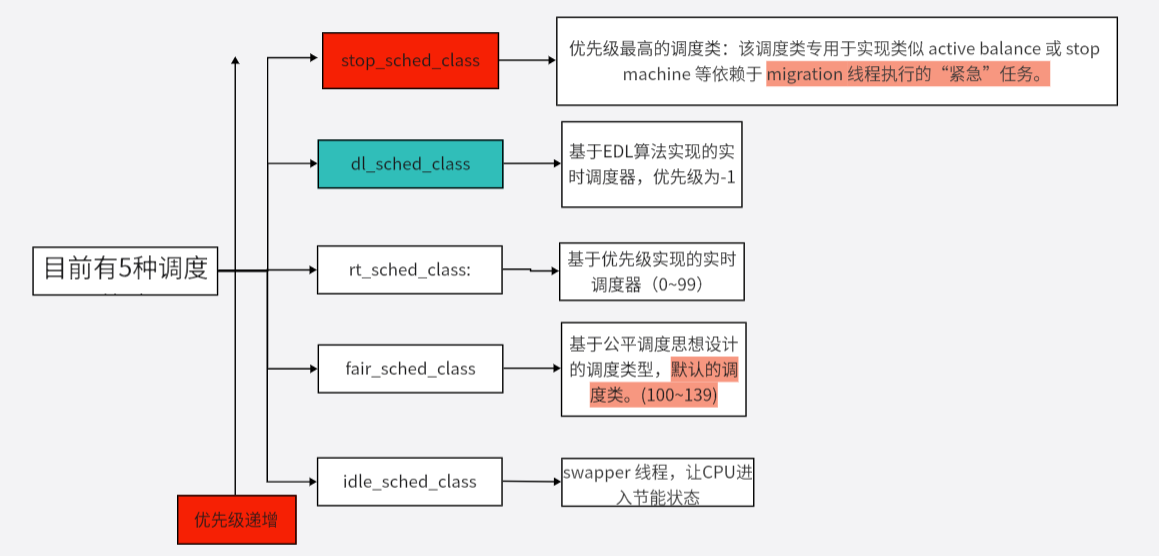
linux调度依赖于调度策略,Linux内核把相同的调度策略抽象成调度类(schedule class)。不同类型的进程采用不同的调度策略,目前Linux内核默认实现了5种调度类,分别是stop、deadline、realtime、CFS和idle,他们分别使用sched_class来实现,并且通过next指针串联在一起 。
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 63.调度算法
3.1 O(n)调度算法
Linux 0.11版本就已经有一个简单的调度器,当然并不适合现在的多处理器的系统。该调度器值维护了一个全局的进程队列,每次都需要遍历该队列来寻找新的进程执行。
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +(*p)->priority;
}
switch_to(next);
}linux2.4版本的linux内核使用的调度算法也非常简单和直接,由于每次在寻找下一个任务时,需要遍历系统中所有的任务链表,所以被称为O(n)调度器。
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
struct list_head *tmp;
int this_cpu, c;
spin_lock_prefetch(&runqueue_lock);
BUG_ON(!current->active_mm);
need_resched_back:
prev = current;
this_cpu = prev->processor; //记录当前进程信息
if (unlikely(in_interrupt())) { //判断是否处于中断当中,不允许在中断中发生调度
printk("Scheduling in interrupt\n");
BUG();
}
release_kernel_lock(prev, this_cpu); //每个CPU只能运行一个进程
/*
* 'sched_data' is protected by the fact that we can run
* only one process per CPU.
*/
sched_data = & aligned_data[this_cpu].schedule_data;
spin_lock_irq(&runqueue_lock);
/* move an exhausted RR process to be last.. */
if (unlikely(prev->policy == SCHED_RR)) //如果当前是RR调度,那么需要判断当前进程的时间片是否已经用完,如果用完,重新计算,然后将该进程加入到就绪列表中
if (!prev->counter) {
prev->counter = NICE_TO_TICKS(prev->nice);
move_last_runqueue(prev);
}
switch (prev->state) {
case TASK_INTERRUPTIBLE: //如果当前进程为TASK_INTERRUPTIBLE,如果信号来了,就唤醒进程并置位
if (signal_pending(prev)) {
prev->state = TASK_RUNNING;
break;
}
default://如果是其他状态,就将该进程转为睡眠状态,并从运行队列中删去
del_from_runqueue(prev);
case TASK_RUNNING:;
}
prev->need_resched = 0;
/*
* this is the scheduler proper:
*/
repeat_schedule:
/*
* Default process to select..
*/
next = idle_task(this_cpu); //默认进程
c = -1000;
//遍历进程就绪列表,如果该进程可以被调度则计算优先级,如果优先级大于当前进程优先级,则next指针指向新进程,直到找到优先级最大的进程
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);
if (can_schedule(p, this_cpu)) {
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
/* Do we need to re-calculate counters? */
if (unlikely(!c)) { //判断是否需要重新计算每个进程的时间片
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);
read_lock(&tasklist_lock);
for_each_task(p) //重新计算时间片
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
goto repeat_schedule; //返回重新调度过程,重新找优先级最高的进程调度
}
/*
* from this point on nothing can prevent us from
* switching to the next task, save this fact in
* sched_data.
*/
sched_data->curr = next;
task_set_cpu(next, this_cpu);//当前进程与CPU进行绑定
spin_unlock_irq(&runqueue_lock);
if (unlikely(prev == next)) { //如果是同一个进程则不需要调度
/* We won't go through the normal tail, so do this by hand */
prev->policy &= ~SCHED_YIELD;
goto same_process;
}
#ifdef CONFIG_SMP
/*
* maintain the per-process 'last schedule' value.
* (this has to be recalculated even if we reschedule to
* the same process) Currently this is only used on SMP,
* and it's approximate, so we do not have to maintain
* it while holding the runqueue spinlock.
*/
sched_data->last_schedule = get_cycles();
/*
* We drop the scheduler lock early (it's a global spinlock),
* thus we have to lock the previous process from getting
* rescheduled during switch_to().
*/
#endif /* CONFIG_SMP */
kstat.context_swtch++;
/*
* there are 3 processes which are affected by a context switch:
*
* prev == .... ==> (last => next)
*
* It's the 'much more previous' 'prev' that is on next's stack,
* but prev is set to (the just run) 'last' process by switch_to().
* This might sound slightly confusing but makes tons of sense.
*/
prepare_to_switch();
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (!mm) {
BUG_ON(next->active_mm);
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next, this_cpu);
} else {
BUG_ON(next->active_mm != mm);
switch_mm(oldmm, mm, next, this_cpu);
}
if (!prev->mm) {
prev->active_mm = NULL;
mmdrop(oldmm);
}
}
/*
* This just switches the register state and the
* stack.
*/
switch_to(prev, next, prev);
__schedule_tail(prev);
same_process:
reacquire_kernel_lock(current);
if (current->need_resched)
goto need_resched_back;
return;
}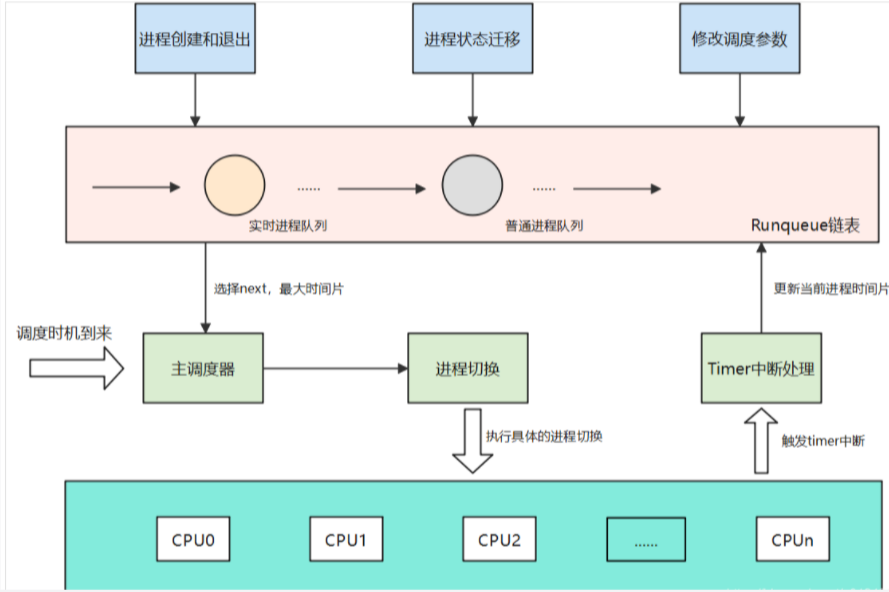
基本思想:O(n)调度器采用一个Runqueue运行队列来管理所有可运行的进程,在主调度schedule函数中选择一个优先级最高,也就是时间片最大的进程来运行,同时也会对喜欢睡眠的进程做奖励,去增加此类进程的时间片当Runqueue运行队列中无进程可选择时,则会对系统中所有的进程进行依次重新计算时间片的操作。
3.2 O(1)调度算法
O(n)调度器存在的缺点:时间复杂度为O(n),当系统中就绪队列中的进程数目增多,那么调度器的运算量就会线性增长,为每个进程计算其时间片的过程太耗费时间。多核处理器扩展问题,多处理器的进程在同一个就绪队列中,因此调度器对它的所有操作都会因为全局自旋锁而导致系统各个处理器之间的等待,使的就绪队列称为明显的瓶颈。实时进程不能及时调度,内核不可抢占,如果某个进程,一旦进入内核态,那么再高优先级的进程都无法剥夺,只有等进程返回用户态的时候才可以被调度。
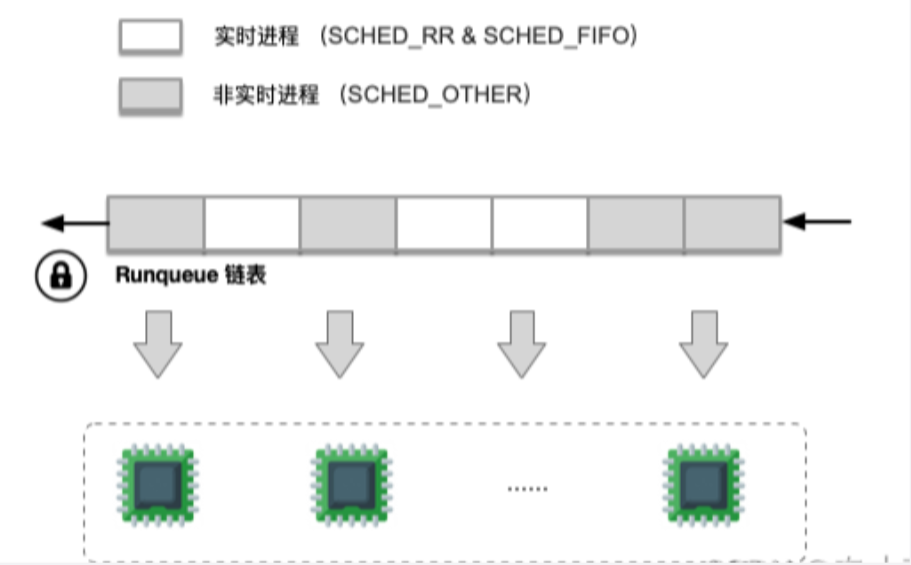
对于O(n)调度器会在所有进程的时间片用完后,才会重新计算任务的优先级。而O(1)调度器则是在每个进程时间片用完后,就重新计算优先级。对于O(1)调度器为每个CPU维护了两个队列。为了减小多核CPU之间的竞争,所以每个CPU都需要维护一份本地的优先级队列,因为如果使用全局的优先级,那么多核CPU就需要对全局优先队列进行上锁,从而导致性能下降。runqueue结构主要维护调度相关的信息。
struct runqueue {
spinlock_t lock;
//nr_running可运行进程总数
unsigned long nr_running, nr_switches, expired_timestamp,
nr_uninterruptible;
task_t *curr, *idle;
struct mm_struct *prev_mm;
//active队列指针,expired队列指针,实现存放不同优先级对应的任务链表
prio_array_t *active, *expired, arrays[2];
int prev_cpu_load[NR_CPUS];
#ifdef CONFIG_NUMA
atomic_t *node_nr_running;
int prev_node_load[MAX_NUMNODES];
#endif
task_t *migration_thread;
struct list_head migration_queue;
atomic_t nr_iowait;
};
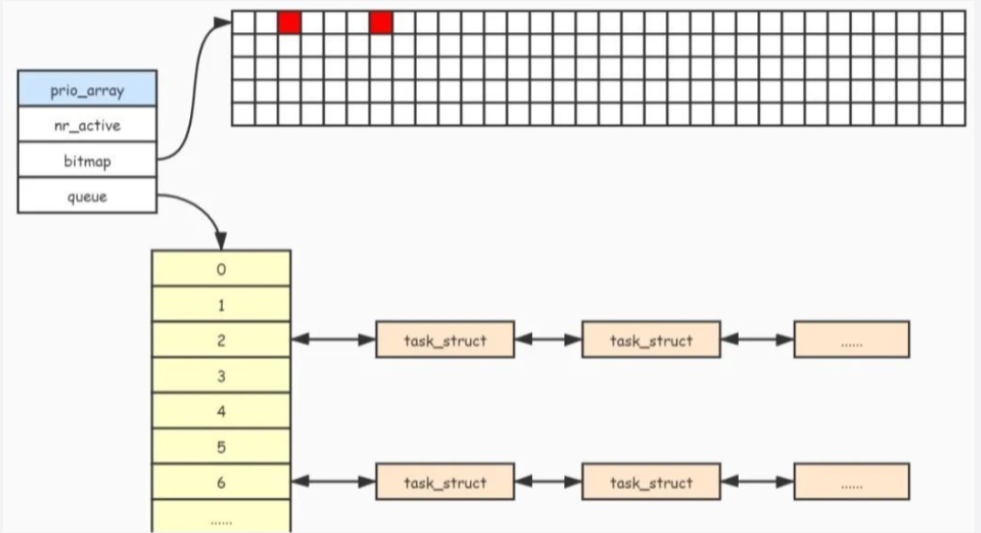
struct prio_array {
int nr_active; //列表中的任务总数
unsigned long bitmap[BITMAP_SIZE]; //位图表示对应优先级链表是否有任务存在
struct list_head queue[MAX_PRIO]; //任务列表,每种优先级对应一个双向链表
};bitmap位图的作用:每个位对应一个优先级的任务队列,用于记录那个任务队列不为空,通过bitmap快速找到不为空的任务队列;
调度算法的实现
(1)与之前的内核一样,内核会设置一个时钟tick,在时钟tick中会进入时钟中断,最终会触发调用scheduler_tick函数;
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id(), system = user_tick ^ 1;
update_one_process(p, user_tick, system, cpu);
run_local_timers();
scheduler_tick(user_tick, system); //周期调度函数
}如果时间片用完,那么把进程从active队列移动到expired队列中。如果当前runqueue的active队列为空,那么把队列active与expired队列进行互换。
void scheduler_tick(int user_ticks, int sys_ticks)
{
int cpu = smp_processor_id();
struct cpu_usage_stat *cpustat = &kstat_this_cpu.cpustat;
runqueue_t *rq = this_rq();
task_t *p = current;
if (rcu_pending(cpu))
rcu_check_callbacks(cpu, user_ticks);
/* note: this timer irq context must be accounted for as well */
if (hardirq_count() - HARDIRQ_OFFSET) {
cpustat->irq += sys_ticks;
sys_ticks = 0;
} else if (softirq_count()) {
cpustat->softirq += sys_ticks;
sys_ticks = 0;
}
if (p == rq->idle) {
if (atomic_read(&rq->nr_iowait) > 0)
cpustat->iowait += sys_ticks;
else
cpustat->idle += sys_ticks;
rebalance_tick(rq, 1);
return;
}
if (TASK_NICE(p) > 0)
cpustat->nice += user_ticks;
else
cpustat->user += user_ticks;
cpustat->system += sys_ticks;
/* Task might have expired already, but not scheduled off yet */
if (p->array != rq->active) {
set_tsk_need_resched(p);
goto out;
}
spin_lock(&rq->lock);
/*
* The task was running during this tick - update the
* time slice counter. Note: we do not update a thread's
* priority until it either goes to sleep or uses up its
* timeslice. This makes it possible for interactive tasks
* to use up their timeslices at their highest priority levels.
*/
if (unlikely(rt_task(p))) {
/*
* RR tasks need a special form of timeslice management.
* FIFO tasks have no timeslices.
*/
if ((p->policy == SCHED_RR) && !--p->time_slice) {
p->time_slice = task_timeslice(p);
p->first_time_slice = 0;
set_tsk_need_resched(p);
/* put it at the end of the queue: */
dequeue_task(p, rq->active);
enqueue_task(p, rq->active);
}
goto out_unlock;
}
if (!--p->time_slice) {
dequeue_task(p, rq->active);
set_tsk_need_resched(p);
p->prio = effective_prio(p);
p->time_slice = task_timeslice(p);
p->first_time_slice = 0;
if (!rq->expired_timestamp)
rq->expired_timestamp = jiffies;
if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) {
enqueue_task(p, rq->expired);
} else
enqueue_task(p, rq->active);
} else {
/*
* Prevent a too long timeslice allowing a task to monopolize
* the CPU. We do this by splitting up the timeslice into
* smaller pieces.
*
* Note: this does not mean the task's timeslices expire or
* get lost in any way, they just might be preempted by
* another task of equal priority. (one with higher
* priority would have preempted this task already.) We
* requeue this task to the end of the list on this priority
* level, which is in essence a round-robin of tasks with
* equal priority.
*
* This only applies to tasks in the interactive
* delta range with at least TIMESLICE_GRANULARITY to requeue.
*/
if (TASK_INTERACTIVE(p) && !((task_timeslice(p) -
p->time_slice) % TIMESLICE_GRANULARITY(p)) &&
(p->time_slice >= TIMESLICE_GRANULARITY(p)) &&
(p->array == rq->active)) {
dequeue_task(p, rq->active);
set_tsk_need_resched(p);
p->prio = effective_prio(p);
enqueue_task(p, rq->active);
}
}
out_unlock:
spin_unlock(&rq->lock);
out:
rebalance_tick(rq, 0);
}

不过O(1)调度器在根据"nice"值确定时间片的算法上,存在一些瑕疵。它所使用的的规则大致是这样的:"nice"为0的任务可以运行100ms,"nice"值每增加1,可运行时间将减少5ms,照此推算,"nice"为+19的任务可以运行5ms。如果一个任务"nice"是0,另一个是1,那么可运行时间分别是100ms和95ms,差别不大,但如果一个是18,另一个是19,那么可运行时间分别是10ms和5ms,差了一倍。此外,前一种场景的任务切换每105ms发生一次,而后一种场景则是每15ms一次,调度周期的长度并不固定。内核演变就出现了完全公平的调度算法。
3.3CFS调度算法
在O(n)和O(1)调度器中,每当系统时钟中断来临,调度器就从当前任务的时间片中减去一个时钟周期,直至时间片耗完,这个时候当前任务返回用户空间,换成其他任务执行。以往的调度器把动态优先级和时间片绑定在一起,高优先级的进程获得时间片,而低优先级的进程获得短的时间片,调度器优先调度具有时间片长的任务,但是时间片长的任务不一定是当下最需要cpu时间的任务,这样的算法存在一定的缺点,例如:

针对以上问题,linux2.6.23版本引入了CFS(Complete Fair Scheduler),引入了公平性的概念。
3.3.1CFS调度器基本思想
基本思想:使得每一个进程都尽可能“公平”地获得运行时间,因此每次都选择过去运行的最少的进程去运行。
(1)CFS调度器和以往调度器不同之处在于没有时间片的概念,而是分配CPU使用时间的比例;
(2)CFS为了实现公平,必须惩罚当前正在运行的进程,以使得哪些正在等待的进程下一次被调度;
CFS引入了虚拟运行时间(vruntime),每个调度实体的运行时间,任务的虚拟运行时间越小,意味着任务被访问的时间越短,其对处理器的需求就越高,其核心的思想表现如下:
(1)进程运行的时间相等;
(2)对睡眠的进程进行补偿;
每个进程都有一个vruntime值,根据不同的权重,vruntime就是该进程实际运行时间,得到这个vruntime后,系统将会根据vruntime的排序,基于红黑树,vruntime最小进程会最早得到调度。
CFS针对优先级问题引入了权重,由权重表示进程的优先级,各个进程按照权重的比例分配CPU的时间,因此CFS调度器的公平保证所有可运行状态的进程按照权重分配其CPU资源。实际运行时间的计算如下:
实际运行时间 = 调度周期*进程权重/所有进程权重之和。
CFS使用nice值来表示优先级,取值范围为[-20,19],nice值与权重是一一对应关系,进程每降低一个nice几倍,优先级提高一个级别,相应进程多获得10%的CPU时间。内核本身选择范围[0,139]来表示优先级。
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p); //对于普通进程,优先级不会发生变化
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
*/
//如果不是实时进程,返回前面normal_prio的计算结果
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}如果进程A和进程B的nice值都为0,那么权重值就是1024,那么它们将获得50%的CPU时间,计算公式为1024/(1024+1024) = 50%,假设进程A增加nice值,此时变成nice = 1,那么进程B理论上将获得55%的CPU时间,而进程A应该获得45%的CPU时间,我们利用prio_to_weight表来计算,对于进程A,其获得CPU时间为820/(820+1024)=44.5%,对于进程B,其获得CPU时间为1024/(820+1024)=55.5%。
有了CPU运行权重后,内核就可以根据权重值计算出进程的虚拟运行时间(virtual runtime).“虚拟运行时间”,就是内核根据进程运行的实际时间和权重计算出来的一个时间,CFS调度器只需要保证在同一个CPU上面运行的进程,其虚拟运行时间一致即可。例如

很明显,2个进程实际的运行时间不相等,但是CFS想保证每个进程运行时间都相等,因此CFS引入了虚拟时间的概念,经过一个公式的转换就可以得到一样的值,这个转换后的值是虚拟时间。vruntime与实际运行时间转换公式:
virture_runtime = 实际运行时间*NICE_0_LOAD/weight
所以,对于上图的进程A和B的虚拟运行时间分别为:3.3*1024/1024 = 3.3ms, 2.7*1024/820 = 3.3。为了避免浮点数的计算,内核采用先放大在缩小的方式保证计算精度:
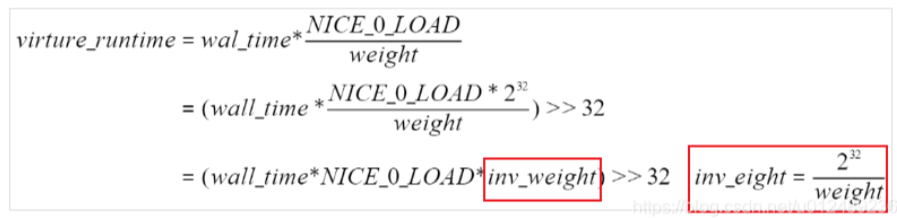
对于权重的值,已经预先计算好,保留在prio_to_wmult中:
static const u32 prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
内核中使用load_weight记录进程对应的weight和inv_weight:
struct load_weight {
unsigned long weight; //进程对应的权重
u32 inv_weight; //存储了权重值用于重除的结果wight*inv_weight = 2^32
};set_load_weight()负责根据非实时进程类型及其静态优先级计算权重,实时进程不需要CFS调度,因此不需要计算权重值:
static void set_load_weight(struct task_struct *p)
{
//由于数组中的下标是0~39, 普通进程的优先级是[100~139],将静态优先级转换成为数组下标
//权重值取决于static_prio,减去100而不是120,对应了下面数组下标
int prio = p->static_prio - MAX_RT_PRIO;
//task_statuct->se.load获取权重的信息
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
* 必须保证SCHED_IDLE进程的负荷权重最小
* 其权重weight就是WEIGHT_IDLEPRIO
* 而权重的重除结果就是WMULT_IDLEPRIO
*/
if (p->policy == SCHED_IDLE) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
/* 设置进程的负荷权重weight和权重的重除值inv_weight */
load->weight = scale_load(prio_to_weight[prio]);
load->inv_weight = prio_to_wmult[prio];
}内核中使用函数__calc_delta()来将实际时间转换为虚拟时间:
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight); //fact=weight
int shift = WMULT_SHIFT; //32
__update_inv_weight(lw); //更新load_weight->inv_weight
if (unlikely(fact >> 32)) {
while (fact >> 32) {
fact >>= 1;
shift--;
}
}
/* hint to use a 32x32->64 mul */
fact = (u64)(u32)fact * lw->inv_weight;
while (fact >> 32) {
fact >>= 1;
shift--;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}对于vruntime的理解:假如系统中有3个进程A、B、C
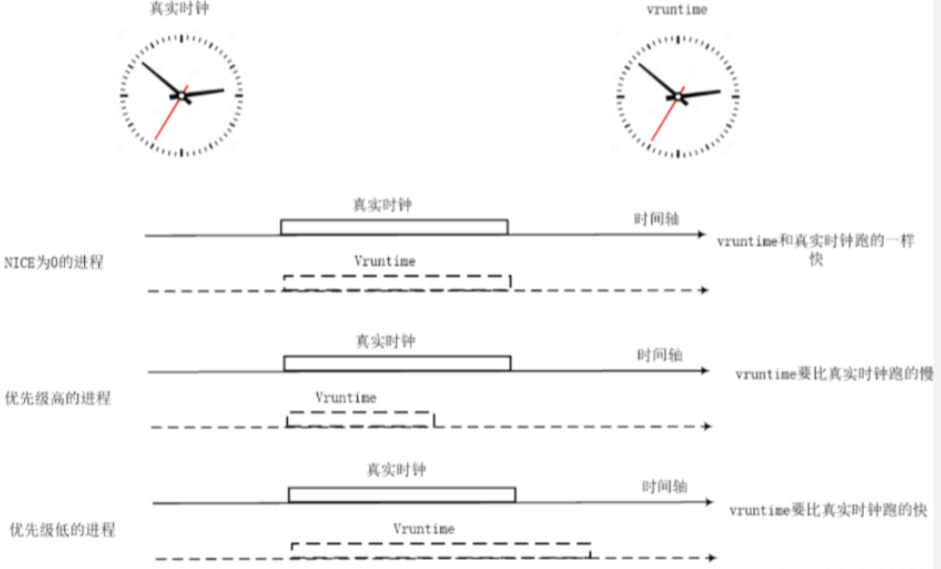
nice值越小的进程,优先级高且权重越大,vruntime值越小,其虚拟时钟比真实时钟跑的慢,也就可以获得比较多的运行时间。
nice值越大的进程,优先级低且权重越低,vruntime值越大,其虚拟时钟比真实时钟跑的快,反而获得比较少的运行时间。
CFS调度器总是选择虚拟时钟跑得慢的进程,它像一个多级变速箱,NICE为0的进程是基准齿轮,其他各个进程在不同的变速比下相互追赶,从而达到公正公平。
3.3.2调度延迟
调度延迟就是保证每一个可运行进程都至少运行一次的时间间隔,如果保持调度延时不变,例如固定是6ms,那么系统中如果有两个进程,那么每个进程的运行时间为3ms;但是如果系统中有100个进程,那么每个CPU分配到时间片就为0.06ms,将会导致系统的进程调度太过于频繁,上下文切换时间开销就变大。所以CFS调度器的调度延迟的设定并不是固定的。
当系统就绪态进程个数超过这个值时,我们保证每个进程至少运行一定的时间才让出cpu。这个“至少一定的时间”被称为最小粒度时间。在CFS默认设置中,最小粒度时间是0.75ms。用变量sysctl_sched_min_granularity记录。因此,调度周期是一个动态变化的值。调度周期计算函数是__sched_period()。
// 调度周期的计算流程,保证每个task至少跑一遍
// 大概是max(nr_running * 0.75ms, 6ms),nr大于8就取左边
// 6ms并不是一个传统意义上的时间片概念,只是一个CPU密集型task的调度抢占延迟
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}4 进程切换
对于用户进程,其任务描述符(task_struct)的mm和active_mm相同,都是指向其进程地址空间的进程描述符mm_struct。对于内核线程而言,其task_struct的mm成员为NULL(内核线程没有进程地址空间),但是,内核线程被调度执行的时候,总是需要一个进程地址空间,而active_mm就是指向它借用的那个进程地址空间,所以mm为空的话,说明B进程是内核线程,这时候,只能借用A进程当前正在使用的那个地址空间(prev->active_mm)。注意:这里不能借用A进程的地址空间(prev->mm),因为A进程也可能是一个内核线程,不拥有自己的地址空间描述符。
如果要切入的B进程是内核线程,那么由于是借用当前正在使用的地址空间,因此没有必要调用switch_mm_irqs_off进行地址空间切换,只有要切入的B进程是一个普通进程的情况下(有自己的地址空间)才会调用switch_mm_irqs_off,真正执行地址空间切换。switch_to完成了具体prev到next进程的切换,当switch_to返回的时候,说明A进程再次被调度执行了。
static inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
/* 完成进程切换的准备工作 */
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm; //指向A进程当前正在使用的地址空间描述符
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) {/* 内核线程无虚拟地址空间, mm = NULL*/
/* 内核线程的active_mm为上一个进程的mm
* 注意此时如果prev也是内核线程,
* 则oldmm为NULL, 即next->active_mm也为NULL */
next->active_mm = oldmm;
/* 增加mm的引用计数 */
atomic_inc(&oldmm->mm_count);
/* 通知底层体系结构不需要切换虚拟地址空间的用户部分
* 这种加速上下文切换的技术称为惰性TBL */
enter_lazy_tlb(oldmm, next);
} else/* 不是内核线程, 则需要切切换虚拟地址空间 */
switch_mm(oldmm, mm, next);
/* 如果prev是内核线程或正在退出的进程
* 就重新设置prev->active_mm
* 然后把指向prev内存描述符的指针保存到运行队列的prev_mm字段中
*/
if (!prev->mm) {
/* 如果需要切换 的进程为内核线程 */
prev->active_mm = NULL;
/* 更新运行队列的prev_mm成员 */
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
lockdep_unpin_lock(&rq->lock);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
/* Here we just switch the register state and the stack.
*/
//切换进程的执行环境,包括堆栈和寄存器,同时返回上一个执行的程序,所以有三个参数
switch_to(prev, next, prev);
/* switch_to之后的代码只有在
* 当前进程再次被选择运行(恢复执行)时才会运行
* 而此时当前进程恢复执行时的上一个进程可能跟参数传入时的prev不同
* 甚至可能是系统中任意一个随机的进程
* 因此switch_to通过第三个参数将此进程返回
*/
/* 路障同步, 一般用编译器指令实现
* 确保了switch_to和finish_task_switch的执行顺序
* 不会因为任何可能的优化而改变 */
barrier();
/* 进程切换之后的处理工作 */
return finish_task_switch(prev);
}
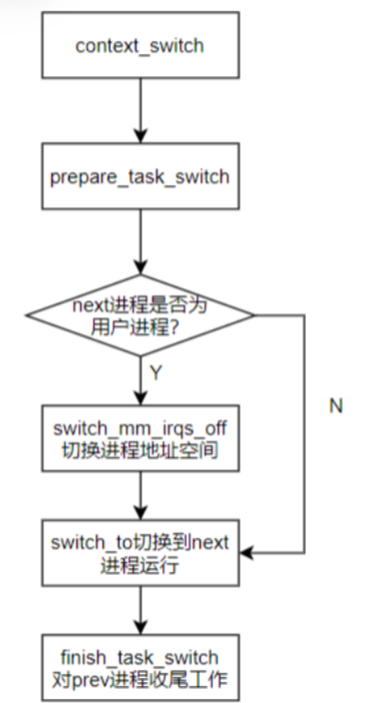
虽然每个进程都可以拥有属于自己的进程空间,但是所有进程必须共享CPU寄存器等资源,所以在进程切换的时候必须把next进程在上一次挂起时保持的寄存器重新装载到CPU里,进程恢复执行前必须装入CPU寄存器的数据为硬件上下文。由于对于每个进程拥有系统全部的虚拟地址空间,但是其并没有占用所有的物理地址,物理地址的访问需要页表转换完成,所以切换进程的页表到硬件页表中,此时才能切换进程地址空间,该过程是由switch_mm_irqs_off实现,切换到next进程的内核态栈和硬件上下文,是由switch_to函数实现的,硬件上下文提供了内核执行next进程所需要的所有硬件信息。
对于ARM64的cpu,每个cpu core都有两个寄存器来指示当前运行在该CPU core上的进程实体的地址空间,这两个寄存器分别是ttbr0_el1(用户地址空间)和ttbr1_el1(内核地址空间)。由于所有的进程共享内核地址空间,因此所谓地址空间切换也就是切换ttbr0_el1而已。
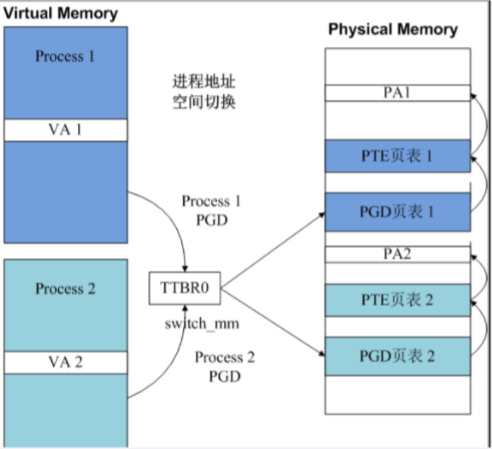
TTBR0指示了进程PGD页表基址,PGD指示了PTE页表基址,PTE指示了物理地址PA。每个进程的PGD不同,因而不同进程虚拟内存对于的物理地址就隔离开了。进程切换switch_mm实质上就是完成TTBR0寄存器的改写。
查看arm64的switch_to()函数:
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
unsigned int cpu = smp_processor_id();
/*
* init_mm.pgd does not contain any user mappings and it is always
* active for kernel addresses in TTBR1. Just set the reserved TTBR0.
*/
if (next == &init_mm) {
cpu_set_reserved_ttbr0();
return;
}
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next)
check_and_switch_context(next, tsk);
}
static inline void cpu_set_reserved_ttbr0(void)
{
unsigned long ttbr = page_to_phys(empty_zero_page); //对于swapper进程
asm(
" msr ttbr0_el1, %0 // set TTBR0\n"
" isb"
:
: "r" (ttbr));
}check_and_switch_context完成了进程地址空间的切换:
void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{
unsigned long flags;
unsigned int cpu = smp_processor_id();
u64 asid;
if (unlikely(mm->context.vmalloc_seq != init_mm.context.vmalloc_seq))
__check_vmalloc_seq(mm);
/*
* We cannot update the pgd and the ASID atomicly with classic
* MMU, so switch exclusively to global mappings to avoid
* speculative page table walking with the wrong TTBR.
*/
cpu_set_reserved_ttbr0();
asid = atomic64_read(&mm->context.id); //首先通过内存描述符读取该进程地址的ID
if (!((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS)//当切入的mm的asid仍然处于当前这批次的ASID时,进程不需要任何的TLB操作
&& atomic64_xchg(&per_cpu(active_asids, cpu), asid))
goto switch_mm_fastpath; //直接调用cpu_switch_mm进行地址空间切换
raw_spin_lock_irqsave(&cpu_asid_lock, flags);
/* Check that our ASID belongs to the current generation. */
asid = atomic64_read(&mm->context.id);
if ((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS) { ///当要切入的进程和当前的asid不一致的时候,说明地址空间需要一个新的asid,需要推进到 new generation了,分配一个新的 context id
asid = new_context(mm, cpu);
atomic64_set(&mm->context.id, asid);
}
if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending)) {
local_flush_bp_all();
local_flush_tlb_all(); //每个cpu在切入新一代的asid空间时,都要进行TLB
}
atomic64_set(&per_cpu(active_asids, cpu), asid);
cpumask_set_cpu(cpu, mm_cpumask(mm));
raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);
switch_mm_fastpath:
cpu_switch_mm(mm->pgd, mm);
}
调用switch_to进行栈空间切换:
extern struct task_struct *__switch_to(struct task_struct *,
struct task_struct *);
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next);//切换浮点寄存器
tls_thread_switch(next);//切换线程本地存储相关的寄存器
hw_breakpoint_thread_switch(next);//切换调试寄存器
contextidr_thread_switch(next);//切换上下文表示寄存器
/*
* Complete any pending TLB or cache maintenance on this CPU in case
* the thread migrates to a different CPU.
*/
dsb(ish);
/* the actual thread switch */
last = cpu_switch_to(prev, next); //切换通用寄存器
return last;
}/*
* Register switch for AArch64. The callee-saved registers need to be saved
* and restored. On entry:
* x0 = previous task_struct (must be preserved across the switch)
* x1 = next task_struct
* Previous and next are guaranteed not to be the same.
*
*/ //x0表示prev_task,x1是next_task
ENTRY(cpu_switch_to)
mov x10, #THREAD_CPU_CONTEXT //得到THREAD_CPU_CONTEXTD的偏移
add x8, x0, x10
mov x9, sp
stp x19, x20, [x8], #16 // store callee-saved registers
stp x21, x22, [x8], #16
stp x23, x24, [x8], #16
stp x25, x26, [x8], #16
stp x27, x28, [x8], #16
stp x29, x9, [x8], #16
str lr, [x8]
add x8, x1, x10
ldp x19, x20, [x8], #16 // restore callee-saved registers
ldp x21, x22, [x8], #16
ldp x23, x24, [x8], #16
ldp x25, x26, [x8], #16
ldp x27, x28, [x8], #16
ldp x29, x9, [x8], #16
ldr lr, [x8]
mov sp, x9
ret
ENDPROC(cpu_switch_to)cpu_switch_to要如何保存现场呢?要保存那些通用寄存器,那么就需要符合ARM64标准的过程调用,对于该过程用到了task_struct数据结构里的一个thread_struct的数据结构,用于存放和具体架构相关的信息,对于ARM64定义在arch/arm64/include/asm/processor.h中
struct thread_struct {
struct cpu_context cpu_context; /* cpu context */
unsigned long tp_value; /* TLS register */
#ifdef CONFIG_COMPAT
unsigned long tp2_value;
#endif
struct fpsimd_state fpsimd_state;
unsigned long fault_address; /* fault info */
unsigned long fault_code; /* ESR_EL1 value */
struct debug_info debug; /* debugging */
};struct cpu_context {
unsigned long x19;
unsigned long x20;
unsigned long x21;
unsigned long x22;
unsigned long x23;
unsigned long x24;
unsigned long x25;
unsigned long x26;
unsigned long x27;
unsigned long x28;
unsigned long fp;
unsigned long sp;
unsigned long pc;
};进程上下文切换的过程如下图所示,在切换的过程中,将进程硬件上下文的重要的寄存器保存到prev进程的cpu_context数据结构中,进程上下文的包括X19~X28寄存器,FP寄存器,SP寄存器,PC寄存器,然后将next进程描述符的cpu_contex的x19-x28,fp,sp,pc恢复到相应寄存器中,而且将next进程的进程描述符task_struct地址存放在sp_el0中,用于通过current找到当前进程,这样就完成了处理器的状态切换。

















 2528
2528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











