







问题引入
考虑构建一个垃圾邮件分类器,通过给定的垃圾邮件和非垃圾邮件的数据集,通过机器学习构建一个预测一个新的邮件是否是垃圾邮件的分类器。邮件分类器是通常的文本分类器中的一种。
朴素贝叶斯方法
贝叶斯假设
假设当前我们已经拥有了一批标识有是垃圾邮件还是非垃圾邮件的数据集,然后我们来构建一个分类器。
我们可以通过一个特征向量来表示一封邮件,向量的维度就是字典中单词的个数。如果字典中的第i个单词包含在邮件中,那个这个向量的
xi=1
,否则
xi=0
。假设字典中单词个数为50000,那么如下向量
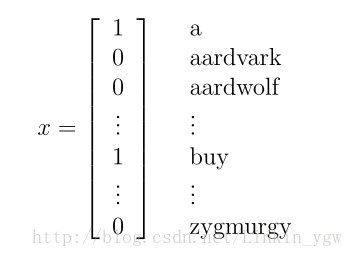
表示邮件中存在单词a,buy,而aardvark,aardwolf和zygmurgy不存在。从这里可以看到,向量的维度为字典单词的个数,这里为50000。
有了特征向量,我们来构建模型,实际上,我们需要构建的就是这样一个条件概率模型 p(x|y) ,这里字典的大小为50000,那么 x∈{0,1}50000 ,显然这种指数级的参数来估计是不可行的。若要构建 p(x|y) ,我们必须要做一些假设条件,我们假设每个 xi 针对给定的y具有条件独立性,这就是朴素贝叶斯假设。在这个假设条件下,例如在给定 y=1 的条件下 x200 与 x5 相互独立,即 p(x200|y)=p(x5|y,x200) ,这里需要注意的是不是假设 x200 和 x5 相互独立,而是在给定y的条件下相互独立。
朴素贝叶斯方法
有了以上的朴素贝叶斯假设,那我们可以构建我们的模型 p(x|y) ,
将模型参数化
ϕi|y=1=p(xi=1|y=1)
,
ϕi|y=1=p(xi=1|y=1)
,
ϕy=1=p(y=1)
。朴素贝叶斯方法,学习就是意味着估计这些参数,可以应用极大似然估计法估计相应的概率。先验概率的极大似然估计是:
这里 ϕj|y=1 的意思就是在所有的垃圾邮件中(y=1),单词 xj 出现的概率。对于朴素贝叶斯方法,我们所要计算的就是后验概率 p(y|x) ,有了上面的参数,后延概率计算如下:
然后确认哪一类具有最大的概率。
以上讲的邮件分类器中的特征都是离散的,如果特征是连续的变量该如何处理呢?连续的变量可以通过处理成离散的特征来应用朴素贝叶斯方法。例如房屋面积是一个连续变量,但是可以通过将面积按区间来处理得到一个离散的特征,如下图所示
| 面积(平方米) | <50 | 50~100 | 100~150 | 150~200 | >200 |
|---|---|---|---|---|---|
| xi | 1 | 2 | 3 | 4 | 5 |
通过这样处理后,我们就可以按照上面那样应用朴素贝叶斯方法了。
朴素贝叶斯训练函数python实现:
#Naïve Bayes classifier training function
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) #训练数据集大小
numWords = len(trainMatrix[0]) #有多少个特征
pAbusive = sum(trainCategory) / float(numTrainDocs) #计算p(y)
p0Num = zeros(numWords)
p1Num = zeros(numWords)
p0Denom = 0.0
p1Denom = 0.0
for i in range(numTrainDocs): #计算每一类中每个特征的概率,即p(wj|yi)
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num / p1Denom)
p0Vect = log(p0Num / p0Denom)
return p0Vect, p1Vect, pAbusive拉普拉斯平滑
上面的计算存在这一个隐藏的问题,就是如果一个词汇表中的单词在给定的数据集中都没有出现过的话,比如 x100 这个单词在数据集中都没有出现过,而新的需要分类的邮件中包含了 x100 这个单词,那么计算出来的 ϕ100|y=1=0 , ϕ100|y=0=0 ,同时, p(y=1|x)=00 ,这样就无法做出分类了。
考虑一个随机变量
z
取值于
为了避免刚才提到了某些特征计算出来为0的情况,我们可以应用拉普拉斯平滑,即将上式改为:
这样,就保证了 ϕj 不会为0,同时 ∑kj=1ϕj=1 也有保证。
回到上面的邮件分类器,应用拉普拉斯平滑后,
上面的代码应用拉普拉斯平滑后为:
#Naïve Bayes classifier training function
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) #训练数据集大小
numWords = len(trainMatrix[0]) #有多少个特征
pAbusive = sum(trainCategory) / float(numTrainDocs) #计算p(y)
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs): #计算每一类中每个特征的概率,即p(wj|yi)
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num / p1Denom)
p0Vect = log(p0Num / p0Denom)
return p0Vect, p1Vect, pAbusive













 2019
2019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









