







本文正在参与新星计划Python学习方向,详情请看:(93条消息) lifein的博客_CSDN博客-SQL SERVER,计算机三级——数据库领域博主
目录
一、引言
本文将从分类器指标的计算和ROC图像绘制,使用鸢尾花数据集来讲解分类器中代码的含义。
二、分类器
(一)代码:
1、导入库:
from sklearn.datasets import load_iris
from sklearn import tree, svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
import numpy as np如果未搭建环境,则需要先
pip install numpy
pip install sklearn2、数据集的加载、清洗、训练以及预测
# 加载数据集
iris = load_iris() # 一个数组
X = iris.data # 特征
y = iris.target # 标签
n_samples, n_features = X.shape # 返回各个维度的维数(行数——几个record,列数——几个特征)
# 一个数组:X.shape[0]代表行数,X.shape[1]代表列数;
# 一个包含了多个数组的数组:X.shape[0]代表包含二维数组的个数,X.shape[1]表示二维数组的行数,X.shape[2]表示二维数组的列数
# 清洗数据集
#加入噪点
random_state = np.random.RandomState(0)#始终产生同一个随机数(可复现性)
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)] # 引入random
#(1)rand(0):表示随机产生一个空数组。
#(2)rand(n):表示随机产生一个一维的,每个元素在[0,1)之间的n个数字的数组。
#(3)rand(m,n):表示随机产生一个m行n列的二维数组。
#(4)rand(d0,d1,…,dn):表示随机生成一个 d0×d1×⋯×dn 维度的数组。
#将数据二进制化处理,此处和onehotencoder大概一致
y = label_binarize(y, classes=[0, 1, 2]) # LabelBinarizer():标签二值化, 把yes和no转化为0和1
# classes参数,能指定标签的index,默认是从0开始按顺序给标签编码
n_classes = y.shape[1]
# 分割数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=33) # random_state就是为了保证程序每次运行都分割一样的训练集合测试集
# 引入训练模型
# clf = tree.DecisionTreeClassifier() # 决策树
clf = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True)) # 线性分类svm
# 开始训练
# clf.fit(X_train,y_train)
y_score = clf.fit(X_train, y_train).decision_function(X_test)
# 预测
y_predict=clf.predict(X_test)
print(n_classes)输出结果:3,意味着有三个类别的鸢尾花 。
3、 计算F1-Score值
# 计算F1-Score值
from sklearn.metrics import classification_report
print(clf.score(X_test,y_test)) # 使用均方误差对其进行打分,输出精确度,输出结果为0.9111, 随机后0.3555
print(classification_report(y_predict,y_test)) # F1-Score
# 输出结果为(012 分别表示3个标签的值),其结果转化为了独热编码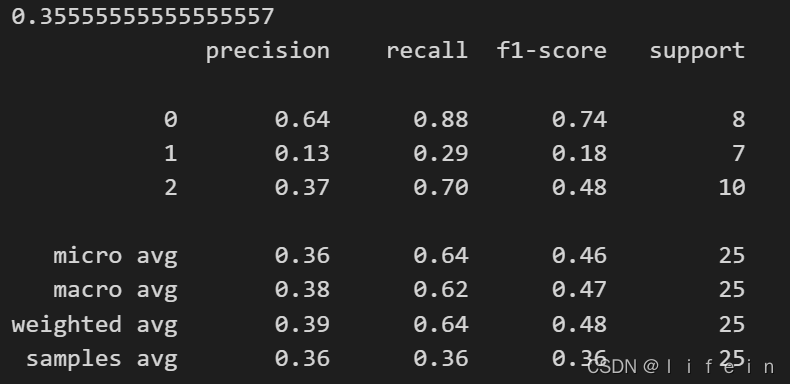
4、 计算fpr和tpr
# 计算fpr和tpr
from sklearn.metrics import roc_curve, auc
fpr = dict()
tpr = dict()
roc_auc = dict()
# 用一个分类器对应一个类别,每个分类器都把其他全部的类别作为相反类别看待。
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i]) # 取当前类这一列的实际标签和预测标签
roc_auc[i] = auc(fpr[i], tpr[i]) # 计算AUC面积5、绘制ROC曲线
# 绘制ROC曲线
import matplotlib.pyplot as plt
plt.figure()
plt.title("ROC")
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.plot(fpr[2], tpr[2], color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.legend(loc="lower right")
plt.show() 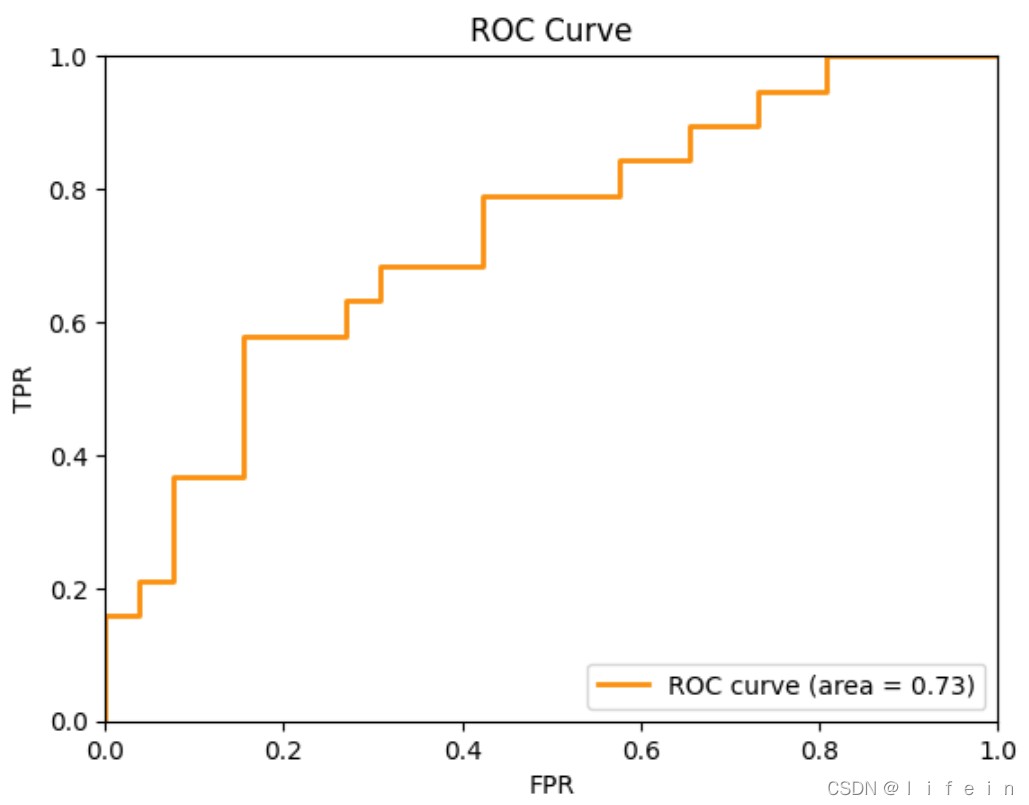
(二)重要注释:
1、np.random.randn()
·语法: numpy.random.randn(d0,d1,…,dn)
·功能: 用法同np.random.rand()一样,只是服从正态分布。用法同上。
·说明:
标准正态分布又称为u分布,是以0为均值、以1为标准差的正态分布,记为N(0,1)。randn函数返回一个或一组样本,具有标准正态分布。dn表格每个维度,返回值为指定维度的array。
2、np.random.randint()
·语法: numpy.random.randint(low, high=None, size=None, dtype=’l’)
·功能: 通过low来指定起点,通过high来指定终点,通过size参数来指定数组的维度,通过dtype来确定类型。
·说明:
返回值为随机整数,范围区间为[low,high),包含low,不包含high。
·参数:
low为最小值,high为最大值,size为数组维度大小,dtype为数据类型,默认的数据类型是np.int。high没有填写时,默认生成随机数的范围是[0,low)
3、fit_transform()
from sklearn.preprocessing import LabelEncoder里面的fit_transform就是将序列重新排列后再进行标准化,这个重新排列可以把它理解为查重加升序,像下面的序列,经过重新排列后可以得到:array([1,3,7]),而这个新的序列的索引是 0:1, 1:3, 2:7,这个就是fit的功能,所以transform根据索引又产生了一个新的序列,于是便得到array([0, 1, 1, 2, 1, 0])。
4、fit()
fit函数主要用来计算一组数据的特征值,例如平均值,方差,中位数等等固定属性。
5、transform()
transform这个函数主要是就是进行标椎化,降维,归一化等操作
6、fit_transform()
fit_transform这个函数主要就是将上述fit函数和transform函数结合起来一步操作,例如标椎化过程,首先计算方差和平均值,然后再进行标准化(比如标准化~N(0,1))。
注:
根据对之前部分trainData进行fit的整体指标,对剩余的数据(testData)使用同样的均值、方差、最大最小值等指标进行转换transform(testData),从而保证train、test处理方式相同。所以,一般都是这么用:
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
std.fit_tranform(X_train)
std.tranform(X_test)必须先用fit_transform(trainData),之后再transform(testData),如果直接transform(testData),程序会报错。如果fit_transfrom(trainData)后,使用fit_transform(testData)而不transform(testData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。(一定要避免这种情况)
有任何问题,欢迎在下方评论留言。
更多Python数据挖掘与分析内容,详见个人主页:(98条消息) lifein的博客_CSDN博客-Python可视化,Python,SQL SERVER领域博主
https://blog.csdn.net/m0_60066036?type=blog















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









