







 本文介绍了Google的Protocol Buffer(Protobuf)的优缺点、使用方法和序列化原理,包括TLV和Varint编码。进一步探讨了PbCodec的使用,这是一种避免大量生成getter/setter的高级技巧,简化了编码和解码过程。
本文介绍了Google的Protocol Buffer(Protobuf)的优缺点、使用方法和序列化原理,包括TLV和Varint编码。进一步探讨了PbCodec的使用,这是一种避免大量生成getter/setter的高级技巧,简化了编码和解码过程。
Protocol Buffer
Google Protocol Buffer又简称Protobuf,它是一种很高效的结构化数据存储格式,一般用于结构化数据的串行化,简单说就是我们常说的数据序列化。这种序列化的协议非常轻便高效,而且是跨平台的,目前已支持多种主流语言(3.0版本支持C++, JAVA, C#, OC, GO, PYTHON等)。
通过这种方式序列化得到的二进制流数据比传统的XML, JSON等方式的结果都占用更小的空间,并且其解析效率也更高,用于通讯协议或数据存储领域是非常好的。
再者,其使用的方式也非常简单,我们只需要预先定义好消息(message)的数据格式,然后通过其提供的compiler即可生成对应的文件,在那些文件里定义和实现了操作这个数据结构所有字段的setter/getter方法,我们只需要使用这些方法设置该数据结构的字段,然后通过序列化方法即可得到需要的结果(二进制数据流)。
一、优缺点
优点挺多的,以下简单例举几个好鸟。
- 更小,更快,更简单。更小是因为它的数据存储的很紧凑,与使用XML定义的数据相比较,其空间小3-4倍。后面从它的实现原理上也可以了解到为什么它占用空间会更小。
- “向后”兼容性好。不必破坏已部署的、依靠老数据格式的程序就可以对数据结构进行升级。所以不必担心因为消息结构的改变而造成大规模的代码重构或迁移问题。
- 语义清晰,不需要自己实现类似XML解析器那样的东西。只要使用Protobuf的compiler就可以生成对应的用于序列化和反序列化的对象。
其最大的缺点应该就是其序列化的结果缺乏自描述性,所以它不适合用来描述数据结构。与XML不同的就是,我们可以从XML的文件中直接很清晰的看出数据的层次结构等,而Procolbuf的结果都是二进制流不可读的,我们只能通过.proto文件来了解其数据结构。
二、Protocol Buffer的使用
Protobuf支持多语言,这里作为例子讲解的话主要解释的是C++语言上的使用方式,= =。其实不管啥语言好像都类似差不多,八九不离十的了。= =。这里就简单的做一下介绍就好了,其实详细的介绍和使用都可以在官网上的指南查到【Language Guide】。
2.1 第一步
这个例子使用的语言是C++,Protobuf的版本是2.6.1,windows平台上跑的。先直接甩出官网的链接,可以去上面下载【protocol-buffers】,因为这也是个开源项目(用C++写的),在github上也可以找到,而且上面也有3.0beta版本之类的可以去看看。
安装完了我们首先来看一波.proto定义文件的内容。这个消息(message)中定义了两个int和一个string类型的字段。一般实际上的消息要比这个要复杂的多,不过好在protobuf也支持比较复杂的消息结构。
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3;
}2.2 指定字段的类型
下面的表格列出了消息里字段允许的数据类型。
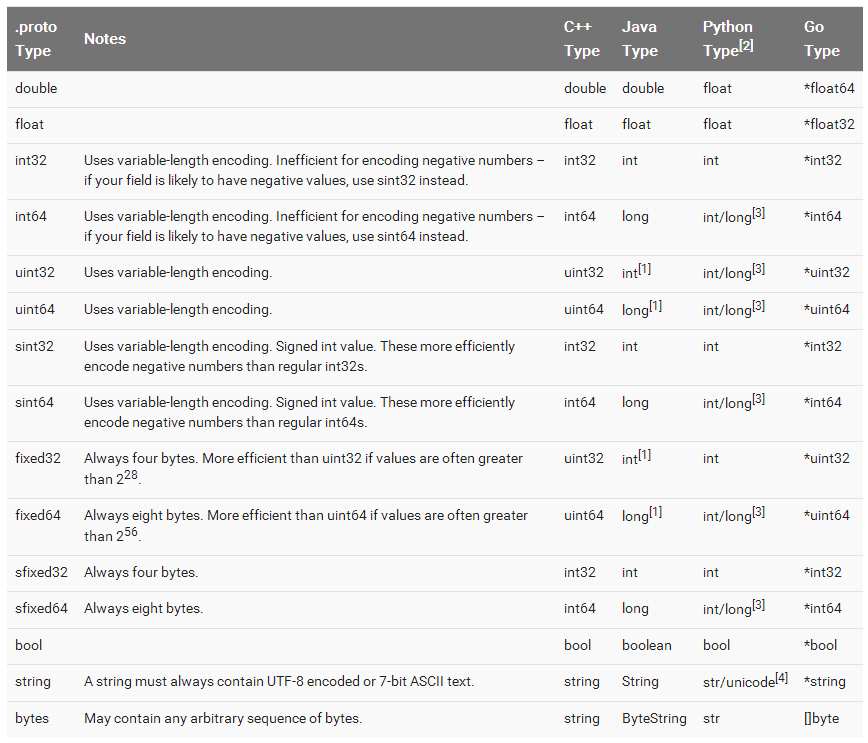
2.3 指定字段的规则
对于message中的字段可以指定三种规则,而且也都很简单:
required:表示该字段的值是必须要存在的,且只有一个。optional:表示该字段的值是可选的(不存在或有且只有一个)。repeated:表示该字段值可以有零或多个,且是有序的(即添加的顺序)。
2.4 其他部分
在一个.proto文件里可以定义多个message,且message可以嵌套(这点极大增强了灵活性啊)。message中对于字段的注释和平时代码的注释类似,使用 // 的方式就好了。
2.5 使用
当定义好了.proto文件,并且下载安装好对应版本的compile后,执行以下命令可以生成对应的.h和.cc文件。
其中$SRC_DIR表示希望生成的文件所在的目录,以及对应.proto文件所在目录的位置。
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto然后将生成的头文件引入要工程项目中,直接调用里面对应的方法就好了。(当然protobuf的基础库也要引入) = =。这些最基本的就不多说了,下面主要是扯一下它的实现原理和一个进阶使用。
如果对于安装和使用还有神马疑问,可以参考一下这些文章。(个人还是优先推荐官方文档)
- https://developers.google.com/protocol-buffers/docs/cpptutorial#defining-your-protocol-format
- http://colobu.com/2015/01/07/Protobuf-language-guide/ 【官方文档翻译版】???
- http://www.jianshu.com/p/b1f18240f0c7
三、原理简介
首先通过上面的简单使用应该可以了解到,实际上protobuf就是提供一个编译器给定义的message结构自动生成对应的消息类,且每个类中包含了对指定字段的setter, getter方法,以及序列化和反序列化整个消息类的serialize和parse方法,对于使用者来说只需要简单调用这些方法就可以实现消息的序列化和反序列化操作了。
为了更深入了解其序列化和反序列化的原理的话,就要先了解其组织数据的方式。
3.1 TLV
实际上protobuf使用一种类似((T)([L]V))的形式来组织数据的,即Tag-Length-Value(其中Length是可选的,比如储存Varint编码数据就不需要存储Length)。每一个字段都是使用TLV的方式进行序列化的,一个消息就可以看成是多个字段的TLV序列拼接成的一个二进制字节流。其实这种方式很像Key-Value的方式,所以Tag一般也可以看做是Key。由上可知,这种方式组织的数据并不需要额外的分隔符来划分数据,所以这也是其可以减低序列化结果的大小的原因之一。
下面这图有点不太准确,不过可以凑合着理解一下。
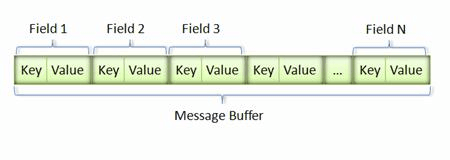
Value的值很自然知道就是字段的值,那么Tag值是什么呢?在.proto文件中定义的每一个字段都需要声明其数据类型,其还表明该字段是可变长度还是固定长度,这部分一般称为wire_type。此外, 每个字段都有一个field值,这个值代表该字段是message里的第几个值,一般称为field_num。
required string query = 1
//比如说这里字段query为可变长的string类型,其field = 1,是消息中的第一个值;在Protobuf中,数据类型是进行了划分的,其中wire_type主要是以下几种类型。
- Varint是一种比较特殊的编码方式,后面会再介绍。
- FixedXXX是固定长度的数字类型。
- Length-delimited是可变长数据类型,常见的就是string, bytes之类的。
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5,
};
了解了wire_type的含义后,就可以知道Tag是怎么解析的。就是结合移位操作和或操作就可以判断出其是哪种数据类型了。这里可能有人会疑惑field_num左移3位后会不会导致数据丢失,实际上可以假设field_num是uint32类型的,其左移3位后,可以表示的数范围为(0 ~ 2^29-1)这么大的范围足够表示message里字段数了吧!(从枚举的WireType类型变量中可以知道wire_type只需要3位就可以表示了)。
key = field_num << 3 || wire_type;3.2 Varint
Varint是一种紧凑的表示数字的方式。它可以用一个或多个字节来表示一个数字,其中值越小的数字需要的字节数越少。Varint中每一个字节的最高位bit都是有特殊含义的,如果其值为1,则表示下一个字节也是该数字的一部分,如果其值为0,则表明该数字到这一个字节就结束了。
通常情况下一个int32类型的数字,一般需要4个字节来表示。使用Varint方式编码的话,对于比较小的数字,比如说 -128~127 之间的数字则只需要一个字节,而如果是300(下图有解释),则需要两个字节来表示。然而其也有不好的地方,比如说对于一个大数字,其最多可能需要5个字节来表示,但从概率统计的角度来说,绝大多数情况下采用Varint编码可以减少字节数来表示数字。
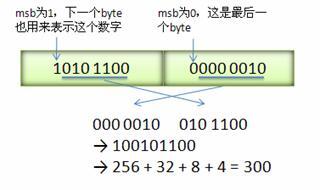
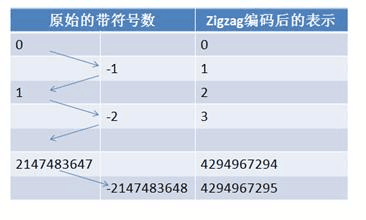
在计算机里,一个负数会被表示为一个很大的整数(- -,就是最高位一般为符号位,负数最高位为1)。如果采用Varint来编码的话负数则一定会需要5个字节了。所以Google protocol buffer 定义了sint32, sint64这些数据类型,其采用zigzag编码(见下图)。这样无论是正数还是负数,只要其绝对值比较小的时候需要的字节数就少,可以充分发挥Varint编码的优势。
3.3 序列化
protobuf生成的类中,其继承体系涉及的主要是::google::protobuf::MessageLite和Message这两个类,其中Message是::google::protobuf::MessageLite的子类。我们自动生成的类可能继承自这两个类中的一个,这取决于在proto描述文件中的配置,如果设置option optimize_for = LITE_RUNTIM,则编译生成的类继承自::google::protobuf::MessageLite。这两个类都拥有基本的功能的代码,而Message是扩展出来的子类,增加了一些特性功能,然而实际中如果用不到这些功能,则开启这个优化可以使得我们生成的文件更小。
现在来了解一下序列化的过程。先看一段代码:
//序列化接口,传入一个输出流参数
void ReqBody::SerializeWithCachedSizes(::google::protobuf::io::CodedOutputStream* output) const {
//这个message中有一个可选参数叫msg_set_req,其field_num = 1;
//optional message msg_set_req = 1;
//先判断该字段是否设置,如果设置则调用相应函数
if (has_msg_set_req()) {
::google::protobuf::internal::WireFormatLite::WriteMessage(1, this->msg_set_req(),output);
}
}
//判断该值是否已经设置
inline bool ReqBody::has_msg_set_req() const {
return (_has_bits_[0] & 0x00000001u) != 0;
} 在代码中看到序列化就是判断某些字段是否已经设置了值,如果设置了值就调用相应的函数写出该字段。如果找一个包括多个字段的message看的话,其SerializeWithCachedSizes方法中应该会包含多个类似上面的if()操作。然后还有很多类似判断该字段是否已经设置的内联函数。
大家应该还注意到了_has_bits_这个数组,这个数组标示了其中某个字段是否已经设置了值,这个数组在反序列化是也会被创建和设置,然后就像上面那函数一样用于判断某个字段是否已经设置了值。
通过查看protobuf源代码的wire_format_lite.h头文件中的定义,会发现针对不同类型的数据类型,都有对应的writeXXX方法。
// Write fields, including tags.
static void WriteInt32 (field_number, int32 value, output);
static void WriteInt64 (field_number, int64 value, output);
static void WriteUInt32 (field_number, uint32 value, output);
static void WriteUInt64 (field_number, uint64 value, output);
static void WriteSInt32 (field_number, int32 value, output);
static void WriteSInt64 (field_number, int64 value, output);
static void WriteFixed32 (field_number, uint32  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









