







Linux下ibus输入法词库扩展
一、骡子
面向百度编程已经给出了很多方法,但是都没有把真正的资源给你,都是链接到国外网站 国外ibus词库下载地址;国外网站很慢,甚至访问不了。然后某些地方虽然给出了下载的文件,但是要付出代价,比如某SDN下载。
二、直接上教程
-
到我的码云:https://gitee.com/mr_allen/ibus-thesaurus.git下载里面的文件(如果不能访问可以留言或私信我,看到会第一时间回复),只要
local.db的文件就可以了。 -
下载完了直接复制到输入法路径下,我的路径是这个
/usr/share/ibus-libpinyin/db(没添加之前没有local.db文件)
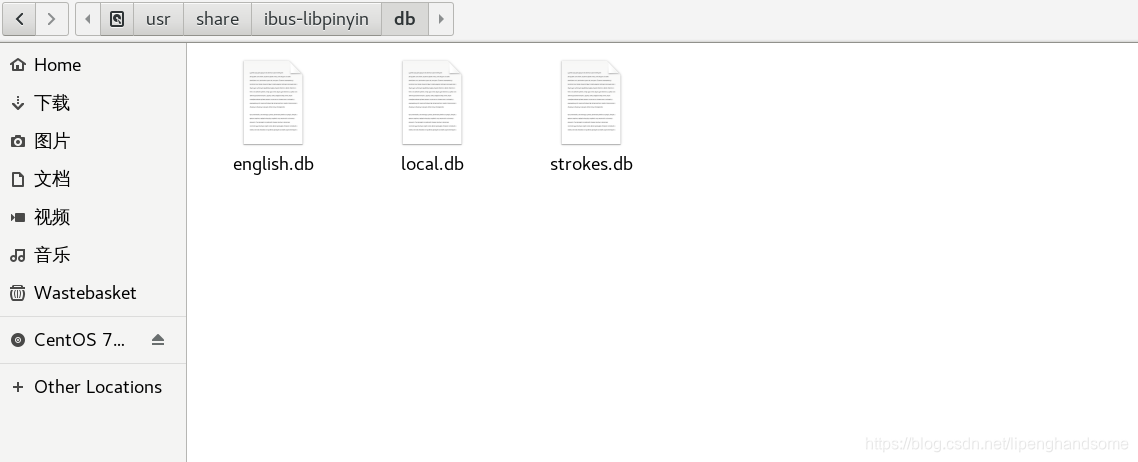
-
然后重启一下
ibus输入法,重启方式如下(不行的就重启系统):ibus-daemon -d -x -r
然后能打出弗雷德霍姆行列式就是成功了。这个词库只是比较常用的,如果需要更丰富的,可以自己去找一下。
三、目前支持的词汇(如果你找到了比较全的词库,希望能够得到你的分享)
词库包括以下部分:
成语大全
诗词精选
网络用语
名人词库
名人名言
美食大全
股票基金
计算机
流行歌曲
动漫大全
四、补充:自己添加词库
下载:首先到搜狗输入法官方https://pinyin.sogou.com/dict/cate/index/97?rf=dictindex下载词库,下载后文件是以.scel结尾的文件。转换:这时就需要将搜狗的词库导出生成新的.txt文档或者直接.db的文档。粘贴复制:方法同上,将你新生成的词库合并到之前local.db的词库里面。重启输入法:ibus-daemon -d -x -r
生成代码如下:
注:下面代码在其他大佬博客上找的,因为我的Linux词库需要的格式是打工人 da'gong'ren这样的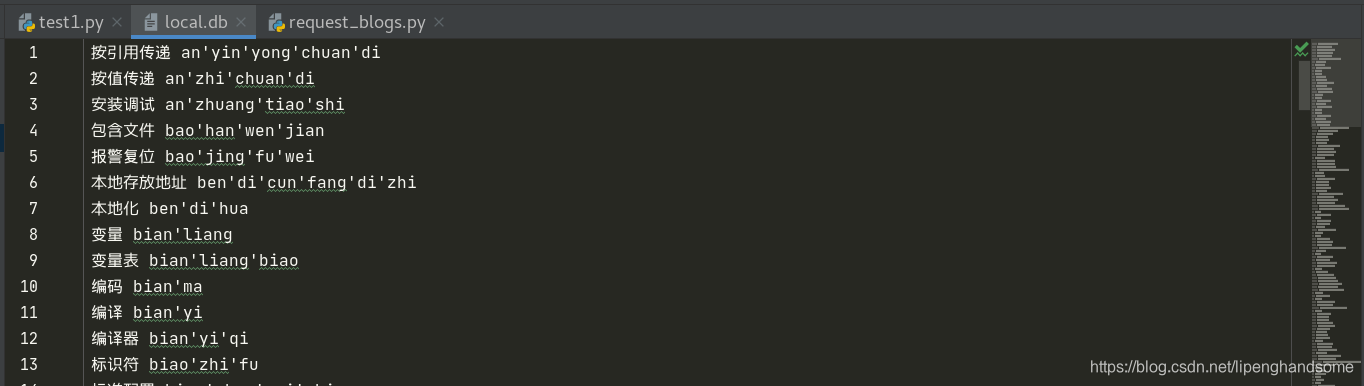
所以在代码的getWordPy接口做了判断,增加'符号。不需要的可删掉,其他的不多叙述,可自行阅读代码更改
#!/usr/bin/python
# -*- coding: utf-8 -*-
import struct
import sys
import binascii
import pdb
# 搜狗的scel词库就是保存的文本的unicode编码,每两个字节一个字符(中文汉字或者英文字母)
# 找出其每部分的偏移位置即可
# 主要两部分
# 1.全局拼音表,貌似是所有的拼音组合,字典序
# 格式为(index,len,pinyin)的列表
# index: 两个字节的整数 代表这个拼音的索引
# len: 两个字节的整数 拼音的字节长度
# pinyin: 当前的拼音,每个字符两个字节,总长len
#
# 2.汉语词组表
# 格式为(same,py_table_len,py_table,{word_len,word,ext_len,ext})的一个列表
# same: 两个字节 整数 同音词数量
# py_table_len: 两个字节 整数
# py_table: 整数列表,每个整数两个字节,每个整数代表一个拼音的索引
#
# word_len:两个字节 整数 代表中文词组字节数长度
# word: 中文词组,每个中文汉字两个字节,总长度word_len
# ext_len: 两个字节 整数 代表扩展信息的长度,好像都是10
# ext: 扩展信息 前两个字节是一个整数(不知道是不是词频) 后八个字节全是0
#
# {word_len,word,ext_len,ext} 一共重复same次 同音词 相同拼音表
# 拼音表偏移,
startPy = 0x1540
# 汉语词组表偏移
startChinese = 0x2628
# 全局拼音表
GPy_Table = {}
# 解析结果
# 元组(词频,拼音,中文词组)的列表
GTable = []
def byte2str(data):
'''将原始字节码转为字符串'''
i = 0
length = len(data)
ret = u''
while i < length:
x = data[i:i+2]
t = chr(struct.unpack('H', x)[0])
if t == u'\r':
ret += u'\n'
elif t != u' ':
ret += t
i += 2
return ret
# 获取拼音表
def getPyTable(data):
if data[0:4] != bytes(map(ord,"\x9D\x01\x00\x00")):
return None
data = data[4:]
pos = 0
length = len(data)
while pos < length:
index = struct.unpack('H', data[pos:pos +2])[0]
# print index,
pos += 2
l = struct.unpack('H', data[pos:pos + 2])[0]
# print l,
pos += 2
py = byte2str(data[pos:pos + l])
# print py
GPy_Table[index] = py
pos += l
# 获取一个词组的拼音
def getWordPy(data):
pos = 0
length = len(data)
ret = u''
while pos < length:
if pos>0: #在每个拼音之间插入字符'做分割,如果你的输入法词库不需要这种格式可删掉
ret += "'"
index = struct.unpack('H', data[pos:pos + 2])[0]
ret += GPy_Table[index]
pos += 2
return ret
# 获取一个词组
def getWord(data):
pos = 0
length = len(data)
ret = u''
while pos < length:
index = struct.unpack('H', data[pos:pos +2])[0]
ret += GPy_Table[index]
pos += 2
return ret
# 读取中文表
def getChinese(data):
# import pdb
# pdb.set_trace()
pos = 0
length = len(data)
while pos < length:
# 同音词数量
same = struct.unpack('H', data[pos:pos + 2])[0]
# print '[same]:',same,
# 拼音索引表长度
pos += 2
py_table_len = struct.unpack('H', data[pos:pos + 2])[0]
# 拼音索引表
pos += 2
py = getWordPy(data[pos: pos + py_table_len])
# 中文词组
pos += py_table_len
for i in range(same):
# 中文词组长度
c_len = struct.unpack('H', data[pos:pos +2])[0]
# 中文词组
pos += 2
word = byte2str(data[pos: pos + c_len])
# 扩展数据长度
pos += c_len
ext_len = struct.unpack('H', data[pos:pos +2])[0]
# 词频
pos += 2
count = struct.unpack('H', data[pos:pos +2])[0]
# 保存
GTable.append((count, py, word))
# 到下个词的偏移位置
pos += ext_len
def deal(file_name):
print('-' * 60)
f = open(file_name, 'rb')
data = f.read()
f.close()
if data[0:12] != bytes(map(ord,"\x40\x15\x00\x00\x44\x43\x53\x01\x01\x00\x00\x00")):
print("确认你选择的是搜狗(.scel)词库?")
sys.exit(0)
# pdb.set_trace()
print("词库名:", byte2str(data[0x130:0x338])) # .encode('GB18030')
print("词库类型:", byte2str(data[0x338:0x540])) # .encode('GB18030')
print("描述信息:", byte2str(data[0x540:0xd40])) # .encode('GB18030')
print("词库示例:", byte2str(data[0xd40:startPy]) ) # .encode('GB18030')
getPyTable(data[startPy:startChinese])
getChinese(data[startChinese:])
if __name__ == '__main__':
# 将要转换的词库添加在这里就可以了
o = ['helloword.scel']
for f in o:
deal(f)
# 保存结果
f = open('local.db', 'w')
for count, py, word in GTable:
# GTable保存着结果,是一个列表,每个元素是一个元组(词频,拼音,中文词组),有需要的话可以保存成自己需要个格式
# 我没排序,所以结果是按照上面输入文件的顺序
# print(count,py,word)
# f.write((('{%(count)s}' % {'count': count} + py + ' ' + word))) # 最终保存文件的编码,可以自给改
f.write(( word + ' ' + py)) # 最终保存文件的编码,可以自给改
f.write('\n')
f.close()

















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









