







1机器学习
1.1 逻辑回归:
分析因变量y取某个值的概率与自变量x的关系,0<y<1,可以理解为实际上是寻找一个以x为变量的函数;
Logistic回归为概率型非线性回归模型,是研究二分类观察结果
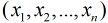
变量分析方法。通常的问题是,研究某些因素条件下某个结果是否发生,比如医学中根据病人的一些症状来判断它是
否患有某种病。
在讲解Logistic回归理论之前,我们先从LR分类器说起。LR分类器,即Logistic Regression Classifier。
在分类情形下,经过学习后的LR分类器是一组权值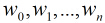
照线性加和得到
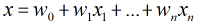
这里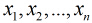
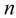
之后按照sigmoid函数的形式求出
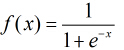
由于sigmoid函数的定义域为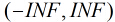
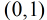
所以Logistic回归最关键的问题就是研究如何求得
求权值可以使用梯度下降法、或极大似然估计来做。
1.2 梯度下降法

 ;
;
;
;
 初始值就在local minimum的位置,则会如何变化?
已经在local minimum位置,所以derivative 肯定是0,因此
不会变化;
初始值就在local minimum的位置,则会如何变化?
已经在local minimum位置,所以derivative 肯定是0,因此
不会变化;
 值,则cost function应该越来越小;
值?
值,如果cost function变小了,则ok,反之,则再取一个更小的值;
值,则cost function应该越来越小;
值?
值,如果cost function变小了,则ok,反之,则再取一个更小的值;



| 举个实际的例子,
有两个Feature:
(1)size,取值范围0~2000;
(2)#bedroom,取值范围0~5;
则通过feature scaling后,


|

| midterm exam | (midterm exam)2 | final exam |
| 89 | 7921 | 96 |
| 72 | 5184 | 74 |
| 94 | 8836 | 87 |
| 69 | 4761 | 78 |
 经过feature scaling后的值为多少?
经过feature scaling后的值为多少?



| x | y |
| 3 | 4 |
| 2 | 1 |
| 4 | 3 |
| 0 | 1 |

1.3 神经网络各层权重、偏差的大小确定方法
每层神经元个数n[i]由神经网络构架者自行确定,每层参数的个数由该层输入的个数n[i-1],及本层神经元数目n[i]共同确定,权重矩阵大小为[n[i],n[i-1]],偏差b向量大小为[n[i],1].
当输入样本为n时,注意numpy库的传播作用。
深层神经网络其实就是包含更多的隐藏层神经网络。如下图所示,分别列举了逻辑回归、1个隐藏层的神经网络、2个隐藏层的神经网络和5个隐藏层的神经网络它们的模型结构。
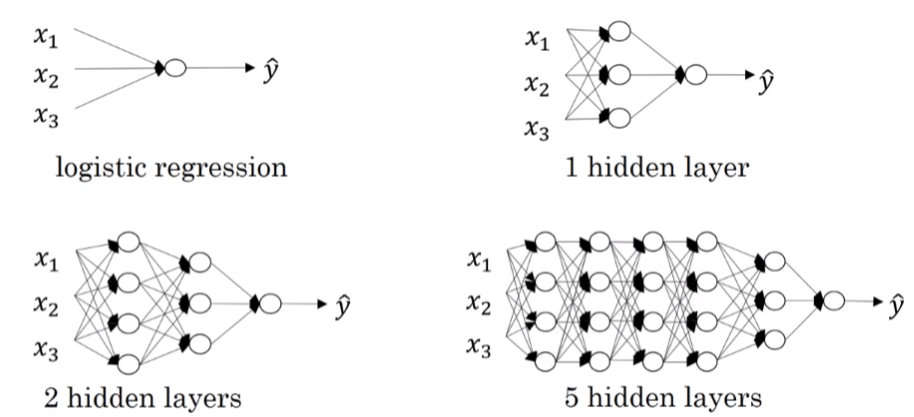
命名规则上,一般只参考隐藏层个数和输出层。例如,上图中的逻辑回归又叫1 layer NN,1个隐藏层的神经网络叫做2 layer NN,2个隐藏层的神经网络叫做3 layer NN,以此类推。如果是L-layer NN,则包含了L-1个隐藏层,最后的L层是输出层。
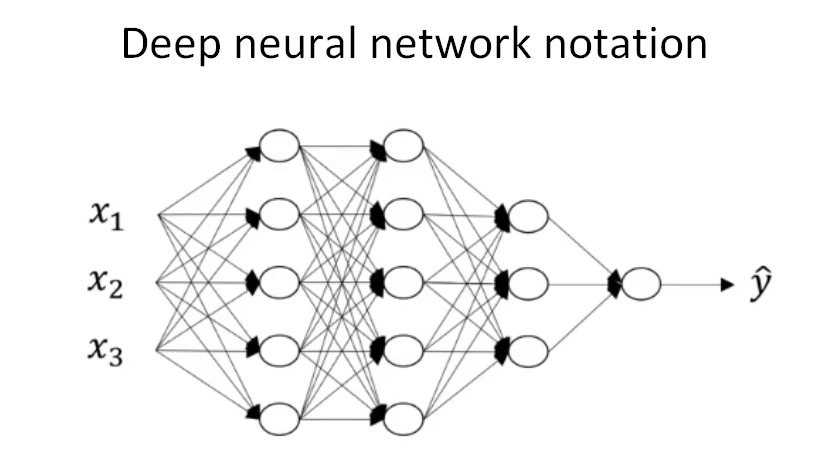
下面以一个4层神经网络为例来介绍关于神经网络的一些标记写法。如下图所示,首先,总层数用L表示,L=4。输入层是第0层,输出层是第L层。 n[l] 表示第 l 层包含的单元个数, l=0,1,⋯,L 。这个模型中, n[0]=nx=3 ,表示三个输入特征 x1,x2,x3 。 n[1]=5 , n[2]=5 , n[3]=3 , n[4]=n[L]=1 。第 l 层的激活函数输出用 a[l] 表示, a[l]=g[l](z[l]) 。 W[l] 表示第 l 层的权重,用于计算 z[l] 。另外,我们把输入x记为 a[0] ,把输出层 y^ 记为 a[L] 。
注意, a[l] 和 W[l] 中的上标 l 都是从1开始的, l=1,⋯,L 。
2. Forward Propagation in a Deep Network
接下来,我们来推导一下深层神经网络的正向传播过程。仍以上面讲过的4层神经网络为例,对于单个样本:
第1层, l=1 :
第2层, l=2 :
第3层, l=3 :
第4层, l=4 :
如果有m个训练样本,其向量化矩阵形式为:
第1层, l=1 :
第2层, l=2 :
第3层, l=3 :
第4层, l=4 :
综上所述,对于第 l 层,其正向传播过程的 Z[l] 和 A[l] 可以表示为:
其中 l=1,⋯,L
3. Getting your matrix dimensions right
对于单个训练样本,输入x的维度是( n[0],1 )神经网络的参数 W[l] 和 b[l] 的维度分别是:
其中, l=1,⋯,L , n[l] 和 n[l−1] 分别表示第 l 层和 l−1 层的所含单元个数。 n[0]=nx ,表示输入层特征数目。
顺便提一下,反向传播过程中的 dW[l] 和 db[l] 的维度分别是:
注意到, W[l] 与 dW[l] 维度相同, b[l] 与 db[l] 维度相同。这很容易理解。
正向传播过程中的 z[l] 和 a[l] 的维度分别是:
z[l] 和 a[l] 的维度是一样的,且 dz[l] 和 da[l] 的维度均与 z[l] 和 a[l] 的维度一致。
对于m个训练样本,输入矩阵X的维度是( n[0],m )。需要注意的是 W[l] 和 b[l] 的维度与只有单个样本是一致的:
只不过在运算 Z[l]=W[l]A[l−1]+b[l] 中, b[l] 会被当成( n[l],m )矩阵进行运算,这是因为python的广播性质,且 b[l] 每一列向量都是一样的。 dW[l] 和 db[l] 的维度分别与 W[l] 和 b[l] 的相同。
但是, Z[l] 和 A[l] 的维度发生了变化:
dZ[l] 和 dA[l] 的维度分别与 Z[l] 和 A[l] 的相同。
1.4 神经网络的构建方法
1、确定神经网络的结构
2、初始化参数 各层权重及偏差
3、循环
a.计算前向传递函数
b.计算损失函数
c.计算反向传递函数,获得各层dw,db;
d.更新参数
1.5 神经网络超参数调试
学习率 迭代次数 隐藏层层数 各层隐藏单元数 激活函数等都是超参数
调试思路:
1、参考论文中给出的数据,通过实验验证其有效性
未全待续,,,,,,,,
1.6 方差与偏差问题
方差衡量训练集与开发集训练准确度之间的差值
偏差描述训练集的准确度 ,准确度越高,偏差越小
(可避免偏差,是人类分类的误差与机器分类误差之差的衡量,可用其对神经网络是否还有提升空间进行分析)
对于高偏差的情况:通过更大的神经网络来训练、以解决高偏差问题、或使用更好的算法
高方差问题:通过正则化方法解决高方差 (dropout 、 L2、) 、使用更大的训练集















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









